
大厂面试题分享 面试题库
前后端面试题库 (面试必备) 推荐:★★★★★
地址:前端面试题库
前言
大厂面试中除了问常见的算法网络基础,和一些八股文手写体之外,经常出现的一个问题就是,你做过什么项目吗?
看似简单的题目却让很多同学不知如何回答,因为面试就像相亲一样,你心仪的妹子不想听你说小学二年级还拿过三好学生,她其实只想了解现在的你,有什么特点和优点
项目也是一样, 面试官其实是想看看你做过什么有亮点的项目, 其实大家日常做的项目都差不多,增删改查,登录注册,弹窗等等,所谓有亮点,就是在这些实现功能的基础上,在以下几个方面做出了探索和优化, 个人能力有限,先聊这几个方面
大数据量优化
研发效率的提高
研发质量的提高
性能优化
用户体验优化
复杂 & 新场景
....
我们以大家都做过的需求举例,通过优化,每个需求都可以做成有亮点的需求,也就是所谓企业级的项目
欢迎加我,畅聊前端 & 英语学习
大数据量
想做出亮点,首先做一些你周围同事做不到的需求,首先就是数据量变大,变得贼大,虽然大部分场景遇不到,但是挡不住骚包面试官喜欢问,我们只聊面试
场景1: 课程页面,增删改查
这种场景,我们可以让数据量变成1W行,大部分场景都是分页,只有极端场景(移动端无限滚动的商品页),如果直接渲染1W行列表,不出意外你的页面就要卡了,比较常见的优化方案就是虚拟滚动,就是只渲染你能看到的视窗中的几十行,然后通过监听滚动来更新这几十个dom,大致原理图如下 (网上找的)
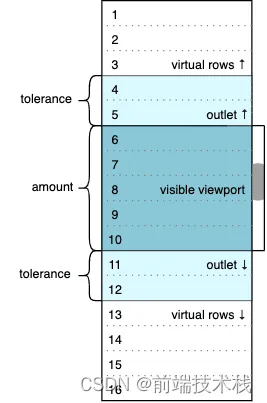
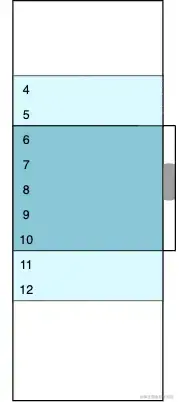
解决方案出来后,无论是Vue还是React解决方案都是类似的,这里用React+Typescript举栗子,首先我们就得完成下面的任务,为了简化场景,先假定每个元素高度都一样
可视区的高度固定 viewHeight (clientHeight
每个列表高度height (固定
可视区域的数据索引start和end (scrollTop / height
基于startIndex计算出offset偏移(scrollTop - (scrollTop % height);
渲染数据 & 监听滚动事件
代码大致如下
// 列表容器的domconst container = useRef<HTMLDivElement>(null) // 开始位置const [start, setStart] = useState(0) // 视图中的数据const [visibleData, setVisibleData] = useState<VirtualProps['list']>([]) // 控制偏移量const [viewTransfrom, setViewTransfrom] = useState('translate3d(0,0,0)') useEffect(() => { const containerDom = container.currentconst viewHeight = containerDom?.clientHeight || 500// 视窗高度const visibleCount = Math.ceil(viewHeight / HEIGHT) // 视窗内有几个元素const end = start + visibleCount setVisibleData(list.slice(start, end)) }, []) functionhandleScroll(e: React.UIEvent<HTMLDivElement, UIEvent>) { const scrollTop = e.currentTarget.scrollTop// 滚动的距离const containerDom = container.currentconst viewHeight = containerDom?.clientHeight || 500// 视窗高度const start = Math.floor(scrollTop / HEIGHT) const end = start + Math.ceil(viewHeight / HEIGHT) setVisibleData(list.slice(start, end)) setStart(start) setViewTransfrom(`translate3d(0,${start * HEIGHT}px,0)`) }稍微难一丢丢,或者更骚包的面试官还会问,如果每行都是一段文字,不知道有多高呢?其实解决方案也不复杂,可以预估一个大致的高度,然后渲染的时候获取实际dom的高度 + 缓存到数组
下面是伪代码,由于位置数组是一个累加的数组,其实还可以用二分算法继续优化,给同学们留个作业吧
// 预估高度60constPREDICT_HEIGHT = 60// 不定高数组,维护一个位置数据const [positions, setPosition] = useState<{ top: number;height: number }[]>([])// 渲染数组之后,更新positions数组Array.from(listDom?.children).forEach((node, index) => { const { height } = node.getBoundingClientRect() // console.log(start+index, node.id)if (height !== positions[start + index].height) { setPosition((prev) => { const newPos = [...prev] newPos[start + index].height = height for (let k = index + 1; k < prev.length; k++) newPos[k].top = newPos[k - 1].top + newPos[k - 1].heightreturn newPos }) }})}, [visibleData])复制代码
场景2: 文件上传
这个场景之前我写过一篇文章,这里也回顾一下,其实就是数据量大了之后,想继续让用户有比较好的交互体验,就得不断地解决新问题
上传普通文件axios.post + 进度条就搞定了,如果想有亮点,可以把文件的体积想的大一些,比如2个G,直接上传容易断,我们需要断点续传,就诞生几个新的问题
文件切片 + 秒传 + 暂停
文件计算hash值,就像文件的身份证号,用来问后端有没有切片存在
计算hash的卡顿 可以使用web-worker,时间切片,抽样Hash三种解决方案
上传文件切片
上面这些解决方案搞完,文件上传这个需求如果面试官问起,我觉得聊半个小时没问题,web-workder,从React源码学到的时间切片,布隆过滤器思想的抽样hash,TCP的慢启动理想,字节高频面试题异步任务并发数控制项目实战

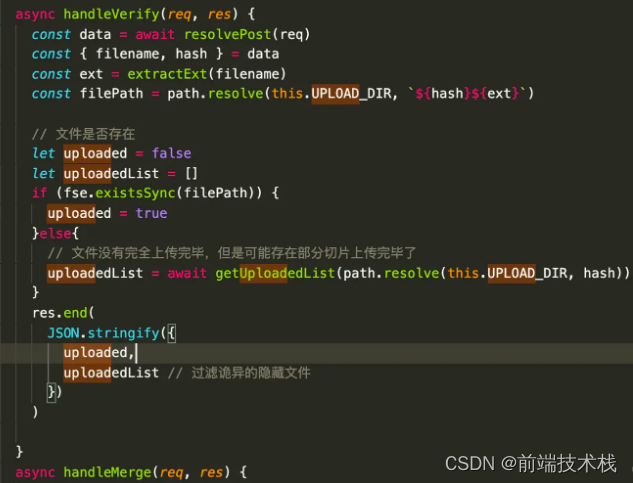
web-worker计算md5 (影分身策略)
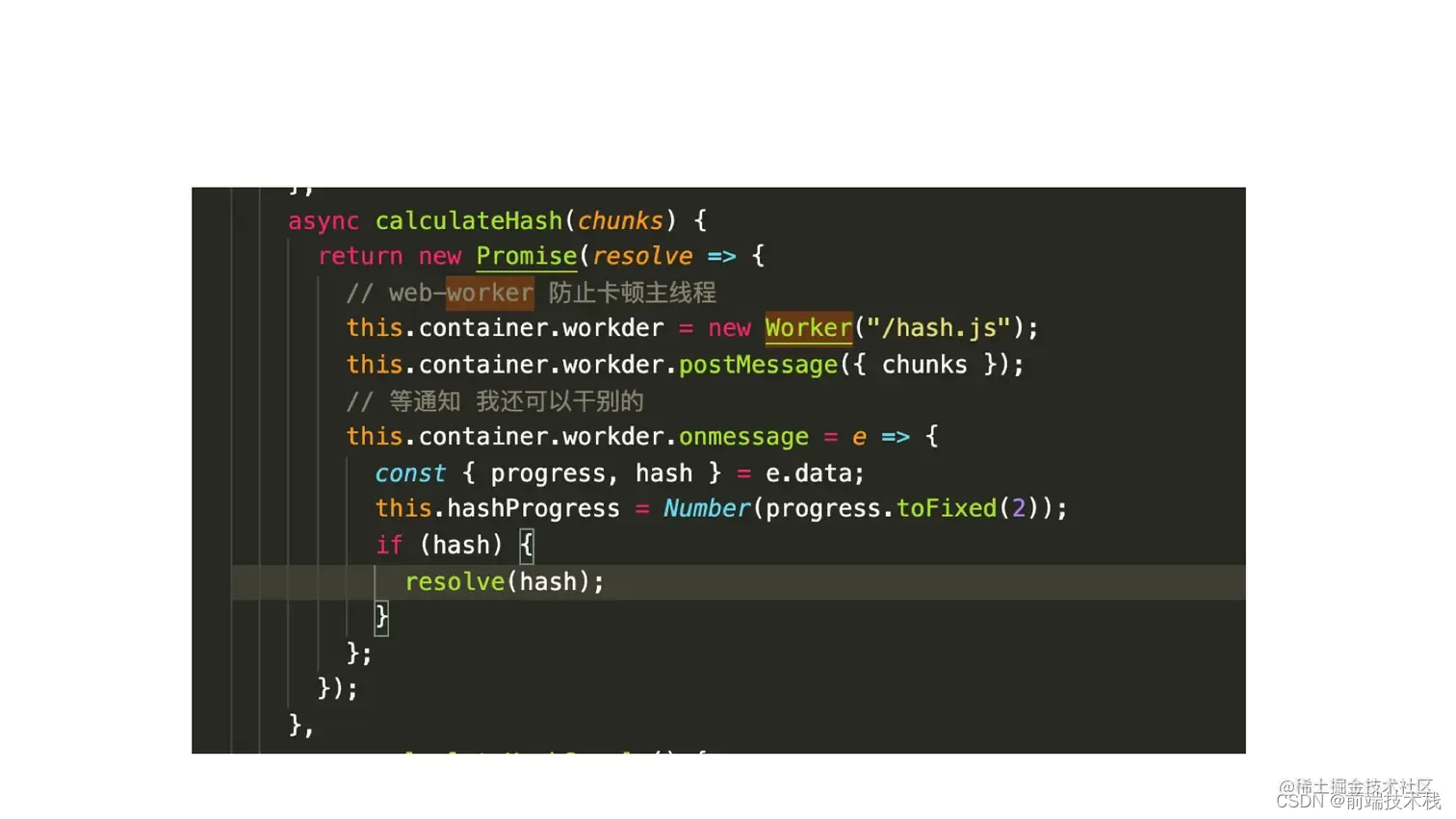
React16之前的架构中,有一个性能瓶颈,就是当虚拟dom的diff时间过长的时候,可能会导致卡顿,React16使用了fiber,也就是时间切片架构解决了,现在计算ms5也是类似的场景,计算量过大导致的卡顿,我们也可以借鉴
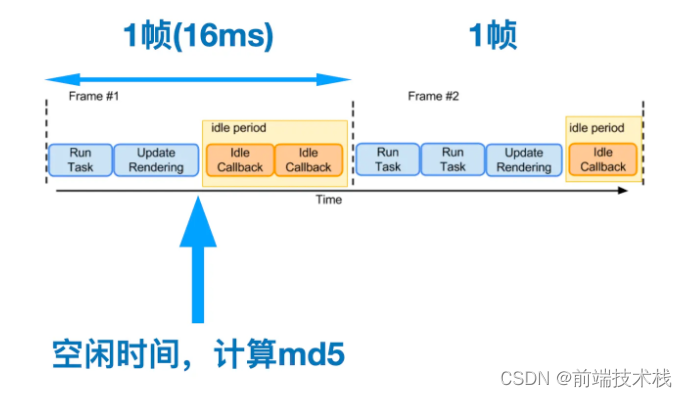
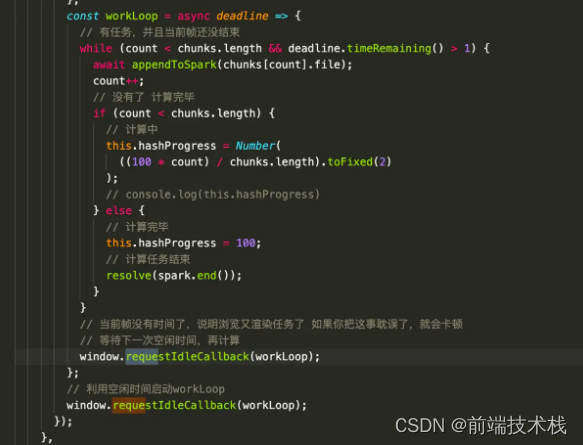
md5也计算完了,如果现在有100个切片,直接Promise.all上传,同时发起100个请求也会让浏览器产生卡顿,我们需要控制异步任务的并发数量,这本身就是字节常问的题目

用队列和Promise.race的特性都可以实现
functionlimit(maxCount){ // 任务队列let queue = [] let activeCount = 0constnext = ()=>{ //下一个任务 activeCount-- if(queue.length>0){ queue.shift()() } } construn = async (fn,resolve,args)=>{ //执行一个函数 activeCount++ const result = (async()=>fn(...args))() resolve(result) await result next() //下一个 } constpush = async (fn,resolve,args)=>{ queue.push(run.bind(null,fn,resolve,args)) if(activeCount<maxCount && queue.length>0){ // 队列没满 并且还有任务 启动任务 queue.shift()() } } letrunner = (fn,...args)=>{ returnnewPromise((resolve)=>{ push(fn,resolve,args) }) } return runner}复制代码还可以用Promise来实现 仅供参考
asyncfunctionasyncPool({ limit, items, fn}) { const promises= [] const pool = newSet() for (const item of items) { const promise = fn(item) promises.push(promise) pool.add(promise) constclean = () => pool.delete(promise) promise.then(clean, clean) if (pool.size >= limit) awaitPromise.race(pool) } returnPromise.all(promises)}复制代码综上所述,你现在做的大部分需求,只需要把数据量想的很大,然后逐步解决大数据量导致的性能问题,就算是亮点之一了
研发效率的提高
程序员也是一种很贵的资源,能提高他们的研发效率,也算是给公司省钱了,当然是亮点了,但是每个人的开发能力不同,我们可以从团队协作和多项目间复用两条路,来寻求研发效率的提高
团队效率
最常见的就是统一规范,js规范,git 分支规范,log规范,项目文件规范,并且用恰当的工具进行自动化校验和修正
然后是多项目间的复用率,也能极大地提高效率
代码初始化,可以封装成脚手架,类似create-vite, 可以内置上面说的各种规范,新项目直接启动
代码研发效率, 前端主要就是组件库和工具库utils封装
代码联调效率, 比如接口json自动生成Typescript接口类型等等,比如mock数据工具
代码上线效率,发布部署,部署结果同步到聊天群等等,把日常重复的行为自动化
这部分也有大量的开源代码可以参考,比如React生态的AntDesign,Vue生态的Antd-vue和element-ui, vueuse, 通用工具库参考lodash等等,这里就不赘述了
这也是大部分团队能有机会做开源的领域,由于需要多个项目之间的共用,所以对代码质量,版本管理,代码文档也会有更高的要求,无形中也提高了我们的段位和能力
现在很火的rust生态,可以极大地提高前端编译的速度,其实也无形中提高了开发者写代码时候的心情和效率,比如webpack换成vite,babel换成swc,还有现在很火的rspack,都是努力让前端开发环境能有丝滑秒开的体验
还有一些非代码层面的协作效率,比如敏捷看板,高效开会,代码review啥的,不在本篇文章讨论范围之内,先略过
研发质量的提高
质量的提高,也是程序员上限的提高
这一部分其实也是一个大话题,【重构】【整洁代码的艺术】【代码大全】等经典书籍数不胜数,不过在前端这个比较蛮荒的领域,能把自动化测试做好,就已经非常难得了
业务性的页面写测试成本过高,但是上面说的多项目之间共享的组件库,工具库还是需要用测试来确保代码质量,学会jest或者vitest写测试,也是我们有机会参与热门开源项目的机会,代码测试覆盖率也是一个项目质量高低的重要指标,而且也是代码可维护性高的体现
你可以现在就尝试用vitest给你项目中写的工具函数 or组件库来点测试代码保驾护航把
除了代码层面的单元测试,还有流程层面的,比如code-review,
性能优化
天下武功,唯快不破
如何让页面打开速度更快是一个永恒的话题,性能优化第一课首先你就得知道页面性能几个常见的指标,FCP,TTI,LCP,就像我们想提高游戏水平,就得了解攻击力防御力这些参数的含义
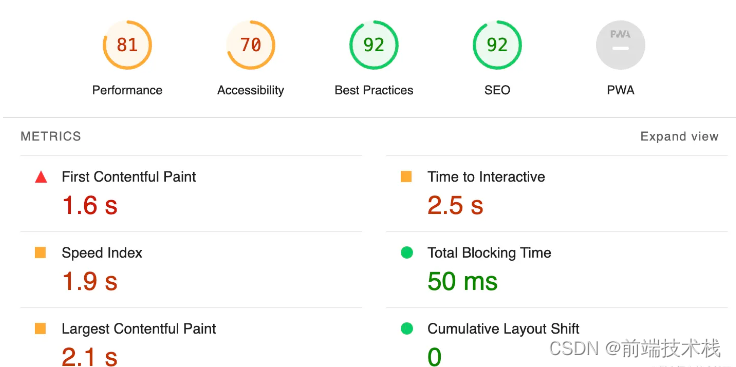
然后前端优化可以先从两个方向开始
1. 更快的加载文件
首先前端工程化中的打包压缩,就是减少了文件的体积和数量,并且通过很好的文件缓存管理,最大限度的利用浏览器的缓存,达到更快加载文件的目的
文件体积里,其实图片的格式选择和优化是大头,jpg, png, webp的选择,还有打包中图片的压缩,都可以获得比较可观的体积收益,静态资源还可以使用cdn继续提高加载文件的速度
还可以使用懒加载的思想,减少首屏加载的文件数量,也可以很好的提高文件加载的速度,图片/路由懒加载现在在前端开发领域都是必备特性了,快去手写一个lazy-load把
rollup带来的tree-shaking能力(跟互联网公司裁员还挺像,囧),可以去除项目中的无用代码,现在也成了前端工程化的标配,这也是为什么我们要尽量向esm规范靠拢的原因之一,而且静态分析还可以给我们带来一些额外的收益,比如vite中的预打包等等
这些我们都可以在工程化环节使用工具or插件的形式存在,所以学会定制webpack/vite的插件也成为前端架构师的必备能力之一, 快去学起来把
2. 代码执行的更快
这里也很好理解,执行的速度也是鉴定代码好坏的一个指标,比如同样一个leftpad函数(前面补齐字符),如果这么写
functionleftpad(str,length,ch){ let len = length-str.length+1returnArray(len).join(ch)+str}console.log(leftpad('hello',10,'0'))复制代码相比于我们用二分法+位运算的优化思路的写法
functionleftpad2(str,length,ch){ let len = length-str.length total = ''while(true){ // if(len%2==1){if(len & 1){ total+=ch } if(len==1){ return total+str } ch += ch len = len >> 1// len = parseInt(len/2) }}console.log(leftpad2('hello',10,'0'))复制代码console.time('leftpad')for(let i=0;i<10000;i++){ leftpad('hello',1000,'0')}console.timeEnd('leftpad')console.time('leftpad2')for(let i=0;i<10000;i++){ leftpad2('hello',1000,'0')}console.timeEnd('leftpad2')❯ node leftpad.js00000hello00000helloleftpad: 51.97msleftpad2: 2.077ms复制代码数据量越大,性能差距就越大,数据量是1W的时候,性能有25倍的差距,当然也可以看出来算法和数据结构对前端的必要性,对不同的场景选择合适的算法or数据结构也是高级前端的必备能力
不同的框架内部也有不同的性能优化方式,减少组件不必要的rerender,减少浏览器的重绘回流,减少页面内部的dom操作等等经典的优化方式 就不赘述了
还有按需执行代码的思想,比如vue3种的静态标记,只有dom种的动态部分需要参与计算diff,静态的dom会直接略过, 还有astro,nuxt3这种ssr框架中的岛屿架构,就是只对页面中的动态组件进行js激活,都是按需思想的表达
复杂场景
一些天生复杂的场景,或者是前端新兴的领域或者热门的领域,面试官也比较喜欢,这个方向就比较多了,以后有机会展开详细说说
很火的低代码(搭建平台
文档技术 (在线office,notion笔记
图形学(figma,白板
3D (可视化,游戏,webgl
....更多未来的可能性
不要陷入成长陷阱
写了这么多,我们要无限进步,但是不要陷入低水平的成长陷阱中,也就是我们要努力学会通用技能,而不是单纯的招式
比如当年浏览器混战的时候,我花了很多时间研究ie6/7/8的兼容性问题,并且感觉自己进步很大,但是浏览器兼容是一个特定混乱时期的问题,现在那些兼容性的写法对于现在的我,毫无积累
我们要花更多的时间学习能够对我们有积累效果的技能,现在webpack和vite是工程化领域混乱发展的时期,过于关注api的使用,以后有一个工具统一这个领域后,你现在努力学习的工程化工具技能,跟我当年的ie6兼容性一样,都被历史埋了
我们可以学习webpack和vite内部的原理,学习他们内部优化的思想,怎么收集文件的依赖关系,怎么实现模块化,怎么实现loader和plugin机制扩展自身,怎么实现高效的热更新等等,这些才是能够帮助我们对未来有积累的技能
少学点api,多研究点问题和本质
总结
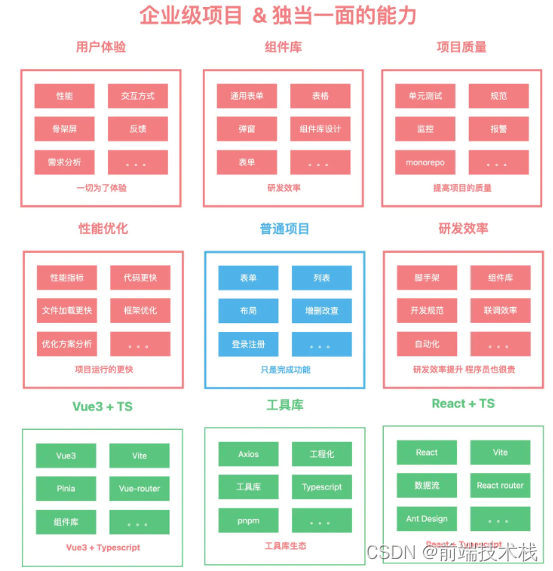
送几个我画的架构图把
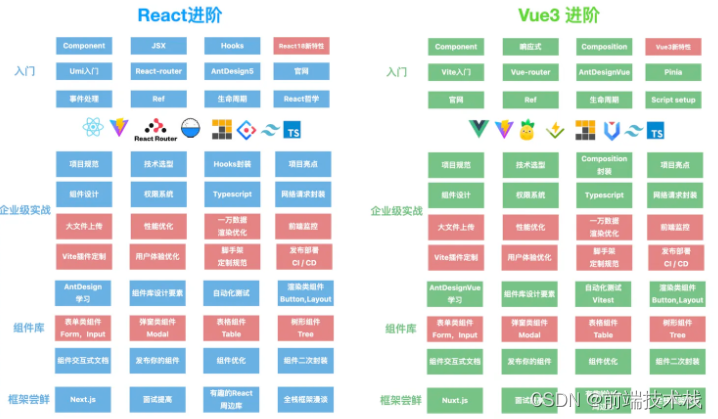
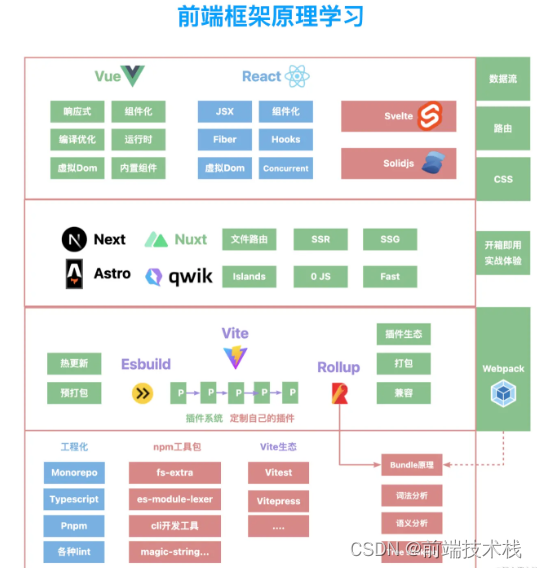
大厂面试题分享 面试题库
前后端面试题库 (面试必备) 推荐:★★★★★
地址:前端面试题库