LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking
ABSTRACT
自监督预训练技术在文档人工智能方面取得了显着的进步。大多数多模态预训练模型使用掩码语言建模目标来学习文本模态的双向表示,但它们在图像模态的预训练目标上有所不同。这种差异增加了多模态表示学习的难度。在本文中,我们提出 LayoutLMv3 来通过统一的文本和图像掩码来预训练文档 AI 的多模态 Transformer。此外,LayoutLMv3 还使用单词补丁对齐目标进行了预训练,通过预测文本单词的相应图像补丁是否被屏蔽来学习跨模态对齐。简单的统一架构和训练目标使 LayoutLMv3 成为适用于以文本为中心和以图像为中心的文档 AI 任务的通用预训练模型。实验结果表明,LayoutLMv3 不仅在以文本为中心的任务(包括表单理解、收据理解和文档视觉问答)中实现了最先进的性能,而且在以图像为中心的任务(如文档图像分类和文档布局分析)中也实现了最先进的性能。代码和模型可在 https://aka.ms/layoutlmv3 上公开获取。微软亚洲研究院:文档智能多模态预训练模型LayoutLMv3:兼具通用性与优越性 (msra.cn)论文地址:[2204.08387] LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking (arxiv.org),论文被计算机多媒体领域顶会 ACM Multimedia 2022 接收为 Oral Presentation现实生活中的文档不仅有大量的文本信息,同时也包含丰富的布局和视觉信息,并且这三种模态在文档中有天然的对齐特性。如何对这些文档进行建模并且通过训练达到跨模态对齐是一个重要的研究课题。对此,微软亚洲研究院在文档智能领域进行了诸多探索,推出了通用文档理解预训练 LayoutLM 系列研究成果。这些成果不仅在学术界受到了广泛关注和认可,在工业界也得到了广泛应用,如微软 Azure 认知服务中的表单识别器(Form Recognizer)等。 LayoutLM——通过将文本和布局进行联合预训练,在多种文档理解任务上取得了显著提升。LayoutLMv2——通过将视觉特征信息融入到预训练过程中,大大提高了模型的图像理解能力。LayoutXLM——基于 LayoutLMv2 的模型结构,通过使用53种语言进行预训练,拓展了 LayoutLM 的多语言支持。
INTRODUCTION
自监督学习利用大量无标注数据,在表征学习中取得了快速进展。在自然语言处理研究中,BERT 首先提出了“掩码语言建模”(Masked Language Modeling, MLM)的自监督预训练方法,通过随机遮盖文本中一定比例的单词,并根据上下文重建被遮盖的单词来学习具有上下文语义的表征。虽然大多数用于文档智能的多模态预训练模型在语言模态上使用了 MLM,但它们在图像模态的预训练目标有所不同。例如,有的模型目标是重建密集的图像像素或是重建连续的局部区域特征,这些方法倾向于学习嘈杂的细节,而不是高层结构(如文档布局)。并且,图像和文本目标的粒度不同进一步增加了跨模态对齐学习的难度,而跨模态对齐学习对多模态表示学习非常关键。此外,对于文档来说,每个文本词都对应着一个图像块。为了学习这种跨模态的对齐关系,研究员们还提出了一个词块对齐预训练目标,通过预测一个文本词的对应图像块是否被遮盖,来学习这种语言——图像细粒度对齐关系。为了克服文本和图像在预训练目标上的差异,促进多模态表征学习,微软亚洲研究院的研究员们提出了 LayoutLMv3,以统一的文本和图像掩码建模目标来预训练多模态模型,即 LayoutLMv3 学习重建语言模态的遮盖词 ID,并对称地重建图像模态的遮盖图像块 ID。
近年来,预训练技术在文档理解任务方面取得了显着进展,在文档人工智能社区中掀起了波澜。如下图所示,预训练的文档AI模型可以解析扫描表格和学术论文等各种文档的布局并提取关键信息,这对于工业应用和学术研究非常重要。

(a) FUNSD 上以文本为中心的形式理解;(b) PubLayNet 上以图像为中心的布局分析
虽然为特定任务设计的深度学习方法针对某一项文档理解任务能取得较好的性能,但这些方法通常依赖于有限的标注数据,而对于文档理解任务尤其是其中的信息抽取任务来说,获取详细的标注数据昂贵且耗时。为此,微软亚洲研究院的研究人员将目光转向了那些被忽视的无标注数据上,通过自监督预训练技术来利用现实生活中大量的无标注数据。由于近年来预训练在深度学习领域被广泛应用,所以该技术在文档智能领域也取得了显著进展。经过预训练的文档智能模型可以解析并提取文档的各类信息,这对文档智能的学术研究和生产应用都有重要意义。
自监督预训练技术由于其重建预训练目标的成功应用,在表示学习方面取得了快速进展。在 NLP 研究中,BERT 首先提出了“掩码语言建模”(MLM),通过根据上下文预测随机掩码词标记的原始词汇 ID 来学习双向表示。尽管大多数高性能多模态预训练文档 AI 模型都使用 BERT 提出的文本模态 MLM,但它们在图像模态的预训练目标上有所不同,如下图所示。
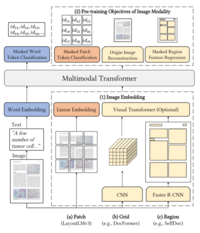
与现有工作(例如 DocFormer 和 SelfDoc )在(1)图像嵌入方面的比较:我们的 LayoutLMv3 使用线性补丁来减少 CNN 的计算瓶颈,并消除训练目标检测器时对区域监督的需要; (2) 图像模态的预训练目标:我们的 LayoutLMv3 学习重建掩模补丁的离散图像标记而不是原始像素或区域特征,以捕获高级布局结构而不是噪声细节。
在模型架构设计上,LayoutLMv3 不依赖复杂的 CNN 或 Faster R-CNN 网络来表征图像,而是直接利用文档图像的图像块,从而大大节省了参数并避免了复杂的文档预处理(如人工标注目标区域框和文档目标检测)。简单的统一架构和训练目标使 LayoutLMv3 成为通用的预训练模型,可适用于以文本为中心和以图像为中心的文档 AI 任务。
例如,DocFormer 学习通过 CNN 解码器重建图像像素 ,它倾向于学习嘈杂的细节,而不是高级结构,例如文档布局 。 SelfDoc 提出回归屏蔽区域特征,这比在较小词汇量中对离散特征进行分类噪音更大且更难学习。图像(例如,密集图像像素或连续区域特征)和文本(即离散标记)目标的不同粒度进一步增加了跨模态对齐学习的难度,而这对于多模态表示学习至关重要。
为了克服文本和图像模态预训练目标的差异并促进多模态表示学习,我们提出 LayoutLMv3 来预训练文档 AI 的多模态 Transformer,具有统一的文本和图像掩蔽目标 MLM 和 MIM。如下图所示,LayoutLMv3 学习重建文本模态的屏蔽词标记,并对称地重建图像模态的屏蔽补丁标记。受 DALL-E 和 BEiT 的启发,我们从离散 VAE 的潜在代码中获取目标图像标记。对于文档,每个文本单词对应一个图像块。为了学习这种跨模态对齐,我们提出了单词补丁对齐(WPA)目标来预测文本单词的相应图像补丁是否被屏蔽。
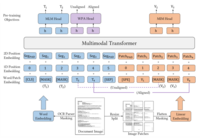
LayoutLMv3的架构和预训练目标。 LayoutLMv3 是用于文档 AI 的预训练多模态 Transformer,具有统一的文本和图像屏蔽目标。给定输入文档图像及其相应的文本和布局位置信息,该模型将补丁和单词标记的线性投影作为输入,并将它们编码为上下文向量表示。 LayoutLMv3 使用掩码语言建模 (MLM) 和掩码图像建模 (MIM) 的离散标记重建目标进行了预训练。此外,LayoutLMv3 还使用字补丁对齐 (WPA) 目标进行预训练,通过预测文本字的相应图像补丁是否被屏蔽来学习跨模态对齐。 “Seg”表示段级位置。 “[CLS]”、“[MASK]”、“[SEP]”和“[SPE]”是特殊标记。
受 ViT 和 ViLT 的启发,LayoutLMv3 直接利用文档图像中的原始图像补丁,无需复杂的预处理步骤(例如页面对象检测)。 LayoutLMv3 在 Transformer 模型中联合学习图像、文本和多模态表示,具有统一的 MLM、MIM 和 WPA 目标。这使得 LayoutLMv3 成为第一个无需 CNN 进行图像嵌入的多模态预训练文档 AI 模型,可显着节省参数并摆脱区域注释。简单的统一架构和目标使 LayoutLMv3 成为适用于以文本为中心的任务和以图像为中心的文档 AI 任务的通用预训练模型。
我们通过五个公共基准评估了预训练的 LayoutLMv3 模型,包括以文本为中心的基准:用于表单理解的 FUNSD 、用于收据理解的 CORD 、用于文档视觉问答的 DocVQA 和以图像为中心的基准:RVL- CDIP 用于文档图像分类,PubLayNet 用于文档布局分析。实验结果表明,LayoutLMv3 在这些基准测试中以参数效率实现了最先进的性能。此外,LayoutLMv3 因其简单、整洁的架构和预训练目标而易于重现。我们的贡献总结如下:
LayoutLMv3 是 Document AI 中第一个不依赖预训练 CNN 或 Faster R-CNN 主干来提取视觉特征的多模态模型,这显着节省了参数并消除了区域注释。
LayoutLMv3 通过统一的离散标记重建目标 MLM 和 MIM 减轻了文本和图像多模态表示学习之间的差异。我们进一步提出了单词补丁对齐(WPA)目标,以促进跨模式对齐学习。
LayoutLMv3 是一个通用模型,适用于以文本为中心和以图像为中心的文档 AI 任务。我们首次展示了多模态 Transformer 在 Document AI 中视觉任务的通用性。
实验结果表明,LayoutLMv3 在文档 AI 中以文本为中心的任务和以图像为中心的任务中实现了最先进的性能。代码和模型可在 https://aka.ms/layoutlmv3 上公开获取。
企业数字化转型中,以文档、图像等多模态形式为载体的结构化分析和内容提取是其中的关键一环,快速、自动、精准地处理包括合同、票据、报告等信息,对提升现代企业生产效率至关重要。因此,文档智能技术应运而生。过去几年,微软亚洲研究院推出了通用文档理解预训练 LayoutLM 系列研究成果,并不断优化模型对文档中文本、布局和视觉信息的预训练性能。随着各行各业的数字化转型,涵盖表单、票据、邮件、合同、报告、论文等的电子文档数量持续增长。电子文档包含大量与行业相关的图像和文本信息,人工处理这些大量的信息耗时长、成本大。电子文档的自动识别、理解和分析技术对提高个人或企业的生产力十分重要,因此文档智能技术应运而生。文档智能利用计算机自动识别、理解及分析电子文档,大大提升了个人和企业处理电子文档的生产力,是自然语言处理和计算机视觉交叉领域的一个重要研究方向。
LayoutLMv3 还应用了文本——图像多模态 Transformer 架构来学习跨模态表征。文本向量由词向量、词的一维位置向量和二维位置向量相加得到。文档图像的文本和其相应的二维位置信息(布局信息)则利用光学字符识别(OCR)工具抽取。因为文本的邻接词通常表达了相似的语义,LayoutLMv3 共享了邻接词的二维位置向量,而 LayoutLM 和 LayoutLMv2 的每个词则用了不同的二维位置向量。
图像向量的表示通常依赖于 CNN 抽取特征图网格特征或 Faster R-CNN 提取区域特征,这些方式增加了计算开销或依赖于区域标注。因此,研究员们将图像块经过线性映射获得图像特征,这种图像表示方式最早在 ViT 中被提出,计算开销极小且不依赖于区域标注,有效解决了以上问题。具体来说,首先将图像缩放为统一的大小(例如224x224),然后将图像切分成固定大小的块(例如16x16),并通过线性映射获得图像特征序列,再加上可学习的一维位置向量后得到图像向量。
LAYOUTLMV3
Model Architecture
LayoutLMv3 应用统一的文本图像多模态 Transformer 来学习跨模态表示。 Transformer 具有多层架构,每层主要由多头自注意力和位置全连接前馈网络组成。 Transformer 的输入是文本嵌入 Y = y1:L 和图像嵌入 X = x1:M 序列的串联,其中 L 和 M 分别是文本和图像的序列长度。通过 Transformer,最后一层输出文本和图像上下文表示。
Text Embedding. 文本嵌入是词嵌入和位置嵌入的组合。我们使用现成的 OCR 工具包对文档图像进行预处理,以获得文本内容和相应的 2D 位置信息。我们使用预训练模型 RoBERTa 中的词嵌入矩阵来初始化词嵌入。位置嵌入包括 1D 位置嵌入和 2D 布局位置嵌入,其中 1D 位置是指文本序列中标记的索引,2D 布局位置是指文本序列的边界框坐标。遵循 LayoutLM,我们通过图像的大小标准化所有坐标,并使用嵌入层分别嵌入 x 轴、y 轴、宽度和高度特征 。 LayoutLM和LayoutLMv2采用字级布局位置,每个字都有其位置。相反,我们采用段级布局位置,段中的单词共享相同的2D位置,因为单词通常表达相同的语义。
Image Embedding. Document AI 中现有的多模态模型要么提取 CNN 网格特征 ,要么依赖 Faster R-CNN 等对象检测器来提取图像嵌入的区域特征,这占了严重的计算瓶颈或需要区域监督。受 ViT 和 ViLT 的启发,我们在将文档图像输入多模态 Transformer 之前,用图像块的线性投影特征来表示文档图像。具体来说,我们将文档图像的大小调整为 H × W 并用 I ∈ R C × H × W I ∈ \R^{C×H×W} I∈RC×H×W 表示图像,其中 C、H 和 W 分别是图像的通道大小、宽度和高度。然后,我们将图像分割成一系列均匀的 P × P 块,将图像块线性投影到 D 维度,并将它们展平为向量序列,其长度为 M = HW /P^2。然后,我们向每个补丁添加可学习的 1D 位置嵌入,因为我们在初步实验中没有观察到使用 2D 位置嵌入带来的改进。 LayoutLMv3 是 Document AI 中第一个不依赖 CNN 提取图像特征的多模态模型,这对于 Document AI 模型减少参数或删除复杂的预处理步骤至关重要。
我们将语义 1D 相对位置和空间 2D 相对位置作为偏差项插入到遵循 LayoutLMv2 的文本和图像模态的自注意力网络中。
Pre-training Objectives
LayoutLMv3 使用 MLM、MIM 和 WPA 目标进行预训练,以自监督学习方式学习多模态表示。 LayoutLMv3 的完整预训练目标定义为 L = L M L M + L M I M + L W P A L = L_{MLM} + L_{MIM} + L_{WPA} L=LMLM+LMIM+LWPA。
目标 I:掩码语言建模 (MLM)。对于语言方面,我们的 MLM 受到 BERT 中的屏蔽语言建模以及 LayoutLM 和 LayoutLMv2 中的屏蔽视觉语言建模的启发。我们使用跨度掩码策略来掩码 30% 的文本标记,跨度长度取自泊松分布 (λ = 3) 。预训练的目标是基于图像标记 X M ′ X^{M'} XM′ 和文本标记 Y L ′ Y^{L'} YL′ 的损坏序列的上下文表示,最大化正确屏蔽文本标记 y l y^l yl 的对数似然,其中 M ′ M' M′ 和 L ′ L' L′ 表示屏蔽的文本标记职位。我们用 θ \theta θ 表示 Transformer 模型的参数,并最小化随后的交叉熵损失:
L M L M ( θ ) = − ∑ l = 1 L ′ l o g p θ ( y l ∣ X M ′ , Y L ′ ) , ( 1 ) L_{MLM}(\theta)=-\sum_{l=1}^{L'}logp_{\theta}(y_l|X^{M'},Y^{L'}),(1) LMLM(θ)=−l=1∑L′logpθ(yl∣XM′,YL′),(1)
由于我们保持布局信息不变,这个目标有助于模型学习布局信息与文本和图像上下文之间的对应关系。
目标 II:掩模图像建模 (MIM)。为了鼓励模型从上下文文本和图像表示中解释视觉内容,我们将 BEiT 中的 MIM 预训练目标调整为我们的多模态 Transformer 模型。 MIM 目标与 MLM 目标对称,即我们使用块屏蔽策略随机屏蔽约 40% 的图像标记 。 MIM 目标由交叉熵损失驱动,以在周围文本和图像标记的背景下重建屏蔽图像标记 x m x_m xm。
L M I M ( θ ) = − ∑ m = 1 M ′ l o g p θ ( x m ∣ X M ′ , Y L ′ ) , ( 2 ) L_{MIM}(\theta)=-\sum_{m=1}^{M'}logp_{\theta}(x_m|X^{M'},Y^{L'}),(2) LMIM(θ)=−m=1∑M′logpθ(xm∣XM′,YL′),(2)
图像标记的标签来自图像标记器,它可以根据视觉词汇表将密集图像像素转换为离散标记。因此,MIM 有助于学习高级布局结构,而不是嘈杂的低级细节。
目标 III:字补丁对齐 (WPA)。对于文档,每个文本单词对应一个图像块。由于我们分别使用 MLM 和 MIM 随机屏蔽文本和图像标记,因此文本和图像模态之间没有明确的对齐学习。因此,我们提出了一个 WPA 目标来学习文本单词和图像块之间的细粒度对齐。 WPA 的目标是预测文本单词对应的图像块是否被屏蔽。具体来说,当对应的图像标记也未被屏蔽时,我们将对齐的标签分配给未被屏蔽的文本标记。否则,我们分配一个未对齐的标签。我们在计算 WPA 损失时排除屏蔽文本标记,以防止模型学习屏蔽文本单词和图像块之间的对应关系。我们使用两层 MLP 头输入上下文文本和图像,并输出具有二进制交叉熵损失的二进制对齐/未对齐标签:
L W P A ( θ ) = − ∑ l = 1 L − L ′ l o g p θ ( z l ∣ X M ′ , Y L ′ ) L_{WPA}(\theta)=-\sum_{l=1}^{L-L'}logp_{\theta}(z_l|X^{M'},Y^{L'}) LWPA(θ)=−l=1∑L−L′logpθ(zl∣XM′,YL′)
其中L−L′是未屏蔽文本标记的数量,zℓ是ℓ位置的语言标记的二进制标签。
掩码语言建模(Masked Language Modeling, MLM)。为了利于模型学习布局信息与文本和图像之间的对应关系,该任务随机遮盖30%的文本词向量,但保留对应的二维位置(布局)信息。类似 BERT 和 LayoutLM,模型目标是根据未被遮盖的图文和布局信息还原文本中被遮盖的词。
掩码图像建模(Masked Image Modeling, MIM)。为了鼓励模型从文本和图像的上下文信息推测图像信息,该任务随机遮盖了约40%的图像块。类似 BEiT,模型目标是根据未被遮盖的文本和图像的信息还原被遮盖的图像块经过离散化的 ID。
词块对齐(Word-Patch Alignment, WPA)。对于文档来说,每个文本词都对应着一个图像块。由于前两个任务随机遮盖了部分文本词和图像块,模型无法显式地学习这种文本词和图像块之间的细粒度对齐关系。该目标通过显式地预测一个文本词的对应图像块是否被掩盖来学习语言和视觉模态之间的细粒度对齐关系。
EXPERIMENTS
Model Configurations
LayoutLMv3 的网络架构遵循 LayoutLM 和 LayoutLMv2 的网络架构,以便进行公平比较。我们对 LayoutLMv3 使用基本模型尺寸和大模型尺寸。 LayoutLMv3BASE采用12层Transformer编码器,具有12头自注意力,隐藏大小D = 768,前馈网络的中间大小为3,072。LayoutLMv3LARGE采用24层Transformer编码器,具有16头自注意力,隐藏大小D = 1, 024, 前馈网络的中间大小为4,096。为了预处理文本输入,我们使用字节对编码(BPE)对文本序列进行标记,最大序列长度 L = 512。我们在开头和结尾添加一个 [CLS] 和一个 [SEP] 标记每个文本序列。当文本序列的长度短于 L 时,我们向其附加 [PAD] 标记。这些特殊标记的边界框坐标均为零。图像嵌入的参数为 C × H × W = 3 × 224 × 224,P = 16,M = 196。
我们采用分布式和混合精度训练来降低内存成本并加快训练过程。我们还使用梯度累积机制将样本批次分成几个小批次,以克服大批次大小的内存限制。我们进一步使用梯度检查点技术进行文档布局分析,以减少内存成本。为了稳定训练,我们按照 CogView 将注意力的计算更改为 s o f t m a x ( Q T K / d ) = s o f t m a x ( ( Q T K / ( α d ) − m a x ( Q T K α d ) ) ∗ α ) softmax (Q^TK/\sqrt{d}) = softmax ((Q^TK/(\alpha\sqrt{d})-max(\frac{Q^TK}{\alpha\sqrt{d}}))*\alpha) softmax(QTK/d )=softmax((QTK/(αd )−max(αd QTK))∗α),其中 α 为 32。
Pre-training LayoutLMv3
为了学习各种文档任务的通用表示,我们在大型 IIT-CDIP 数据集上预训练 LayoutLMv3。 IITCDIP Test Collection 1.0是一个大规模扫描文档图像数据集,包含约1100万张文档图像,可分割为4200万页。我们只使用其中的 1100 万个来训练 LayoutLMv3。我们不按照 LayoutLM 模型进行图像增强。对于多模态 Transformer 编码器以及文本嵌入层,LayoutLMv3 是根据 RoBERTa 的预训练权重进行初始化的。我们的图像标记器是从 DiT 中预训练的图像标记器初始化的,DiT 是一种自监督的预训练文档图像 Transformer 模型 。图像标记的词汇量为 8,192。我们随机初始化其余模型参数。我们使用 Adam 优化器预训练 LayoutLMv3,批量大小为 2,048,步数为 500,000。我们使用 1e− 2 的权重衰减,并且 (β1, β2) = (0.9, 0.98)。对于 LayoutLMv3BASE 模型,我们使用 1e − 4 的学习率,并在前 4.8% 的步骤中线性预热学习率。对于 LayoutLMv3LARGE,学习率和预热比分别为 5e− 5 和 10%。Fine-tuning on Multimodal Tasks
我们将 LayoutLMv3 与典型的自监督预训练方法进行比较,并按预训练方式对它们进行分类。
[T] 文本模态:BERT 和 RoBERTa 是典型的预训练语言模型,仅使用具有 Transformer 架构的文本信息。我们使用来自 LayoutLM 的 RoBERTa 的 FUNSD 和 RVLCDIP 结果以及来自 LayoutLMv2 的 BERT 结果。我们重现并报告 RoBERTa 的 CORD 和 DocVQA 结果。
[T+L] 文本和布局模式:LayoutLM 通过将字级空间嵌入添加到 BERT 的嵌入中来合并布局信息。 StructuralLM 利用段级布局信息 。 BROS 对相对布局位置进行编码 。 LILT 使用预先训练的文本模型对不同语言进行微调 。 FormNet 利用表单中标记之间的空间关系。
[T+L+I ®] 具有 Faster R-CNN 区域特征的文本、布局和图像模态:这一系列工作从 Faster R-CNN 模型中的 RoI 头中提取图像区域特征 。其中,LayoutLM 和TILT 使用OCR单词的边界框作为区域建议,并将区域特征添加到相应的文本嵌入中。SelfDoc 和 UDoc 使用文档对象提案并将区域特征与文本嵌入连接起来。
[T+L+I (G)] 具有 CNN 网格特征的文本、布局和图像模态:LayoutLMv2 和 DocFormer 使用 CNN 主干提取图像网格特征,无需进行对象检测。 XYLayoutLM 采用LayoutLMv2的架构并改进了布局表示。
[T+L+I §] 具有线性补丁特征的文本、布局和图像模态:LayoutLMv3 用简单的线性嵌入替换 CNN 主干来编码图像补丁。
我们在公开可用的基准上对多模式任务的 LayoutLMv3 进行了微调。结果如下表所示。

与 CORD 、FUNSD 、RVL-CDIP 和 DocVQA 数据集上现有已发布模型的比较。“T/L/I”表示“文本/布局/图像”模式。 “R/G/P”表示“区域/网格/补丁”图像嵌入。为了更好的可读性,我们将所有值乘以一百。 †在 UDoc 论文中,CORD 分割是用于训练/测试的 626/247 收据,而不是其他作品采用的官方 800/100 训练/测试收据。因此,该分数†不能与其他分数直接比较。用 ‡ 表示的模型使用更多数据来训练 DocVQA,预计得分更高。例如,TILT 在更多 QA 数据集上引入了一个多监督训练阶段 。 StructuralLM 在训练中还使用了验证集 。
任务一:表格和收据理解。表格和收据理解任务需要提取和构建表格和收据的文本内容。这些任务是一个序列标记问题,旨在用标签标记每个单词。我们分别使用线性层和 MLP 分类器来预测每个文本标记的最后隐藏状态的标签,用于表格和收据理解任务。
我们在 FUNSD 数据集和 CORD 数据集上进行了实验。 FUNSD 是从 RVL-CDIP 数据集 中采样的噪声扫描形式理解数据集。 FUNSD 数据集包含 199 个文档,其中包含 9,707 个语义实体的综合注释。我们专注于 FUNSD 数据集上的语义实体标记任务,为每个语义实体分配“问题”、“答案”、“标题”或“其他”之间的标签。训练和测试部分分别包含 149 个和 50 个样本。 CORD是一个收据关键信息提取数据集,在4个类别下定义了30个语义标签。它包含 800 个训练、100 个验证和 100 个测试示例的 1,000 个收据。我们使用官方提供的图像和 OCR 注释。我们将 LayoutLMv3 微调为 1,000 个步骤,FUNSD 的学习率为 1e − 5,批量大小为 16,CORD 的学习率,批量大小为 5e − 5 和 64。
我们报告此任务的 F1 分数。对于大模型尺寸,LayoutLMv3 在 FUNSD 数据集上获得了 92.08 的 F1 分数,显着优于 StructuralLM 提供的 85.14 的 SOTA 结果。请注意,LayoutLMv3 和 StructuralLM 使用段级布局位置,而其他作品则使用字级布局位置。使用段级位置可能有利于 FUNSD 上的语义实体标记任务,因此两种类型的工作不能直接比较。 LayoutLMv3 还在 CORD 数据集上的基本模型尺寸和大型模型尺寸上获得了 SOTA F1 分数。结果表明,LayoutLMv3 可以显着有益于以文本为中心的表单和收据理解任务。
任务二:文档图像分类。文档图像分类任务旨在预测文档图像的类别。我们将特殊分类标记 ([CLS]) 的输出隐藏状态输入 MLP 分类器以预测类标签。
我们在 RVL-CDIP 数据集上进行实验。它是 IIT-CDIP 集合的子集,标记有 16 个类别 。 RVL-CDIP数据集包含400,000张文档图像,其中320,000张是训练图像,40,000张是验证图像,40,000张是测试图像。我们使用 Microsoft Read API 提取文本和布局信息。我们将 LayoutLMv3 微调为 20,000 个步骤,批量大小为 64,学习率为 2e − 5。
评价指标是总体分类准确率。 LayoutLMv3 使用比以前的作品小得多的模型尺寸实现了更好或可比的结果。例如,与 LayoutLMv2 相比,LayoutLMv3 在基本模型和大模型尺寸上分别实现了 0.19% 和 0.29% 的绝对改进,并且图像嵌入更加简单(即 Linear 与 ResNeXt101-FPN)。结果表明,我们简单的图像嵌入可以在以图像为中心的任务上取得理想的结果。
任务三:Document Visual Question Answering. 文档视觉问答需要一个模型将文档图像和问题作为输入并输出答案。我们将此任务形式化为提取式 QA 问题,其中模型通过使用二元分类器对每个文本标记的最后隐藏状态进行分类来预测开始和结束位置。
我们在 DocVQA 数据集上进行了实验,这是一个用于文档图像视觉问答的标准数据集 。 DocVQA 数据集的官方分区分别包含 10,194/1,286/1,287 个图像和 39,463/5,349/5,188 个训练/验证/测试集问题。我们在训练集上训练模型,在测试集上评估模型,并将结果提交到官方评估网站来报告结果。我们使用 Microsoft Read API 从图像中提取文本和边界框,并使用启发式方法在提取的文本中查找给定答案,如 LayoutLMv2 中所示。我们将 LayoutLMv3BASE 微调为 100,000 个步骤,批量大小为 128,学习率为 3e − 5,预热比率为 0.048。对于 LayoutLMv3LARGE,步长、批量大小、学习率和预热比率分别为 200,000、32、1e − 5 和 0.1。我们报告了常用的基于编辑距离的度量 ANLS(也称为平均标准化编辑相似度)。 LayoutLMv3BASE 将 LayoutLMv2BASE 的 ANLS 分数从 78.08 提高到 78.76,图像嵌入更加简单(即从 ResNeXt101-FPN 到线性嵌入)。与 LayoutLMv3BASE 相比,LayoutLMv3LARGE 进一步获得了 4.61 的绝对 ANLS 分数。结果表明LayoutLMv3对于文档视觉问答任务是有效的。
Fine-tuning on a Vision Task
为了证明 LayoutLMv3 从多模态领域到视觉领域的通用性,我们将 LayoutLMv3 转移到文档布局分析任务。此任务是通过提供边界框和类别(例如表格、图形、文本等)来检测非结构化数字文档的布局。此任务有助于将文档解析为下游应用程序的机器可读格式。我们将此任务建模为没有文本嵌入的对象检测问题,这在现有工作中是有效的[。我们将 LayoutLMv3 作为 Cascade R-CNN 检测器中的特征骨干与使用 Detectron2 实现的 FPN 集成。我们采用标准做法从不同的 Transformer 层中提取单尺度特征,例如 LayoutLMv3 基础模型的第 4、6、8 和 12 层。我们使用分辨率修改模块将单尺度特征转换为多尺度 FPN 特征 。
我们在 PubLayNet 数据集上进行实验。该数据集包含带有边界框和多边形分割注释的研究论文图像,跨五个文档布局类别:文本、标题、列表、图形和表格。官方分割包含 335,703 个训练图像、11,245 个验证图像和 11,405 个测试图像。我们按照标准实践 在训练分割上训练我们的模型,并在验证分割上评估我们的模型。我们使用 AdamW 优化器对模型进行 60,000 个步骤的训练,在 DiT 之后进行 1,000 个预热步骤和 0.05 的权重衰减。由于 LayoutLMv3 是使用视觉和语言模态的输入进行预训练的,因此我们根据经验使用较大的批量大小 32 和较低的学习率 2e − 4。我们在微调阶段不使用翻转或裁剪增强策略,以与我们的预训练阶段保持一致。我们不使用自注意力网络中的相对位置作为 DiT。
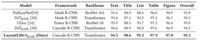
我们使用边界框的平均精度 (MAP) @ 并集交集 (IOU) [0.50:0.95] 来测量性能,并在下表中报告结果。我们与 ResNets 和并发视觉 Transformer 骨干。 LayoutLMv3 在所有指标上都优于其他模型,总体 mAP 得分为 95.1。 LayoutLMv3 在“标题”类别中取得了很高的增益。由于标题通常比其他类别小得多,并且可以通过其文本内容进行识别,因此我们将这种改进归因于我们在预训练 LayoutLMv3 中纳入了语言模态。这些结果证明了LayoutLMv3的通用性和优越性。
PubLayNet 验证集上的文档布局分析 mAP @ IOU [0.50:0.95]。所有模型仅使用来自视觉模态的信息。 LayoutLMv3 的性能优于所比较的 ResNets 和视觉 Transformer 主干网。
Ablation Study
在下表中,我们研究了图像嵌入和预训练目标的效果。我们首先构建一个基线模型#1,它使用文本和布局信息,并通过 MLM 目标进行预训练。然后我们使用线性投影图像块作为基线模型的图像嵌入,表示为模型#2。我们进一步使用 MIM 和 WPA 目标进一步预训练模型 #2,并将新模型分别表示为 #3 和 #4。

针对典型的以文本为中心的任务(FUNSD 和 CORD 上的表单和收据理解)和以图像为中心的任务(RVL-CDIP 上的文档图像分类和 PubLayNet 上的文档布局分析)的图像嵌入和预训练目标的消融研究。所有模型均以 BASE 大小、100 万个数据、150,000 个步骤进行训练,学习率为 3e − 4。
在下图中,我们可视化了模型 #2、#3 和 #4 在 PubLayNet 数据集上进行微调时的损失,批量大小为 16,学习率为 2e − 4。我们尝试训练模型 # 2,学习率为 {1e − 4, 2e − 4, 4e− 4},批量大小为 {16, 32},但模型 #2 的损失没有收敛,并且 PubLayNet 上的 mAP 分数接近零。
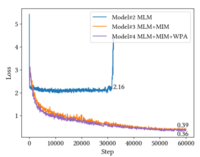
在 PubLayNet 数据集上微调 LayoutLMv3 消融模型的损失收敛曲线。模型#2 的损失没有收敛。通过合并 MIM 目标,损失可以正常收敛。 WPA 目标进一步减少了损失。最好以彩色形式观看。
Effect of Linear Image Embedding. 我们观察到,没有图像嵌入的模型#1 在某些任务上取得了良好的结果。这表明语言模态(包括文本和布局信息)在文档理解中起着至关重要的作用。然而,结果仍然不尽如人意。此外,如果没有视觉模态,模型#1 无法执行一些以图像为中心的文档分析任务。例如,视觉模态对于 PubLayNet 上的文档布局分析任务至关重要,因为边界框与图像紧密集成。我们简单的线性图像嵌入设计与适当的预训练目标相结合,不仅可以持续改进以图像为中心的任务,还可以进一步改进一些以文本为中心的任务。
MIM 预训练目标的效果。简单地将线性图像嵌入与文本嵌入连接作为模型 #2 的输入会降低 CORD 和 RVL-CDIP 上的性能,而 PubLayNet 上的损失则不同。我们推测,在没有任何与图像模态相关的预训练目标的情况下,该模型无法在线性块嵌入上学习有意义的视觉表示。MIM 目标通过随机屏蔽输入图像块的一部分并在输出中重建它们来保留图像信息直到模型的最后一层,从而缓解了这个问题。比较模型 #3 和模型 #2 的结果,MIM 目标有利于 CORD 和 RVL-CDIP。由于简单地使用线性图像嵌入改进了 FUNSD,因此 MIM 不会进一步对 FUNSD 做出贡献。通过在训练中结合 MIM 目标,在微调 PubLayNet 时损失会收敛,如上图所示,并且我们获得了理想的 mAP 分数。结果表明,MIM 可以帮助规范训练。因此,MIM 对于 PubLayNet 上的文档布局分析等视觉任务至关重要。
WPA 预训练目标的效果。通过比较上表中的模型 #3 和模型 #4,我们观察到 WPA 目标持续改进所有任务。此外,WPA 目标减少了上图中 PubLayNet 上视觉任务的损失。这些结果证实了 WPA 不仅在跨模态表示学习中的有效性,而且在图像表示学习中也有效。
参数比较。该表显示,将图像嵌入合并到 16×16 面片投影(#1 → #2)仅引入 0.6M 个参数。与 CNN 主干网的参数相比(例如 ResNet-101 的 44M),这些参数可以忽略不计。 MIM头和WPA头在预训练阶段引入了6.9M和0.6M参数。与 MLM 头相比,图像嵌入引入的参数开销是微乎其微的,MLM 头具有 39.2M 参数,文本词汇量为 50,265。在计算参数时,我们没有计算图像分词器的数量,因为分词器是用于生成 MIM 标签的独立模块,但未集成到 Transformer 主干中。
RELATED WORK
多模态自监督预训练技术由于其在文档布局和图像表示学习方面的成功应用,在文档智能领域取得了快速进展。 LayoutLM 及后续通过编码文本的空间坐标来进行联合布局表示学习 。然后,各种工作通过将 CNN 与 Transformer 自注意力网络相结合来联合图像表示学习。这些工作要么提取 CNN 网格特征 ,要么依赖对象检测器提取区域特征,这会造成大量计算瓶颈或需要区域监督。在自然图像视觉和语言预训练(VLP)领域,研究工作已经从区域特征到网格特征的转变,以解除预定义对象类的限制和区域监管。受视觉 Transformer 的启发,最近也有人在没有 CNN 的 VLP 方面做出了努力,以克服 CNN 的弱点。尽管如此,大多数还是依赖单独的自注意力网络来学习视觉特征;因此,它们的计算成本并没有减少。ViLT 是一个例外,它通过轻量级线性层学习视觉特征,并显着减少模型大小和运行时间 。受 ViLT 的启发,我们的 LayoutLMv3 是文档 AI 中第一个使用图像嵌入而不使用 CNN 的多模态模型。
重建预训练目标彻底改变了表征学习。在 NLP 研究中,BERT 首先提出“掩码语言建模”(MLM)来学习双向表示,并推进了广泛语言理解任务的最新技术 。在 CV 领域,掩模图像建模(MIM)旨在通过预测可见上下文中的掩模内容条件来学习丰富的视觉表示。例如,ViT 重建了掩模斑块的平均颜色,这导致 ImageNet 分类的性能提升 。 BEiT 重建了离散 VAE 学习的视觉标记,在图像分类和语义分割方面取得了有竞争力的结果 。 DiT 将 BEiT 扩展到文档图像和文档布局分析 。
受 MLM 和 MIM 的启发,视觉和语言领域的研究人员探索了多模态表征学习的重构目标。尽管大多数性能良好的视觉和语言预训练(VLP)模型都使用 BERT 提出的关于文本模态的 MLM,但它们在图像模态的预训练目标上有所不同。 MIM 存在对应于不同图像嵌入的三种变体:掩模区域建模(MRM)、掩模网格建模(MGM)和掩模补丁建模(MPM)。 MRM 已被证明可以有效地回归原始区域特征或对屏蔽区域的对象标签进行分类。 MGM 也在 SOHO 中进行了探索,其目标是预测视觉词典中屏蔽网格特征的映射索引 。对于补丁级图像嵌入,Visual Parsing 提出根据自注意力图像编码器中的注意力权重来屏蔽视觉标记,这不适用于简单的线性图像编码器。 ViLT 和 METER 尝试利用类似于 ViT 和 BEiT 的 MPM,分别重建图像块的视觉词汇中的平均颜色和离散标记,但导致下游任务的性能下降。我们的 LayoutLMv3 首先演示了 MIM 对于线性块图像嵌入的有效性。
进一步开发了各种跨模态目标,用于多模态模型中的视觉和语言(VL)对齐学习。图像文本匹配广泛用于学习粗粒度的 VL 对齐 。为了学习细粒度的 VL 对齐,UNITER 提出了基于最佳传输的字区域对齐目标,该目标计算将上下文图像嵌入传输到字嵌入的最小成本 。ViLT 将这一目标扩展到补丁级图像嵌入 。与自然图像不同,文档图像意味着文本单词和图像区域之间存在明确的细粒度对齐关系。利用这种关系,UDoc 使用对比学习和相似性蒸馏来对齐属于同一区域的图像和文本 。 LayoutLMv2 覆盖原始图像中的一些文本行并预测每个文本标记是否被覆盖 。相比之下,我们自然地利用 MIM 中的掩码操作以有效且统一的方式构造对齐/未对齐对。
CONCLUSION AND FUTURE WORK
在本文中,我们提出了 LayoutLMv3 来预训练 Document AI 的多模态 Transformer,它重新设计了 LayoutLM 的模型架构和预训练目标。与Document AI中现有的多模态模型不同,LayoutLMv3不依赖于预先训练的CNN或Faster R-CNN主干来提取视觉特征,显着节省了参数并消除了区域注释。我们使用统一的文本和图像屏蔽预训练目标:屏蔽语言建模、屏蔽图像建模和字补丁对齐,来学习多模态表示。大量的实验结果证明了 LayoutLMv3 对于以文本为中心和以图像为中心的文档 AI 任务的通用性和优越性,具有简单的架构和统一的目标。在未来的研究中,我们将研究扩大预训练模型的规模,以便模型可以利用更多的训练数据来进一步推动 SOTA 结果。此外,我们还将探索fewshot和zero-shot学习能力,以促进文档AI行业更多真实的业务场景。APPENDIX
LayoutLMv3 in Chinese
中文预训练LayoutLMv3。为了证明 LayoutLMv3 不仅在英语中而且在中文中的有效性,我们在基本尺寸上预训练了 LayoutLMv3-Chinese 模型。它接受了 5000 万个中文文档页的训练。我们通过下载公开的数字化文档并遵循Common Crawl(https://commoncrawl.org/)的原则来处理这些文档来收集大规模的中文文档。对于多模态 Transformer 编码器以及文本嵌入层,LayoutLMv3-Chinese 是根据 XLM-R 的预训练权重进行初始化的。我们随机初始化其余模型参数。其他训练设置与LayoutLMv3相同。
视觉信息提取的微调。视觉信息提取(VIE)需要从文档图像中提取关键信息。该任务是一个序列标记问题,旨在用预定义的标签标记每个单词。我们用线性层预测每个文本标记的最后一个隐藏状态的标签。
我们在 EPHOIE 数据集上进行实验。 EPHOIE 是一个视觉信息提取数据集,由具有不同布局和背景的试卷头部组成。它包含 1,494 张图像,并对 15,771 个中文文本实例进行了全面注释。我们专注于 EPHOIE 数据集上的标记级实体标记任务,为每个字符分配十个预定义类别中的标签。训练集和测试集分别包含 1,183 个和 311 个图像。我们对 LayoutLMv3-Chinese 进行了 100 个 epoch 的微调。批量大小为 16,学习率为 5e − 5,在第一个 epoch 内进行线性预热。
我们报告了该任务的 F1 分数,并在下表 中报告了结果。LayoutLMv3-Chinese 在大多数指标上都显示出卓越的性能,并实现了 99.21% 的 SOTA 平均 F1 分数。结果表明,LayoutLMv3 对中文 VIE 任务有显着的好处。

EPHOIE 测试集上中文 F1 分数的视觉信息提取。
文档基础模型引领文档智能走向多模态大一统 (msra.cn)“我们看到,在人工智能领域的研究中,包括 NLP、CV 等不同模态的研究都在呈现大一统 (Big Convergence) 的趋势,不同领域都在进行统一模型的研究。LayoutLM 的前两个版本着重解决的是语言处理问题,而 LayoutLMv3 最大的特点是可以同时应对 NLP 和 CV 两种模态的任务,在计算视觉领域取得了较大的突破,”微软亚洲研究院高级研究员崔磊表示。