张士玉小黑屋
一个关注IT技术分享,关注互联网的网站,爱分享网络资源,分享学到的知识,分享生活的乐趣。
当前位置:首页 » 《随便一记》 - 第160页
Amazon SageMaker测评分享,效果超出预期
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 556次

一、前言随着科技的进步和社会的发展,人工智能得到了愈加广泛的重视,特别是最近大火的Chatgpt,充分展现了研发通用人工智能助手广阔的研究和应用前景。让越来越多的组织和企业跟风加入到人工智能领域的研究中,但机器学习的实施是一项极其复杂的工作,不仅需要专业技能,还涉及大量的试错。无论是“专业”,抑或是“试错”,其背后都是高昂的成本。而且,通过传统的方式创建机器学习模型,开发人员需要从高度手动的数据准备过程开始,经过可视化、选择算法、设置框架、训练模型、调整数百万个可能的参数、部署模型并监视其性能,这个过程往往需要重复多次,是非常繁琐且特别耗时的。所以说,究竟有多少公司能够玩得起,想必很多人都会在心里打出一个大大的问号。最近刚好受邀参与了亚马逊云科技【云上探索实验室】活动,使用了它们推出
Unet++语义分割网络(网络结构分析+代码分析)
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 306次

1.前言许多初入视觉深度学习的小伙伴都会以图像分类网络作为入门案例来学习,个人觉得语义分割网络可以作为分类网络之后第二个学习的案例,因为其网络结构一般较为简单,只要对每个像素点进行分类即可。刚好课题组召开分享会,就和大家分享下Unet++语义分割网络。注:以下分享的许多地方是我的个人理解,可能有不恰当之处还请指出和包涵。视频和代码链接在下方。视频分享链接:课题组技术分享会-Unet++网络_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1La411U7FS/?vd_source=73870594793a8be3d80e0be8a37582d3github源码:GitHub-MrGiovanni/UNetPlusPlus:Offici
输入与输出函数—— 关于python 输入和输出你知道多少?
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 310次
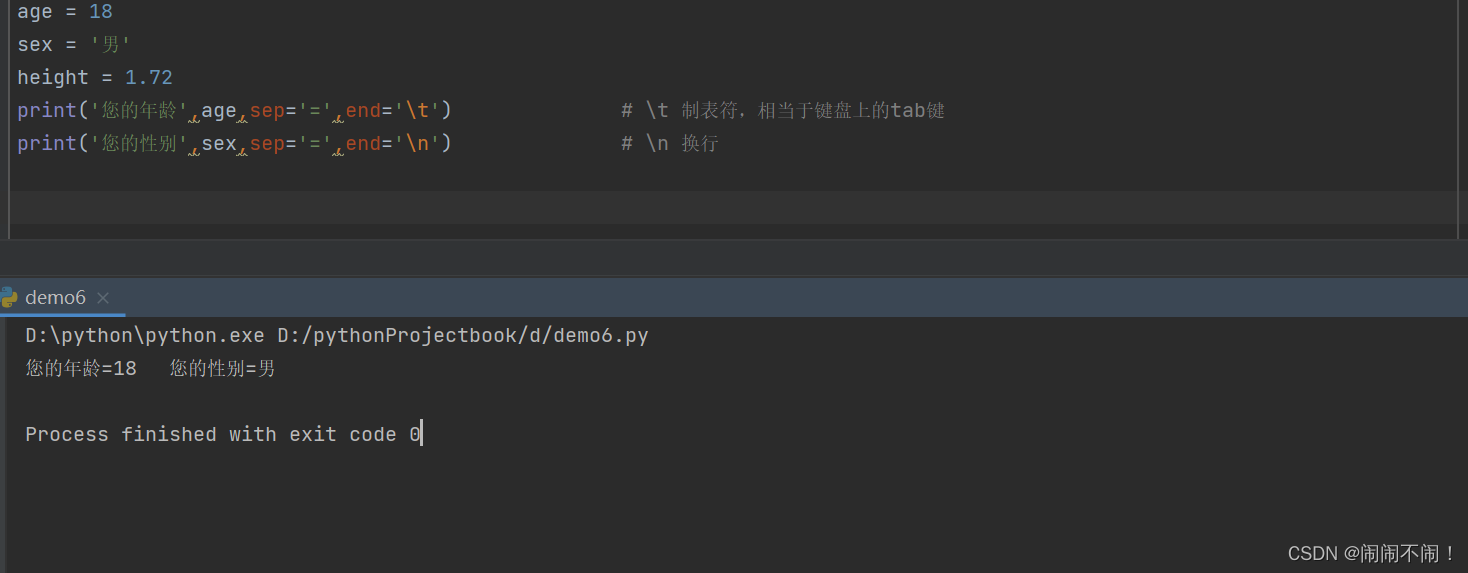
输入与输出函数——关于python输入和输出你知道多少?文章目录输入与输出函数——关于python输入和输出你知道多少?1️⃣输入print()?基本语法?%格式化?format()格式化?f-strings格式化2️⃣输入input()?数据类型转换1️⃣输入print()?基本语法print的基本语法格式⬇️print(value,…,sep="“,end=”\n",file=sys.stdout,flush=False)value:表示想要输出的数据,可以是多个数据,个数据间用逗号隔开。sep:当输出多个数据时,可以插入各个数据的分隔字符,默认是空格字符。end:当数据输出结束时所插入的字符,默认是\n换行。file:数据
Pytorch深度学习实战3-2:什么是张量?Tensor的创建与索引
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 442次

目录1什么是张量?2Pytorch数据类型与转化3张量Tensor的创建3.1类型创建3.2序列转换3.30/1张量3.4对角张量3.5正态张量3.6随机向量3.7线性张量4张量Tensor的索引4.1下标索引4.2条件索引4.3附加控制索引1什么是张量?张量(Tensor)是多维数组结构,在人工智能领域应用广泛,例如输入彩色图片即是3维张量——RGB三维且每维都是二维平面像素矩阵。下面这张表直观地总结了张量的形式,这张表可以解决大部分的张量理解问题维数图例名称0标量1向量2矩阵3三阶张量N
初识二叉树以及堆的简单实现
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 305次
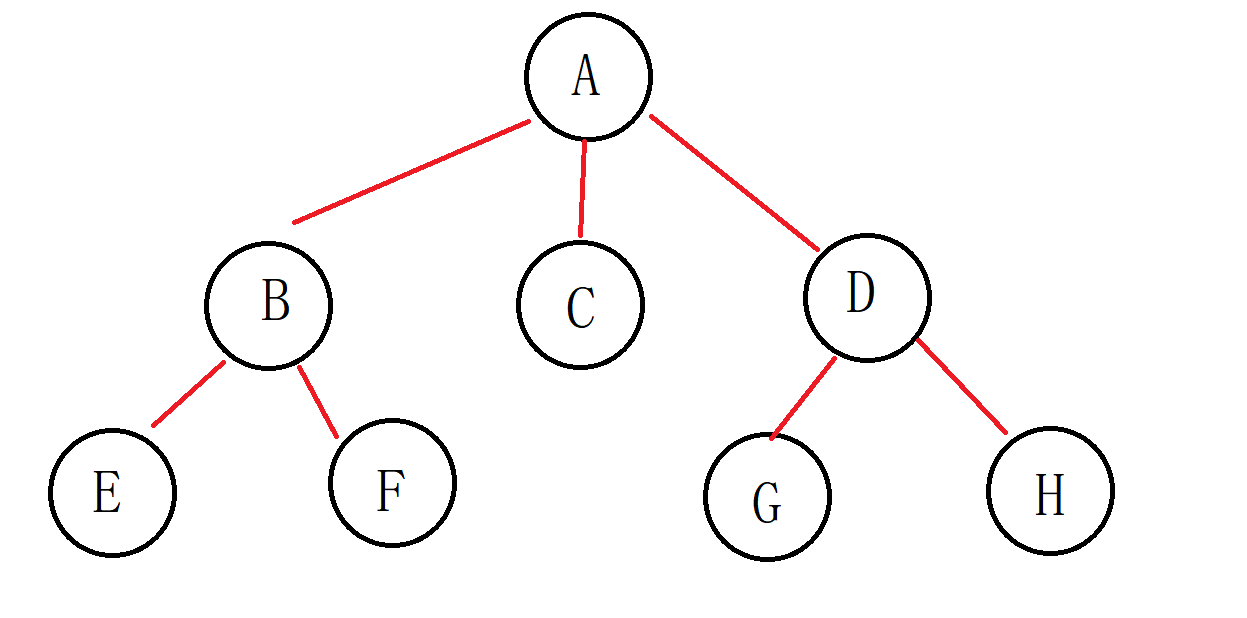
目录一:什么是树【1】树的概念【2】树的另外几个重要概念【3】树的几种表示方法二:什么是二叉树【1】概念以及特点【2】两种特殊的二叉树【3】二叉树的性质【4】二叉树的两种存储方式三:堆的实现一:什么是树【1】树的概念我们前面所学的顺序表,链表都属于线性结构,而树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。图解:(1)树有一个特殊的节点,叫根节点,在图中为结点A。(2)除根节点外,其余结点被分成M(M>0)个互不相交的集合T1、T2、……、Tm,其中每一个集合Ti(1<=i<=m)又是一棵结构与树类
超详细——动态内存分配+柔性数组
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 346次

☃️个人主页:fighting小泽?作者简介:目前正在学习C语言和数据结构?博客专栏:C语言学习?️欢迎关注:评论??点赞??留言??文章目录一.为什么存在动态内存分配二.动态内存函数的介绍2.1malloc和free2.2calloc2.3realloc三.常见的动态内存错误3.1对空指针的解引用操作3.2对动态开辟空间的越界访问3.3对非动态开辟内存进行free释放3.4动态开辟的内存没有被释放完3.5对同一块动态内存多次释放3.6动态开辟内存忘记释放(内存泄漏)四.C/C++程序的内存开辟五.柔性数组5.1柔性数组的特点5.2柔性数组的使用5.3柔性数组的优势结尾一.为什么存在动态内存分配我们已经学会的内存开辟方式有:创建一个变量
uni-app--》如何制作一个APP并使用?
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 366次
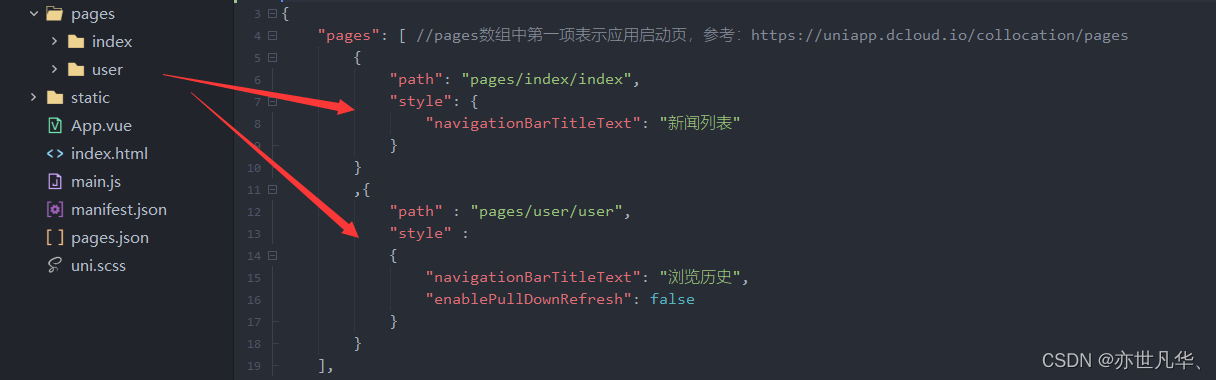
?️作者简介:大家好,我是亦世凡华、渴望知识储备自己的一名在校大学生?个人主页:亦世凡华、?系列专栏:uni-app?座右铭:人生亦可燃烧,亦可腐败,我愿燃烧,耗尽所有光芒。?引言 ⚓经过web前端的学习,相信大家对于前端开发有了一定深入的了解,今天我开设了uni-app专栏,主要想从移动端开发方向进一步发展,而对于我来说写移动端博文的第二站就是uni-app开发,希望看到我文章的朋友能对你有所帮助。目录项目搭建配置tabBar路由设置基础内容导航栏点击样式设置新闻详情页布局新闻列表数据的详细展示实现上拉触底效果获取参数并跳转到详情页项目的打包上线项目开源Github项目搭建今天实现一个简单的新闻列表的小案例,并制作成一个APP
零基础小白如何自学 Unity 游戏开发?(送 Unity 教程)
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 404次

如何自学Unity?初级阶段:学习编程语言初级阶段:编程实践中级阶段:继续学习编程语言Unity教程赠书活动内容简介作者简介赠书方式如何自学Unity?有很多同学对游戏开发很感兴趣,但都不知道从何学起,缺乏目的性,往往会走不少弯路,本文正是为了帮助大家少走弯路。“游戏开发”看似只有四个字,但涉及的内容有很多,包括UI、建模、绘画、动画系统、粒子系统、图形学、物理系统等等。内容多需要学习的知识也就多,那么学习之后如何巩固知识呢?答案就是两个字“成果”,我们在学习游戏开发的过程中必须要能够看到成果,让成果做知识的依托,其实也就是边学习、边开发,在制作一个个游戏案例的过程中来反复的巩固和补充基础知识,最终形成自己对游戏开发的全局认识。当我们接触足够多的案例、写了
多目标跟踪MOT(Multiple Object Tracking)最全综述
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 9638次
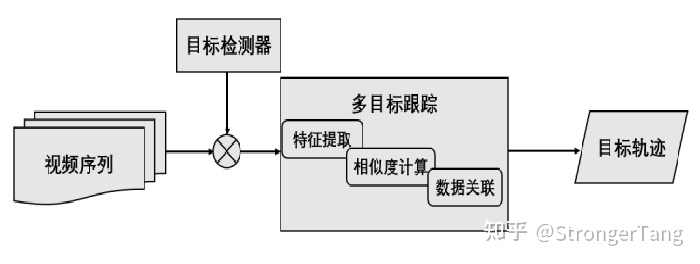
1.MOT概念多目标跟踪,一般简称为MOT(MultipleObjectTracking),也有一些文献称作MTT(MultipleTargetTracking)。在事先不知道目标数量的情况下,对视频中的行人、汽车、动物等多个目标进行检测并赋予ID进行轨迹跟踪。不同的目标拥有不同的ID,以便实现后续的轨迹预测、精准查找等工作。MOT是计算机视觉领域的一项关键技术,在自动驾驶、智能监控、行为识别等方向应用广泛。如下图所示,对于输入视频,输出目标的跟踪结果,包括目标包围框和对应的ID编号。理论上,同一个目标的ID编号保持不变。多目标跟踪中即要面对在单目标跟踪中存在的遮挡、变形、运动模糊、拥挤场景、快速运动、光照变化、尺度变化等挑战,还要面对如轨迹的初始化与终止、相似目标间的相互干扰
VIT:Transformer进军CV的里程碑
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 485次
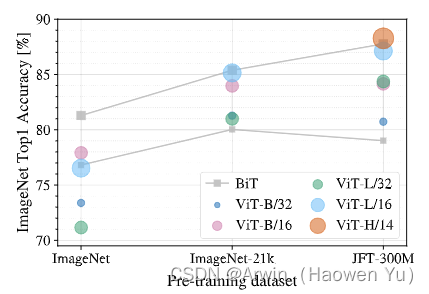
文章目录前言一、VisionTransformer1.LinearProjectionofFlattenedPatches2.TransformerEncoder3.MLPHead4.modelscaling二、HybridVisionTransformer三、总结四、引用前言Transformer[1]最初提出是针对NLP领域的,并且在NLP领域大获成功,几乎打败了RNN模型,已经成为NLP领域新一代的baseline模型。这篇论文也是受到其启发,尝试将Transformer应用到CV领域。通过这篇文章的实验,给出的最佳模型在ImageNet1K上能够达到88.55%的准确率(先在大型数据集JFT上进行了预训练),说明Transformer在CV领域确实是
search zhannei
最新文章
-
- 丁榆:结局+番外看点十足(和渣男小叔叔的游戏日常)全书无套路阅读
- 法医狂妃:王爷你命中缺我小说(苏七夜景辰)全本完整阅读最新章节(法医狂妃:王爷你命中缺我)_笔趣阁
- (头条)洛甯陆乘渊小说(闪婚老公是卧底,消失三年回来了)整本免费版阅读无广告(洛甯陆乘渊)
- 陆少今天又秀恩爱了吗后续(陆怀骁苏棠)(陆少今天又秀恩爱了吗)整本畅享在线+无广告结局
- 独家江柏俊夏清恬无删减(重生之团长俊夫要离婚)(江柏俊夏清恬)TXT免费版阅读
- 全网首发重生下乡嫁糙汉,渣男全家悔哭了彩蛋(师明凯颜惜雪)(重生下乡嫁糙汉,渣男全家悔哭了)全本完整阅读无弹窗
- 我是让他不屑一顾,不愿多看一眼的路人小说(安喻意商晋深)(我是让他不屑一顾,不愿多看一眼的路人)在线畅读阅读连载中
- 丁榆后续(和渣男小叔叔的游戏日常)全文在线下载在线+纯净版结局
- 洛甯陆乘渊::结局+番外评价五颗星-闪婚老公是卧底,消失三年回来了:结局+番外新上热文
- 前传孟流年周丽珍续集(孟流年周丽珍)终章阅读极简(孟流年周丽珍)
- 夏语栀祁墨寒我们各归人海,此生,也不必再见彩蛋小说结尾+附加(我们各归人海,此生,也不必再见)清爽版阅读
- 重生下乡嫁糙汉,渣男全家悔哭了小说完结篇(师明凯颜惜雪)(重生下乡嫁糙汉,渣男全家悔哭了)全书无套路阅读无广告小说大结局
Copyright © 2020-2022 ZhangShiYu.com Rights Reserved.豫ICP备2022013469号-1