1. 前言
许多初入视觉深度学习的小伙伴都会以图像分类网络作为入门案例来学习,个人觉得语义分割网络可以作为分类网络之后第二个学习的案例,因为其网络结构一般较为简单,只要对每个像素点进行分类即可。刚好课题组召开分享会,就和大家分享下Unet++语义分割网络。注:以下分享的许多地方是我的个人理解,可能有不恰当之处还请指出和包涵。视频和代码链接在下方。
视频分享链接:课题组技术分享会-Unet++网络_哔哩哔哩_bilibili https://www.bilibili.com/video/BV1La411U7FS/?vd_source=73870594793a8be3d80e0be8a37582d3
https://www.bilibili.com/video/BV1La411U7FS/?vd_source=73870594793a8be3d80e0be8a37582d3
github源码:GitHub - MrGiovanni/UNetPlusPlus: Official Keras Implementation for UNet++ in IEEE Transactions on Medical Imaging and DLMIA 2018 https://github.com/MrGiovanni/UNetPlusPlus
https://github.com/MrGiovanni/UNetPlusPlus
2. 网络结构和思想
2.1 什么是语义分割
首先明白什么是语义分割,语义分割是对同一种类的物体进行提取,以掩码图的形式输出分割的结果。相比实例分割,它只能提取一个种类,而不能在同一个类中区分出不同的个体。可以简单理解为:实例分割=语义分割+目标检测。

2.2 传统语义分割
下图为一种非常经典的语义分割网络,backbone提取完特征,通过反卷积变回原图尺寸,然后对每个像素点分类,输出结果。
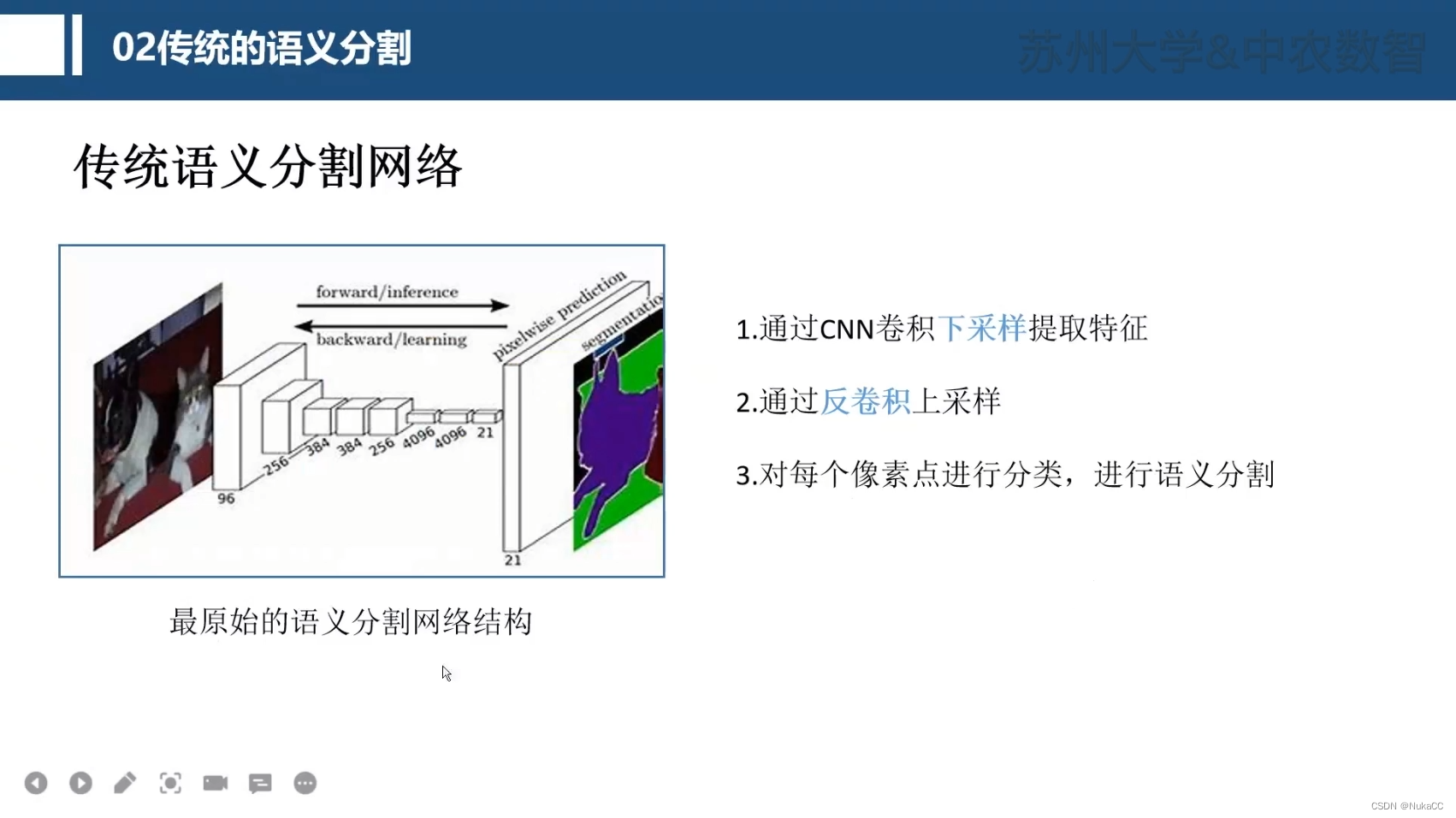
2.3 进阶语义分割
下图为进阶的语义分割,主要不同之处在于会将不同尺寸不同阶段的特征图进行融合,提升分割效果。
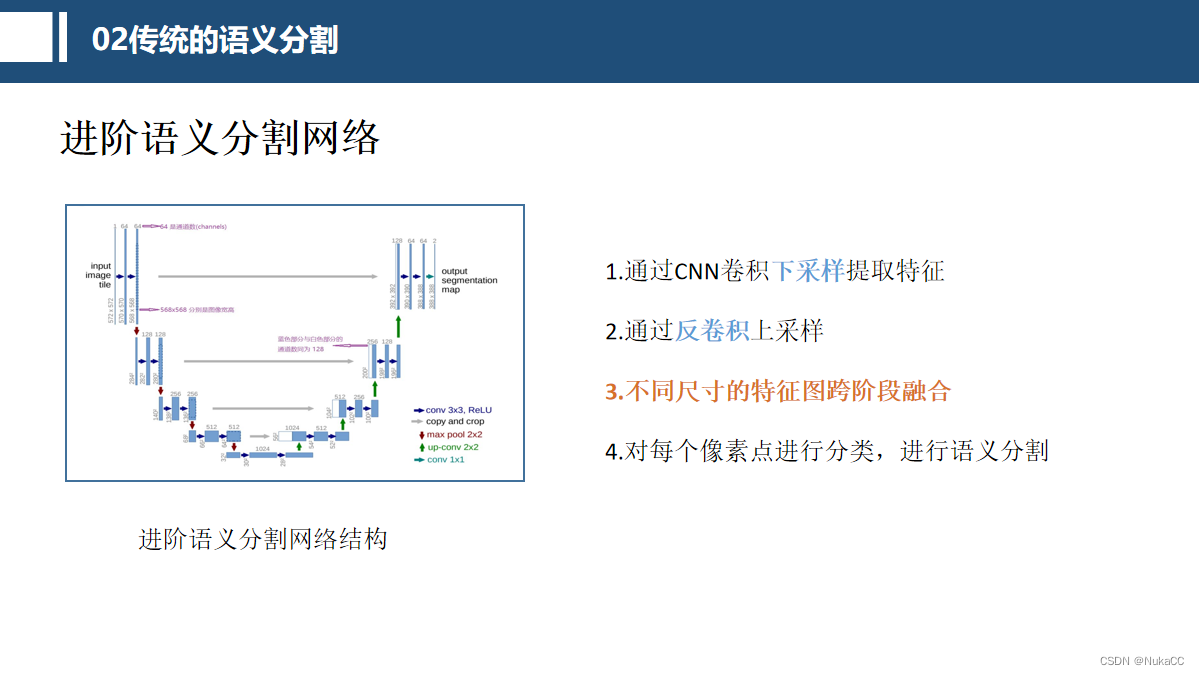
那么问题来了,为什么要多个特征图融合呢?原因在于卷积网络的浅层提供了纹理特征,深层提供了丰富的语义信息,两者都有用。拿下面ppt的问题类比一下,假设目前给你提供一个信息,一个目标有鼻子、 眼睛、耳朵、四肢,该目标最大可能性是什么?

有人可能会回答是人,但正如下面ppt所示,事实情况也可能是猩猩或者猴子或者其他小动物。我们不能判断的原因在于只用了语义信息而没用纹理信息。

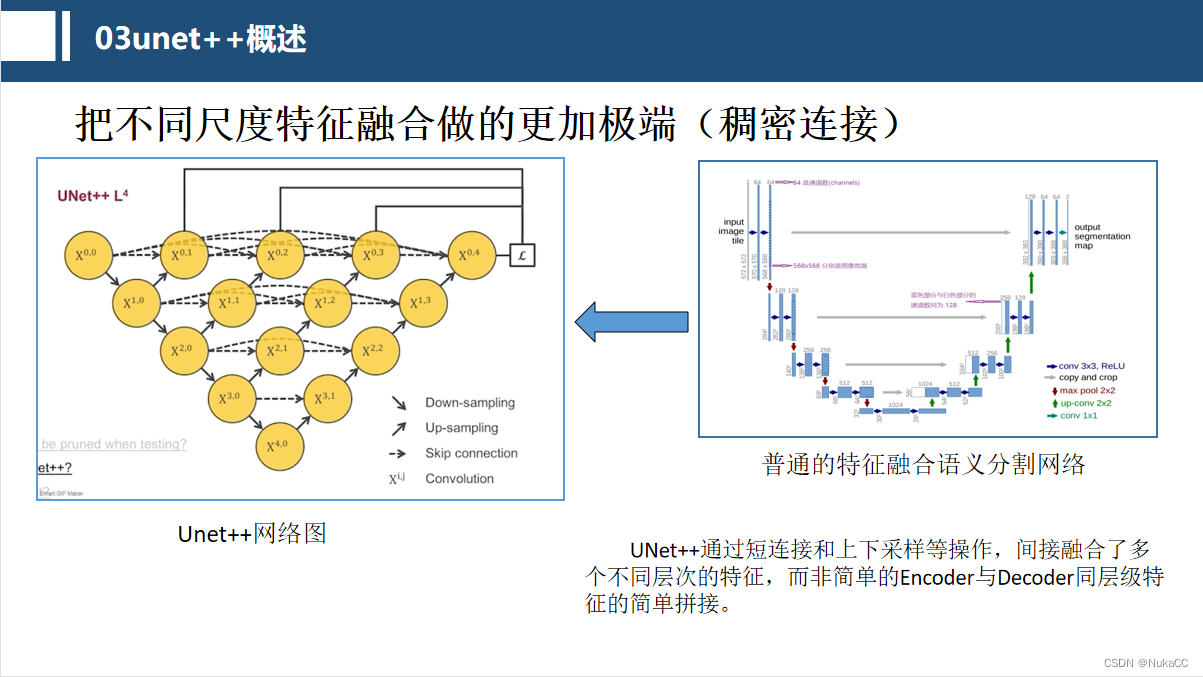
2.4 Unet++特性
上面提到了特征跨阶段融合的意义,接下去就不难理解UNet++网络结构为什么要这样做了。UNet++通过短连接和上下采样等操作,间接融合了多个不同层次的特征,而非简单的Encoder与Decoder同层级特征的简单拼接。从其网络特征来看,就像织了一张网一样,将特征融合做到了极致,用专业的术语来说就是稠密连接。
3. 代码讲解
代码讲解在视频里面,视频已经发布,在如下链接里。视频是课题组分享会录制的,里面不仅有Unet++网络结构的讲解,还有很多通用的pytorch代码讲解,创作不易,欢迎一键三连噢(●'◡'●)。注:视频里的代码是其他up主提供的注释版。
课题组技术分享会-Unet++网络_哔哩哔哩_bilibili https://www.bilibili.com/video/BV1La411U7FS/?vd_source=73870594793a8be3d80e0be8a37582d3
https://www.bilibili.com/video/BV1La411U7FS/?vd_source=73870594793a8be3d80e0be8a37582d3
4. 总结
Unet++是一个非常经典又易于学习的网络,非常值得前期研究一下。