高效学习NumPy基础
- 创建数组
- numpy.array(object, dtype,copy, order, subox, ndmin)
- numpy.arange(start, stop, step, dtype)
- numpy.linspace(start, stop, num)
- numpy.logspase(start,stop,num)
- numpy.zeros(shape,dtype,order)
- numpy.eye(N,M, K,dtype,order)
- numpy.diag(V,K)
- numpy.ones(shape,dtype, order)
- 数组对象的属性
- 数组数据类型
- 基本数据类型
- 类型转换
- 创建数据类型
- 查看数据类型
- 自定义数组数据
- 生成随机数
- random模块的常用随机数生成函数
- 通过索引访问数组
- 一维数组的索引
- 多维数组的索引
- 使用整数函数和布尔值索引访问多维数组
- 变换数组的形态
- reshape()改变数组形状
- ravel()展平数组
- flatten()展平数组
- hstack()横向合并数组
- vstack()纵向合并数组
- concatenate()合并数组
- hsplit()横向分割数组
- vsplit()纵向分割数组
- split()分割数组
- 创建NumPy矩阵
- 矩阵创建
- 矩阵运算
- 矩阵属性
- ufunc函数
- 常用的函数
- 常用的ufunc函数运算
- 广播机制
- 文件操作
- 数据存储
- 文件读取
- txt格式保存与读取
- genfromtxt函数读取数据
- 排序
- sort函数 无返回值 直接对原始数据修改
- argsort函数
- lexsort函数
- 去重与生成重复数据
- 常用的统计函数
NumPy提供了两种基本对象:ndarray和ufunc,ndarray称为数组,而ufunc则是对数组进行处理的函数。
创建数组
numpy.array(object, dtype,copy, order, subox, ndmin)
用于创建NumPy数组
import numpy as np
"""
array(object, dtype=None, copy=True, order='K', subox=False, ndmin=0)
参数说明:
object : 数组,公开数组接口的任何对象,__array__方法返回数组的对象,或任何(嵌套)序列。
dtype : 数据类型,数组所需的数据类型。如果没有给出,那么类型将被确定为保持序列中的对象所需的最小类型。此参数只能用于“upcast”数组。对于向下转换,请使用.astype(t)方法。
copy : 如果为True(默认值),则复制对象。否则,只有当__array__返回副本,obj是嵌套序列,或者需要副本来满足任何其他要求(dtype,顺序等)时,才会进行复制。
order : 英文字母,参数可写{'K','A','C','F'},指定阵列的内存布局。如果object不是数组,则新创建的数组将按C顺序排列(行主要),除非指定了'F',在这种情况下,它将采用Fortran顺序(专业列)。如果object是一个数组,则以下成立。当copy=False出于其他原因而复制时,结果copy=True与对A的一些例外情况相同,请参阅“注释”部分。默认顺序为“K”。
subok : boolean值,如果为True,则子类将被传递,否则返回的数组将被强制为基类数组(默认)。
ndmin : int值,指定结果数组应具有的最小维数。根据需要,将根据需要预先设置形状。
满足要求的数组对象
"""
# 创建一个数组 主要参数 object、dtype、ndmin。
a1 = np.array([1,2,3])
a2 = np.array([1,2,3], dtype=float)
a3 = np.array([1,2,3], ndmin=2)
print(a1)
print(a2)
print(a3)
运行结果:
[1 2 3]
[1. 2. 3.]
[[1 2 3]]
numpy.arange(start, stop, step, dtype)
在给定间隔内返回均匀间隔的值。左闭右开区间 [起始值,终止值)
import numpy as np
# 用array(range(10)) 生成0-9的的int类型数组
a1 = np.array(range(10))
"""
numpy.arange(start, stop, step, dtype=None)
参数说明:
start 起始值
stop 终止值 生成的范围到终止值-1 例如(0,10) 生成0~9
step 步长
dtype 数据类型
"""
# a1和a2的效果一样
a2 = np.arange(10)
a3 = np.arange(0, 10)
a4 = np.arange(0, 10, 2)
a5 = np.arange(0, 10, 2, float)
print(a1)
print(a2)
print(a3)
print(a4)
print(a5)
运行结果:
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
[0 2 4 6 8]
[0. 2. 4. 6. 8.]
numpy.linspace(start, stop, num)
用于返回间隔类均匀分布的数值序列。闭区间 [起始值,终止值]
import numpy as np
"""
numpy.linspace(start, stop, num)
参数说明:
start 起始值
stop 终止值
num 数量 默认值为50
"""
a1 = np.linspace(0,10)
a2 = np.linspace(0,10, 5)
print(a1)
print(a2)
运行结果:
[ 0. 0.20408163 0.40816327 0.6122449 0.81632653 1.02040816
1.2244898 1.42857143 1.63265306 1.83673469 2.04081633 2.24489796
2.44897959 2.65306122 2.85714286 3.06122449 3.26530612 3.46938776
3.67346939 3.87755102 4.08163265 4.28571429 4.48979592 4.69387755
4.89795918 5.10204082 5.30612245 5.51020408 5.71428571 5.91836735
6.12244898 6.32653061 6.53061224 6.73469388 6.93877551 7.14285714
7.34693878 7.55102041 7.75510204 7.95918367 8.16326531 8.36734694
8.57142857 8.7755102 8.97959184 9.18367347 9.3877551 9.59183673
9.79591837 10. ]
[ 0. 2.5 5. 7.5 10. ]
numpy.logspase(start,stop,num)
用于返回间隔类均匀分布的等比数列。闭区间 [起始值,终止值]
"""
numpy.logspace(start, stop, num)
参数说明:
start 起始值
stop 终止值
num 数量 默认值为50
"""
a1 = np.logspace(0,2)
a2 = np.logspace(0,2, 5)
print(a1)
print(a2)
运行结果:
[ 1. 1.09854114 1.20679264 1.32571137 1.45634848
1.59985872 1.75751062 1.93069773 2.12095089 2.32995181
2.55954792 2.8117687 3.0888436 3.39322177 3.72759372
4.09491506 4.49843267 4.94171336 5.42867544 5.96362332
6.55128557 7.19685673 7.90604321 8.68511374 9.54095476
10.48113134 11.51395399 12.64855217 13.89495494 15.26417967
16.76832937 18.42069969 20.23589648 22.22996483 24.42053095
26.82695795 29.47051703 32.37457543 35.56480306 39.06939937
42.9193426 47.14866363 51.79474679 56.89866029 62.50551925
68.6648845 75.43120063 82.86427729 91.0298178 100. ]
[ 1. 3.16227766 10. 31.6227766 100. ]
numpy.zeros(shape,dtype,order)
用于创建值全部为0的数组,即创建的数组元素全部为0
"""
numpy.zeros(shape, dtype, order)
参数说明:
shape 数组的维度
dtype 数据类型
order 指定阵列的内存布局
"""
a1 = np.zeros((5,5), dtype=int)
a2 = np.zeros((5,5), dtype=float)
print(a1)
print(a2)
运行结果:
[[0 0 0 0 0]
[0 0 0 0 0]
[0 0 0 0 0]
[0 0 0 0 0]
[0 0 0 0 0]]
[[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0.]]
numpy.eye(N,M, K,dtype,order)
用于生成主对角线为1,其余元素为0的数组
"""
numpy.eye(N,M, K,dtype,order)
参数说明:
N 数组的行数
M 数组的列数 不写默认为N
K 对角线的索引:0(默认值)指的是主对角线,正值指的是上对角线,负值指的是下对角线。
dtype 数据类型
order 指定阵列的内存布局
"""
a1 = np.eye(5, dtype=int)
a2 = np.eye(2, 3, dtype=int)
a3 = np.eye(5, 5, 0, dtype=int)
a4 = np.eye(5, 5, 1, dtype=int)
a5 = np.eye(5, 5, -1, dtype=int)
print(a1)
print(a2)
print(a3)
print(a4)
print(a5)
运行结果:
[[1 0 0 0 0]
[0 1 0 0 0]
[0 0 1 0 0]
[0 0 0 1 0]
[0 0 0 0 1]]
[[1 0 0]
[0 1 0]]
[[1 0 0 0 0]
[0 1 0 0 0]
[0 0 1 0 0]
[0 0 0 1 0]
[0 0 0 0 1]]
[[0 1 0 0 0]
[0 0 1 0 0]
[0 0 0 1 0]
[0 0 0 0 1]
[0 0 0 0 0]]
[[0 0 0 0 0]
[1 0 0 0 0]
[0 1 0 0 0]
[0 0 1 0 0]
[0 0 0 1 0]]
numpy.diag(V,K)
除了对角线以外的其他元素为0, 对角线上的元素可以是0或其他值
"""
numpy.diag(V, K)
参数说明:
V 如果是2D数组,返回k位置的对角线。
如果是1D数组,返回一个v作为k位置对角线的2维数组。
K 对角线的位置,大于零位于对角线上面,小于零则在下面。
"""
a1 = np.diag([1,2,3,4])
a2 = np.diag([1,2,3,4,5], 0)
a3 = np.diag([1,2,3,4,5], 1)
a4 = np.diag([1,2,3,4,5], -1)
print(a1)
print(a2)
print(a3)
print(a4)
运行结果:
[[1 0 0 0]
[0 2 0 0]
[0 0 3 0]
[0 0 0 4]]
[[1 0 0 0 0]
[0 2 0 0 0]
[0 0 3 0 0]
[0 0 0 4 0]
[0 0 0 0 5]]
[[0 1 0 0 0 0]
[0 0 2 0 0 0]
[0 0 0 3 0 0]
[0 0 0 0 4 0]
[0 0 0 0 0 5]
[0 0 0 0 0 0]]
[[0 0 0 0 0 0]
[1 0 0 0 0 0]
[0 2 0 0 0 0]
[0 0 3 0 0 0]
[0 0 0 4 0 0]
[0 0 0 0 5 0]]
numpy.ones(shape,dtype, order)
用于创建元素全部为1的数组
"""
numpy.ones(shape, dtype, order)
参数说明:
shape 数组的维度
dtype 数据类型
order 指定阵列的内存布局
"""
a1 = np.ones((3,4), dtype=int)
a2 = np.ones((4,4), dtype=float)
print(a1)
print(a2)
运行结果:
[[1 1 1 1]
[1 1 1 1]
[1 1 1 1]]
[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]
数组对象的属性
| 属性 | 说明 |
|---|---|
| ndarray.ndim | 秩,即轴的数量或维度的数量 |
| ndarray.shape | 数组的维度,对于矩阵,n 行 m 列 |
| ndarray.size | 数组元素的总个数,相当于 .shape 中 n*m 的值 |
| ndarray.dtype | ndarray 对象的元素类型 |
| ndarray.itemsize | ndarray 对象中每个元素的大小,以字节为单位 |
| ndarray.flags | ndarray 对象的内存信息 |
| ndarray.real | ndarray元素的实部 |
| ndarray.imag | ndarray 元素的虚部 |
| ndarray.data | 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性。 |
import numpy as np
"""
数组对象的属性
ndarray.ndim 秩,即轴的数量或维度的数量
ndarray.shape 数组的维度,对于矩阵,n 行 m 列
ndarray.size 数组元素的总个数,相当于 .shape 中 n*m 的值
ndarray.dtype ndarray 对象的元素类型
ndarray.itemsize ndarray 对象中每个元素的大小,以字节为单位
ndarray.flags ndarray 对象的内存信息
ndarray.real ndarray元素的实部
ndarray.imag ndarray 元素的虚部
ndarray.data 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性。
"""
a1 = np.array([[1,2,3], [4,5,6], [7,8,9]])
print("ndim:", a1.ndim)
print("shape:", a1.shape)
print("size:", a1.size)
print("dtype:", a1.dtype)
print("itemsize:", a1.itemsize)
"""
C_CONTIGUOUS (C) 数据是在一个单一的C风格的连续段中
F_CONTIGUOUS (F) 数据是在一个单一的Fortran风格的连续段中
OWNDATA (O) 数组拥有它所使用的内存或从另一个对象中借用它
WRITEABLE (W) 数据区域可以被写入,将该值设置为 False,则数据为只读
ALIGNED (A) 数据和所有元素都适当地对齐到硬件上
UPDATEIFCOPY (U) 这个数组是其它数组的一个副本,当这个数组被释放时,原数组的内容将被更新
"""
print("flags:", a1.flags)
print("real:", a1.real)
print("imag:", a1.imag)
print("data:", a1.data)
运行结果:
ndim: 2
shape: (3, 3)
size: 9
dtype: int32
itemsize: 4
flags: C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
real: [[1 2 3]
[4 5 6]
[7 8 9]]
imag: [[0 0 0]
[0 0 0]
[0 0 0]]
data: <memory at 0x000001D1BDE91860>
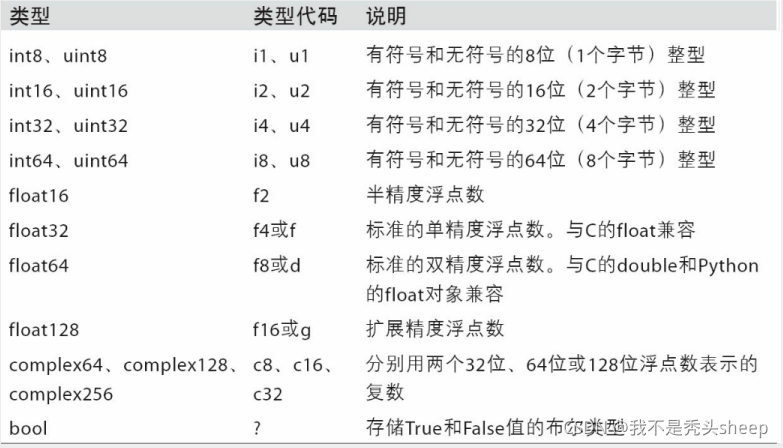
数组数据类型
基本数据类型
转载至https://www.cnblogs.com/mengxiaoleng/p/11616270.html

类型转换
语法:numpy.数据类型(object)
# 整型转换为浮点型
print("整型转换为浮点型:", np.float64(66))
# 浮点型转换为整型
print("浮点型转换为整型:", np.int8(66.66))
# 整型转换为布尔型 0为False 其他数为True
print("整型转换为布尔型:", np.bool(0))
# 布尔型转浮点型 True为1.0 False为0.0
print("布尔型转浮点型:", np.float64(True))
"""
运行结果:
整型转换为浮点型: 66.0
浮点型转换为整型: 66
整型转换为布尔型: False
布尔型转浮点型: 1.0
"""
创建数据类型
语法:numpy.dtype([(name, dtype, [size]),(name, dtype)…])
"""
创建一个数据类型,存储图书信息
需求:
1.能存储50个字符的字符串 记录书名
2.用一个64位的整数 记录库存
3.用一个64位的单精度浮点数 记录价格
"""
book_type = np.dtype([("name", np.str_, 50), ("count", np.int64), ("price", np.float64)])
print("数据类型为:", book_type)
运行结果:
数据类型为: [('name', '<U50'), ('count', '<i8'), ('price', '<f8')]
查看数据类型
语法:直接当作字典访问或numpy.dtype()
# 直接访问
print("图书名字的数据类型:", book_type["name"])
# numpy.dtype()
print("图书数量的数据类型:", np.dtype(book_type["count"]))
运行结果:
图书名字的数据类型: <U50
图书数量的数据类型: int64
自定义数组数据
在使用array函数创建数组时,自定义数组数据,可以预先自定数据类型,而默认是浮点型。
items = np.array([("华为应用开发中级", 88, 79.00), ("Python语言程序设计", 50, 49.80)], dtype=book_type)
print("自定义数据为:", items)
运行结果:
自定义数据为: [('华为应用开发中级', 88, 79. ) ('Python语言程序设计', 50, 49.8)]
生成随机数
# rand函数生成的均匀分布的随机数 参数:size
a1 = np.random.rand(1, 2)
a2 = np.random.rand(1, 2, 3, 4)
print("rand函数生成的均匀分布的随机数:")
print(a1)
print(a2)
print("-"*50)
# randn函数生成具有标准正态分布的随机数 参数:size
a3 = np.random.randn(1, 2)
a4 = np.random.randn(1, 2, 3, 4)
print("randn函数生成具有标准正态分布的随机数:")
print(a3)
print(a4)
print("-"*50)
# randint函数生成[low, high)区间的随机整数 参数:low, high, size, dtype
a5 = np.random.randint(1, 10, [1, 2], dtype="short")
a6 = np.random.randint(1, 10, [1, 2, 3], dtype="long")
print("randint函数生成[low, high)区间的随机整数:")
print(a5, a5.dtype)
print(a6, a6.dtype)
print("-"*50)
# random_sample函数生成随机浮点数,在半开区间 [0.0, 1.0) 参数: size
a7 = np.random.random_sample([1, 2])
a8 = np.random.random_sample([1, 2, 3])
print("random_sample函数生成随机浮点数:")
print(a7)
print(a8)
运行结果:
rand函数生成的均匀分布的随机数:
[[0.37825834 0.36723038]]
[[[[0.71418784 0.73996675 0.15419813 0.99419331]
[0.58614779 0.73066644 0.49114029 0.80010252]
[0.33072697 0.48593358 0.73750939 0.6098291 ]]
[[0.18201681 0.34509901 0.07229337 0.89061953]
[0.41669819 0.59503481 0.73802839 0.40802414]
[0.185528 0.73147802 0.46253263 0.25485796]]]]
--------------------------------------------------
randn函数生成具有标准正态分布的随机数:
[[1.01330053 0.59629841]]
[[[[-1.23013022 -0.54980997 -0.86341347 -0.14536862]
[-0.54584678 -0.22382106 -1.71041033 0.91828566]
[-0.2115877 -0.53002694 0.04532693 -0.7821888 ]]
[[-0.39234029 -0.82818071 -0.06566115 0.63458322]
[ 0.51276787 -2.08087158 0.47010658 1.85817864]
[ 1.09909745 0.24666559 -0.72258201 -0.64547011]]]]
--------------------------------------------------
randint函数生成[low, high)区间的随机整数:
[[5 6]] int16
[[[5 2 1]
[9 1 9]]] int32
--------------------------------------------------
random_sample函数生成随机浮点数:
[[0.97716236 0.89218794]]
[[[0.53794987 0.11502953 0.32427659]
[0.51851268 0.631096 0.49160983]]]
random模块的常用随机数生成函数
| 函数 | 说明 |
|---|---|
| seed | 确定随机数生成种子 |
| permutation | 返回一个序列的随机排列或返回一个随机排列的范围 |
| shuffle | 对一个序列进行随机排序 |
| binomial | 生成二项分布的随机数 |
| normal | 生成正态(高斯)分布的随机数 |
| beta | 生成beta分布的随机数 |
| chisquare | 生成卡方分布的随机数 |
| gamma | 生成gamma分布的随机数 |
| uniform | 生成在[0,1]中均匀分布的随机数 |
通过索引访问数组
一维数组的索引
# 定义数组
a = np.arange(10)
# 获取某个元素
print("获取某个元素:", a[3])
# 切片(跟列表切片是一样的)
print("取前五个元素:", a[:6], a[:-4], a[0: 6])
# 设置步长 取 1 3 5 7
print("设置步长:", a[1: 8: 2])
# 反向设置步长 取7 5 3 1
print("反向设置步长", a[7: 0: -2])
运行结果:
获取某个元素: 3
取前五个元素: [0 1 2 3 4 5] [0 1 2 3 4 5] [0 1 2 3 4 5]
设置步长: [1 3 5 7]
反向设置步长 [7 5 3 1]
多维数组的索引
# 定义多维数组
a = np.array([[1,2,3,4,5], [4,5,6,7,8], [7,8,9,10,11]])
# 取第1行第2 3个 注意下标都是从0开始的 即第2行的第3 4个
print("取第1行第2 3个:", a[1, 2: 4])
# 取第0和1行 第1~4列的元素 即取第一第二行的第二个元素到最后一个元素
print("取第0和1行 第2~5列的元素:", a[:2, 1:])
# 取所有行的第3列
print("取所有行的第3列", a[:, 2])
运行结果:
取第1行第2 3个: [6 7]
取第0和1行 第2~5列的元素: [[2 3 4 5]
[5 6 7 8]]
取所有行的第3列 [3 6 9]
使用整数函数和布尔值索引访问多维数组
# 定义多维数组
a = np.array([[1,2,3,4,5], [4,5,6,7,8], [7,8,9,10,11]])
# 从两个序列的对应位置去除两个整数来组成下标 [0,1] [2,2] [2,3]
print("索引结果为:", a[(0,2,2), (1,2,3)])
# 取第一第二行的0,1,2列元素
print("取第一第二行的0,1,2列元素:", a[1:, (0, 1 ,2)])
# 生成一个布尔数组
bools = np.array([0, 1, 1], dtype=np.bool)
# 取第一第二行的4列元素
print("取第一第二行的4列元素:", a[bools, 3])
运行结果:
索引结果为: [ 2 9 10]
取第一第二行的0,1,2列元素: [[4 5 6]
[7 8 9]]
取第一第二行的3,4列元素: [ 7 10]
变换数组的形态
reshape()改变数组形状
# 创建一个数组
a1 = np.arange(12)
print("原数据:", a1, a1.shape)
# 改变数组的形状 (不改变原对象, 生成新的对象需要接收返回值)
a2 = a1.reshape(3, 4)
print("改变数组的形状:", a2, a2.shape)
运行结果:
原数据: [ 0 1 2 3 4 5 6 7 8 9 10 11] (12,)
改变数组的形状: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]] (3, 4)
ravel()展平数组
# 创建一个数组
a1 = np.arange(12)
print("原数据:", a1, a1.shape)
# 改变数组的形状 (不改变原对象, 生成新的对象需要接收返回值)
a2 = a1.reshape(3, 4)
print("改变数组的形状:", a2, a2.shape)
# ravel函数展平数组 (改变原对象, 不需要接收返回值)
a1.ravel()
print("ravel函数展平数组后:", a1, a1.shape)
运行结果:
原数据: [ 0 1 2 3 4 5 6 7 8 9 10 11] (12,)
改变数组的形状: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]] (3, 4)
ravel函数展平数组: [ 0 1 2 3 4 5 6 7 8 9 10 11] (12,)
flatten()展平数组
# 创建一个shape为(3, 4)的数组
a1 = np.arange(12).reshape(3, 4)
print("原数据:", a, a.shape)
# flatten函数展平数组
a2 = a1.flatten() # 横向展平
print("横向展平:", a2, a2.shape)
a3 = a1.flatten('F') # 纵向展平
print("纵向展平:", a3, a3.shape)
运行结果:
原数据: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]] (3, 4)
横向展平: [ 0 1 2 3 4 5 6 7 8 9 10 11] (12,)
纵向展平: [ 0 4 8 1 5 9 2 6 10 3 7 11] (12,)
hstack()横向合并数组
# 创建两个数组
a1 = np.arange(12).reshape(3, 4)
a2 = a1 * 2
print("数组1:", a1, a1.shape)
print("数组2:", a2, a2.shape)
# hstack横向合并
print("hstack横向合并:", np.hstack((a1, a2)))
运行结果:
数组1: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]] (3, 4)
数组2: [[ 0 2 4 6]
[ 8 10 12 14]
[16 18 20 22]] (3, 4)
hstack横向合并: [[ 0 1 2 3 0 2 4 6]
[ 4 5 6 7 8 10 12 14]
[ 8 9 10 11 16 18 20 22]]
vstack()纵向合并数组
# 创建两个数组
a1 = np.arange(12).reshape(3, 4)
a2 = a1 * 2
print("数组1:", a1, a1.shape)
print("数组2:", a2, a2.shape)
# vstack纵向合并
print("vstack纵向合并:", np.vstack((a1, a2)))
运行结果:
数组1: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]] (3, 4)
数组2: [[ 0 2 4 6]
[ 8 10 12 14]
[16 18 20 22]] (3, 4)
vstack纵向合并: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[ 0 2 4 6]
[ 8 10 12 14]
[16 18 20 22]]
concatenate()合并数组
# 创建两个数组
a1 = np.arange(12).reshape(3, 4)
a2 = a1 * 2
print("数组1:", a1, a1.shape)
print("数组2:", a2, a2.shape)
# concatenate横向合并 (axis默认为0)
print("concatenate纵向合并:", np.concatenate((a1, a2), axis=0))
# concatenate横向合并
print("concatenate横向合并:", np.concatenate((a1, a2), axis=1))
运行结果:
数组1: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]] (3, 4)
数组2: [[ 0 2 4 6]
[ 8 10 12 14]
[16 18 20 22]] (3, 4)
concatenate纵向合并: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[ 0 2 4 6]
[ 8 10 12 14]
[16 18 20 22]]
concatenate横向合并: [[ 0 1 2 3 0 2 4 6]
[ 4 5 6 7 8 10 12 14]
[ 8 9 10 11 16 18 20 22]]
hsplit()横向分割数组
# 创建一个数组
a = np.arange(16).reshape(4, 4)
print("原数组:", a, a.shape)
# 横向分割
print("横向分割:", np.hsplit(a, 2))
运行结果:
原数组: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]] (4, 4)
横向分割: [array([[ 0, 1],
[ 4, 5],
[ 8, 9],
[12, 13]]), array([[ 2, 3],
[ 6, 7],
[10, 11],
[14, 15]])]
vsplit()纵向分割数组
# 创建一个数组
a = np.arange(16).reshape(4, 4)
print("原数组:", a, a.shape)
# 纵向分割
print("纵向分割:", np.vsplit(a, 2))
运行结果:
原数组: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]] (4, 4)
纵向分割: [array([[0, 1, 2, 3],
[4, 5, 6, 7]]), array([[ 8, 9, 10, 11],
[12, 13, 14, 15]])]
split()分割数组
# 创建一个数组
a = np.arange(16).reshape(4, 4)
print("原数组:", a, a.shape)
# 纵向分割 (axis默认为0)
print("纵向分割:", np.split(a, 2, axis=0))
# 横向分割
print("横向分割:", np.split(a, 2, axis=1))
运行结果:
原数组: [[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]] (4, 4)
纵向分割: [array([[0, 1, 2, 3],
[4, 5, 6, 7]]), array([[ 8, 9, 10, 11],
[12, 13, 14, 15]])]
横向分割: [array([[ 0, 1],
[ 4, 5],
[ 8, 9],
[12, 13]]), array([[ 2, 3],
[ 6, 7],
[10, 11],
[14, 15]])]
创建NumPy矩阵
矩阵创建
# mat创建矩阵 使用分号分隔数据
m1 = np.mat("1 2 3; 4 5 6; 7 8 9")
print(m1, m1.shape)
# matrix创建矩阵
m2 = np.matrix([[1,2,3], [4,5,6], [7,8,9]])
print(m2, m2.shape)
# 创建一个全为0和一个全为1的数组
a1 = np.zeros([3, 3])
a2 = np.ones([3, 3])
# # bmat将多个小矩阵(数组)合并成一个大矩阵
print("bmat将多个小矩阵合并成一个大矩阵:\n", np.bmat("a1 a2;a2 a1"))
运行结果:
[[1 2 3]
[4 5 6]
[7 8 9]] (3, 3)
[[1 2 3]
[4 5 6]
[7 8 9]] (3, 3)
bmat将多个小矩阵合并成一个大矩阵:
[[0. 0. 0. 1. 1. 1.]
[0. 0. 0. 1. 1. 1.]
[0. 0. 0. 1. 1. 1.]
[1. 1. 1. 0. 0. 0.]
[1. 1. 1. 0. 0. 0.]
[1. 1. 1. 0. 0. 0.]]
矩阵运算
# 创建两个矩阵
m1 = np.mat("1 2 3; 4 5 6; 7 8 9")
m2 = m1 * 2
print("矩阵1:", m1, m1.shape)
print("矩阵2:", m2, m2.shape)
# 矩阵相加
print("矩阵相加:", m1 + m2)
# 矩阵相减
print("矩阵相减:", m1 - m2)
# 矩阵相除
print("矩阵相除:", (m2+1) / (m1+1))
# 矩阵相乘
print("矩阵相乘:", m1 * m2)
print("矩阵相乘:", np.multiply(m1, m2))
运行结果:
矩阵1: [[1 2 3]
[4 5 6]
[7 8 9]] (3, 3)
矩阵2: [[ 2 4 6]
[ 8 10 12]
[14 16 18]] (3, 3)
矩阵相加: [[ 3 6 9]
[12 15 18]
[21 24 27]]
矩阵相减: [[-1 -2 -3]
[-4 -5 -6]
[-7 -8 -9]]
矩阵相除: [[1.5 1.66666667 1.75 ]
[1.8 1.83333333 1.85714286]
[1.875 1.88888889 1.9 ]]
矩阵相乘: [[ 60 72 84]
[132 162 192]
[204 252 300]]
矩阵相乘: [[ 2 8 18]
[ 32 50 72]
[ 98 128 162]]
矩阵属性
| 属性 | 说明 |
|---|---|
| T | 返回自身的转置 |
| H | 返回自身的共轭转置 |
| I | 返回自身的逆矩阵 |
| A | 返回自身数据的二维数组的一个视图(没做任何复制) |
# 创建矩阵
m = np.mat("1 2 3; 4 5 6; 7 8 9")
# 转置
print("转置:", m.T)
# 共轭转置
print("共轭转置:", m.H)
# 逆矩阵
print("逆矩阵:", m.I)
# 二维数组的视图
print("二维数组的视图:", m.A)
运行结果:
转置: [[1 4 7]
[2 5 8]
[3 6 9]]
共轭转置: [[1 4 7]
[2 5 8]
[3 6 9]]
逆矩阵: [[-4.50359963e+15 9.00719925e+15 -4.50359963e+15]
[ 9.00719925e+15 -1.80143985e+16 9.00719925e+15]
[-4.50359963e+15 9.00719925e+15 -4.50359963e+15]]
二维数组的视图: [[1 2 3]
[4 5 6]
[7 8 9]]
ufunc函数
常用的函数
大多数ufunc函数都是用C语言实现的,因此ufunc函数比math库中的函数效率高。
| 函数 | 使用方法 |
|---|---|
| sqrt() | 计算序列化数据的平方根 |
| sin()、cos() | 三角函数 |
| abs() | 计算序列化数据的绝对值 |
| dot() | 矩阵运算 |
| log()、logl()、log2() | 对数函数 |
| exp() | 指数函数 |
| cumsum()、cumproduct() | 累计求和、求积 |
| sum() | 对一个序列化数据进行求和 |
| mean() | 计算均值 |
| median() | 计算中位数 |
| std() | 计算标准差 |
| var() | 计算方差 |
| corrcoef() | 计算相关系数 |
常用的ufunc函数运算
进行运算的两个数组的形状必须相同
# 创建两个数组
a = np.array([1, 2, 3])
b = np.array([2, 4, 6])
# 四则运算
print("数组相加:", a + b)
print("数组相减:", a - b)
print("数组相乘:", a * b)
print("数组相除:", a / b)
print("数组幂运算:", a ** b)
# 比较运算
print("比较结果:", a < b)
print("比较结果:", a > b)
print("比较结果:", a == b)
print("比较结果:", a <= b)
print("比较结果:", a >= b)
print("比较结果:", a != b)
运行结果:
数组相加: [3 6 9]
数组相减: [-1 -2 -3]
数组相乘: [ 2 8 18]
数组相除: [0.5 0.5 0.5]
数组幂运算: [ 1 16 729]
比较结果: [ True True True]
比较结果: [False False False]
比较结果: [False False False]
比较结果: [ True True True]
比较结果: [False False False]
比较结果: [ True True True]
广播机制
- ufunc通用函数,能够对array中所有元素进行操作的函数
- Broadcasting指对不同形状的array之间执行算术运算的方式
- 不同形状的数组运算时,Numpy则会执行广播机制
- numpy能够运用向量化运算处理整个数组,所以速度比较快
文件操作
数据存储
# 创建数组
a = np.arange(100).reshape(10, 10)
b = a * 2
# 二进制数据保存 np.save(file, arr, allow_pickle=True, fix_imports=True)
np.save("save01", a)
# 多个数组保存
np.savez("save02", a, b)
运行结果:
文件读取
# 读取单个数组
a = np.load("save01.npy")
print("读取单个数组", a)
# 读取多个数组
data = np.load("save02.npz")
# arr_下标 固定格式
print("a:", data['arr_0'])
print("b:", data['arr_1'])
运行结果:
读取单个数组 [[ 0 1 2 3 4 5 6 7 8 9]
[10 11 12 13 14 15 16 17 18 19]
[20 21 22 23 24 25 26 27 28 29]
[30 31 32 33 34 35 36 37 38 39]
[40 41 42 43 44 45 46 47 48 49]
[50 51 52 53 54 55 56 57 58 59]
[60 61 62 63 64 65 66 67 68 69]
[70 71 72 73 74 75 76 77 78 79]
[80 81 82 83 84 85 86 87 88 89]
[90 91 92 93 94 95 96 97 98 99]]
a: [[ 0 1 2 3 4 5 6 7 8 9]
[10 11 12 13 14 15 16 17 18 19]
[20 21 22 23 24 25 26 27 28 29]
[30 31 32 33 34 35 36 37 38 39]
[40 41 42 43 44 45 46 47 48 49]
[50 51 52 53 54 55 56 57 58 59]
[60 61 62 63 64 65 66 67 68 69]
[70 71 72 73 74 75 76 77 78 79]
[80 81 82 83 84 85 86 87 88 89]
[90 91 92 93 94 95 96 97 98 99]]
b: [[ 0 2 4 6 8 10 12 14 16 18]
[ 20 22 24 26 28 30 32 34 36 38]
[ 40 42 44 46 48 50 52 54 56 58]
[ 60 62 64 66 68 70 72 74 76 78]
[ 80 82 84 86 88 90 92 94 96 98]
[100 102 104 106 108 110 112 114 116 118]
[120 122 124 126 128 130 132 134 136 138]
[140 142 144 146 148 150 152 154 156 158]
[160 162 164 166 168 170 172 174 176 178]
[180 182 184 186 188 190 192 194 196 198]]
txt格式保存与读取
# 创建数组
a = np.arange(16).reshape(4, 4)
# txt格式数据保存 np.savetxt(file, arr, fmt="%.18e", delimiter=" ", newline="\n", header="", footer="", comments="# ")
np.savetxt("save03.txt", a, fmt="%d", delimiter=",", newline="\n")
# 读取txt文件
data = np.loadtxt("save03.txt", delimiter=",")
print(data)
运行结果:
[[ 0. 1. 2. 3.]
[ 4. 5. 6. 7.]
[ 8. 9. 10. 11.]
[12. 13. 14. 15.]]
genfromtxt函数读取数据
genfromtxt函数和loadtxt函数相似,genfromtxt函数是面向结构化和缺失数据。通常使用的三个参数,fname文件路径,delimiter分隔符,names列标题
# 使用genfromtxt函数读取数据
data = np.genfromtxt("save03.txt", delimiter=",")
print(data)
运行结果:
[[ 0. 1. 2. 3.]
[ 4. 5. 6. 7.]
[ 8. 9. 10. 11.]
[12. 13. 14. 15.]]
排序
sort函数 无返回值 直接对原始数据修改
# 设置随机数种子
np.random.seed(11)
# 随机生成一维数组
a = np.random.randint(1, 10, size=10)
print("排序前:", a)
a.sort()
print("排序后:", a)
# 随机生成二维数组
b = np.random.randint(1, 10, size=(3, 3))
# 纵向排序
b.sort(axis=0)
print("纵向排序", b)
# 横向排序
b.sort(axis=1)
print("横向排序", b)
运行结果:
排序前: [1 2 8 2 8 3 9 1 1 5]
排序后: [1 1 1 2 2 3 5 8 8 9]
纵向排序 [[2 2 5]
[3 8 6]
[6 9 9]]
横向排序 [[2 2 5]
[3 6 8]
[6 9 9]]
argsort函数
# 随机生成一维数组
a = np.random.randint(1, 10, size=10)
print("排序前:", a)
# 返回值为重新排序后,原值的下标
print("排序后返回下标:", a.argsort())
运行结果:
排序前: [4 2 1 4 9 8 2 5 9 3]
排序后返回下标: [2 1 6 9 0 3 7 5 4 8]
lexsort函数
# 创建三个数组
a = np.array([5, 7, 8, 2])
b = np.array([30, 50, 20, 80])
c = np.array([900, 400, 600, 200])
# 进行lexsort排序 只接收一个参数
d = np.lexsort((a, b , c))
# 多个键值排序时,按照最后一个传入的数据排序
print("排序后返回下标:", d)
print("排序后的数组为:", list(zip(a[d], b[d], c[d])))
运行结果:
排序后返回下标: [3 1 2 0]
排序后的数组为: [(2, 80, 200), (7, 50, 400), (8, 20, 600), (5, 30, 900)]
去重与生成重复数据
# 随机生成一维数组
a = np.random.randint(1, 5, size=10)
print("一维数组a:", a)
# 去重
print("去重后:", np.unique(a))
# 生成[0, 1, 2, 3, 4]
b = np.arange(5)
# np.tile(arr, times)
print("使用tile函数对b重复3次后:", np.tile(b, 3))
# 创建一个二维数组
c = np.random.randint(0, 10, size=(2, 3))
print("二维数组c:", c)
# np.repeat(arr, times, axis=None)
print("纵向重复数据:", np.repeat(c, 2, axis=0))
print("横向重复数据:", np.repeat(c, 2, axis=1))
运行结果:
一维数组a: [3 2 4 2 3 1 4 2 2 3]
去重后: [1 2 3 4]
使用tile函数对b重复3次后: [0 1 2 3 4 0 1 2 3 4 0 1 2 3 4]
二维数组c: [[6 9 1]
[1 6 5]]
纵向重复数据: [[6 9 1]
[6 9 1]
[1 6 5]
[1 6 5]]
横向重复数据: [[6 6 9 9 1 1]
[1 1 6 6 5 5]]
常用的统计函数
a = np.arange(1,17).reshape(4, 4)
print("数组a:", a)
print("求和:", np.sum(a))
print("纵向求和:", np.sum(a, axis=0))
print("横向求和:", np.sum(a, axis=1))
print("平均值", np.mean(a))
print("纵向平均值:", np.mean(a, axis=0))
print("横向平均值:", np.mean(a, axis=1))
print("标准差:", np.std(a))
print("方差:", np.var(a))
print("最大值:", np.max(a))
print("最小值:", np.min(a))
print("最小索引", np.argmin(a))
print("最大索引", np.argmax(a))
print("计算索引元素的累计和:", np.cumsum(a))
print("计算索引元素的累计积:", np.cumprod(a))
运行结果:
数组a: [[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]
[13 14 15 16]]
求和: 136
纵向求和: [28 32 36 40]
横向求和: [10 26 42 58]
平均值 8.5
纵向平均值: [ 7. 8. 9. 10.]
横向平均值: [ 2.5 6.5 10.5 14.5]
标准差: 4.6097722286464435
方差: 21.25
最大值: 16
最小值: 1
最小索引 0
最大索引 15
计算索引元素的累计和: [ 1 3 6 10 15 21 28 36 45 55 66 78 91 105 120 136]
计算索引元素的累计积: [ 1 2 6 24 120 720
5040 40320 362880 3628800 39916800 479001600
1932053504 1278945280 2004310016 2004189184]
恭喜你已经掌握了NumPy的精髓~

码字不易,请给博主一个小小的赞吧~