张士玉小黑屋
一个关注IT技术分享,关注互联网的网站,爱分享网络资源,分享学到的知识,分享生活的乐趣。
当前位置:首页 » 《随便一记》 - 第175页
【论文笔记】IEEE | 一种新卷积 DSConv: Efficient Convolution Operator
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 346次

论文标题:DSConv:EfficientConvolutionOperator论文链接:https://arxiv.org/abs/1901.01928v2论文代码:发表时间:2019年11月创新点实现更低的内存使用,并且加快计算速度Abstract我们引入了一种称为DSConv(分布移位卷积)的卷积层变体,它可以很容易地替换到标准神经网络架构中,并实现更低的内存使用和更高的计算速度。DSConv将传统的卷积核分解为两个组件:可变量化核(VQK)和分布偏移。通过在VQK中仅存储整数值来实现更低的内存使用和更高的速度,同时通过应用基于内核和通道的分布偏移来保留与原始卷积相同的输出。我们在ResNet50和ResNet34以及AlexNet和M
Vue中 this.$set的用法
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 306次
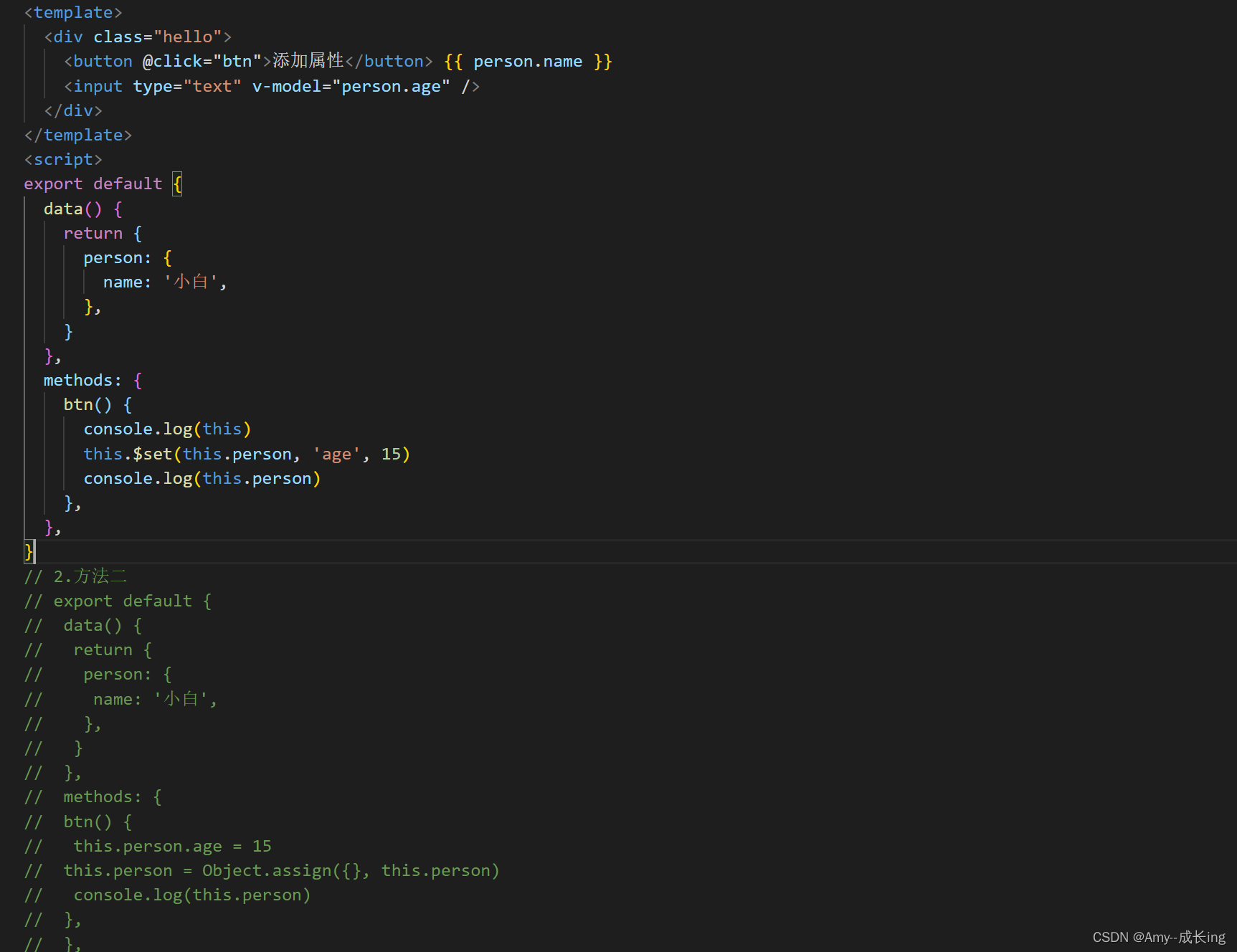
一、this.$set能够实现什么功能 官方解释:向响应式对象中添加一个属性,并确保这个新属性同样是响应式的,且触发视图更新。它必须用于向响应式对象上添加新属性,因为Vue无法探测普通的新增属性(比如this.myObject.newProperty=‘hello,ningzaichun’) 简单说即是:当你发现你给对象加了一个属性,在控制台能打印出来,但是却没有更新到视图上时,也许这个时候就需要用到this.$set()这个方法了 通过触发按钮事件 实现数据改变时,据视图层数也同步改变,此时便可以在控制台看到打印出来的方法及一些属性Vue中this.$set的用法1. Vue.set(target,propertyName/ind
小规模容器编排使用Docker Swarm不香么,用个锤子的kubernetes
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 361次
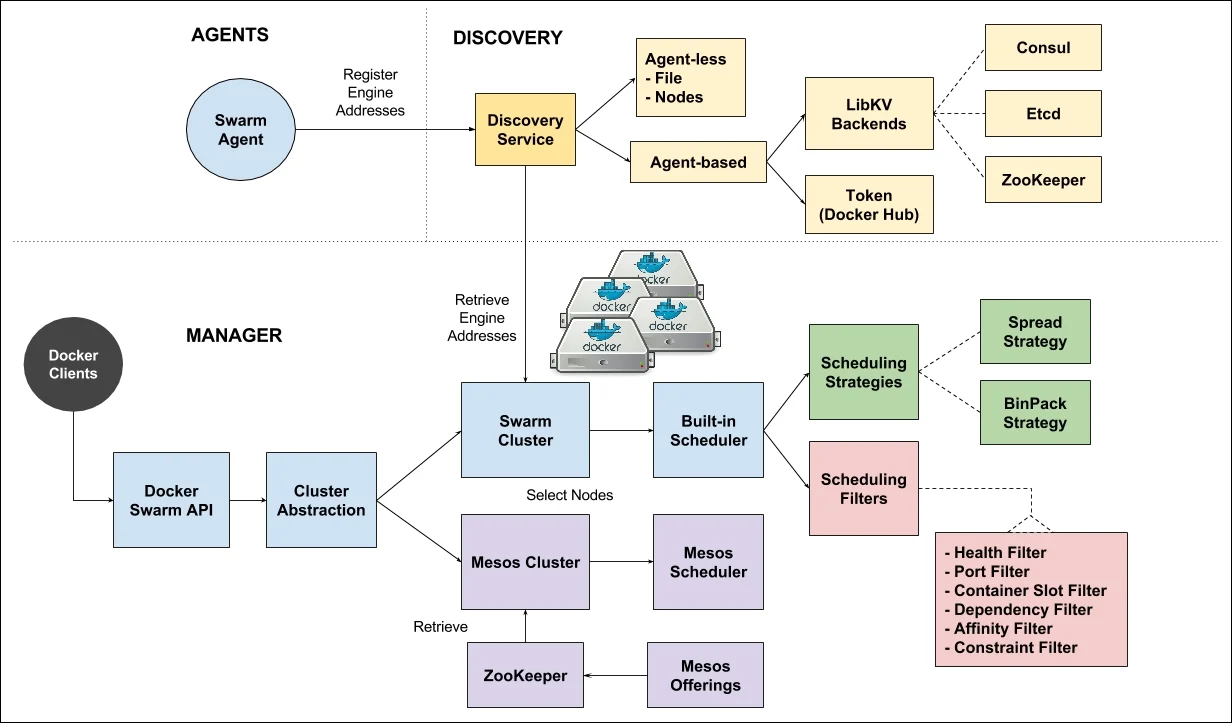
文章目录一、DockerSwarm是什么?二、Swarmkit和SwarmMode是什么?三、DockerSwarm的核心设计四、DockerSwarm安装部署4.1、初始化Swarm节点14.2、新节点加入Swarm集群4.3、使用swarm部署服务4.4、swarm集群管理一、DockerSwarm是什么?DockerSwarm是一款由Docker官方推出的容器编排工具,其主要作用是把若干台Docker主机抽象为一个整体,并且通过一个入口统一管理这些Docker主机上的各种Docker资源,用于管理和编排多个Docker容器的集群。它可以让用户方便地管理多个Docker节点,以及部署和扩展应用程序。DockerSwarm通过提供集群管理、负载均衡
2022年蓝桥杯C++B组题解 - 很详细
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 468次

本人这次侥幸省1,特做题解复习,哈哈哈…1.进制转换(5分):问题描述:直接计算2+2*9+2*9*9*9答案:14782.顺子日期(5分)这题有争议:主要在于0等不能开头:如20220121本人认为0不能作为开头(因为例题中20220123说明的顺子为123并不是012):所以顺子日期有:20220123202211232022123020221231答案:43.刷题统计(10分)解题思路:考虑a=1,b=1,n=1e18情况,不能一天一天计算,会超时5*a+2*b为一周的刷题量,先除法计算多少周,剩余的天数一直减就是了if(n<=0)break;要放在第一位参考代码:#inclu
一分钟玩转Stable Diffusion
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 471次
用计算机视觉模型生成各种各样的图片已经不是什么新鲜的事了,但是最近新出的一款AI绘画模型StableDiffusion确实惊艳到了各位小伙伴,无论是从软件的使用难度还是绘画生成的结果,都有可圈可点的地方,下面我们就一起尝试用该AI绘画软件画出一幅精美的图片。第一步:配置Python环境和安装Git软件StableDiffusion模型需要在Python3.10.6及以上的环境中才能顺利运行模型,所以在正式安装模型之前,我们需要安装Python3.10.6,下面我介绍在conda环境下安装python虚拟环境并使用在StableDiffusion模型中的过程:1、使用conda安装符合条件的python虚拟环境condacreate--namemy_python_name
Docker 快速安装Jenkins完美教程 (亲测采坑后详细步骤)(转)
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 2274次
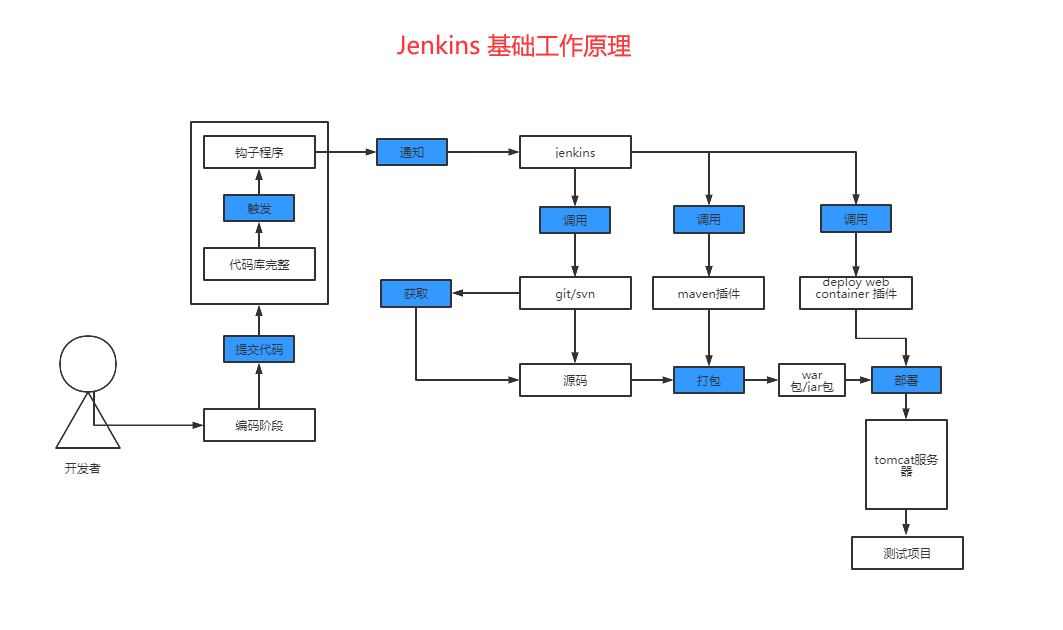
转载至:https://www.cnblogs.com/fuzongle/p/12834080.htmlDocker快速安装Jenkins完美教程(亲测采坑后详细步骤)Jenkins是一个开源软件项目,是基于Java开发的一种持续集成工具,用于监控持续重复的工作,旨在提供一个开放易用的软件平台,使软件的持续集成变成可能。一、前言有人问,为什么要用Jenkins?我说下我以前开发的痛点,在一些中小型企业,每次开发一个项目完成后,需要打包部署,可能没有专门的运维人员,只能开发人员去把项目打成一个war包,可能这个项目已经上线了,需要把服务关,在部署到服务器上,将项目启动起来,这个时候可能某个用户正在操作某些功能上的东西,如果你隔三差五的部署一下,这样的话对用户的体验也不好,自己也是烦
STM32开发(六)STM32F103 通信 —— RS485 Modbus通信编程详解
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 524次
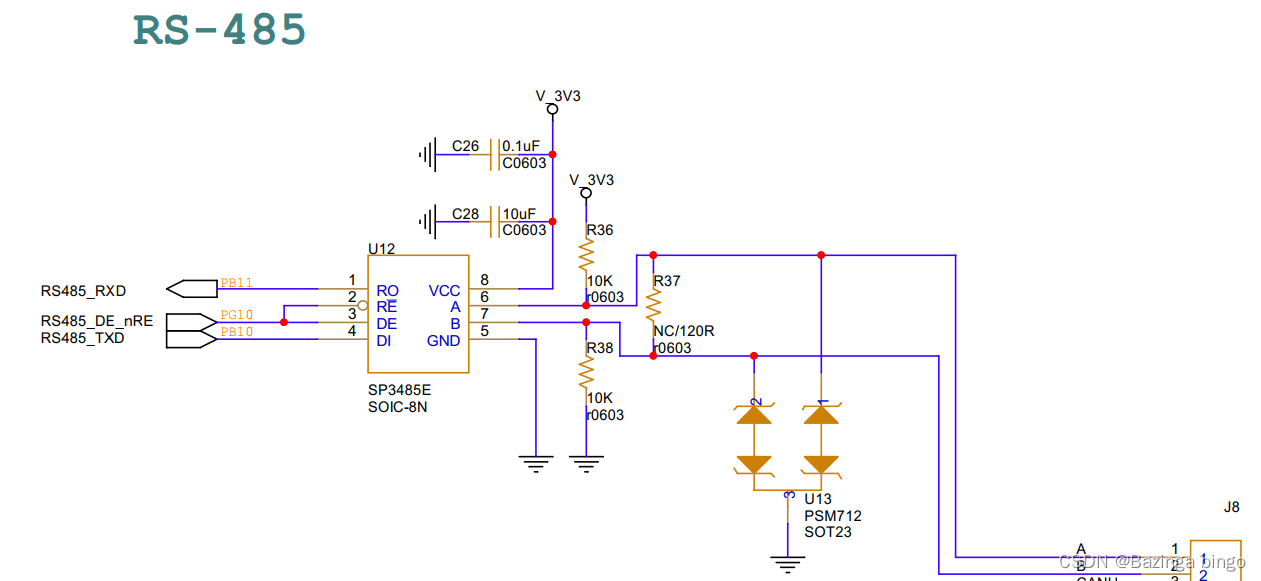
文章目录一、基础知识点二、开发环境三、STM32CubeMX相关配置1、STM32CubeMX基本配置2、STM32CubeMXRS485相关配置四、Vscode代码讲解五、结果演示以及报文解析一、基础知识点了解RS485Modbus协议技术。本实验是基于STM32F103开发实现通过RS-485实现modbus协议。准备好了吗?开始我的showtime。二、开发环境1、硬件开发准备主控:STM32F103ZET6RS485收发器:SP3485P2、软件开发准备软件开发使用虚拟机+VScode+STM32Cube开发STM32,在虚拟机中直接完成编译下载。该部分可参考:软件开发环境构建三、STM32CubeMX相关配置1、STM3
最新版本 Stable Diffusion 开源 AI 绘画工具之汉化篇
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 348次
✨目录?汉化预览?下载插件方法一?下载插件方法二?下载插件方法三?简单汉化?双语汉化?汉化预览在上一篇文章中,我们安装好了StableDiffusion开源AI绘画工具但是整个页面都是英文版的,对于英文不好的同学看起来可相当的不友好那么有没有办法对这个软件进行汉化处理呢?当然是可以的?下载插件方法一这个软件的汉化,是通过汉化插件解决的,下载插件时一般都需要开启魔法上网,因为这些插件的源都不在墙内这里我提供三种下载插件的方式,如果一种下载方式不行,可以看其他下载方式,总有一种方式适合你点击软件界面的Extensions按钮,
【Redis】Redis持久化之AOF详解(Redis专栏启动)
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 408次

?作者简介:小明java问道之路,2022年度博客之星全国TOP3,专注于后端、中间件、计算机底层、架构设计演进与稳定性建工设优化。文章内容兼具广度深度、大厂技术方案,对待技术喜欢推理加验证,就职于知名金融公司后端高级工程师。 ?热衷分享,喜欢原创~关注我会给你带来一些不一样的认知和成长。 ?2022博客之星TOP3|CSDN博客专家|后端领域优质创作者|CSDN内容合伙人?InfoQ(极客邦)签约作者、阿里云专家|签约博主、51CTO专家|TOP红人、华为云享专家 ?如果此文还不错的话,还请?关注、点赞、收藏三连支持?一下博主~ ?文末获取联系? ??精彩专栏推荐订阅收藏?
对抗生成网络(GAN)中的损失函数
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 433次

目录GAN的训练过程:L1和L2损失函数的区别基础概念相同点差异GAN的训练过程:1、先定义一个标签:real=1,fake=0。当然这两个值的维度是按照数据的输出来看的。再定义了两个优化器。用于生成器和判别器。2、随机生成一个噪声z。将z作为生成器的输入,输出gen_imgs(假样本)。3、计算生成器的损失定义:生成器的损失为g_loss。损失函数为adverisal_loss()。判别器为discriminator()。g_loss=adverisal_loss(discriminator(gen_imgs),real)g_loss.backward()optimizer_G.step()可以看出来,g_loss是根据一个输出(将生成的样本作为输入的
search zhannei
最新文章
-
- (新欢闹上门,明小姐消失后司总悔疯了):+后续+番外司锦修明悦后续全本浏览阅读
- 夕景昨日无心怜冷秋语洛斯言后续(冷秋语洛斯言)全文在线下载在线+纯净版结局
- 落青梅,佛前几度相思泪:+后续***(宋佳音陆景琛)终章阅读无广告
- 很快,他们都自由了:结局+番外新上热文(叶浅秋陆凌川)最近章节列表
- 养妹被豪门认回后做成女体盛,缅北杀神的我杀疯了完结全文_妹妹苏月月宾客优质全文_小说后续在线阅读_无删减免费完结_
- 京圈太子爷扫黄被抓,我改嫁八块腹肌风流俏奶爸列表_京圈太子爷扫黄被抓,我改嫁八块腹肌风流俏奶爸(许知意顾云夕)
- (书荒必看)夏晚歌陆秋震惊!玄学大佬被读心了:+后续热血十足
- 老公逼我给女大献血补身后,他悔疯了前言+后续(沈佳音顾时安)_老公逼我给女大献血补身后,他悔疯了前言+后续
- 攻略对象害我绝嗣后,她悔疯了节选_林知夏阿宇方宇热文_小说后续在线阅读_无删减免费完结_
- 如愿娶到假巫女养妹,他却悔疯了超长版_渺渺洛景修沈含霜连载_小说后续在线阅读_无删减免费完结_
- 完结文京圈太子爷扫黄被抓,我改嫁八块腹肌风流俏奶爸完结列表_完结文京圈太子爷扫黄被抓,我改嫁八块腹肌风流俏奶爸完结(许知意顾云夕)
- 韩忆雪顾晏州小说(离婚吧顾总,这豪门怨妇我不当了)前传+全书阅读新作预览
Copyright © 2020-2022 ZhangShiYu.com Rights Reserved.豫ICP备2022013469号-1