1.MOT概念
多目标跟踪,一般简称为MOT(Multiple Object Tracking),也有一些文献称作MTT(Multiple Target Tracking)。在事先不知道目标数量的情况下,对视频中的行人、汽车、动物等多个目标进行检测并赋予ID进行轨迹跟踪。不同的目标拥有不同的ID,以便实现后续的轨迹预测、精准查找等工作。
MOT是计算机视觉领域的一项关键技术,在自动驾驶、智能监控、行为识别等方向应用广泛。如下图所示,对于输入视频,输出目标的跟踪结果,包括目标包围框和对应的ID编号。理论上,同一个目标的ID编号保持不变。
多目标跟踪中即要面对在单目标跟踪中存在的遮挡、变形、运动模糊、拥挤场景、快速运动、光照变化、尺度变化等挑战,还要面对如轨迹的初始化与终止、相似目标间的相互干扰等复杂问题。因此,多目标跟踪当前仍然是图像处理中的一个极具挑战性的方向,吸引了不少研究人员的长期投入。
MOT 获取单个连续视频并以特定帧速率 (fps) 将其拆分为离散帧以输出。
检测每帧中存在哪些对象
标注对象在每一帧中的位置
关联不同帧中的对象是属于同一个对象还是属于不同对象
2.研究难点
目标跟踪是一个早已存在的方向,但之前的研究主要集中于单目标跟踪,直到近几年,多目标跟踪才得到研究者的密切关注。与其它计算机视觉任务相比,多目标跟踪任务主要存在以下研究难点:
准确的对象检测的问题是未能检测到对象或者为检测到的对象分配错误的类别标签或错误地定位已识别的对象:
ID Switching发生在两个相似的物体重叠或混合时,导致身份切换;因此,很难跟踪对象 ID。
背景失真:复杂的背景使得在物体检测过程中难以检测到小物体
遮挡:对象被另一个对象隐藏或遮挡时会产生这个问题。
多个空间空间、变形或对象旋转
由于运动模糊而在相机上捕获的视觉条纹或拖尾
一个好的MOT
通过在每帧的精确位置识别正确数量的跟踪器来跟踪对象。
通过长期一致地跟踪单个对象来识别对象,
尽管有遮挡、照明变化、背景、运动模糊等,仍可跟踪对象。
快速检测和跟踪物体
3.研究方法
视觉目标跟踪的发展相对较短,主要集中在近十余年。早期比较经典的方法有Meanshift和粒子滤波等方法,但整体精度较低,且主要为单目标跟踪。
近五六年来,随着目标检测的性能得到了飞跃式进步,也诞生了基于检测进行跟踪的方案,并迅速成为当前多目标跟踪的主流框架,极大地推动了MOT任务的前进。同时,近期也出现了基于检测和跟踪联合框架以及基于注意力机制的框架,开始引起研究者们的注意力。
3.1基于Tracking-by-detection的MOT
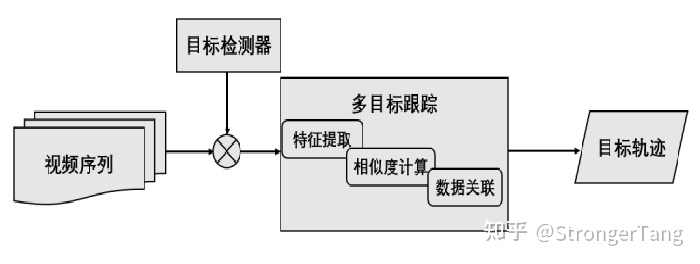 基于Tracking-by-detaction框架的MOT算法是先对视频序列的每一帧进行目标检测,根据包围框对目标进行裁剪,得到图像中的所有目标。然后,转化为前后两帧之间的目标关联问题,通过IoU、外观等构建相似度矩阵,并通过匈牙利算法、贪婪算法等方法进行求解。
基于Tracking-by-detaction框架的MOT算法是先对视频序列的每一帧进行目标检测,根据包围框对目标进行裁剪,得到图像中的所有目标。然后,转化为前后两帧之间的目标关联问题,通过IoU、外观等构建相似度矩阵,并通过匈牙利算法、贪婪算法等方法进行求解。
代表方法:SORT、DeepSORT
3.2 基于检测和跟踪联合的MOT
JDE采用FPN结构,分别从原图的 1/8,1/16 和 1/32 三个尺度进行预测。在这三个不同尺度的输出特征图上分别加入预测头(prediction head),每个预测头由几层卷积层构成,并输出大小为 (6A+D)×H×W 的特征向量。其中 A 为对应尺度下设置的锚框的数量,D 是外观特征的维度。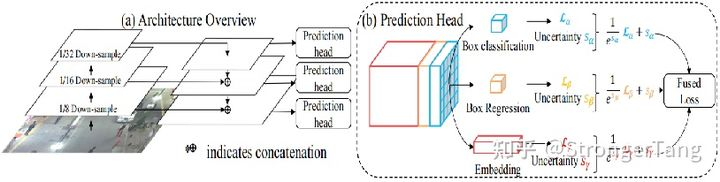
JDE在MOT16测试集上MOTA=64.4%,GPU环境下,高分辨率输入图像下FPS达到22.2,低分辨率输入图像下FPS达到30.3,是第一个接近实时的多目标跟踪算法。
代表方法:JDE、FairMOT、CenterTrack、ChainedTracker等
3.3 基于注意力机制的MOT
随着Transformer[42]等注意力机制在计算机视觉中的应用火热,近期开始有研究者提出了基于注意力机制的多目标跟踪框架,目前主要有TransTrack[43]和TrackFormer[44],这两项工作都是将Transformer应用到MOT中。
TransTrack将当前帧的特征图作为Key,将前一帧的目标特征Query和一组从当前帧学习到的目标特征Query一起作为整个网络的输入Query。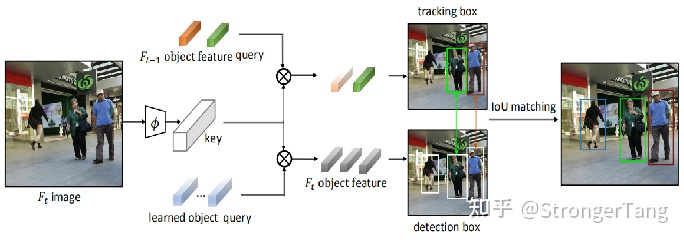
代表方法:TransTrack、TrackFormer等
3.4FairMOT
FairMOT 不使用首先检测对象及其边界框,然后进行对象跟踪的多任务方法,如 SORT 和 Deep SORT。FairMOT 认为网络偏向于主要检测任务,这对 re-ID 或对象跟踪任务是不公平的。
在 FairMOT 中,对象检测和重新识别任务得到同等对待。
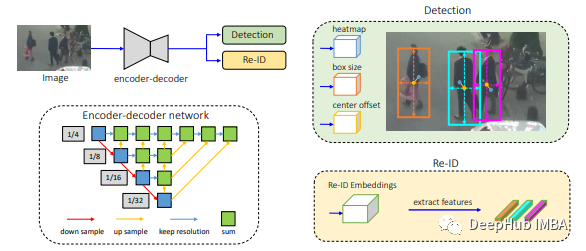
输入图像被馈送到编码器-解码器网络以提取高分辨率特征图。
FairMOT 然后添加了两个同质分支,用于检测对象和提取 re-ID 特征,以获得检测和 re-ID 之间的良好折衷。
3.5BytrTrack
ByteTrack 使用高性能 YOLOX 对视频执行 MOT,并使用 BYTE 执行检测框和轨道之间的关联。
BYTE 保留所有检测框并将它们分为高分(Dʰᶦᵍʰ)和低分(Dˡᵒʷ)。使用卡尔曼滤波器来预测 T 中每个轨道的当前帧中的新位置。
BYTE 中的第一个关联是在高分检测框 Dʰᶦᵍʰ 与所有 tracklets 之间执行的。第一个关联的相似性是使用 IoU 或检测框 Dʰᶦᵍʰ 与轨道的预测框 T 之间的 Re-ID 特征距离计算的。
一些 tracklet 无法匹配是因为它们与适当的高分检测框 Dʰᶦᵍʰ 不匹配,这在发生遮挡、运动模糊或大小变化时发生。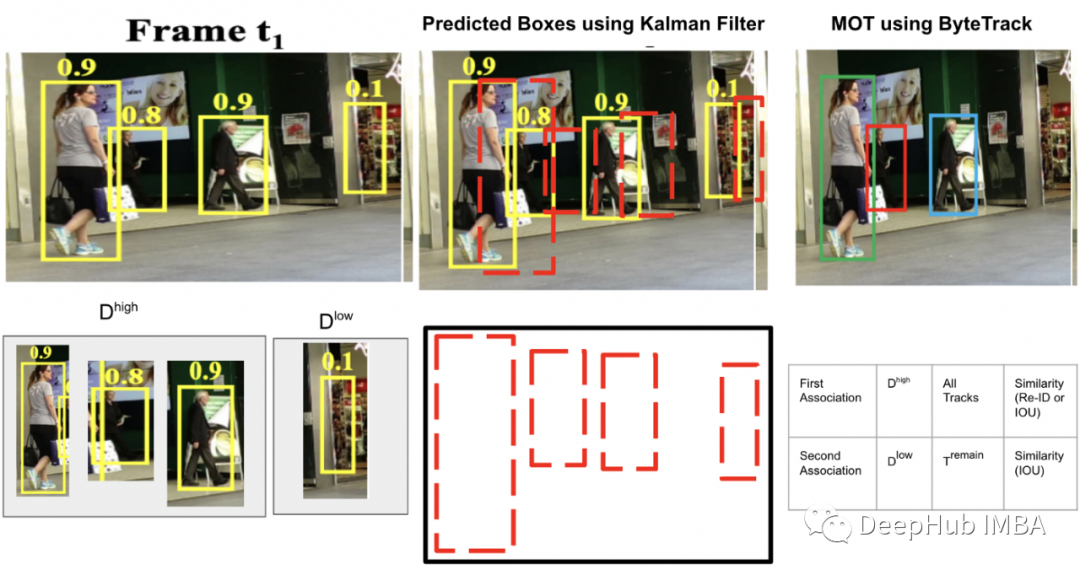
第二次关联是在低分检测框 Dˡᵒʷ 与剩余的未匹配轨迹 (Tʳᵉᵐᵃᶤⁿ) 之间的第一次关联之后执行的,这样可以恢复低分检测框中的对象并过滤掉背景。
将不匹配的目标保留在 Tʳᵉ-ʳᵉᵐᵃᶤⁿ 中,并删除所有不匹配的低分检测框,因为它们被视为背景。
4.评价指标
经过不断完善,目前形成了一组多目标跟踪专用评估指标[63-64]。具体定义及计算公式如下:
1)FP:False Positive,即真实情况中没有,但跟踪算法误检出有目标存在。
2)FN:False Negative,即真实情况中有,但跟踪算法漏检了。
3)IDS:ID Switch,目标ID切换的次数。
4)MOTA: Multiple Object Tracking Accuracy,多目标跟踪准确度。MOTA 是最广泛使用的指标,可以密切代表人类视觉评估。在 MOTA 中,匹配是在检测级别完成的。在 MOTA 中使用身份切换 (IDSW) 测量关联,当跟踪器错误地交换对象身份或轨道丢失并使用不同的身份重新初始化时,就会发生关联。MOTA 测量三种类型的跟踪错误:False Positive, False Negative, and ID Switch
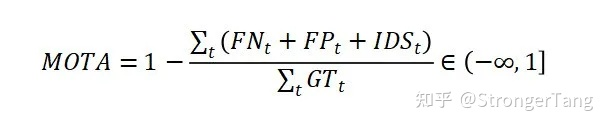
MOTA可以较好地反映跟踪准确度,是当前MOT的主要评估指标。但MOTA不能反映MOT算法对同一个目标轨迹长时间跟踪性能表现。
5)IDF1: ID F1得分,正确身份标签赋予的检测框与平均ground truth和计算的检测数量的比值。IDF1 强调关联准确性而不是检测。IDF1 使用 IDTP(Identity True Positives),其中当 S ≥ α 的轨迹时,prID 与 grID 匹配。IDF1 是正确识别的检测与地面实况和计算检测的平均数量之比。匈牙利算法选择要匹配的轨迹以最小化 IDFP 和 IDFN 的总和。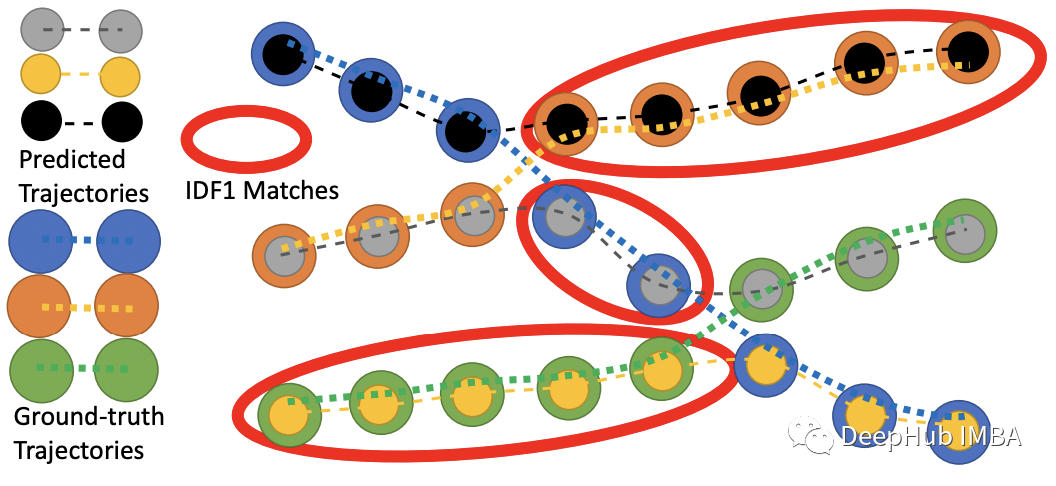
IDF1 结合了 IDP(ID Precision) 和 IDR(ID Recall)。
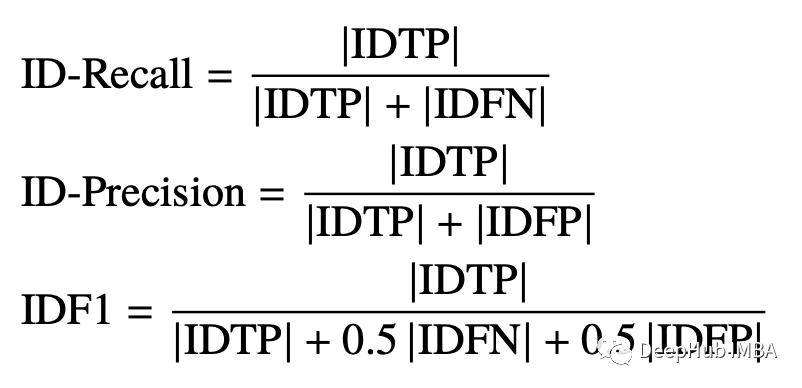
6)MT:Mostly Tracked,大多数目标被跟踪的轨迹数量。目标被成功跟踪到的轨迹长度与轨迹总长度的比值大于等于80%的轨迹数量。
7)ML:Mostly Lost,大多数目标被跟丢的轨迹数量。目标被成功跟踪到的轨迹长度与轨迹总长度的比值小于等于20%的轨迹数量。
8)MOTP:Multiple Object Tracking Precision,多目标跟踪精度。表示得到的检测框和真实标注框之间的重合程度。
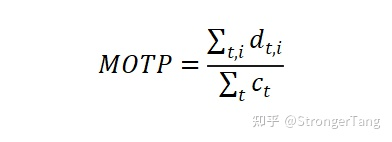
9)FPS:Frames Per Second,每秒处理的帧数。
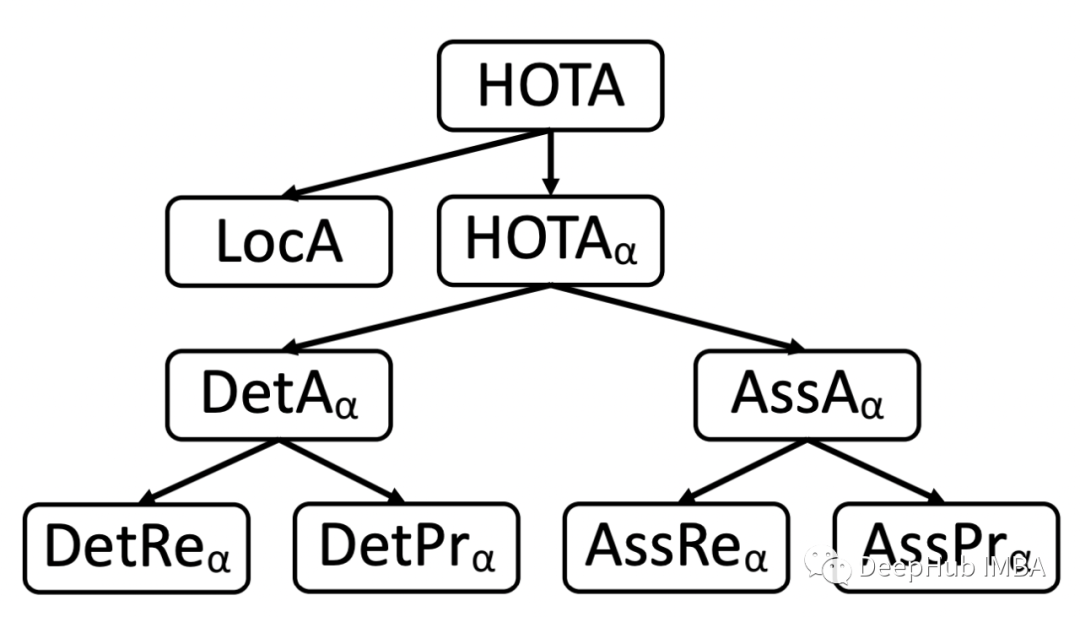
10) HOTA:高阶跟踪精度
HOTA 是用于对跟踪器进行排名的统一度量标准。HOTA 可以分解为对应这五种错误类型的组件:Detection Recall、Detection Precision、Association Recall、Association Precision 和 Localization Accuracy。因此,HOTA 的错误类型是可微的并且是严格单调的,提供有关跟踪器在每种不同基本错误类型方面的性能信息。
HOTA 跟踪错误分为检测错误、关联错误和定位错误。
当跟踪器预测到不存在的检测或未能预测目标的检测时,就会发生检测错误。检测误差可以进一步分为检测召回率(由 FNs 衡量)和检测精度(由 FPs 衡量)
当跟踪器将相同的 prID 分配给具有不同 gtID 的两个检测或将不同的 prID 分配给应该具有相同 gtID 的两个检测时,会发生关联错误。关联误差进一步分为关联召回误差(由 FNA 测量)和关联精度(由 FPA 测量)
当 prDets 在空间上与 gtDets 不完全对齐时,就会发生定位错误。
MOTA 在局部检测级别执行匹配和关联评分,但强调检测精度,而 IDF1 通过强调关联效果在轨迹级别执行。
Track-mAP 类似于 IDF1,因为它在轨迹级别执行匹配和关联,并且偏向于测量关联。
HOTA 通过在检测级别执行匹配,同时在轨迹上对关联进行全局评分,通过作为检测分数和关联分数的显式组合来平衡两者。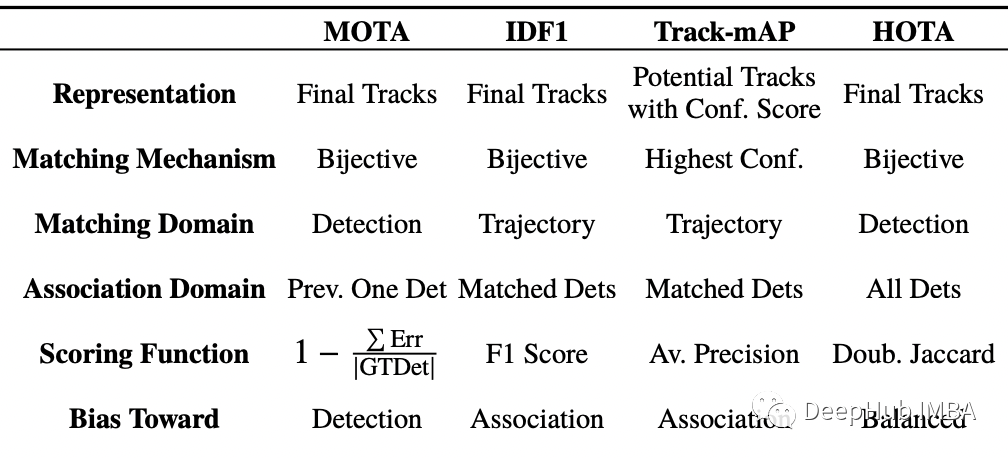
5.多目标追踪的主要步骤
获取原始视频帧利用目标检测器对视频帧中的目标进行检测将检测到的目标的框中的特征提取出来,该特征包括表观特征(方便特征对比避免ID switch)和运动特征(运动特征方便卡尔曼滤波对其进行预测)计算前后两帧目标之前的匹配程度(利用匈牙利算法和级联匹配),为每个追踪到的目标分配ID。5.1 sort流程
Deepsort的前身是sort算法,sort算法的核心是卡尔曼滤波算法和匈牙利算法。
卡尔曼滤波算法作用:该算法的主要作用就是当前的一系列运动变量去预测下一时刻的运动变量,但是第一次的检测结果用来初始化卡尔曼滤波的运动变量。
匈牙利算法的作用:简单来讲就是解决分配问题,就是把一群检测框和卡尔曼预测的框做分配,让卡尔曼预测的框找到和自己最匹配的检测框,达到追踪的效果。
SORT 方法假设跟踪质量取决于对象检测性能。SORT 首先使用 Faster Region-CNN (FrRCNN) 检测对象。
通过预测其在当前帧中的新位置来更新使用卡尔曼滤波框架优化解决的目标状态,将对象检测与检测到的边界框相关联。
为每个检测分配Cost矩阵来计算与来自现有目标的所有预测边界框之间的交并联合(IOU)距离。使用匈牙利算法解决分配问题。
SORT算法有助于减少遮挡目标,当物体运动较小时,Id切换效果很好。SORT 在具拥挤场景和快速运动的情况下可能会失败
sort工作流程如下图所示:
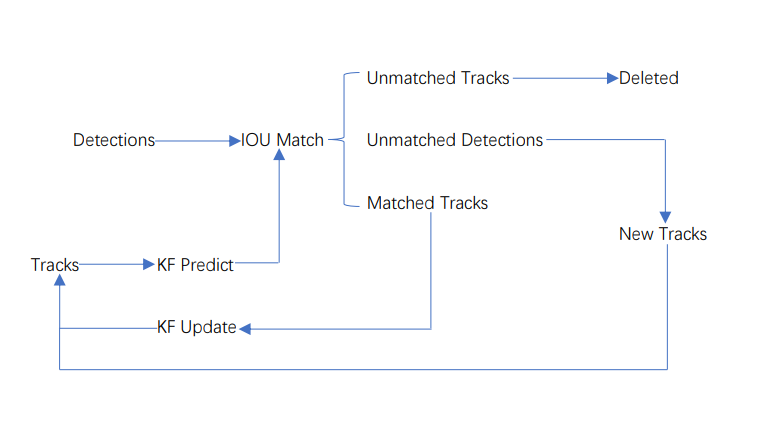
Detections是通过目标检测到的框框。Tracks是轨迹信息。
整个算法的工作流程如下:
(1)将第一帧检测到的结果创建其对应的Tracks。将卡尔曼滤波的运动变量初始化,通过卡尔曼滤波预测其对应的框框。
(2)将该帧目标检测的框框和上一帧通过Tracks预测的框框一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(3)将(2)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(4)反复循环(2)-(3)步骤,直到视频帧结束。
5.2 Deepsort
由于sort算法还是比较粗糙的追踪算法,当物体发生遮挡的时候,特别容易丢失自己的ID。而Deepsort算法在sort算法的基础上增加了级联匹配(Matching Cascade)和新轨迹的确认(confirmed)。Tracks分为确认态(confirmed),和不确认态(unconfirmed),新产生的Tracks是不确认态的;不确认态的Tracks必须要和Detections连续匹配一定的次数(默认是3)才可以转化成确认态。确认态的Tracks必须和Detections连续失配一定次数(默认30次),才会被删除。
Deep SORT:Deep SORT 是 SORT 的扩展,允许通过更长时间的遮挡进行跟踪,实现简单并且可以实时运行。
Deep SORT采用单一的传统假设跟踪方法,具有递归卡尔曼滤波和使用匈牙利算法的逐帧数据关联。
外观特征描述了给定图像的所有特征。Deep SORT 还利用类似于 SORT 的匹配级联来对更常见的对象进行优先级排序。
Deep SORT 减少了 ID 切换和遮挡,从而降低了误报率。
Deepsort算法的工作流程如下图所示: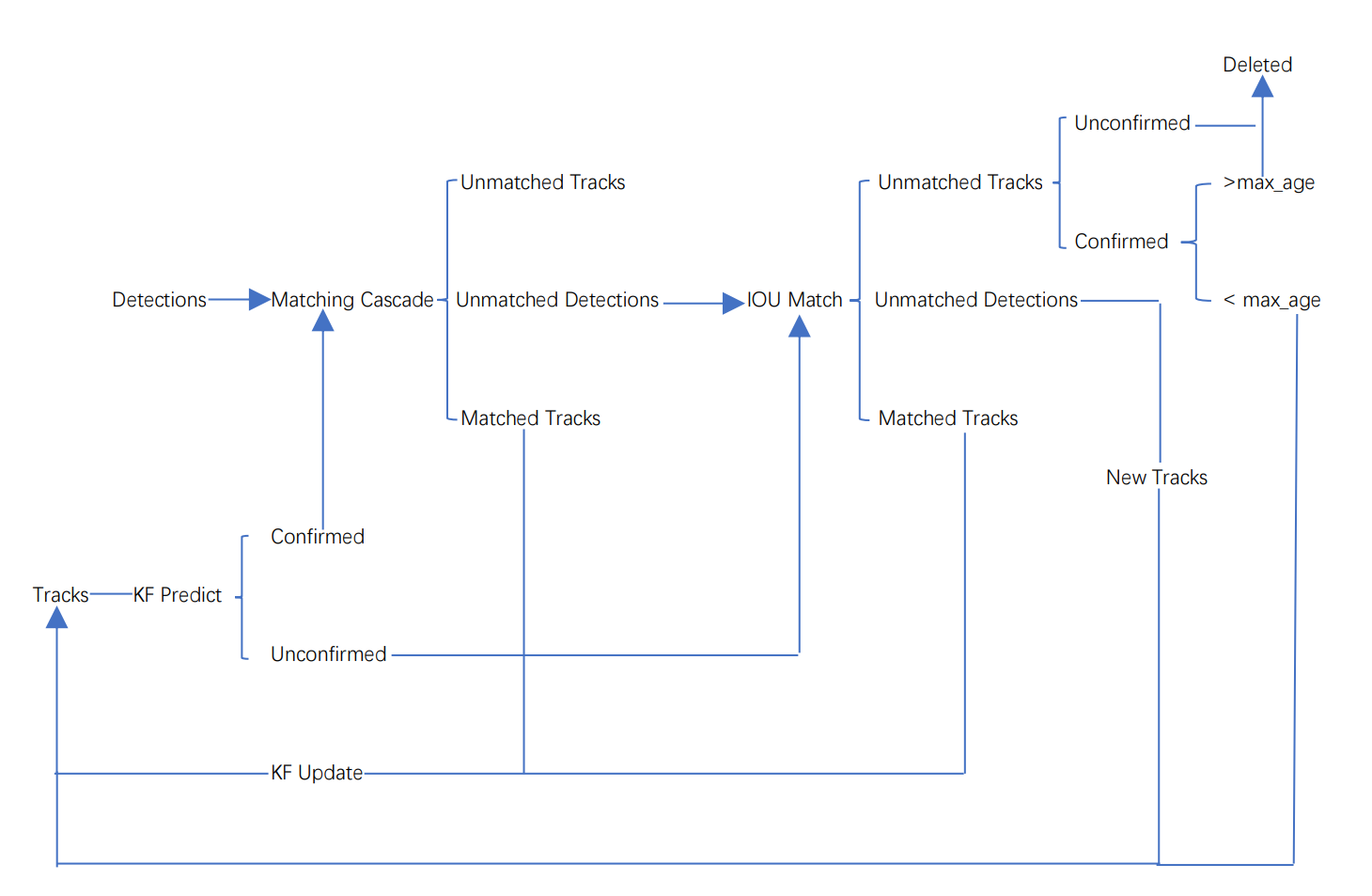
整个算法的工作流程如下:
(1)将第一帧次检测到的结果创建其对应的Tracks。将卡尔曼滤波的运动变量初始化,通过卡尔曼滤波预测其对应的框框。这时候的Tracks一定是unconfirmed的。
(2)将该帧目标检测的框框和第上一帧通过Tracks预测的框框一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(3)将(2)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks(因为这个Tracks是不确定态了,如果是确定态的话则要连续达到一定的次数(默认30次)才可以删除)删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(4)反复循环(2)-(3)步骤,直到出现确认态(confirmed)的Tracks或者视频帧结束。
(5)通过卡尔曼滤波预测其确认态的Tracks和不确认态的Tracks对应的框框。将确认态的Tracks的框框和是Detections进行级联匹配(之前每次只要Tracks匹配上都会保存Detections其的外观特征和运动信息,默认保存前100帧,利用外观特征和运动信息和Detections进行级联匹配,这么做是因为确认态(confirmed)的Tracks和Detections匹配的可能性更大)。
(6)进行级联匹配后有三种可能的结果。第一种,Tracks匹配,这样的Tracks通过卡尔曼滤波更新其对应的Tracks变量。第二第三种是Detections和Tracks失配,这时将之前的不确认状态的Tracks和失配的Tracks一起和Unmatched Detections一一进行IOU匹配,再通过IOU匹配的结果计算其代价矩阵(cost matrix,其计算方式是1-IOU)。
(7)将(6)中得到的所有的代价矩阵作为匈牙利算法的输入,得到线性的匹配的结果,这时候我们得到的结果有三种,第一种是Tracks失配(Unmatched Tracks),我们直接将失配的Tracks(因为这个Tracks是不确定态了,如果是确定态的话则要连续达到一定的次数(默认30次)才可以删除)删除;第二种是Detections失配(Unmatched Detections),我们将这样的Detections初始化为一个新的Tracks(new Tracks);第三种是检测框和预测的框框配对成功,这说明我们前一帧和后一帧追踪成功,将其对应的Detections通过卡尔曼滤波更新其对应的Tracks变量。
(8)反复循环(5)-(7)步骤,直到视频帧结束。
5.3strongsort
现有的多目标跟踪(MOT)方法可以大致分为tracking-by-detection 和 joint-detection-association范式。虽然后者引起了更多的关注,并表现出与前者相当的性能,但我们认为,tracking-by-detection范式仍然是跟踪精度方面的最优解决方案。在本文中,我们回顾了经典的跟踪器DeepSORT,并从检测、嵌入和关联等各个方面对其进行了升级。由此产生的跟踪器,被称为StrongSORT,在MOT17和MOT20上设置了新的HOTA和IDF1记录。我们还提出了两种轻量级和即插即用的算法来进一步细化跟踪结果。首先,提出了一种无外观链路模型(AFLink),将短轨迹与完整轨迹相结合。
首先,提出了一种无外观链路模型(AFLink),将短的轨迹与完整的轨迹关联起来。这是第一个没有外观信息的全局链接模型。其次,我们提出了高斯平滑插值(GSI)来补偿缺失的检测。GSI基于高斯过程回归算法忽略运动信息,而不是忽略线性插值,可以实现更准确的定位。此外,AFLink和GSI可以插入到各种跟踪器中,而额外的计算成本可以忽略不计。
joint-detection-association联合框架中存在两个问题:(1)对不同任务组件之间的不兼容(2)对联合训练这些任务组件的有限数据。虽然已经提出了几种策略来解决这些问题,但这些问题仍然降低了跟踪精度的上界。相反,tracking-by-detection的潜力似乎被低估了。
Review of DeepSORT
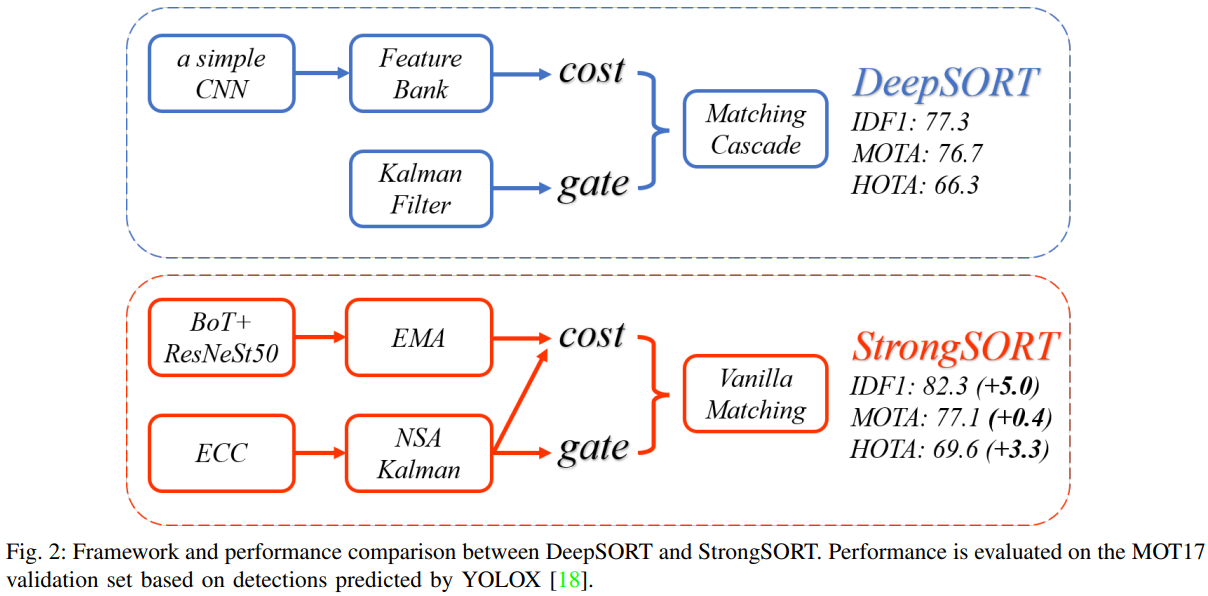
将DeepSORT简要地总结为一个有两个分支的框架,即外观分支和运动分支,如图2的上半部分所示。
在外观分支中,给定每一帧的检测,应用Re-ID数据集MARS上预训练的深度外观descriptor (a simple CNN)来提取它们的外观特征。它利用一个特征集合来存储每个轨迹集的最后100帧的特征。
在运动分支中,卡尔曼滤波算法用于预测轨迹在当前帧中的位置。然后,利用马氏距离来测量轨迹和探测之间的时空差异。DeepSORT将这个运动距离来过滤掉不太可能的关联。
然后,提出匹配级联算法,将关联任务作为一系列子问题,而不是全局分配问题。其核心思想是给予更常见的物体更大的匹配优先级。每个关联子问题都使用匈牙利算法来解决。
6.MOT数据集
6.1数据集的使用
挑战更高难度的多目标跟踪,MOT20数据集使用指南_OpenDataLab的博客-CSDN博客 https://blog.csdn.net/OpenDataLab/article/details/125408125
https://blog.csdn.net/OpenDataLab/article/details/125408125
6.2多目标跟踪指标评测
多目标跟踪数据集 :mot16、mot17数据集介绍以及多目标跟踪指标评测_一个小呆苗的博客-CSDN博客 https://blog.csdn.net/weixin_55775980/article/details/124369512
https://blog.csdn.net/weixin_55775980/article/details/124369512