前言:
对万千程序猿来说,在这个世界上如果有比写程序更痛苦的事情,那一定是亲手找出自己编写的程序中的bug(漏洞)。作为新手在我们日常写代码中,经常会出现报错的情况(好的程序员只是比我们见过的bug多从而减少出错),但当我们遇到报错时大家可能都会出现看不懂的情况,以至于在那里捣鼓半天最后还是当上了“C/V”工程师。本期,基于vs环境下我将带领大家去搞懂代码的调试的小技巧。

文章目录
1. 什么是bug?2. 调试是什么?有多重要?2.1 调试是什么?2.2 调试的基本步骤2.3 Debug和Release的介绍 3. Windows环境调试介绍3.1 调试环境的准备3.2 学会快捷键 4.实例演示4.1实例一:阶乘之和5.2 实例二:死循环问题
1. 什么是bug?
首先,当我们想要去战胜它时,我们先要了解它。就像打战一样,知己知彼方能百战不殆。
大概由来就是有一次在编写程序计算机发生故障,经过排查,在计算机的继电器触电里,找到了一只被夹扁的小飞蛾,这只小虫子卡住了机器的运行,并诙谐的把程序故障称为“bug”。这就是我们今天最爱说的“bug”的由来。它的意思,和原身一致,真就是“一只臭虫”。
具体原因可以了解:
bug的由来
2. 调试是什么?有多重要?
就像警察办案,根据线索一步步的推理和考察,最后得出最后的真相。或许我们最有印象的就是我们看过的【名侦探柯南】。一名优秀的程序员是一名出色的侦探,每一次调试都是尝试破案的过程*
对于绝大多数的新手玩家而言,我们写代码就是“三下五除二”,管它三七二十一一上来就是一顿猛敲,但是到最后的看着密密麻麻的报错,人都要麻了。
又是如何排查出现的问题的呢?
调试错误时或许像这样:

这样无脑的去进行增删查改,到最后忙活半天可能都还在原地踏步。因此,掌握好调试就显得十分重要。
2.1 调试是什么?
调试(英语:Debugging / Debug),又称除错,是发现和减少计算机程序或电子仪器设备中程序错误的一个过程。
2.2 调试的基本步骤
a.发现程序错误的存在
b.以隔离、消除等方式对错误进行定位
c.确定错误产生的原因
d.提出纠正错误的解决办法
e.对程序错误予以改正,重新测试
2.3 Debug和Release的介绍
紧接着我们再来看一下VS下的两种版本,即-----Debug和Release
a:
Debug通常称为调试版本,通过一系列编译选项的配合,编译的结果通常包含调试信息,而且不做任何优化,以为开发人员提供强大的应用程序调试能力,便于程序员调试程序。
b:
而Release通常称为发布版本,是为用户使用的,一般客户不允许在发布版本上进行调试。所以不保存调试信 息,同时,它往往进行了各种优化,以期达到代码最小和速度最优。为用户的使用提供便利。
我们还是通过代码来展示:
#include<stdio.h>int main(){char* p = "hello world";printf("%s\n", p);return 0;}当我们写出以上代码并且放在【Debug】版本下运行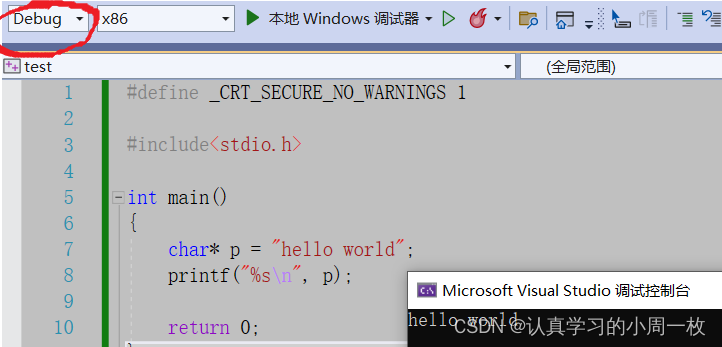
当我们去文件查看在【debug】下的信息时,我们看到结果如下图所示:
而当我们的代码在【Release】版本下运行的时候:
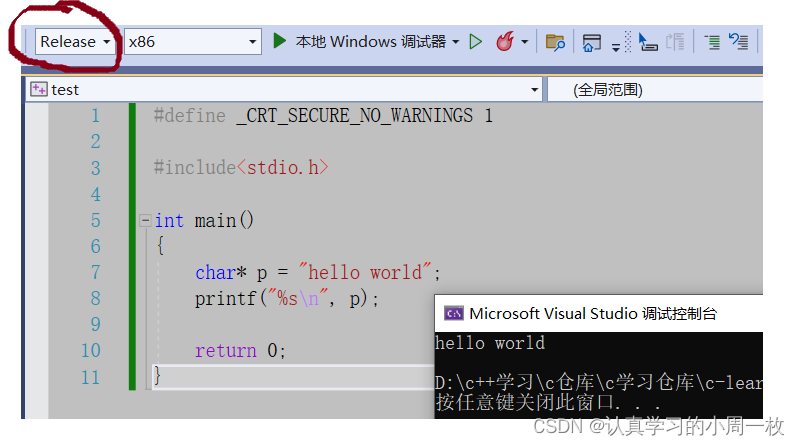
我们可以看到同样的程序在两个版本下的文件大小是不同的。
所以我们说调试就是在Debug版本的环境中,找代码中潜伏的问题的一个过程。
那编译器进行了哪些优化呢?
请看如下代码:
int main(){ int i = 0; int arr[10] = { 0 }; for (i = 0; i <= 12; i++) { arr[i] = 0; printf("hehe\n"); } return 0;}是 【debug 】模式去编译,程序的结果是死循环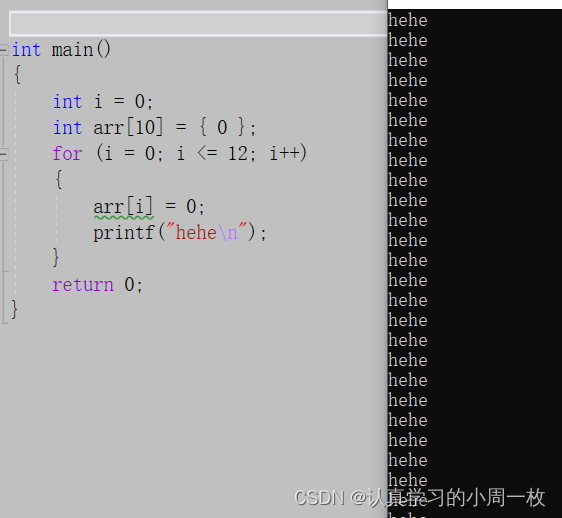
【release 】模式去编译,程序没有死循环。
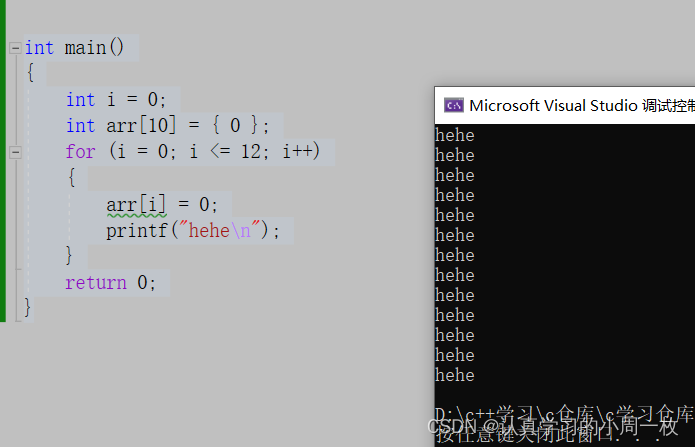
那他们之间有区别,就是因为优化导致的。
3. Windows环境调试介绍
注:linux开发环境调试工具是gdb,后期课程会介绍
3.1 调试环境的准备

在环境中选择 debug 选项,才能使代码正常调试。
3.2 学会快捷键
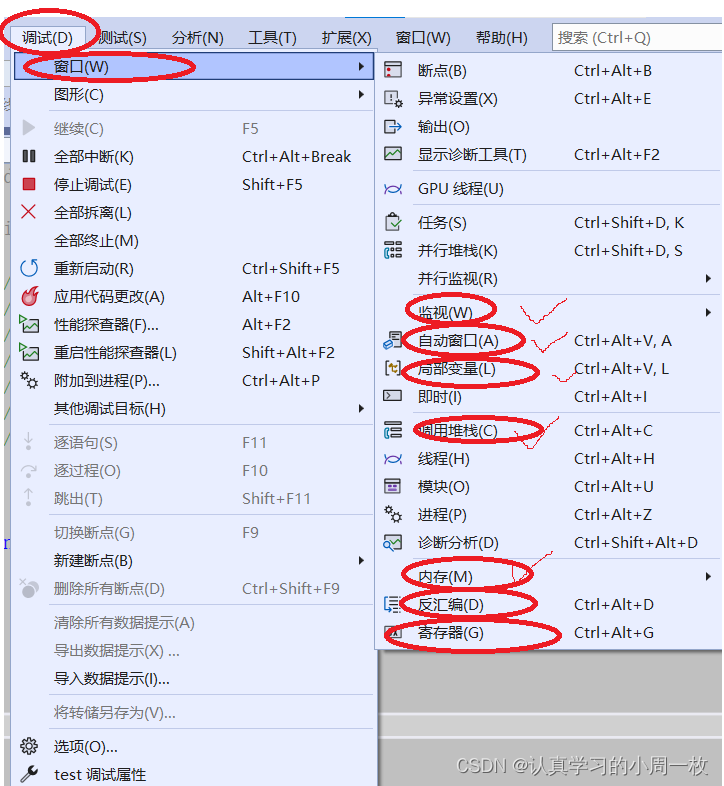
上图我打钩的就是平时经常用得到的一些快捷键,记住快捷键将大大提高我们调试的效率,接下来我将具体介绍:
F5
启动调试,经常用来直接跳到下一个断点处。
F9
创建断点和取消断点
断点的重要作用,可以在程序的任意位置设置断点。
这样就可以使得程序在想要的位置随意停止执行,继而一步步执行下去。
F10
逐过程,通常用来处理一个过程,一个过程可以是一次函数调用,或者是一条语句。
F11
逐语句,就是每次都执行一条语句,但是这个快捷键可以使我们的执行逻辑进入函数内部(这是最长用的)。
CTRL + F5
开始执行不调试,如果你想让程序直接运行起来而不调试就可以直接使用。
更多的快捷键,可以通过如下查看:
https://blog.csdn.net/mrlisky/article/details/72622009
4.实例演示
说了那么多,终究全是书面上的东西,接下来我们通过具体的实例带大家感受一下。
4.1实例一:阶乘之和
代码思维:
在我们开始写代码之前一定要想好n的阶乘和是什么?
当我们脑海中有了思路之后,写起来就会很快,而不是直接就上手:逻辑很简答,首先输入n表示n的阶乘之和,最后在进行求和操作即可
紧接着,想每一步需要用到的知识,具体如下:
1、阶乘:1x2x3…xn 用到了循环语句
2、求和:还是用到了循环
最后就是打印出来即可!!
代码如下:
int main(){int i = 0;int sum = 0;//保存最终结果int n = 0;int ret = 1;//保存n的阶乘(乘法的话一定要初始化为1)scanf("%d", &n);for (i = 1; i <= n; i++){int j = 0;for (j = 1; j <= i; j++){ret *= j;}sum += ret;}printf("%d\n", sum);return 0;}好了,有了以上代码之后,我们接着就要去验证此时写出来的代码是否正确。开始时,我们举个简单的例子,以输入【3】为例。在我们的想象中,【3】的阶乘之后就是:
第一步:1的阶乘,即1;
第二步:2的阶乘,即12=2;
第三步:3的阶乘,即12*3=6;
第四步:三数相加,即1+2+6=9(即最终结果为9)
那么真的是这样吗?接下来我们就通过一步步的调试去看看结果。
首先看到我们进入了内存循环,此时i = 1, j = 0,循环会开始执行一次,因此可以求出此时【1】的阶乘为 :1! = 1
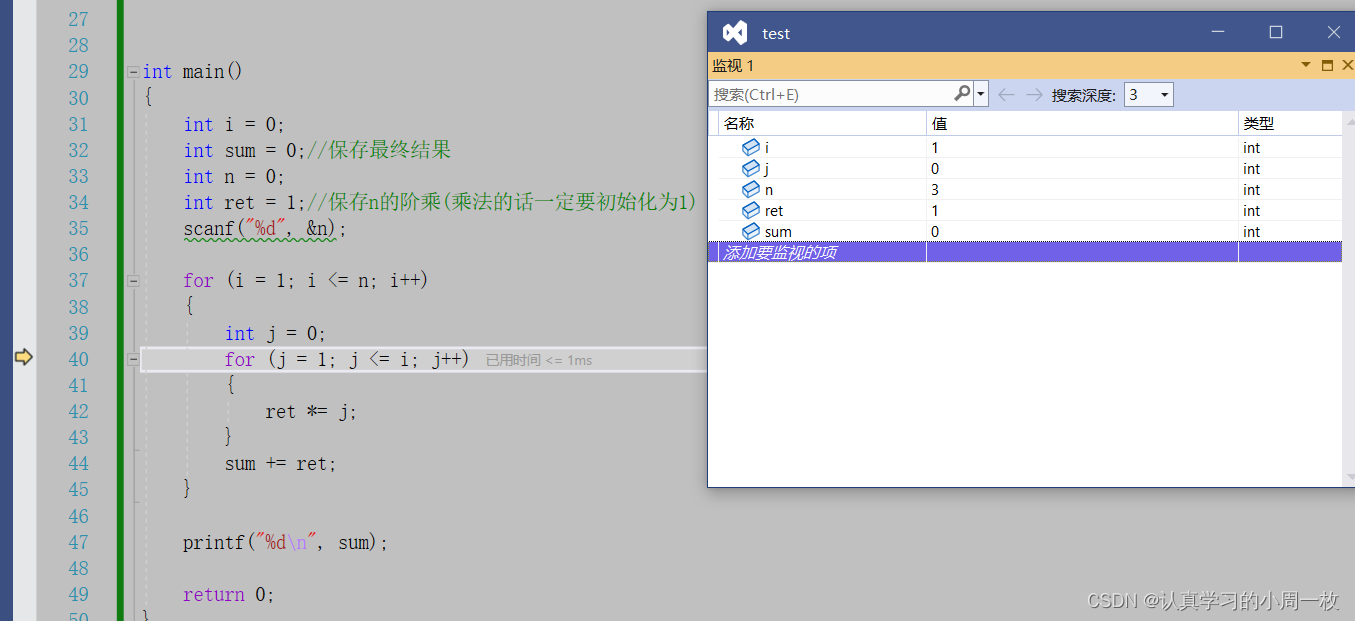
当第一次跳出内层循环之后,我们就可以求出【1!】,因此可以看到【sum】此时为1
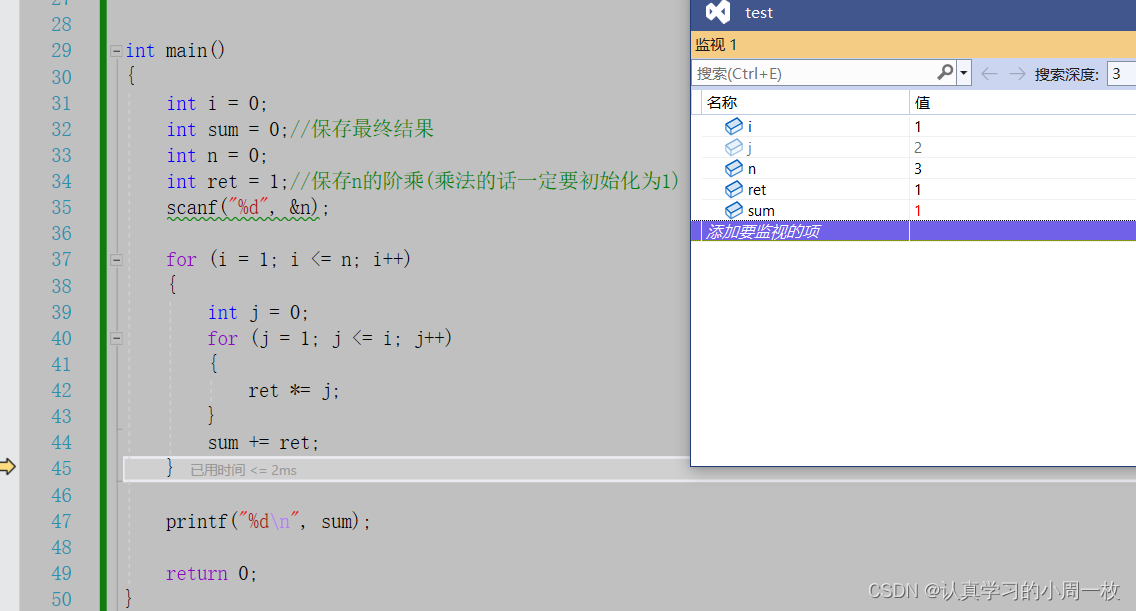
紧接着我们再去计算【2!】,此时在我们函数的内部,会进行两次的循环操作,执行完毕后,此时各个值如下表所示:
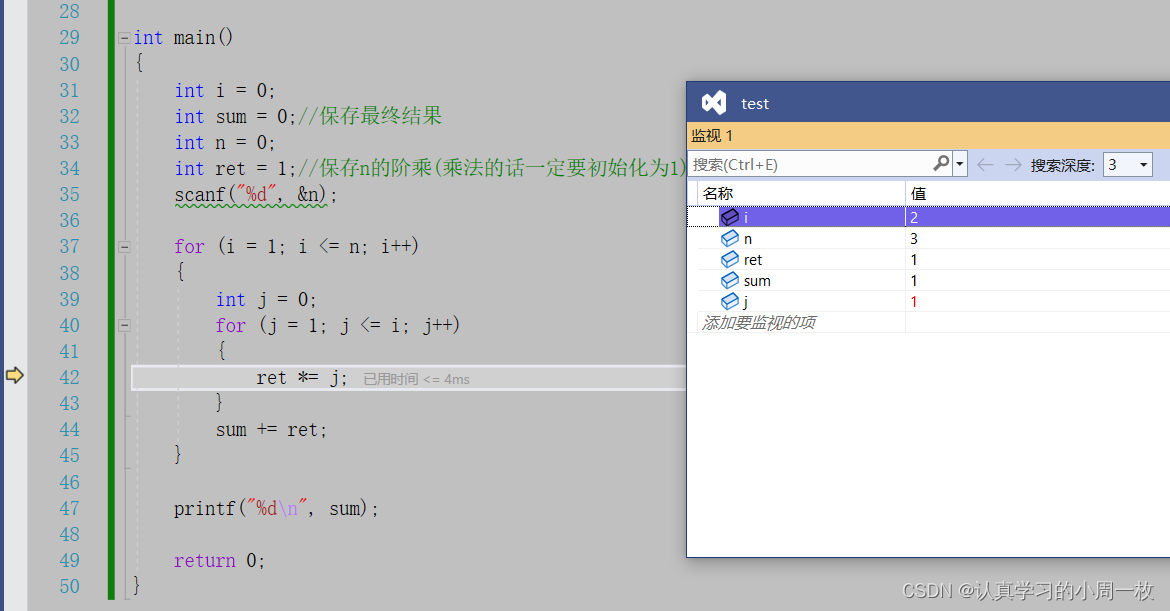
此时将我们【2!】计算完毕之后,可以得到【ret】的值,最后在进行累加的操作,即【1+2】的操作,所以此时的【sum】应该为3,结果如下:
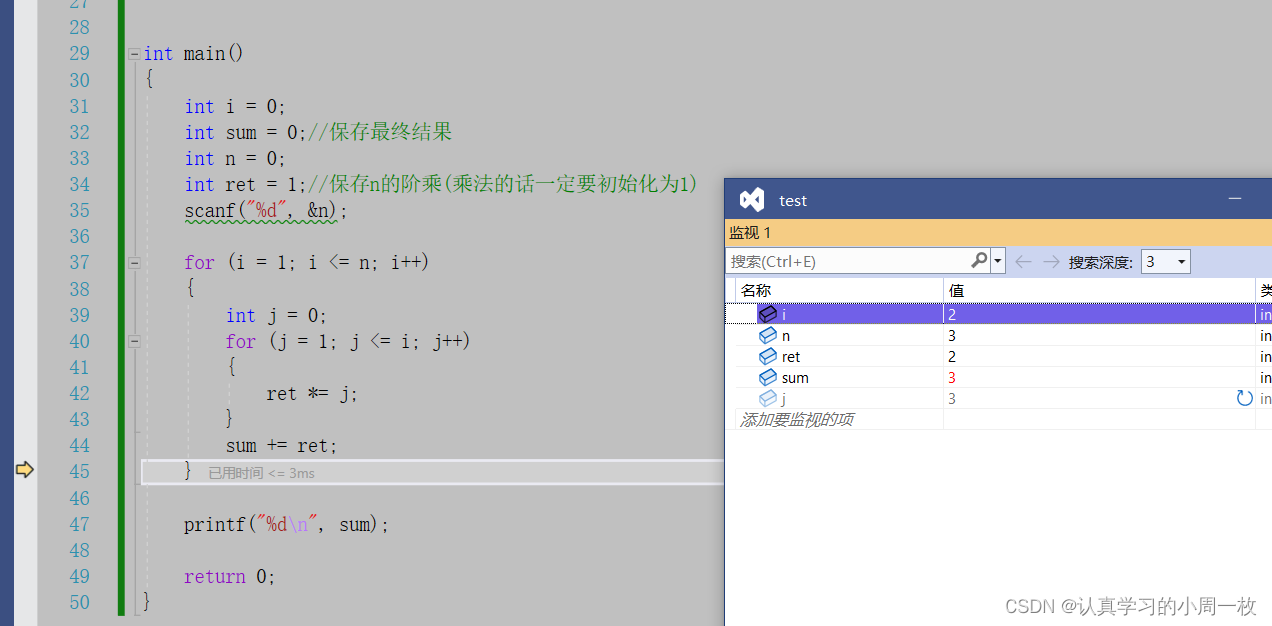
前两次执行完之后,紧接着就回去执行【3!】的操作,在内部进行三次循环操作,我们已经知道,【3!】的结果为6,我们在继续【F10】看结果:
第一次内部循环开始,此时【j=1】,【ret=2】
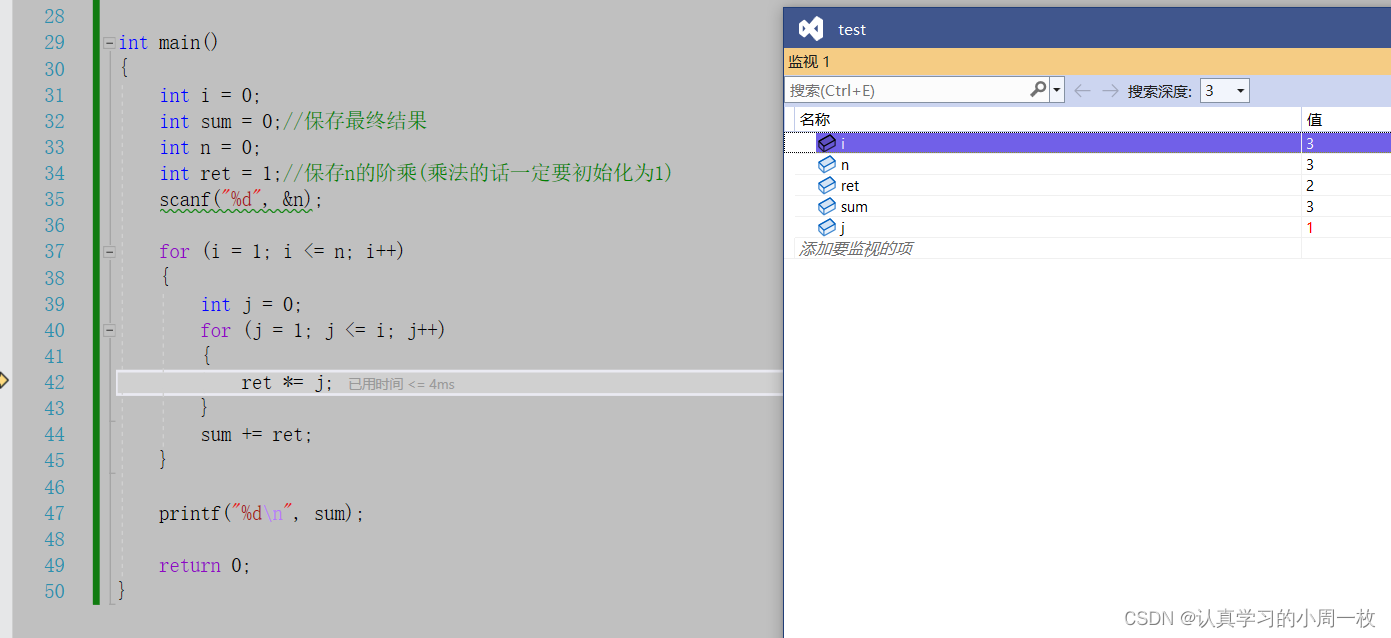
第二次循环完毕之后,此时【j=2】,【ret=4】
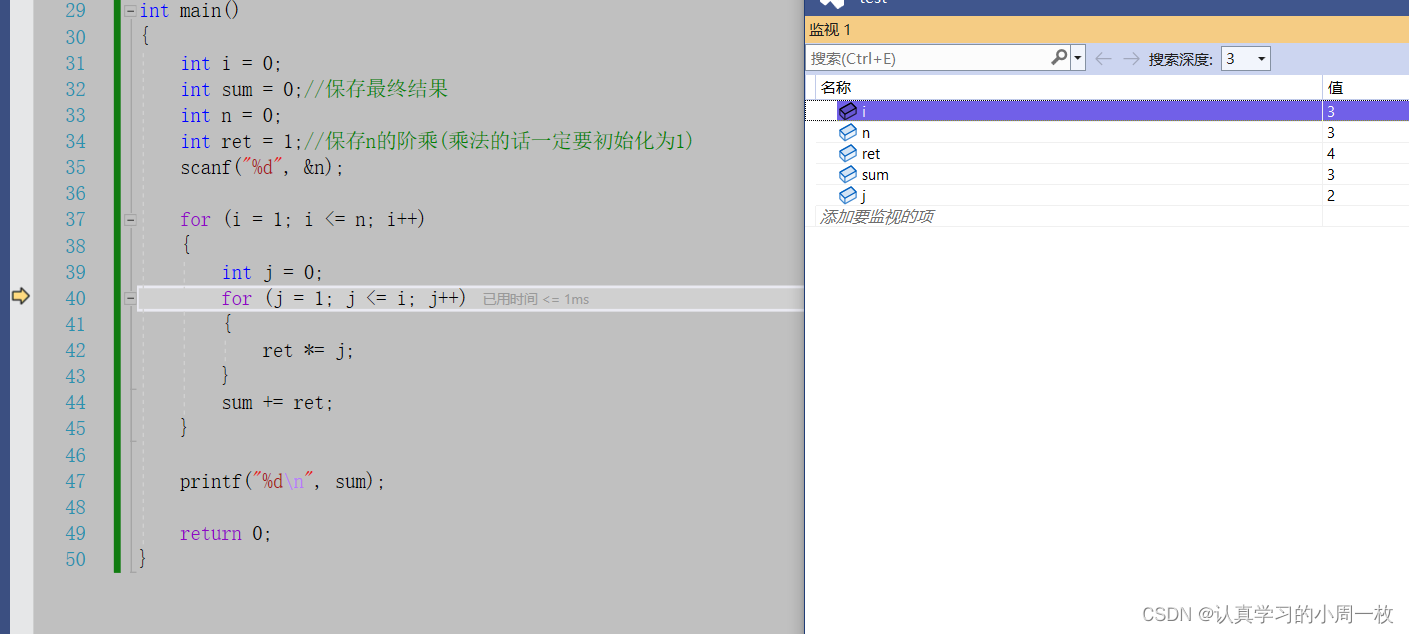
第三次循环完毕之后,我们可以发现此时【j=3】,【ret=12】
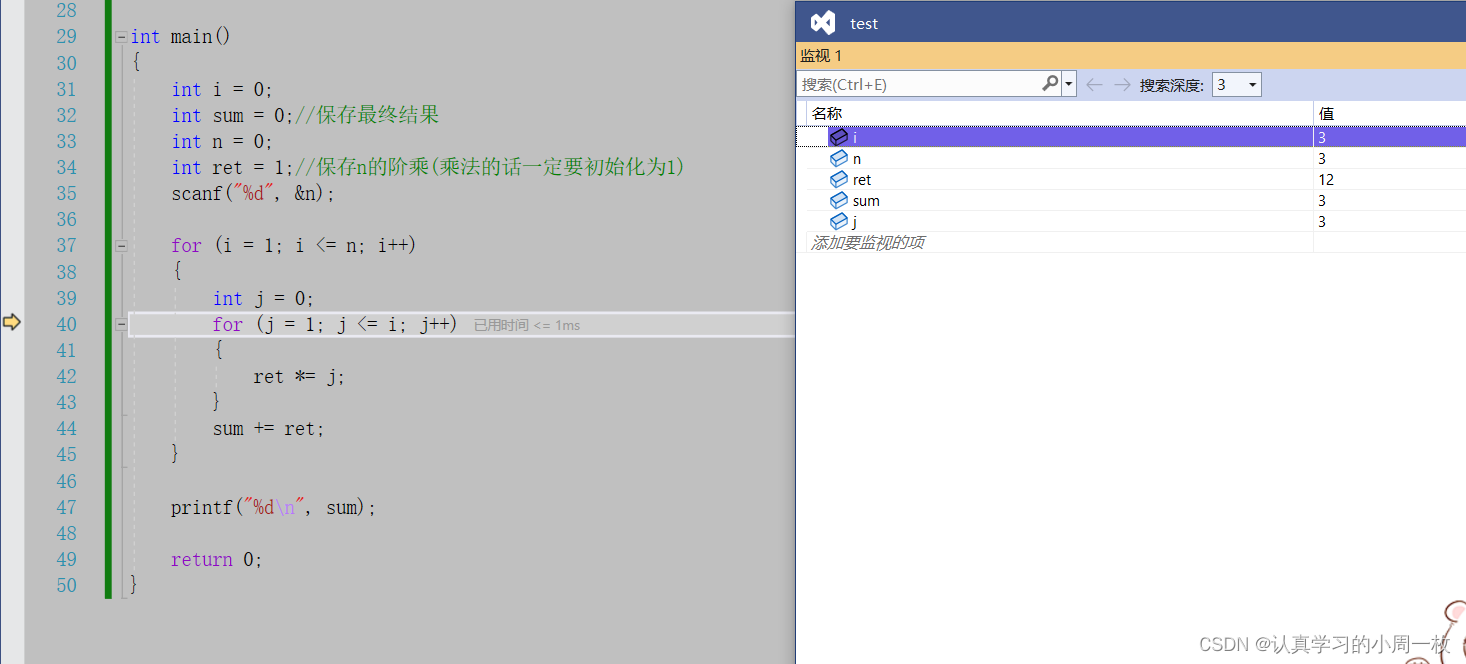
最后一步在循环完之后,我们就需要计算累加和,此时我们可以发现当【j=4】时我们跳出循环操作,而最终的结果显示的是【15】,明明应该是【9】啊.(咦…怎么会是【15】呢?此时各位好奇的小脑袋瓜就开始躁动起来了)
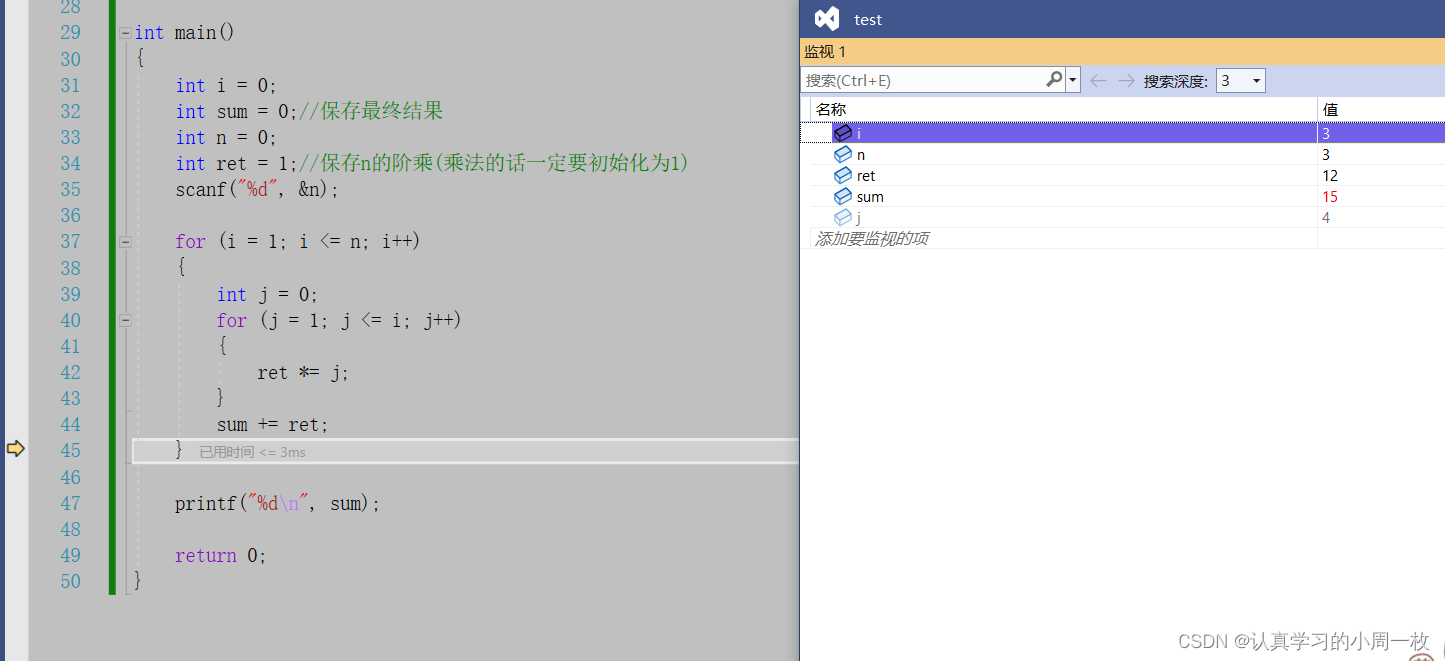
遇到程序出错了不要害怕,我们仔细分析一下。 我们来整理一下,这样写的思路:
a:
n=1时,我们进入第一个循环,然后并没有发生什么,进入第二个循环【ret=1*1】,【sum=0+1】,此时是没有问题的;
b:
n=2时,我们在进入在第一个循环,没有发生什么,进入第二个循环,【ret=1 * 1=1】,但是请注意,在这之后,并不会计算【sum=sum+ret】,而是继续在第二个循环中没有跳出来,因为第二个循环的条件是【i<2】,此时仍然是真的,所以,第二个循环继续,【ret=1 *2=2】;在跳出第二个循环,【sum=0+2】,但是请注意,此时第一个循环没有结束,对于第一个循环,此时【n=1】,还要继续【n=2】的情况,所以最终结果是【4】,因此在这一步就出现了错误。
因此我们可以这样改(每次重置【ret】的值),此时运行结果就正确了: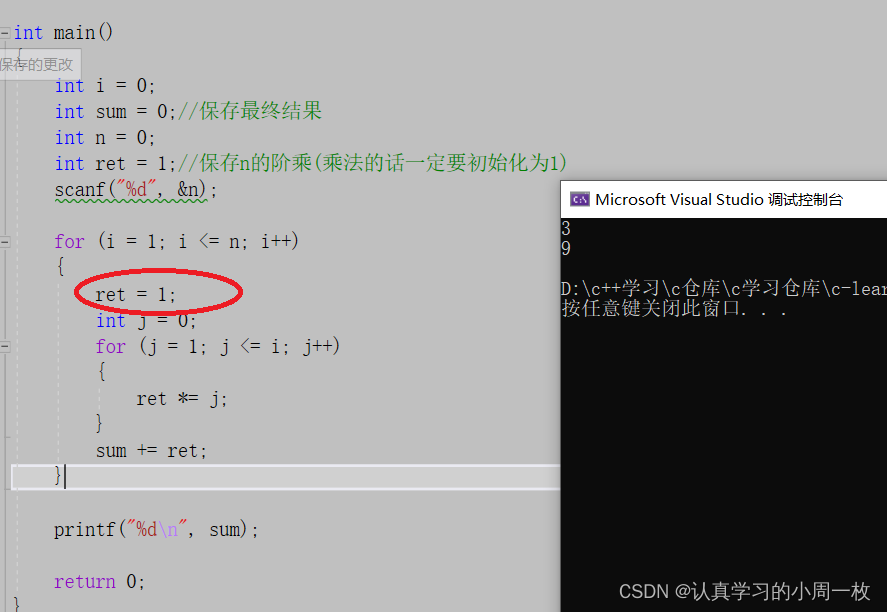
还有一种方法就是我们可以不使用两层嵌套来进行封装,我们只定义一层循环,具体代码如下:
int main(){int n = 1;scanf("%d", &n);int ret = 1;//保存n的阶乘(乘法的话一定要初始化为1)int i = 1;int sum = 0;//保存最终结果for (i = 1; i <= n; i++){ret *= i;sum += ret;}printf("%d\n", sum);return 0;}5.2 实例二:死循环问题
首先我给出一段代码,大家可以猜猜程序最后将会输出什么:
int main(){ int i = 0; int arr[10] = { 1,2,3,4,5,6,7,8,9,10 }; for (i = 0; i <= 12; i++) { arr[i] = 0; printf("hehe\n"); } return 0;}相信大多数的小伙伴看到这个程序的第一印象就是,数组下标为【0-9】,而这里却是【<=12】,很显然的问题就是数组访问越界
然而真的是这样的吗?老规矩直接运行程序,看最终是不是我们想的那样。
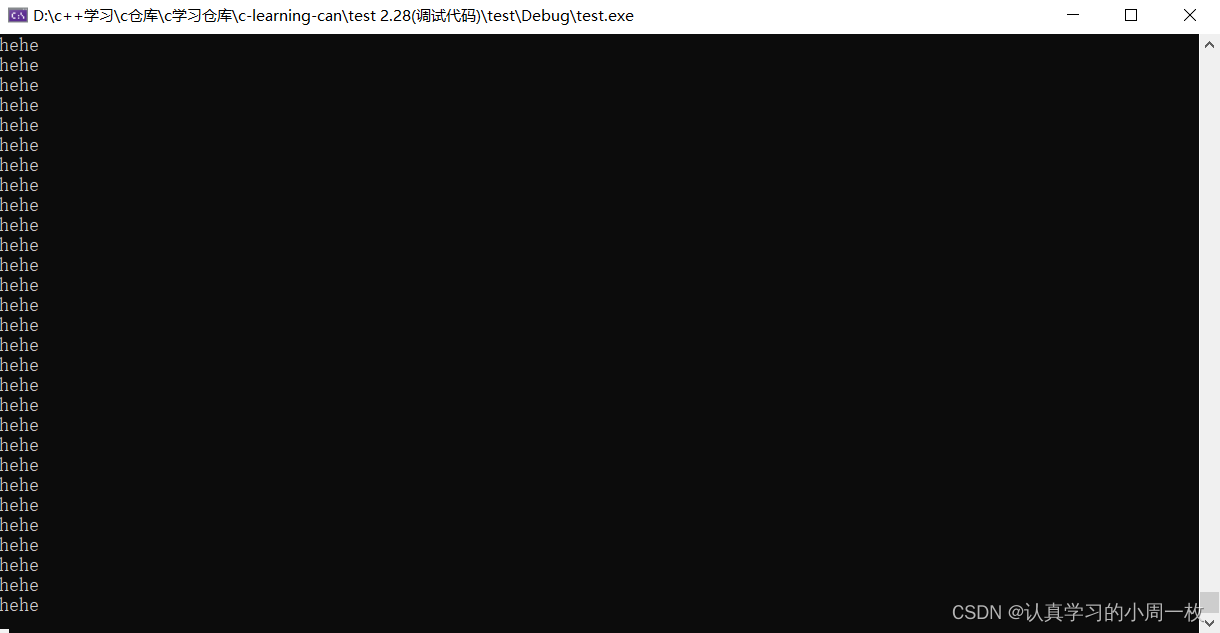
咦…我们发现怎么结果会是死循环打印呢?接下来,你如果要搞清楚这个问题,你能肉眼分析出来是因为什么吗?这时候就需要用到调试了
开始时我们进入循环,对数组进行初始化操作,得到以下结果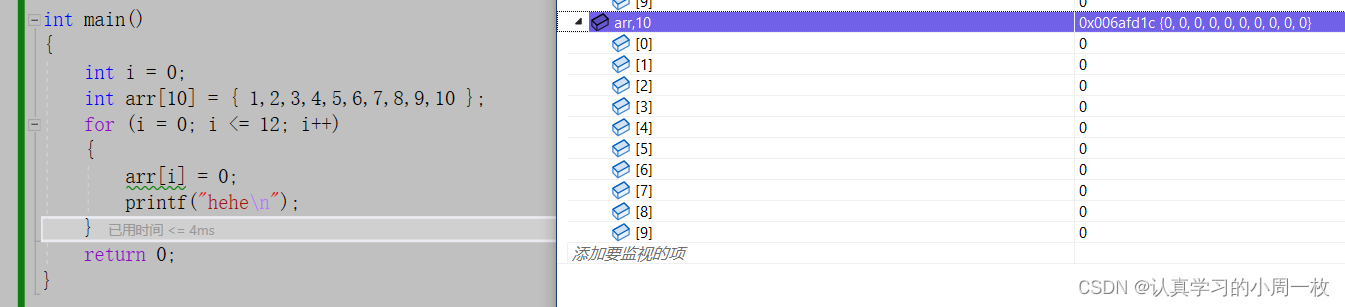
紧接着我们进入循环里面去,对数组元素都改为【0】,一直进行到对【arr[9]】的操作,到这个元素都是在我们的正常范围之内进行的。
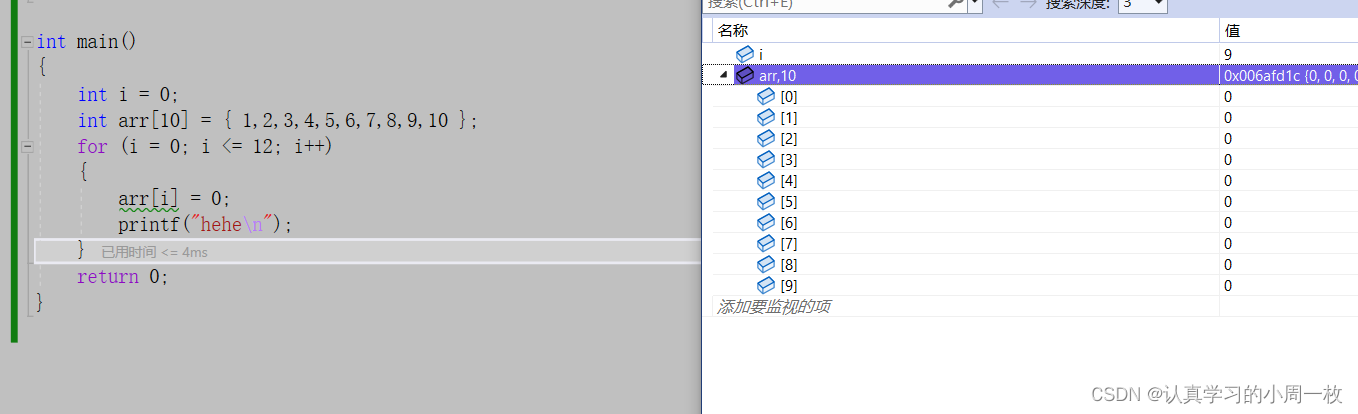
那么接下来的【arr[10]】呢?【arr[11]】和【arr[12]】呢?它们是什么样的呢?我们继续调试下去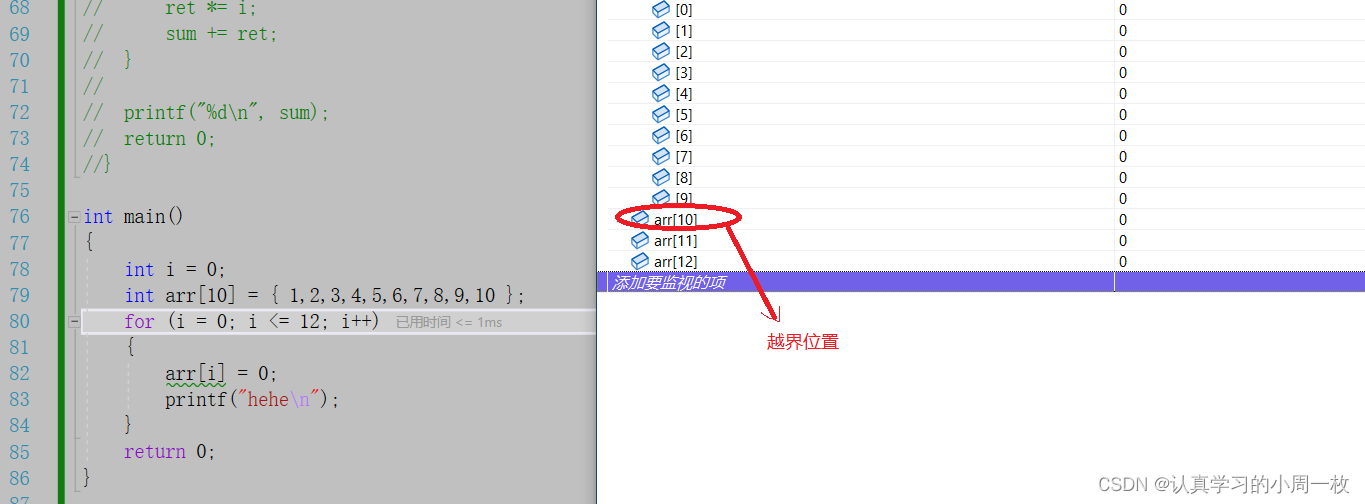
从上图 我们可以发现它依然对其进行操作,那么为什么对【arr[10]】这个位置还能访问得到呢?接下来我给大家解释解释
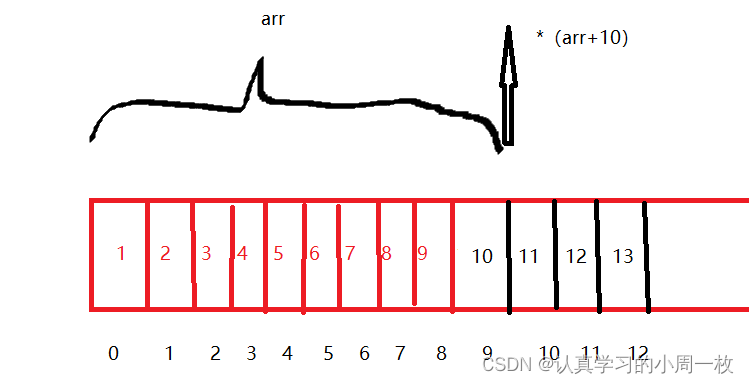
因为当我们的数组存,放在内存中的时候是有一片连续存储的空间,而数组之后也存在一定的空间,而这一片连续的地址空间都存在于【main】函数的栈帧空间下,在它看来存储空间之间都是连续的,因此数组之后的空间也是可以访问到的。
除了这个问题之外,还有一个明显的问题不知道大家有没有发现,就是当我们执行到最后时,【i】和【arr[12]】两个值竟然同时变为了0,这又是为什么呢?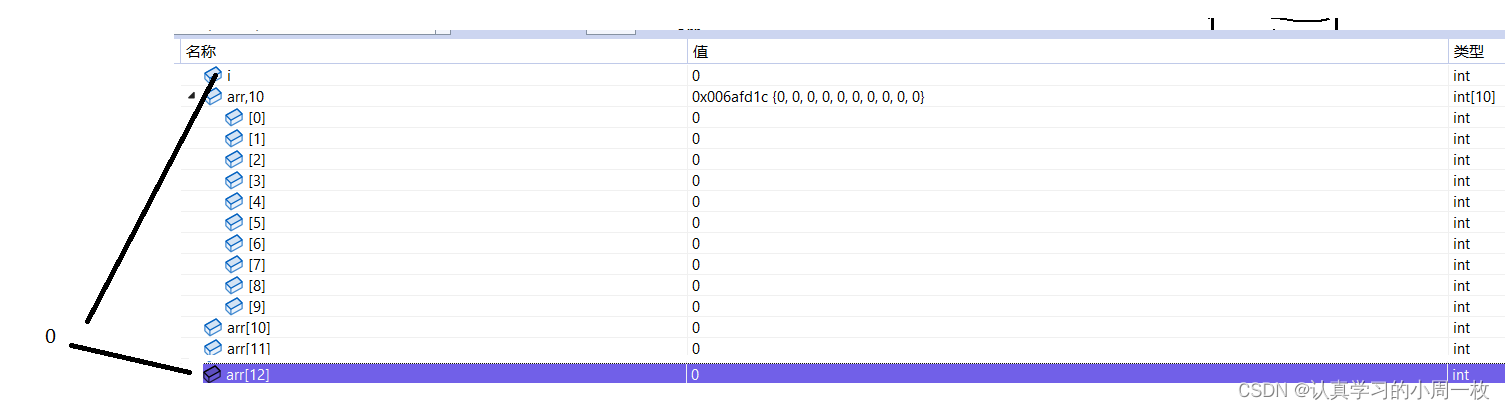
接下来我们我们分别对两个进行取地址的操作,就可以发现这两个竟然是指向的同一片地址空间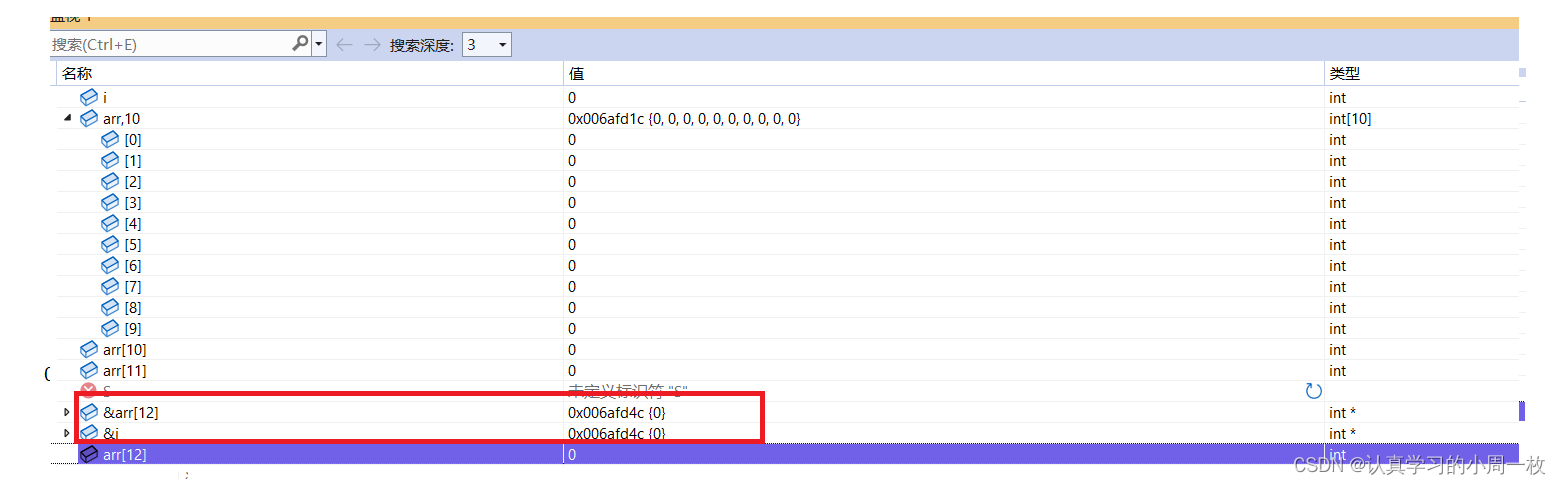
到了这我们就可以想到,对于变量【i】,它应该是位于整个数组结束位置的后两位上,只有这样才会在数组越界访问的情况下改变【i】的值,最后在修改这块块空间中的值时将循环变量【i】的值做了修改,因此使得【i】的值永远不可能到达13,因此才会出现死循环打印的情况。
接下来,我们通过内存布局来进行进一步的了解。
首先我们知道【i】和【arr】是局部变量元素,而局部变量是放在内存中的栈区上的,而栈区的使用习惯是先用高地址空间再用低地址空间(这点非常重要),可以发现变量a的地址是比变量b的地址来得大的。
那么在内存中栈区究竟是怎么样的呢?我们通过以下图片为例。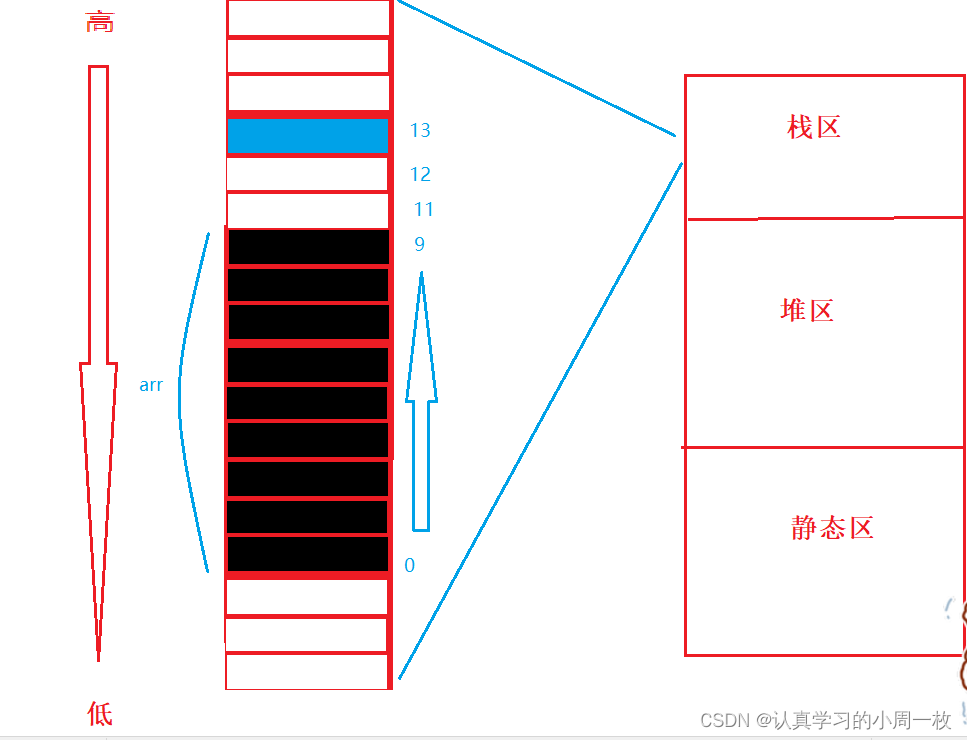
程序一进到【main】函数的函数栈帧中时,就会先为变量【i】开辟一块空间,接着可能就会空出几个位置再为【arr】数组开辟十个元素的空间,根据上述我们可以发现空出来了几个位置,那么为什么要空出来呢?(这里面可是有大学问的)
这并不是我规定的或者谁规定的,中间的大小而是取决于编译器
1.VC6.0编译器下,中间就没有多余的空间;
2.在gcc这个Linux环境下的编译器中,创建的局部变量之间会空出一个整型,也就是4个字节
3.在VS 2013/2019/2022这些编辑器中,中间都会空出两个整型,也就是8个字节
因此在不同的编译器下去运行这段代码虽然得到的都是死循环这个现象,但是底层的实现是有些区别的。
紧接着我们可以知道数组在平时的使用过程中都是从低到高的,但是数组的地址是否也是这样的呢?我们进行一下测试。
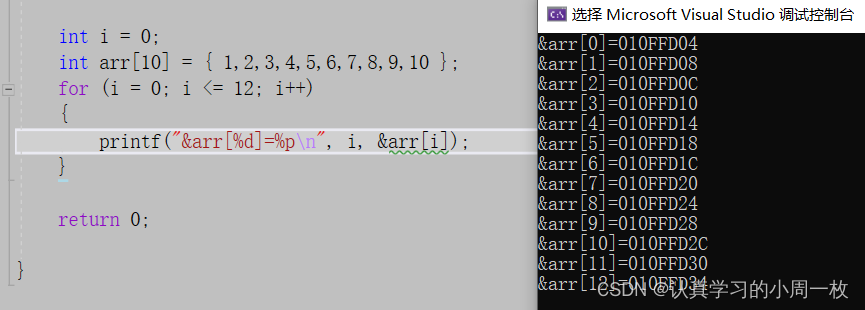
从上图我们可以发现数组的每个元素地址都是从低到高进行一个变化的。
有了这些知识储备之后,我们在回过头去看最开始的问题,这时就可以很好的回答了:
程序开始的时候,变量【i】先创建出来,在内存中先开辟的地址空间;而【arr】数组的地址空间是后开辟出来的。但是,刚才我们已经知道数组的下标和数组元素的地址变化顺序都是从低到高,而内存中的堆栈则是先使用高地址,再使用低地址,因此当数组进行向后访问时,就有可能找到变量【i】,并且把其覆盖掉,因此就有可能把循环变量的值改为其他的情况,从而导致循环结束条件不能达到,就导致了死循环打印的现象。(到此一切就讲通了)
因此,正确的解决方案还是改我们的循环结束条件。
总结:
通过本期的学习,我相信大家以后在遇到程序出现报错的时候就不会无脑的直接去程序里面增删查改了,大家可能会说这个很难,但是俗话说得好呀!(害怕恐惧的最好办法就是战胜恐惧)
以上便是本期的所有内容啦!感谢您的观看,如果对你有帮助的话记得三连支持一下哟!