由于最近需要对YOLOX的理论部分进行深入的理解,因此我需要查看YOLOX的相关论文,但YOLOX是最近新出的目标检测算法,但我发现我无法查看YOLOX相关的见刊论文,因此我只能好好深入理解它的原始论文。但我的理解可能比较浅薄,希望各位大佬在查看这篇文章的时候可以及时纠正我的错误。
以下是旷视科技所提供的YOLOX的GitHub开源代码:
Pytorch版:https://github.com/Megvii-BaseDetection/YOLOX
MegEngine版:https://github.com/MegEngine/YOLOX
原始论文地址:
https://arxiv.org/abs/2107.08430
从GitHub上面可以看到YOLOX的简单说明:

从这里可以看出,YOLOX是一个高性能的anchor-free版本,它超过了YOLOv3到YOLOv5,并且支持MegEngine、ONNX、TensorRT、ncnn和OpenVINO,为大家提供了加速和部署的支持。
在原始论文的题目可以看出,YOLOX在2021年超过了所有YOLO系列的版本:

下面就开始对YOLOX原始论文进行解读:
在这篇文章的最前面,可以看到左边这个图:
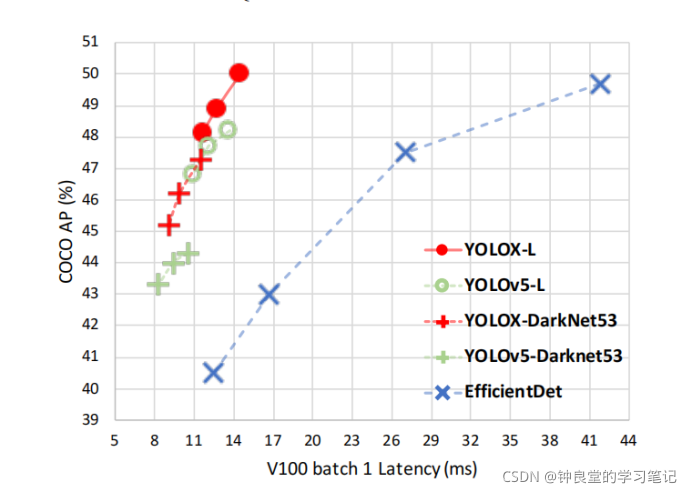
这个图对比了不同模型的精度以及速度,我们可以看到越往左上角的线是越好的。显然左上角的YOLOX-L和YOLOv5-L相比,YOLOX-L的性能更好,它的性能远远超过EfficientDet。
接下来,我们来看右边这幅图:
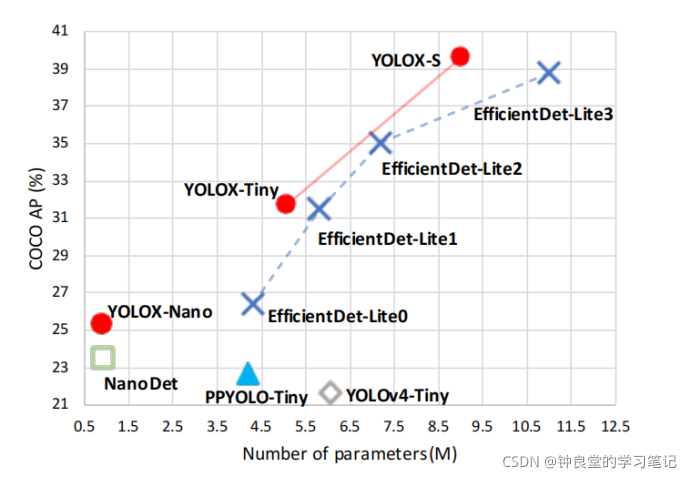
右边这幅图是对小模型的比较(YOLOX-S、YOLOX-Tiny和YOLOX-Nano)
这里我们可以看到,YOLOX-Nano是最快的一个模型,它比NanoDet所得到的AP值更高,而模型的参数量相当。
下面来看文章的摘要:

从这里可以看到,他们把YOLO的检测器转换成一个anchor-free的方式,并且采用了其他先进的技术,包括decoupled head(解耦头)、leading label assignment strategy SimOTA(领先的标签分配策略,SimOTA)。
接着介绍了它的性能表现:

这里介绍了它和小模型NanoDet的对比,特别是提到它的AP增加了1.8%,大模型对比了YOLOv5-L,它的AP也提高了1.8%。并且使用大模型(YOLOX-L)获得了一个比赛的第一名。

接下来,这里提到了YOLOX支持ONNX、TensorRT、ncnn和OpenVINO还有代码的开源地址。
下面是论文的引言部分:

这里作者提到YOLO系列是比较好的追求最优的速度和精度权衡,这样比较适合实时应用。
尽管YOLO系列表现很好,但是过去两年目标检测在学术界有新的进展,其中在anchor-free检测器、先进的标签分配策略(advanced label assignment strategy)和end-to-end(NMS-free) detectors(不需要非极大抑制的候处理),但是这样先进的进展并没有整合到YOLO系列的家族里面。
所以作者希望把这些进展整合到YOLO系列中:

YOLOX把YOLOv3作为一个起点(也就是采用YOLOv3-SPP(SPP:空间金字塔池化)作为默认的YOLOv3版本),并在此基础上进行改进:

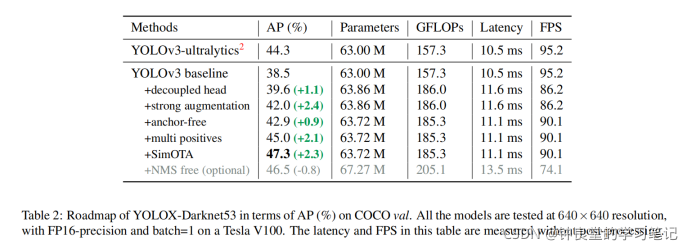
下面作者介绍了相对YOLOv3性能的提升,YOLOX相对YOLOv3(使用同样的主干特征提取网络DarkNet53)在COCO数据集上可以达到47.3%(提高3%):

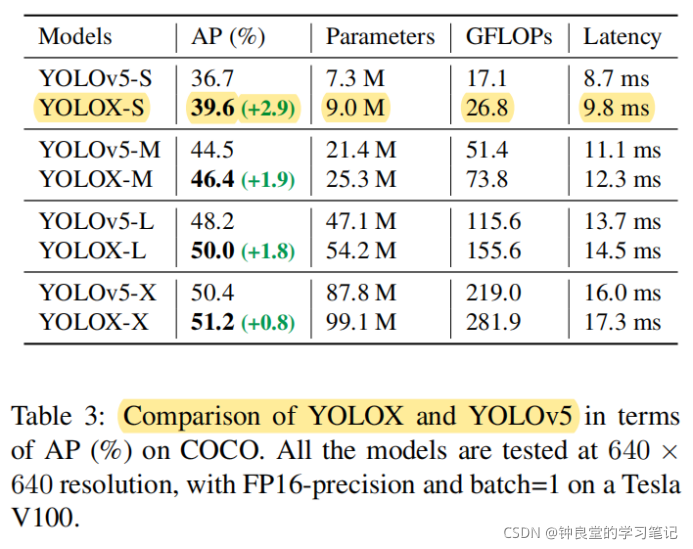
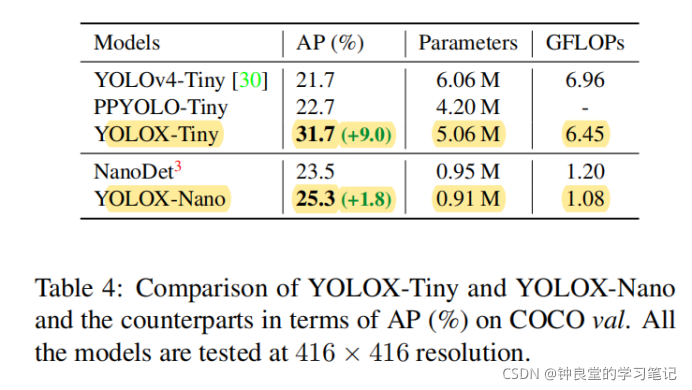
下面是相对于YOLOv5的对比,相比YOLOv5-L上有1.8%AP的提升,在小模型上,YOLOX-Nano(参数量0.91M的参数和1.08G的FLOPs),对比YOLOv4-Tiny和NanoDet分别有10%和1.8%AP的提升。

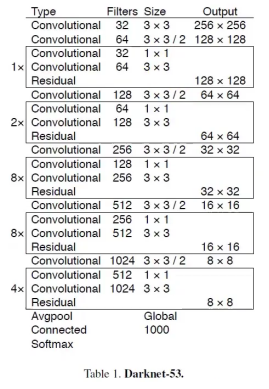
下面开始介绍YOLOX-DarkNet53

作者选用了YOLOv3的DarkNet53作为基线,以下是YOLOv3论文中的DarkNet53网络结构图:
以下是实现的细节:它的训练设置是这样的,为了对比不同的性能,不同的模型都在coco数据集上使用了300代的训练,并且使用5代的warm-up。

其使用了SGD优化器来训练。最初的学习率是0.01,采用了cos学习率方案。
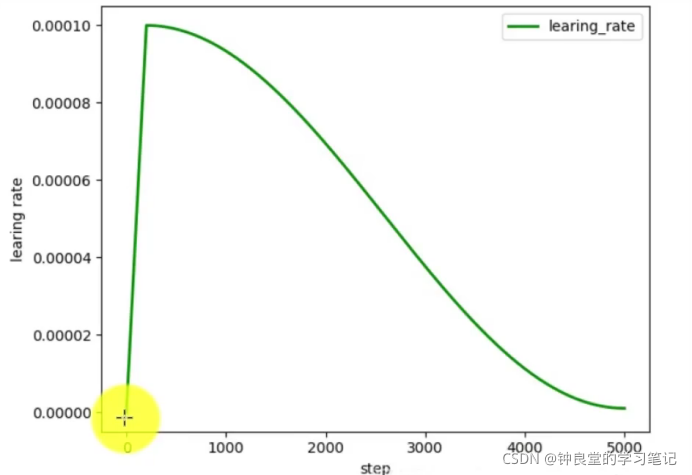
接着是weight decay和SDG momentum的设置。同时设置batch size为128在8个GPU上面。接着在一个Tesla显卡上采用16位浮点精度和batch为1。

下面介绍了YOLOv3的基线:
也就是DarkNet53主干特征提取网络和一个SPP layer(空间金字塔池化模块),它增加了EMA(指数移动平均)的权重更新,cosine的学习率方案,使用了IoU loss和IoU-aware branch。
对于类别(cls)和目标(obj)使用了BCE loss(二元交叉熵损失函数),对于reg回归(branch)使用了IoU loss,也就是在在YOLOv3的基础上进行这些改进。

对于数据增强,它使用了only conduct RandomHorizontalFlip, ColorJitter 和multi-scale for data augmentation ,但是并没有采用RandomResizedCrop策略,这些策略就是作者所采用YOLOv3的基线。
下面介绍decoupled head(解耦头):
具体就是把分类(classification)和回归(regression)解耦,因为分类和回归是有一定的冲突。

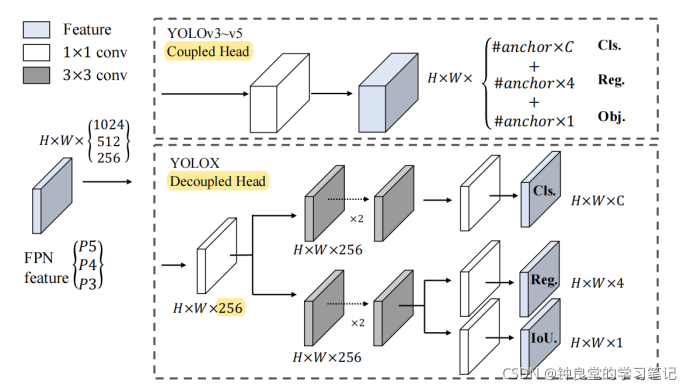
下面这幅图对比了YOLOv3到YOLOv5的Coupled head和YOLOX的Decoupled head:
这幅图可以看到YOLOX把分类和回归分成两个branch,并且还增加了IoU计算的分支。
这里作者又强调了使用Decoupled head方式的原因:1、可以提高训练的收敛速度2、如果想做end-to-end的版本,也就是不采用非极大抑制候处理的话,那么Decoupled head是比较方便的。

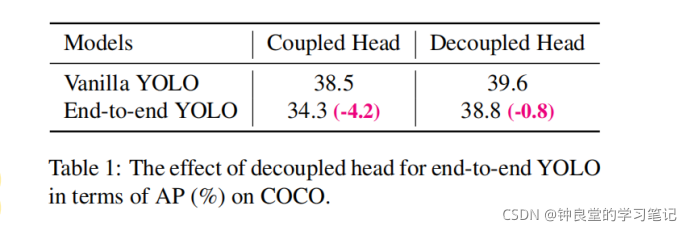
表1中也对比了Coupled head和Decoupled head,对于Vanilla YOLO(YOLOv3的基线),可以看到Decoupled head比Coupled head有提高,提高到39.6%AP,如果采用end-to-end YOLO,Decoupled head比Coupled head性能也有提升。如果使用end-to-end YOLO,会比使用Vanilla YOLO性能会降低,Decoupled head相比Coupled head会降低更少。
这里可以看到采用Decoupled head可以提升1.1毫秒的处理速度的增加:

接下来我们再看一下这个对比图,Decoupled head会先通过1×1的卷积把前面的特征图的通道变为256,然后再经过2个3×3的卷积层,接着再经过1×1的卷积层,分别到分类检测头和回归检测头,同时再回归这个分支还增加了IoU分支。

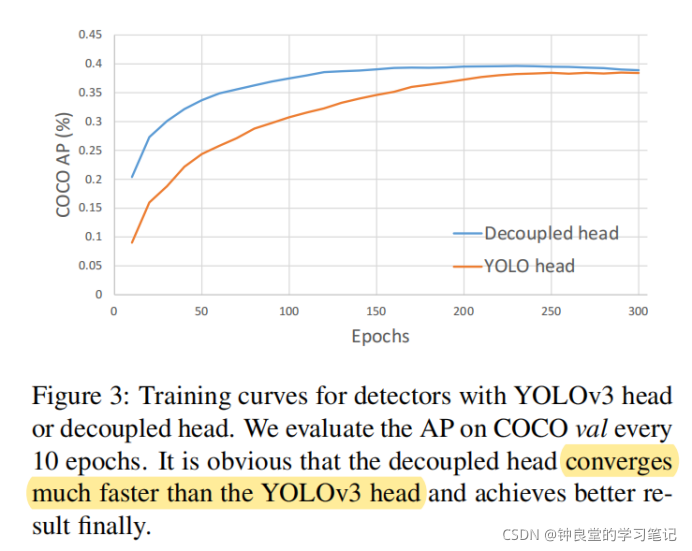
从图3我们可以看到,在训练时,Decoupled head比YOLO head的收敛更快,并且最终的性能也有所提高。
接下来作者介绍了比较强的数据增强,作者采用了Mosaic和MixUp两种数据增强的策略。
Mosaic是YOLOv3所采用的数据增强的方式。

MixUp数据增强方式(将其他图和原图混合在一起,并且标签也混合在一起):

Mosaic数据增强方式(四张图拼接成一张图):

下面介绍Anchor-free(不采用矛框的机制),YOLOv4和YOLOv5都是基于Anchor的策略,但是基于Anchor的机制有不少的问题:首先,这个Anchor的大小应该怎么选择呢?可以采用聚类分析的方法,在训练之前得到比较好的Anchor,但是这些聚类的Anchor没有通用性。
第二,Anchor机制增加了检测头的复杂度,并且对每一个图片也增加了预测的数量。

最近2年,Anchor-free的检测器有比较快的发展,Anchor-free可以减少设计的参数。

如果把YOLO转换成Anchor-free的方式,并不复杂。这里是预测4个值,但是它不少上下左右的值,而是相对于左上角的两个偏移值,还有整个预测边界框的高度和宽度。

另外作者还采用了Muti positives,Anchor-free它可以只选择一个正样本(每个目标的中心位置作为正样本),这样就忽略了其他高质量的预测了,所以作者不是只用了一个正样本点,而是采用了3×3的区域作为正样本,不是一个点作为正样本,在FCOS算法中称为center sampling。

下面介绍SimOTA(用于标签分配)
具体讲解可以查看如下文章:
https://zhuanlan.zhihu.com/p/394392992
https://zhuanlan.zhihu.com/p/395610228
https://blog.csdn.net/weixin_45074568/article/details/120371817

作者没有采用Sinkhorn-Knopp算法,而是动态的top-k start-egy(称为SimOTA),以此来得到近似的解决方案。如果要使用Sinkhorn-Knopp算法的话,在训练时会增加百分之25的训练时间,对于训练300代来说是比较贵的。

接下来介绍SimOTA所采用的prediction-gt 之间这种成对的代价,是采用如下公式来进行计算。

这个公式前面这一项是计算分类损失,λ是一个平衡因子,λ再乘上回归损失。

SimOTA可以减少训练的时间同时避免了SK算法中需要确定的额外的超参。

End-to-end YOLO(端到端,没有非极大抑制候处理的方法),对性能会有一定的降低。

从表2可以看出各个方法使用对AP的影响(与YOLOv3的对比)。
如果采用YOLOv5的话:

论文也做出了对比(每个版本都比YOLOv5的性能要好):
下面是小模型的对比(Tiny和Nano):

可以看出YOLOX小模型的版本也比其他小模型要好:
下面介绍了模型大小和数据增强的相互影响:

这里可以看到如果Nano模型同时使用了两种数据增强的方法,AP值反而降低了,但是对于大模型YOLOX-L来说不会,说明数据增强方法的使用也需要看具体的模型大小的。

作者这里说明了有些模型还没有进行对比,但是以后可以进行对比。

接着作者提到了在Streaming Perception Challenge比赛中获得了第一名:

这个比赛综合考虑了精度和处理速度,在比赛中采用了YOLOX-L模型和TensorRT的加速。

下面就是论文的结论了:
这篇文章提出了高性能的anchor-free检测器YOLOX,采用的decoupled head(解耦头)、先进的标签分配策略(advanced label assignment strategy)等方法来提高了速度和精度的权衡,并且比其他的YOLO系列有性能的提升。
