张士玉小黑屋
一个关注IT技术分享,关注互联网的网站,爱分享网络资源,分享学到的知识,分享生活的乐趣。
当前位置:首页 » 模型 - 第1页
YOLOX原始论文精读_ELSA001的博客
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 891次

由于最近需要对YOLOX的理论部分进行深入的理解,因此我需要查看YOLOX的相关论文,但YOLOX是最近新出的目标检测算法,但我发现我无法查看YOLOX相关的见刊论文,因此我只能好好深入理解它的原始论文。但我的理解可能比较浅薄,希望各位大佬在查看这篇文章的时候可以及时纠正我的错误。以下是旷视科技所提供的YOLOX的GitHub开源代码:Pytorch版:https://github.com/Megvii-BaseDe
效率倍增,PyCaret:一个开源、低代码的 Python 机器学习工具_Python学习与数据挖掘
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 560次

PyCaret是一个开源、低代码的Python机器学习库,可自动执行机器学习工作流。它是一种端到端的机器学习和模型管理工具,可以以指数方式加快实验周期并提高您的工作效率。欢迎收藏学习,喜欢点赞支持,文末提供技术交流群。与其他开源机器学习库相比,PyCaret是一个替代的低代码库,可用于仅用几行代码替换数百行代码。这使得实验速度和效率呈指数级增长。PyCaret本质上是围绕多个机器学习库和框架(例如sci
联邦学习:《Communication-Efficient Learning of Deep Networks from Decentralized Data》_Cyril_KI的博客
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 855次
目录前言AbstractIntroductionFederatedLearningPrivacyFederatedOptimizationTheFederatedAveragingAlgorithmExperimentalResultsIncreasingparallelismIncreasingcomputationperclientCanweover-optimizeontheclientdatasets?ConclusionsandFutureWork
R语言使用caret包构建GBM模型:在模型最优参数已知的情况下,拟合整个训练集,而无需进行任何重采样或参数调优_data+scenario+science+insight
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 470次
R语言使用caret包构建GBM模型:在模型最优参数已知的情况下,拟合整个训练集,而无需进行任何重采样或参数调优目录R语言使用caret包构建GBM模型:在模型最优参数已知的情况下,拟合整个训练集,而无需进行任何重采样或参数调优
终于有人把数据挖掘讲明白了_大数据
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 526次
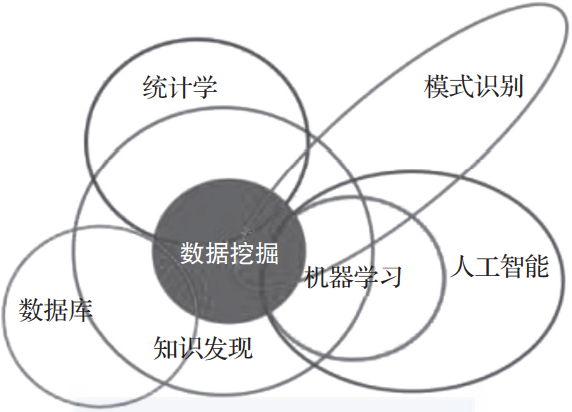
导读:数据挖掘是一种发现知识的手段。数据挖掘要求数据分析师通过合理的方法,从数据中获取与挖掘项目相关的知识。作者:赵仁乾田建中叶本华常国珍来源:大数据DT(ID:hzdashuju)数据挖掘是一个多学科交叉的产物,涉及统计学、数据库、机器学习、人工智能及模式识别等多种学科,如图1-4所示。▲图1-4数据挖掘01数据挖掘方法分类介绍数据挖掘方法按照来源进行分类显得过于庞杂,而且不便于理解和记忆。按照其目的,将数据挖掘方法分为预测性和描述性两大类,
R语言构建文本分类模型:文本数据预处理、构建词袋模型(bag of words)、构建xgboost文本分类模型、xgboost模型预测推理并使用混淆矩阵评估模型、可视化模型预测的概率分布_data+scenario+science+insight
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 460次
R语言构建文本分类模型:文本数据预处理、构建词袋模型(bagofwords)、构建xgboost文本分类模型、xgboost模型预测推理并使用混淆矩阵评估模型、可视化模型预测的概率分布目录
R语言基于自定义函数构建xgboost模型并使用LIME解释器进行模型预测结果解释:基于训练数据以及模型构建LIME解释器解释多个iris数据样本的预测结果、使用LIME解释器进行模型预测结果解释_data+scenario+science+insight
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 454次
R语言基于自定义函数构建xgboost模型并使用LIME解释器进行模型预测结果解释:基于训练数据以及模型构建LIME解释器解释多个iris数据样本的预测结果、使用LIME解释器进行模型预测结果解释并可视化目录
R语言构建logistic回归模型并使用偏差(Deviance)和伪R方(pseudo R-squared )评估概率模型:使用sigr包快速计算偏差和伪R方、AIC赤信息指标和偏差的关系_data+scenario+science+insight
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 937次
R语言构建logistic回归模型并使用偏差(Deviance)和伪R方(pseudoR-squared )评估概率模型:使用sigr包快速计算偏差(Deviance)和伪R方(pseudoR-squared )、赤信息指标(Akaikeinformationcriterion (AIC))和偏差的关系目录
超越前作,实现动漫风格迁移——AnimeGANv2_Yunlord的博客
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 653次

前言之前一直在研究如何将图像动漫化,尝试了阿里云api和百度api,效果都不尽如人意。结果发现了一个宝藏github项目——AnimeGANv2,能够将现实世界场景照片进行动漫风格化。可以看出AnimeGAN的效果非常好,而在去年九月发布的AnimeGANv2优化了模型效果,解决了AnimeGAN初始版本中的一些问题。 相比AnimeGAN,改进方向主要在以下4点:解决了生成的图像中的高频伪影问题。它易于训练,并能直接达到论文所述的效果。进一步减少生成器网络的参数数量。(现在生成器大小8.17Mb)尽可能多地使用来
Copyright © 2020-2022 ZhangShiYu.com Rights Reserved.豫ICP备2022013469号-1