IDEA连接Linux上的Hadoop并对HDFS进行操作
IDEA连接Linux上的Hadoop并对HDFS进行操作
文章目录
IDEA连接Linux上的Hadoop并对HDFS进行操作Windows软件准备和Linux上版本相同的Hadoop与Linux版本相同的JavaWindows的hadoop驱动文件`hadoop.dll `和`winutils.exe`配置`Linux使用Hadoop的用户名`的环境变量`HADOOP_USER_NAME` IDEA中的操作安装`big data tools`插件出现hdfs连接不上的情况第一种错误-`HADOOP_HOME`Error第二种错误-`connectionError` Error使用`telnet`进行测试问题原因解决方法 创建maven项目新建项目即可删除相关无用文件和目录 导入hadoop配置文件到resources中配置pom.xml文件编写WordCount代码进行测试返回Linux中在hdfs中创建输入文件和输出目录指定程序在HDFS中的输入输出路径在**编辑配置**中进行设置以`空格`为分割指定输入输出路径 执行程序 查看输出结果 参考文档`hadoop.dll `Download
Windows软件准备
和Linux上版本相同的Hadoop
压缩包解压: 将放在Linux上面的Hadoop压缩包(hadoop_xxxx.tar.gz)放在Windows任意硬盘中任意(建议新创建的一个Hadoop文件夹)文件夹, 然后直接进行解压即可, 不需要担心软件的系统适配问题
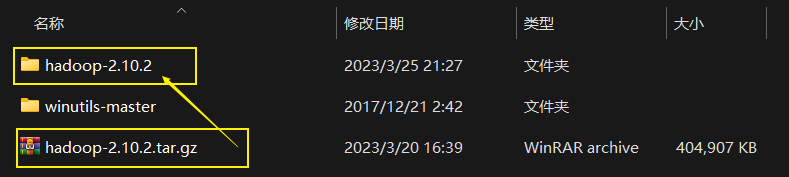
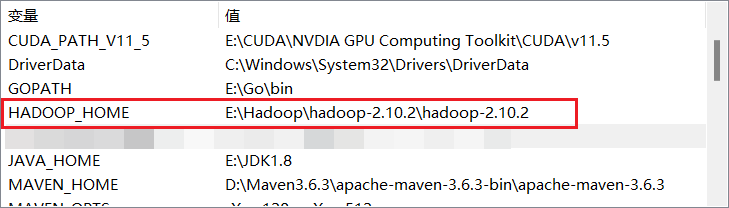
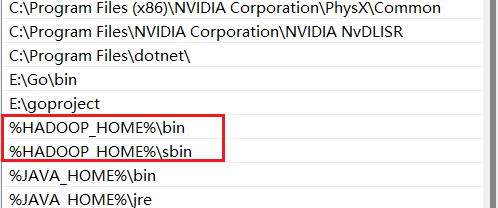
配置HADOOP_HOME环境变量及添加bin和sbin目录的系统路径
验证配置是否成功, 在powershell中输入hadoop -version
显示如下信息即表示配置成功

与Linux版本相同的Java
同样需要配置环境变量

Windows的hadoop驱动文件hadoop.dll 和winutils.exe
在GitHub上面下载, 如果没有对应于自己当前Hadoop的版本, 则选择高一点点的
Download-link-Github
然后将选择指定的版本中的hadoop.dll文件放到./hadoop/bin/下和C:\Windows\System32\下
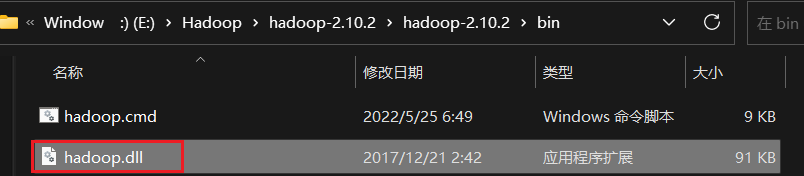

将winutils.exe文件也放到./hadoop/bin/下
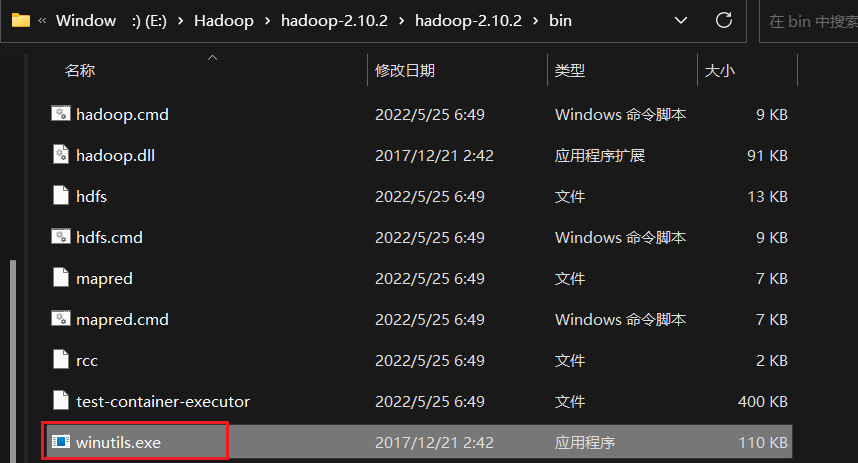
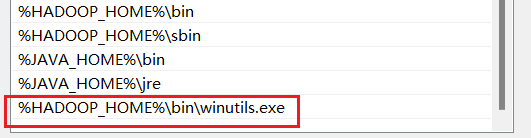
并为该文件配置环境变量添加系统路径
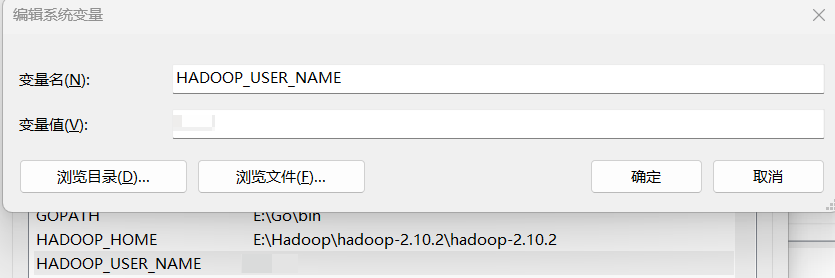
配置Linux使用Hadoop的用户名的环境变量HADOOP_USER_NAME
即在Linux中如果使用Hadoop的用户是hadoop, 则在环境变量配置的变量值中填入hadoop
IDEA中的操作
安装big data tools插件
安装好之后, 右侧边栏会出现Big Data Tools的选项框
点击选项框, 在左上角的+中选择添加HDFS
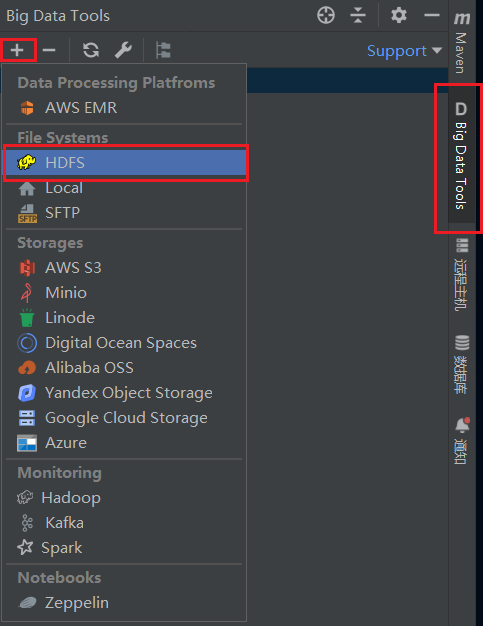
然后进行如下操作
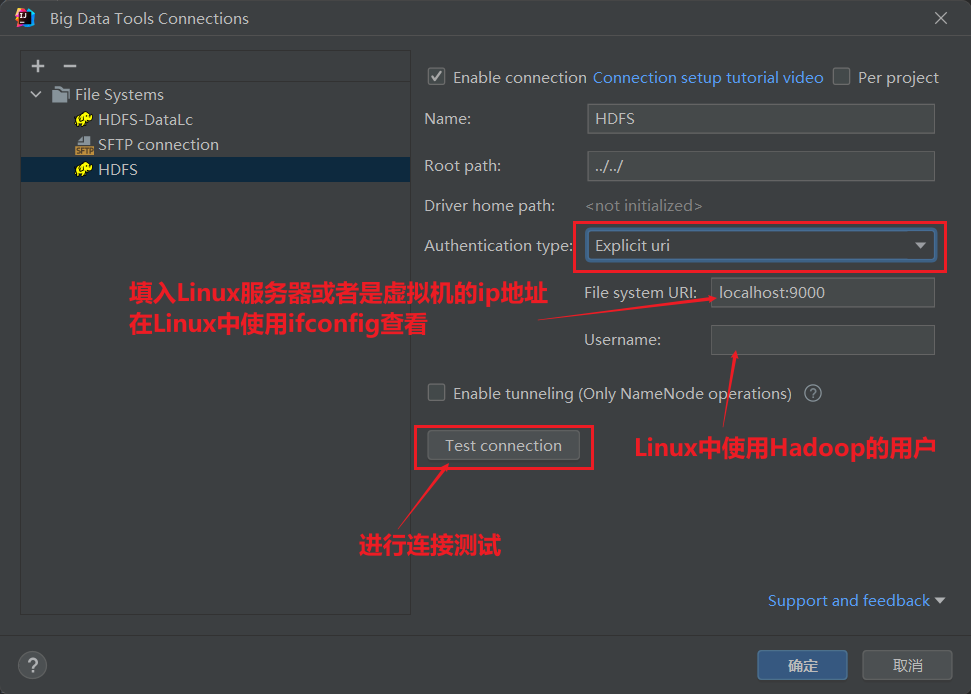
出现hdfs连接不上的情况
第一种错误-HADOOP_HOMEError
出现HADOOP_HOME相关问题, 如果按照预先安装中的四个步骤应该没有这个问题
如果真的还有问题, 那只能再去Google
第二种错误-connectionError Error
显示本机无法连接到Linux, connectionError
使用telnet进行测试
telnet <Linux-IP> 9000
因为Hadoop服务的默认端口是9000, 这个是在core-site.xml中手动指定的
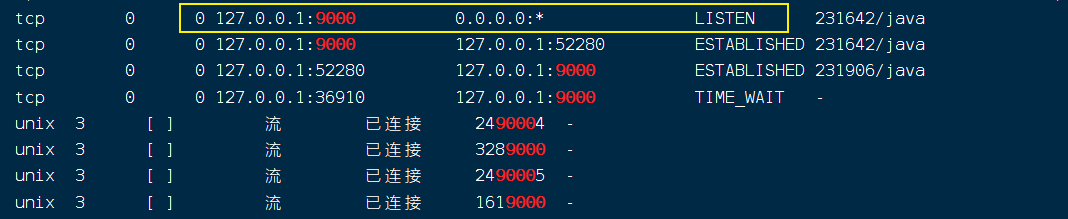
如果上述命令执行过之后显示连接不成功, 那么就是端口的监听问题
问题原因
因为当前Hadoop的9000端口仅允许本地访问,需要更改为允许远程访问。
解决方法
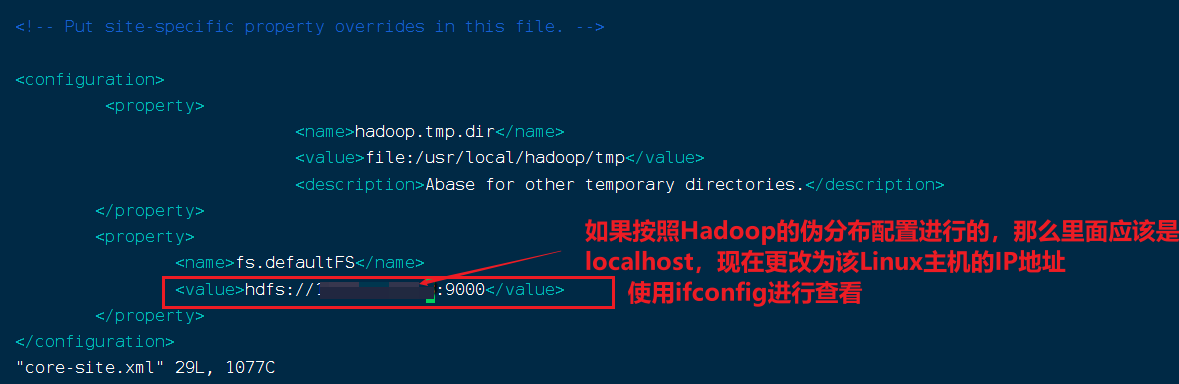
在core-site.xml文件中更改fs.defaultFS属性的值为Linux服务器的IP地址,例如hdfs://192.168.1.100:9000,然后重启Hadoop服务以使更改生效。
重启Hadoop步骤(假设已经为Hadoop中的bin和sbin目录配置了环境变量):
stop-all.sh
start-all.sh
jps查看相关进程以确认启动成功
另外,确保防火墙设置允许来自Windows机器的流量通过9000端口。
完成这些步骤后,就能够从Windows机器上的IDE中成功连接到Linux服务器上的Hadoop并对HDFS进行操作。

然后即可连接成功
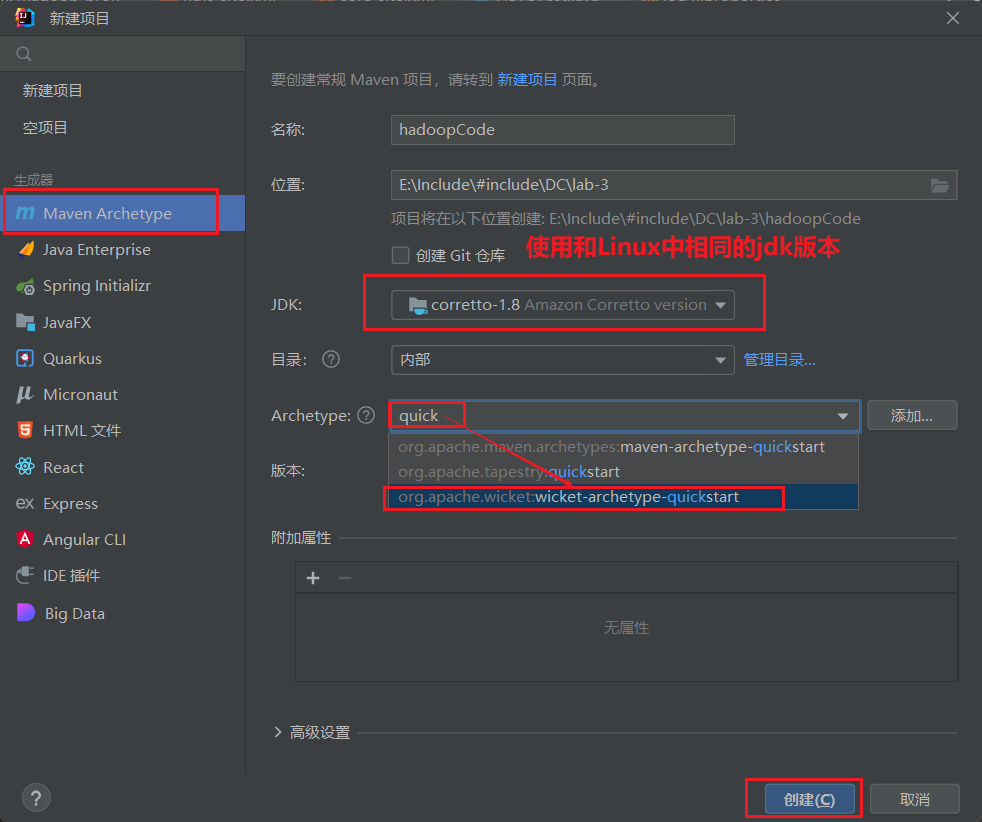
创建maven项目
新建项目即可
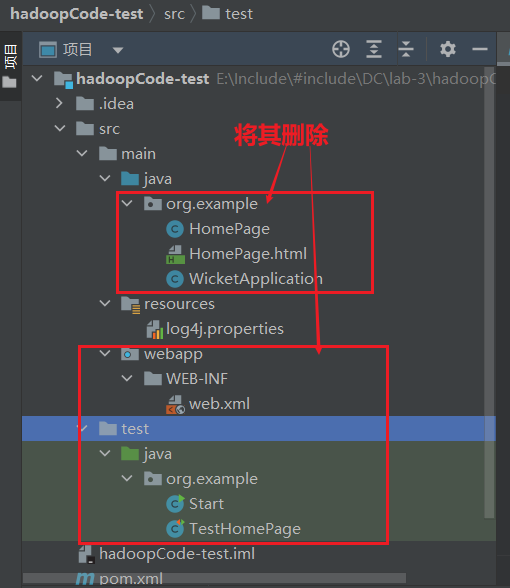
删除相关无用文件和目录
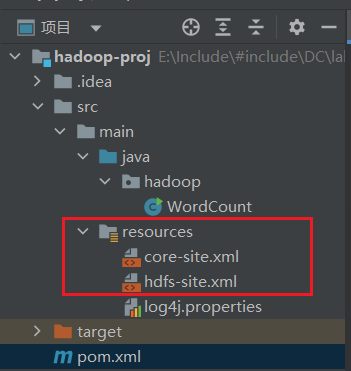
导入hadoop配置文件到resources中
从Linux中的./hadoop/etc/hadoop/目录中取出core-site.xml和hdfs-site.xml文件放入idea的resources目录中
配置pom.xml文件
在hadoop-client中将版本改为自己的hadoop版本
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>JavaHadoopProJectS</artifactId><version>1.0-SNAPSHOT</version><packaging>jar</packaging><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>2.10.2</version></dependency> <!--解决关于slf4j的mutiple bindings问题 --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.25</version><exclusions><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId></exclusion></exclusions></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-jar-plugin</artifactId><version>2.4</version><configuration><archive><manifest><mainClass>org.hhrz.mapreduce.demo.JobMain</mainClass></manifest></archive></configuration></plugin></plugins></build></project>PS:我在上述文件中加入了以下关于slf4j冲突所以去除依赖的语句
如果你没有该冲突问题, 并且该语句让你的程序运行出了问题, 你可以将其去掉
<dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.25</version><exclusions><exclusion><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId></exclusion></exclusions></dependency>编写WordCount代码进行测试
在其中对hadoop.dll文件的路径设置和HADOOP_USER_NAME的value值设置做自己的更改
package hadoop;import java.io.IOException;import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.GenericOptionsParser;import org.apache.log4j.BasicConfigurator;public class WordCount { public static class Map extends Mapper<Object,Text,Text,IntWritable>{ private static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key,Text value,Context context) throws IOException,InterruptedException{ StringTokenizer st = new StringTokenizer(value.toString()); while(st.hasMoreTokens()){ word.set(st.nextToken()); context.write(word, one); } } } public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable>{ private static IntWritable result = new IntWritable(); public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException,InterruptedException{ int sum = 0; for(IntWritable val:values){ sum += val.get(); } result.set(sum); context.write(key, result); } } static { try { // 填入自己的文件的路径 System.load("E:\\Hadoop\\hadoop-2.10.2\\hadoop-2.10.2\\bin\\hadoop.dll");//建议采用绝对地址,bin目录下的hadoop.dll文件路径 } catch (UnsatisfiedLinkError e) { System.err.println("Native code library failed to load.\n" + e); System.exit(1); } } public static void main(String[] args) throws Exception{ BasicConfigurator.configure(); //自动快速地使用缺省Log4j环境。 // 填入自己的环境变量中配置的value值 System.setProperty("HADOOP_USER_NAME", "value"); Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs(); if(otherArgs.length != 2){ System.err.println("Usage WordCount <int> <out>"); System.exit(2); } Job job = new Job(conf,"word count"); job.setJarByClass(WordCount.class); job.setMapperClass(Map.class); job.setCombinerClass(Reduce.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); }}返回Linux中在hdfs中创建输入文件和输出目录
基本命令
hadoop fs -mkdir /data 创建输入目录
hadoop fs -mkdir /out 创建输出目录
hadoop fs -put test.txt /data 上传测试文件到data目录
hadoop fs -cat /data/test.txt 显示test.txt文件中的内容
test filehello world可在Big Data Tools中看到文件树
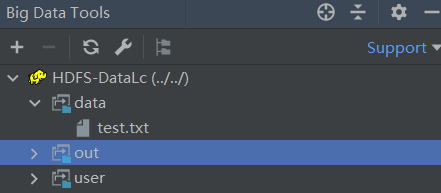
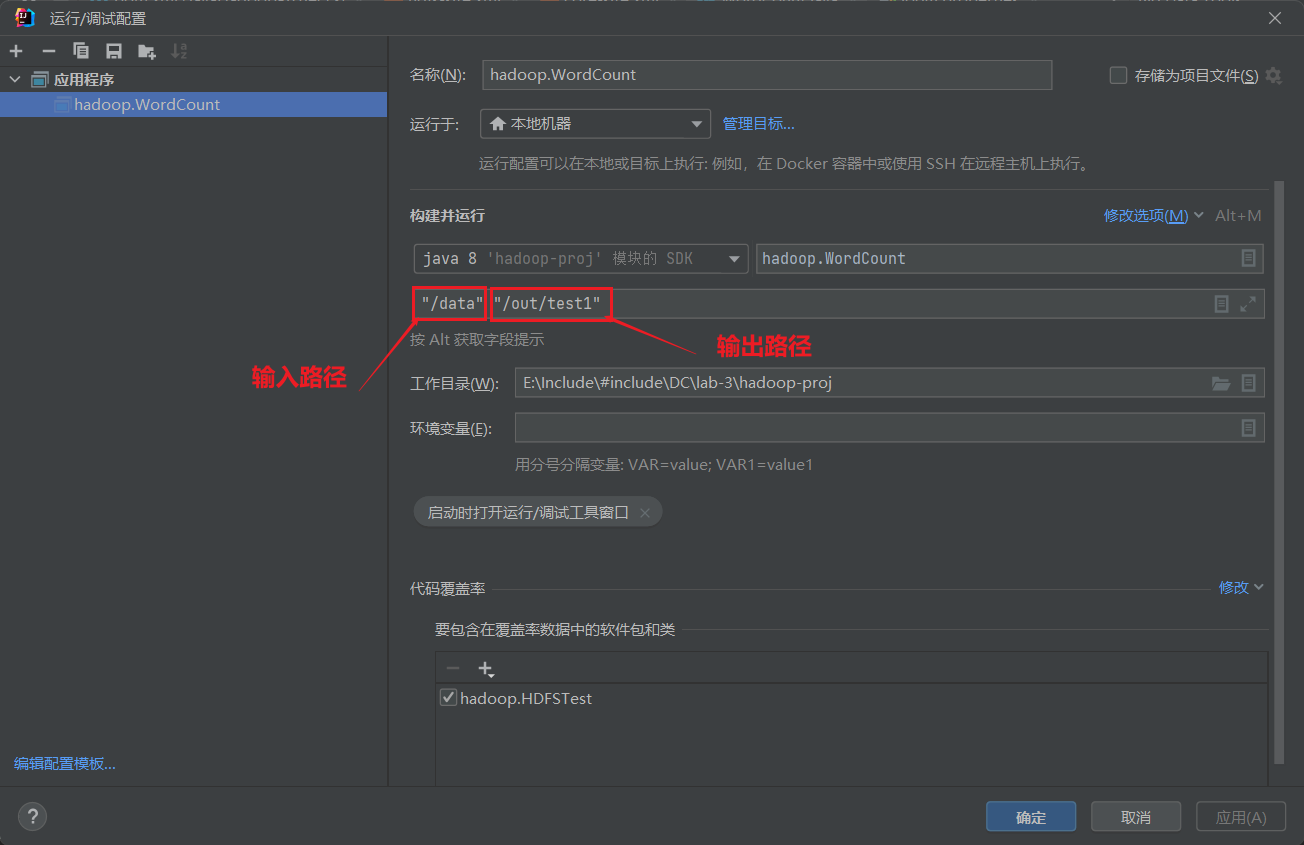
指定程序在HDFS中的输入输出路径
在编辑配置中进行设置
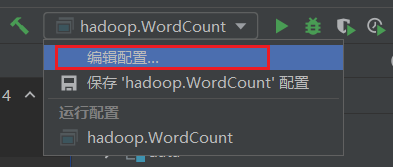
以空格为分割指定输入输出路径
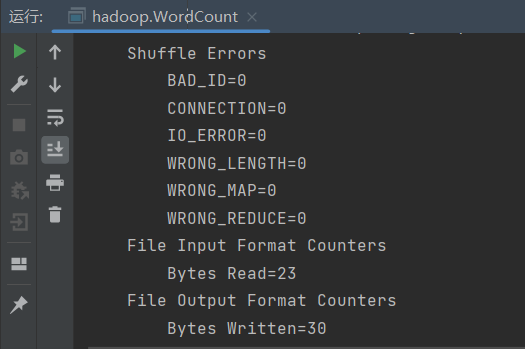
执行程序 查看输出结果
输出语句有几十行 最后几行程序输出如下
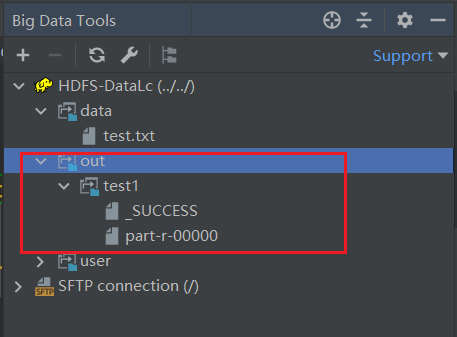
同时查看侧边栏中的HDFS 可看到out目录中已经出现了输出结果
参考文档
win10下IDEA连接虚拟机上的HDFS实现文件操作
利用IDEA通过创建Maven项目来实现hadoop相关项目
在windows系统中安装配置hadoop环境变量
idea连接本地虚拟机Hadoop集群运行wordcount
Windows下IntelliJ IDEA远程连接服务器中Hadoop运行WordCount
hadoop 9000端口只能本地127.0.0.1访问解决方案
hadoop.dll Download
Download-link-Github
登录后可发表评论
点击登录