张士玉小黑屋
一个关注IT技术分享,关注互联网的网站,爱分享网络资源,分享学到的知识,分享生活的乐趣。
当前位置:首页 » 拟合 - 第1页
R语言使用caret包构建GBM模型:在模型最优参数已知的情况下,拟合整个训练集,而无需进行任何重采样或参数调优_data+scenario+science+insight
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 478次

R语言使用caret包构建GBM模型:在模型最优参数已知的情况下,拟合整个训练集,而无需进行任何重采样或参数调优目录R语言使用caret包构建GBM模型:在模型最优参数已知的情况下,拟合整个训练集,而无需进行任何重采样或参数调优
R语言glm拟合logistic回归模型:模型评估(计算模型拟合的统计显著性)、模型评估(赤信息AIC指标计算)_data+scenario+science+insight
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 526次
R语言glm拟合logistic回归模型:模型评估(计算模型拟合的统计显著性)、模型评估(赤信息AIC指标计算)目录
R语言mgcv包中的gam函数拟合广义加性模型:线性回归与广义加性模型GAMs(Generalized Additive Model)模型性能比较(比较RMSE、比较R方指标)_data+scenario+science+insight
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 729次
R语言mgcv包中的gam函数拟合广义加性模型:线性回归与广义加性模型GAMs(GeneralizedAdditiveModel)模型性能比较(比较RMSE、比较R方指标)目录
机器学习(线性相关)_m0_62305088的博客
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 506次
目录一、线性回归<1>线性回归中的函数<2>线性回归方程绘图二、多项式回归三、拟合度输出四、线性预测 五、多元回归一、线性回归<1>线性回归中的函数stats.mode()#众数numpy.median()#中位数numpy.mean()#平均数numpy.std()#标准差numpy.var()#方差numpy.percentile(数组,数字)x=numpy.random.uniform(0.0,5.0,250)
MATLAB,Python,Pytorch实现数据拟合_武成汉都
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 538次
目录1、MATLAB实现数据拟合2、纯python实现数据拟合3、pytorch实现数据拟合1、MATLAB实现数据拟合%MATLAB数据拟合x=linspace(-1,1,100);rng('default')%使用整数种子初始化生成器,替换老版本命令rand('state',s);y=3*x.^2+2+0.2*rand(1,100);scatter(x,y,'filled','MarkerFaceColor',[001]);p=polyfit(x,y,2);holdony_pre=
R语言rms包生存分析之限制性立方样条(RCS, Restricted cubic spline)分析详解实战:拟合连续性自变量和事件风险之间的关系:基于survival包lung数据_data+scenario+science+insight
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 1412次
R语言rms包生存分析之限制性立方样条(RCS,Restrictedcubicspline)分析详解实战:拟合连续性自变量和事件风险之间的关系:基于survival包lung数据目录
【集成学习系列教程2】GBDT原理及sklearn应用_Juicy B的博客
发布 : zsy861 | 分类 : 《休闲阅读》 | 评论 : 0 | 浏览 : 506次

1.5GBDT二分类算法1.5.1概述前面我们介绍了AdaBoost的基本原理,并举了几个实例对AdaBoost的使用做了一些演示。简单来说,AdaBoost的大体思想就是:根据每个弱学习器的预测误差为每个弱学习器赋予不同的权重,并以上一个弱学习器的权重为依据更新数据集样本分布的权重(尤其是不断加大上一轮弱学习器预测错误的样本的权重),通过不断循环这一过程,最终得到一个在所有样本上均有较高预测准确
一文带你用Python玩转决策树 ❤️画出决策树&各种参数详细说明❤️决策树的优缺点又有哪些?_老吴的博客
发布 : zsy861 | 分类 : 《资源分享》 | 评论 : 0 | 浏览 : 713次
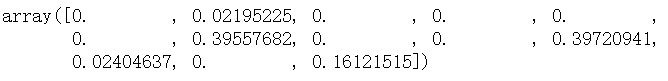
前言在上一篇文章中我们已经详细介绍基于ID3算法进行改良的C4.5算法以及决策树拟合度的优化问题,那这篇文章呢,则是介绍如何使用sklearn实现决策树。当然,如果只是简单实现决策树的话,我是不可能单独拿出来写成一篇文章的,我会在本篇文章中详细地介绍到各种具体功能的代码实现,如剪枝等,同时重要的参数也一个都不会放过(hhh),而且文末也介绍了决策树模型的优缺点有哪些方面&#
谁来救救过拟合?透过现象看本质,如何利用正则化方法解决过拟合问题_wenyusuran的专栏
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 701次
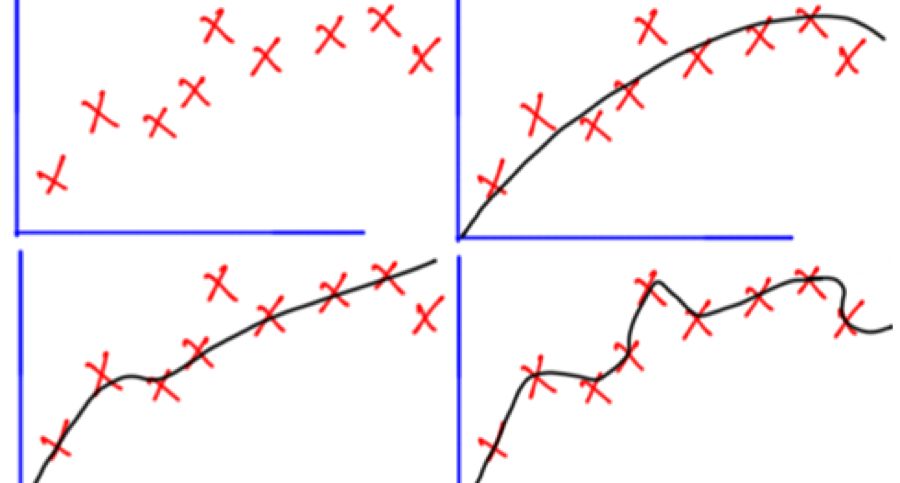
前言声明:后期原力计划活动期间的博文都会转入到对应的收费专栏。博主后续会不断更新该领域的知识:人工智能AI实战系列代码全解析手把手教你ML机器学习算法源码全解析有需要的小伙伴赶紧订阅吧。 在工作中,相信很多小伙伴都遇到过过拟合的现象,创建了一个可以完美训练样本的机器学习模型,但对于需要预测的样本却给出了非常糟糕的预测!你有没有想过为什么会这样?本文将基于回归的正则化技术,对过度拟合进行解析,明确如何使用正则化技术避免过度拟合的方式。 每次谈及过拟合,这张图片就会时不时地
Copyright © 2020-2022 ZhangShiYu.com Rights Reserved.豫ICP备2022013469号-1