点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
为了提高模型在小物体上的性能,我们建议使用以下技术:
提高图像捕获分辨率
提高模型的输入分辨率
平铺图像
通过扩充生成更多数据
自动学习模型锚
过滤掉多余的类
为什么小目标问题很难?
小物体问题困扰着全世界的物体检测模型,查看最新模型YOLOv3、EfficientDet和YOLOv4的COCO评估结果:
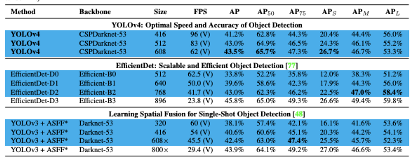
查看 AP_S、AP_M、AP_L 以获取最先进的模型。
例如,在 EfficientDet 中,小物体的 AP 仅为 12%,而大物体的 AP 为 51%,这几乎是五倍的差距!
那么为什么检测小物体这么难呢?
这一切都取决于模型,目标检测模型通过聚合卷积层中的像素来形成特征。
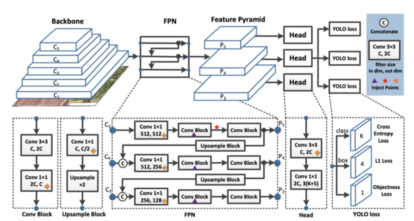
PP-YOLO中目标检测的特征聚合
并且在网络的末端,基于损失函数进行预测,该损失函数基于预测和地面真实情况之间的差异对像素进行汇总。
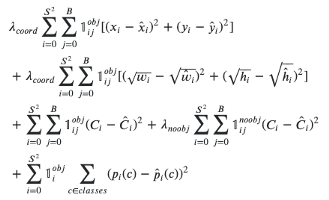
YOLO中的损失函数
如果地面真值框不大,则在进行训练时信号会很小。此外,小物体最有可能存在数据标记错误,因此它们的标识可能会被省略,从经验和理论上来说,小物体是难的。
提高图像捕获分辨率
非常小的物体在边界框中可能只包含几个像素——这意味着提高图像的分辨率以增加检测器可以从该小框中形成的特征的丰富度非常重要。因此,如果可能,我们建议尽可能捕获高分辨率的图像。
提高模型的输入分辨率
一旦我们拥有更高分辨率的图像,我们就可以扩大模型的输入分辨率。警告:这将导致大型模型需要更长的训练时间,并且在开始部署时推断速度会更慢。我们可能需要运行实验,来找出速度与性能之间的正确权衡。
在我们关于培训YOLOv4的教程中,我们可以通过更改配置文件中的图像大小来轻松调整输入分辨率。
[net]
batch=64
subdivisions=36
width={YOUR RESOLUTION WIDTH HERE}
height={YOUR RESOLUTION HEIGHT HERE}
channels=3
momentum=0.949
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue = .1
learning_rate=0.001
burn_in=1000
max_batches=6000
policy=steps
steps=4800.0,5400.0
scales=.1,.1在我们的教程中,小伙伴们还可以通过更改“训练”命令中的“图像大小”参数,轻松调整输入分辨率,该教程介绍了如何训练YOLOv5:
!python train.py --img {YOUR RESOLUTON SIZE HERE} --batch 16 --epochs 10 --data '../data.yaml' --cfg ./models/custom_yolov5s.yaml --weights '' --name yolov5s_results --cache注意:只有在达到训练数据的最大分辨率时,才能看到改进的结果。
平铺图像
检测小图像的另一种很好的策略是将图像平铺作为预处理步骤。平铺可以有效地将检测器放大到小物体上,但允许我们保持所需的小输入分辨率,以便能够进行快速推理。
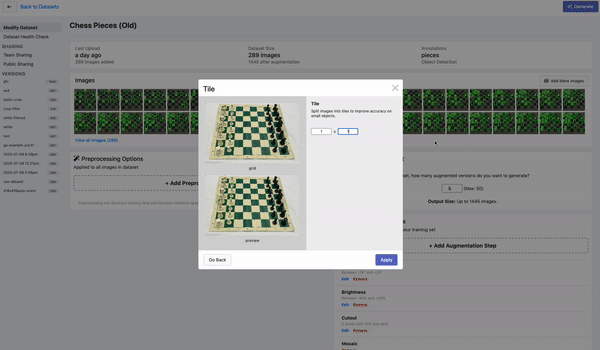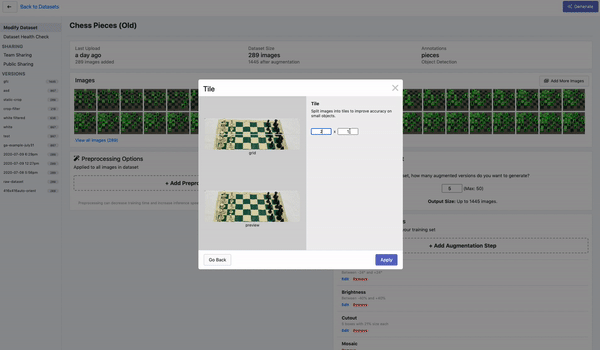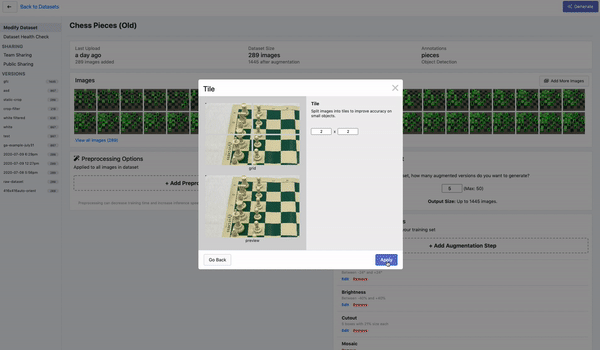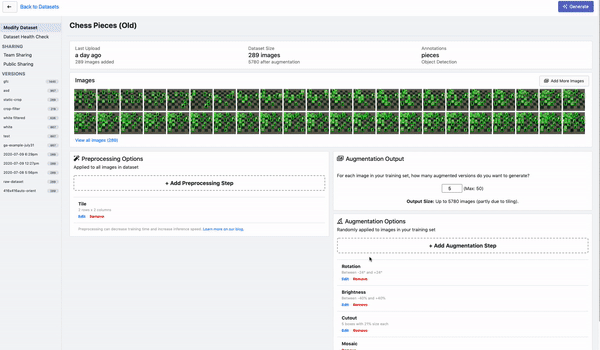 平铺图像作为 Roboflow 中的预处理步骤
平铺图像作为 Roboflow 中的预处理步骤
如果在训练期间使用平铺,请务必记住,我们还需要在推理时平铺图像。
通过扩充生成更多数据
数据扩充会从我们的基本数据集生成新图像,这对于防止模型过度拟合训练集非常有用。
一些特别有用的小物体检测增强包括随机裁剪、随机旋转和镶嵌增强。
自动学习模型锚
锚定框是模型学习预测的原型边界框,也就是说,锚框可以预先设置,有时对于我们的训练数据来说不是最理想的。自定义调整这些参数以适合我们即将完成的任务是很好的,YOLOv5 模型架构会根据我们的自定义数据自动为我们执行此操作,我们所要做的就是开始训练。
Analyzing anchors... anchors/target = 4.66, Best Possible Recall (BPR) = 0.9675. Attempting to generate improved anchors, please wait... WARNING: Extremely small objects found. 35 of 1664 labels are < 3 pixels in width or height. Running kmeans for 9 anchors on 1664 points... thr=0.25: 0.9477 best possible recall, 4.95 anchors past thr n=9, img_size=416, metric_all=0.317/0.665-mean/best, past_thr=0.465-mean: 18,24, 65,37, 35,68, 46,135, 152,54, 99,109, 66,218, 220,128, 169,228 Evolving anchors with Genetic Algorithm: fitness = 0.6825: 100%|██████████| 1000/1000 [00:00<00:00, 1081.71it/s] thr=0.25: 0.9627 best possible recall, 5.32 anchors past thr n=9, img_size=416, metric_all=0.338/0.688-mean/best, past_thr=0.476-mean: 13,20, 41,32, 26,55, 46,72, 122,57, 86,102, 58,152, 161,120, 165,20过滤掉多余的类
类管理是提高数据集质量的一项重要技术,如果我们的一个类与另一个类明显重叠,则应从数据集中过滤该类。也许,我们认为数据集中的小对象不值得检测,因此我们可能想要将其取出。通过Roboflow Pro中的高级数据集进行状况检查,我们可以快速识别所有这些问题。
可以通过Roboflow 的本体管理工具来实现类遗漏和类重命名。
结论
正确检测小物体确实是一个挑战。在这篇文章中,我们讨论了一些改进小物体检测器的策略,即:
提高图像捕获分辨率
提高模型的输入分辨率
平铺图像
通过扩充生成更多数据
自动学习模型锚
过滤掉多余的类
好消息,小白学视觉团队的知识星球开通啦,为了感谢大家的支持与厚爱,团队决定将价值149元的知识星球现时免费加入。各位小伙伴们要抓住机会哦!

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

