文章目录
- 前言
- 一、对论文训练好的模型进行测试
- 1.1嵌入信息(Encoder部分)
- 1.2 提取信息(Decoder部分)
- 二、自己数据集训练模型
- 2.1 小数据集-50张
- 2.2 大数据集-25002张
- 三、避坑指南
- 总结
前言
跑通CVPR2020的一篇关于图像隐藏论文的代码,整理一些避坑信息。有需要修改后跑通的源码请在评论区留言,一键三连,不胜感激。
Tancik M, Mildenhall B, Ng R. Stegastamp: Invisible hyperlinks in physical photographs[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 2117-2126. [PDF] [Github官方Code]
一、对论文训练好的模型进行测试
1.1嵌入信息(Encoder部分)
由于论文提供的开源代码很详细,除了配置环境有点难度,其他均可按照官方文件进行即可,运行过程中会遇到一些环境和调用包的问题,通过百度均可解决,为了能快速得到论文中的结果,我已经将代码进行了整理,并在下面详细说明一下操作。
首先从官方代码下载文件[Github官方Code],下载预先训练好的模型(预训练模型下载),保存到文件夹saved_models/stegastamp_pretrained下面,需要嵌入信息的图像保存在imgs/1.png,嵌入信息后的图像保存在 out/ 下面,嵌入的信息为Hello
在Pycharm的终端中运行如下代码:
python encode_image.py --model saved_models/stegastamp_pretrained --image imgs/1.png --save_dir out/ --secret Hello
运行之后会得到嵌入信息之后的图像和原始图像和嵌入信息图像之间的差别图像。



从左到右依次是原始图像,添加信息Hello的图像和两者的差别图像。由上图可知,添加信息之后的图像几乎于原始图像无差别,肉眼很难分辨两者的不同,最后一张展示了两者细微上的差别,并且是放大10倍之后的,如果没有放大,几乎看不出来。
1.2 提取信息(Decoder部分)
提取信息的部分只针对1.1中已经嵌入水印的图像有用,没有嵌入水印图像的无法提取,因为模型设置了一个判别器,无添加水印的图像无法进行提取。下载提取模板的参数(Decoder参数下载),保存到文件夹saved_models/stegastamp_detector下面,需要提取信息的图像保存在out/1_hidden.png,提取出来的信息为Hello,直接在终端中进行输入如下命令进行提取。
python decode_image.py --model detector_models/stegastamp_detector --image out/1_hidden.png
运行之后在终端中显示了隐藏的信息Hello,说明隐藏的信息提取出来了。
二、自己数据集训练模型
2.1 小数据集-50张
选择边缘提取的BIPED数据集下面imgs\test\rgbr中的50张图片进行训练,参数还是模型预先设定的,没有改变。下图为BIPED数据集的示例图像,BIPED数据集链接。

训练之后的测试结果如下:



由上图可知,训练140000个epoch之后,添加信息的图像有很明显差异,能看出来中间的图添加了信息。主要原因是数据集图片数量较少,只有50张,通过训练的过车中输出的Loss曲线可以看出,大概60000个epoch之后Loss基本平稳,说明训练的参数基本收敛。
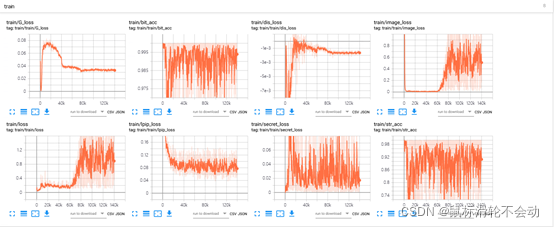
2.2 大数据集-25002张
使用具有2.5万张图像的数据集mirflickr(下载地址)进行训练140000epoch之后,得到的结果如下






根据结果可知,已经跟原始论文的结果很相近了。通过解码模型也能得到保存的信息Hello。
对视频的检测能力也与原始的模型相差无几,说明使用大数据集训练的模型确实能展现论文中的结果。
三、避坑指南
1.安装tensorflow要使用1.版本,2版本会有很多问题,网上有说即使使用2版本的,在报错函数中间增加compat.v1.,这个我试过了,不行,很多地方都需要改,改错了还不好找问题,所以,建议大家重新建个环境之后安装1.版本的tensorflow。
2. 安装lpips包提示安装失败: 直接下载Github源码放到当前项目工作目录下,从源码中直接导入。Github下载lpips
3. models.py中的Sequential函数报错,错误原因是第一层必须输入input_size: 网上很多博主说在可选参数中增加input_size的大小,但是不管用,我使用了最笨的方法,将Sequential的部分打开,逐条定义,方法虽笨,确实通过了。
4.在测试视频提取信息的时候需要使用GPU,要不然带不动。
## 修改前
self.stn_params = Sequential([
Input(shape=(8, 400, 400, 3)),
Conv2D(32, (3, 3), strides=2, activation='relu', padding='same'),
Conv2D(64, (3, 3), strides=2, activation='relu', padding='same'),
Conv2D(128, (3, 3), strides=2, activation='relu', padding='same'),
Flatten(),
Dense(128, activation='relu')
])
## 修改后
self.stn_params1 = Conv2D(32, (3, 3), strides=2, activation='relu', padding='same')
self.stn_params2 = Conv2D(64, (3, 3), strides=2, activation='relu', padding='same')
self.stn_params3 = Conv2D(128, (3, 3), strides=2, activation='relu', padding='same')
self.stn_params4 = Flatten()
self.stn_params5 = Dense(128, activation='relu')
总结
跑通了一篇CVPR2020关于隐藏信息的论文代码,测试官方模型比较容易,配好环境问题不大,但是运行训练模型需要有很多坑要跳,本文整理了过程中的一些坑,希望对大家跑通代码能有些帮助。