引言:
北京时间:2023/3/14/20:09,晚上没课,开心,但是等一下要去练习如何晨跑,并且明天要起床晨跑,不开心,今天博客更新啦!并且明天是周三(课少),所以明天这篇博客就可以发啦!开心,终于又实现了日更博客了,爽!怀念以前在家的时间,每天都可以更新博客,然后CSDN平台会一直帮我推送文章,导致那时候,我的文章都是领域榜的前三名,可惜现在更新没有那么积极了,它居然不给我推了,想哭,不开心;OK,搞笑完毕,开始学习,今天我们就一起学习一下STL容器中的栈和队列的使用(题目)和STL中栈和队列的自我实现,以这些内容为目标,冲冲冲!不过前提是需要把list给收尾一下,哈哈哈!
收尾list
上篇博客,我们已经把list的大致功能和list迭代器等实现了,但是还有一些小知识没有搞定,如析构函数和拷贝构造函数,当然还有一个很重要的,就是迭代器类型的构造函数,所以接下来,我们就来把这几个知识点搞定,如下图:
如上就是一个迭代器类型的构造函数,所以下面,我们就来看一下,在什么场景下会使用到迭代器类型的构造函数来初始化数据吧!如下图:

此时我们就可以发现,当我们在调用拷贝构造函数进行初始化对象的时候,我们可以使用现代化写法(窃取劳动果实写法),让一个临时变量tmp使用一个已初始化的对象的迭代器去调用迭代器构造函数,让这个迭代器构造函数使用已初始化的对象初始化tmp,让后使用库里面的swap函数(效率高)让我们真正需要初始化的对象去和tmp交换,进而使我们想要初始化的对象得到初始化,并且由于tmp是一个拷贝构造函数中的临时变量,所以会自己调用析构函数进行资源释放(无内存泄露的风险),这样就实现了一个经典的现代化拷贝构造函数写法,效率很高,且代码简洁,不需要我们自己去处理对象成员变量赋值等一系列的容易出问题的问题(全权交给std中的swap函数(不就是小小的交换吗?std说:So,easy!))。
所以上述我们就了解了什么是拷贝构造函数的现代写法,此时我们就把正常的写法和现代写法做一个对比,如下图:
可以发现,在代码原理上,本质都没有太大的差别,就是调用push_back函数和使用迭代器进行遍历而已,但是在代码写法上,还是有一定的差距的,所以构造函数,只要你的代码能力够强,你就是神,爱怎么写怎么写!
并且,此时我们知道,拷贝构造函数不仅有上述的写法,赋值也是拷贝数据的一种经典写法,所以我们就来看一看,list中的赋值运算符重载吧!如下图: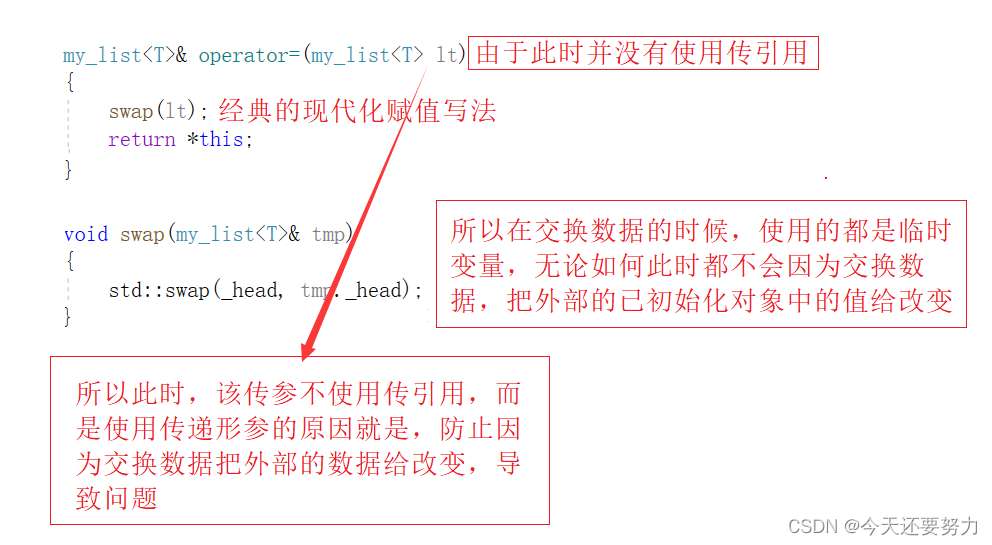
搞定了上述的赋值运算符重载、构造函数和拷贝构造函数,此时我们就来看一看list中的析构函数,析构函数没什么好讲的,如下图:
俗话说,牵一发而动全身,我们的析构函数当之无愧的配得上这句话,堆区上的资源说,想清理我,就看你技术到不到家啦!否则定要你鸡犬升天,不得安宁!虽然看起来非常的简单,只是调用了clear函数,再深入点,可以说是循环调用了 delete [] ,但是实际上却是有非常多的坑在这里的,到处都在等着我们去踩,你可能就是左脚刚拔出来,右脚就又进去了,所以无论是在写构造函数,还是拷贝构造函数,还是有关空间开辟、空间释放的函数,我们都需要非常的熟练(思路非常的清晰),这样才可以减少踩坑的概率或者说可以快速的发现问题的所在(解决问题),百炼方能成刚!
总:有关list的知识收尾差不多是搞定了,接下来就让我们快乐的进入栈和队列吧!
具体list代码贴在文章最下方
STL中的栈
首先,我们要明白,栈是没有迭代器的,因为它不是容器,它是一个容器适配器,所以这就是我们为什么可以快乐学习栈的根本原因,栈和之前在数据结构中学习的本质上是没有什么区别的,学习栈的成本是非常低的,So,here we go!
库中对stack的一些使用描述:
虽然栈不是一个容器,是一个容器适配器,但是它也是可以通过别的效率更好的容器适配器(duque)来实现的,deque我们在下一篇博客会具体谈到(是一个vector和list的结合型数据结构类型),并且此时可以发现,使用栈的成员函数的成本是非常低的,所以接下来我们就看一下栈的使用吧!(先大致包含头文件使用以下,然后再通过做题的方式来进一步使用栈)
如下图:
有关栈的题目
搞定了一般栈的使用(包个头文件就可以使用),此时我们就开始使用栈做题目,来看一看栈的进一步用法,如下:
题目:最小栈(难度:中等)
题目描述:设计一个支持push,pop,top操作,并能在常数时间内获取最小元素的栈(关键句)
解题思路: 使用两个栈,一个栈遍历数据,一个栈存储数据(判断),得最小的数据;
具体原理: 往两个栈中入数据,判断第一个栈中插入的数据,是否比前一个插入的数据小(如果小,下面的栈也插入),如果不小,下面的栈就不插入,插入完数据之后,就开始pop(删除)数据,从上面的栈开始删(删的过程和下面的栈进行比较),因为通过上述的原理,此时我们下面的栈的栈顶,已经就是最小的那个数据了,所以用上面栈中的数据和下面栈中的栈顶数据(也就是最小数据),进行比较,如果相等,那么此时我们就找到了上面那个栈中的最小数据,此时就把它出栈,最后题目实现;
但是有一点需要注意,注意点: 就是当最小值不止一个,且不连续时,所以入栈的时候,需要判断等于(等于下面这个栈的栈顶,也需要入到下面这个栈中),不然不可以找到所有的最小值。
如下图: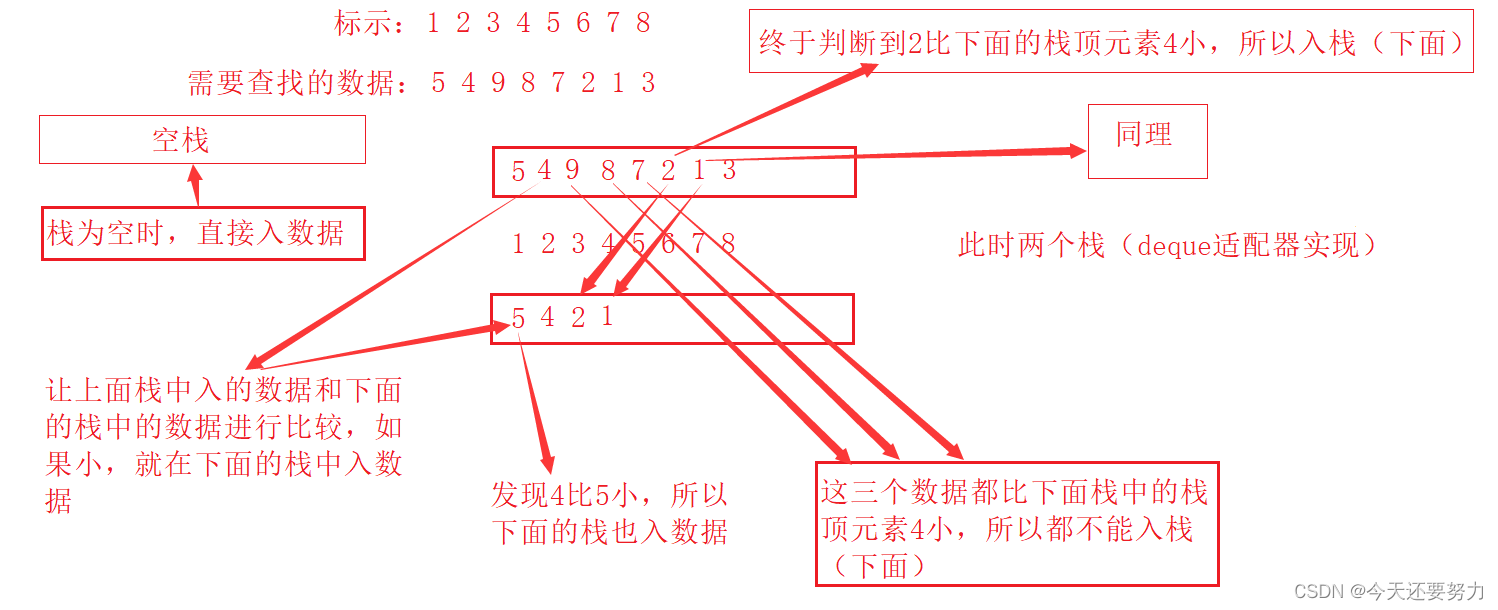
如上图和上述的题目原理,我们可以很好的实现这个题目的要求,但是唯一的一点不足就是上述的那个注意点,所以在写代码时,需要按照注意点,进行一定的改动(就是当入栈数据等于下面最小栈的栈顶数据时,也入到最小栈中),具体代码如下:
class MinStack{public:MinStack()//此时这个就是最小栈的构造函数(我们不写也没关系,因为构造函数编译器默认会对自定义类型初始化,内置类型不作处理){}void push(int val){_stack.push(val);if (_minstack.empty() || val <= _minstack.top()){_minstack.push(val);//满足条件要求, 就是此时的最小值,就入栈}}void pop(){if (_stack.top() == _minstack.top())//出栈过程,只要满足这个条件,就是表示是栈中的最小值{_minstack.pop();//想要删除最小栈中的数据,只有当上面的栈中的数据和下面的数据相等的时候,才可以删,不可以乱删}_stack.pop();//此时的这个删除数据跟我们的获取最小数据并没有关系(想要获取最小数据,只能是获取栈顶数据),删除的目的只是让这个栈拥有删除数据的能力}int top(){return _stack.top();}int getMinStack(){return _minstack.top();//这步就是根据原理之后,得到的答案的关键一步}private:stack<int> _stack;stack<int> _minstack;};当然,这种题目第一步就是使用库里面的stack类,定义两个栈对象出来,通过两个栈的判断关系进行解题。
搞定一题,再来一题,这题可以说是真正的有关栈的经典题目
题目:栈的压入、弹出序列(难度:中等)
题目描述: 输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否可能是该栈的弹出顺序,假设压入栈的所有数字都不相等,例如序列1 2 3 4 5 是某个栈的压入顺序,序列4 5 3 2 1是该栈序列对应的一个弹出序列,但4 3 5 1 2 就不可能是该压栈序列的弹出序列;
解题原理: 模拟入栈和出栈的过程
具体原理: 通过入栈的顺序去匹配出栈的顺序,入栈后的栈顶元素如果匹配出栈顺序,我们就出,如果不匹配,我们就继续入数据,然后再看一下是否匹配,匹配就出,不匹配就继续入,直到把所有的数据给出完
例:1 2 3 4 5 | 4 5 3 2 1
根据示例的具体原理: 第一个出的是4,那么表示3 2 1 已经在栈中了,此时就把4给出出去,此时就要出3,但是发现下一个出数据的元素是5,那么就不可以出3,就要把5给入进去,然后出5,再看3是否匹配出的顺序,发现匹配,就出3,然后判断2,同理,看时候匹配出栈顺序,匹配就出,不匹配就入,最终题目搞定。
所以只要跟上述的原理保持一致,那么此时就是符合栈的输出的,但是如果发现某个数据不匹配时,我们按照原理,就应该要入栈,并且此时在入栈过程中,也一直不匹配,那么此时就说明,这个数据并不是标准的入栈和出栈顺序(也就是错误的)
如图:
还是那句话,结合图示和原理,我们就可以很好的把题目搞定,如下代码:
class Solution{bool IsPopOrder(vector<int> pushV, vector<int> popV){stack<int> st;int pushi = 0, popi = 0;while (pushi < pushV.size())//此时因为我们的pushi(在数据一直不匹配的情况下),是要一直入数据的,但前提是小于题目给我们的vector数组的大小(没数据){st.push(pushV[pushi++]);//此时表示的就是把pushV数组中的数据给入栈(当然此时是一个一个的入(并且是由pushi决定))例:此时pushV数组中的元素是:1 2 3 4 5 ,那么此时就是把 1 给入栈while (!st.empty() && st.top() == popV[popi])//然后把刚刚入栈的那个数据去和题目给我们的popV(出栈顺序)中的数据进行比较,假如此时的出栈顺序是 1 5 4 3 2,那么就导致此时刚刚入栈的顺序,满足出栈顺序,此时它就要出栈了,然后再去入pushV数组中的第二个数据2,然后发现,popV数组中的出栈顺序中第二个数据不是2而是5,所以此时,就不符合出栈要求,所以就要进行继续入栈的操作,直到把5给入栈,然后按照popV数组的顺序,把5给出栈{st.pop();//此时的这个删除和下面的popV数组下标popi加加,就是为了防止数据连续出栈(例: 4 3 2)的情况(支持循环判断),可以一直出数据popi++;//但是此时也要注意,在删除栈顶的时候,栈被删空了,所以想要进入这个循环就要加一个条件,就是判断栈是否为空(为空就不进入这个循环)} //在循环中再嵌套一个判断栈不为空的if语句也是可以的//代码来到这里,就表示需要入数据 ,例:此时是popV中出数据的顺序是5,那么此时就不满足,就需要先把 4 3 2 给入进去,就要调外层循环入数据}//return popi == popV.size();//popi走到尾,表示的就是出栈顺序判断完了(因为是一个一个和popV数组中的出栈顺序进行匹配,所以popi是需要一直向后走的)//和上述的原理一样,当我们把pushV数组中的元素全部给入进去之后,还是没有匹配到popV数组中要出的那个元素顺序,那么此时该popV数组就是有问题的return st.empty();//此时栈是空的也是可以判断的(如果栈为空,就表示符合popV数组的顺序,pushV数组中入栈的元素全部被删除了(也就是出栈了)),如果栈不为空,也就是没有找到匹配的顺序,出不了,栈就不为空}};每句代码的注释都非常的详细,所以使用库里面的栈做题,就是很爽(C语言自己实现栈,我真的是受够了!哼!)
STL中栈的自我实现
搞定了上述的题目和使用原理,此时就轮到栈的自我实现了(目前不使用deque适配器,而是使用vector或者list实现),代码如下:
namespace wwx{template<class T, class Container = vector<T>>//此时的这第二个参数,本质上还是一个模板参数,名字是可以随便起的,但是因为此时该模板的作用是调用一个容器模板,所以此时就给了一个容器的英文单词(并且此时给了这个模板参数一个缺省参数)class stack//所以本质上模板参数和形参是一样的,只是此时的模板参数代表的是类型(什么什么类型),如果改成特定的类型,就跟普通的形参没有任何区别了{//就是对一个已有中的模式进行转换(类似于生活的对电力进行转换,降电压)并且此时涉及到一个叫设计模式的东西,大佬搞出来的,设计模式public:void push(const T& x){_con.push_back(x);//此时就是往数组中入数据的意思(类似就是在入栈)}void pop(){_con.pop_back(); //入完数据,此时数组的最后一个数据就类似于我们的栈顶(所以使用尾删,就等于是在删除栈顶元素)}bool size(){return _con.size();}const T& top()//这种const引用真的很好用{return _con.back();//返回数组的尾部数据,就等于是在返回栈顶元素}bool empty(){return _con.empty();}private:Container _con;//使用一个叫container的适配器来实现栈(类似就是一个vector的数据结构(因为栈不仅可以使用数组实现,也可以使用链表实现))};void test_stack1(){stack<int, vector<int>> st;//这种属于是数组栈//stack<int> st; //因为有缺省值,所以不传也可以(半缺省)//stack<int, list<int>> st;//这个叫链式栈(所以上述的那个适配器就是一个其它类型的数据结构,我们直接使用库里面已经实现了的数据结构来实现栈就行了)st.push(1); //所以此时你想要实现什么类型数据结构的栈,你就给给什么类型的数据结构当作栈的适配器就行(当然最好的数据结构(适配器)是deque)st.push(2); st.push(3);st.push(4);st.push(5);while (!st.empty()){cout << st.top() << " ";st.pop();}cout << endl;}}int main(){wwx::test_stack1();}注意:因为此时我们使用了类模板的方法去实现栈,所以该栈最好不要在.cpp文件中实现,而是去.h文件中实现,因为模板的定义和声明分离是非常的麻烦的,慎用!
并且自我实现栈属实没什么好讲的,而且还是复用别的容器实现,就更没什么好讲的了,所以过啦!
让我们进入到队列吧!(更开心!)
STL中的队列
队列的使用和上述栈的使用是一样的,原理也是一样的,实现也大致是一样的,所以没什么好学的,有一个使用队列实现栈的题目,以前搞过(自己去博客中找),所以我们直接就是把队列的自我实现代码写一下就行了,如下:
#include<iostream>#include<vector>#include<list>using namespace std;namespace wwx{template<class T, class Container = list<T>>class my_queue{public:void push(const T& x){_con.push_back(x);//此时就是往数组中入数据的意思(类似就是在入栈)}void pop(){_con.pop_front(); //这个位置是队列和栈的第一个区别(栈是队尾插入队尾出),而队列是队尾插入队头出}bool size(){return _con.size();}const T& front()//出队头数据{return _con.front();}const T& back()//出队尾数据{return _con.back();}bool empty(){return _con.empty();}private:Container _con;//使用一个叫container的适配器来实现栈(类似就是一个vector的数据结构(因为栈不仅可以使用数组实现,也可以使用链表实现))};//队列能不能用vector适配器呢?//这影响到我们可不可以使用vector实现队列//答案是不可以使用vector实现队列//原因:队列要支持尾插和头删(但是vector是不支持头删的(效率很低))void test_queue(){my_queue<int, list<int>> q;//由于用vector效率低,所以我们用list就行//stack<int> st; //因为有缺省值,所以不传也可以(半缺省)q.push(1); q.push(2);q.push(3);q.push(4);q.push(5);while (!q.empty()){cout << q.front() << " ";q.pop();}cout << endl;}}int main(){wwx::test_queue();}最大的区别就是:多了两个接口(得到队头和队尾数据),并且先进后出,变成先进先出的写法
注意: 唯一的一个注意点,就是因为vector是不支持头插和头删的,所以此时不支持使用vector来实现队列(效率问题),一般是使用 deque ,但是此时我们使用的是list;
北京时间:2023/3/15/22:52
总结:在数据结构的基础之上,STL中的栈和队列学起来没有什么成本,重点我觉得还是list中的各种细节,但是如上述所说一样,百炼成钢,就是干!
最后总结一个小注意点(非常容易写错):以前在学string类的时候,当时类名就是类型(string类),但是此时学习了模板类,类名就不再是类型了,只有类名加模板参数,此时才是类型,切记!
list收尾代码
template<class T>class my_list//此时不是那种无哨兵位的单向非循环链表,而是带头双向循环链表{typedef list_node<T> node;//此时为了防止每一次把这个模板参数T给写漏掉(是类型不是类名),此时我们就直接把它给typedef一下,这样就非常的方便public:typedef __list_iterator<T, T&, T*> iterator;//此时里面这个类和外面那个类的本质区别就是,里面这个类,属于内部类(表示封装的迭代器类本质是my_list类的类),并且没有把外面那个typedef写进来的原因是,私有成员变量有用到,并不是都是给公有函数使用的,所以定义成全局类,提供给整个类使用(而迭代器类,私有成员变量用不上,所以就可以写成内部类的写法)typedef __list_iterator<T, const T&, const T*> const_iterator;//通过这种多一个模板参数的形式来实现同一个迭代器实现两中类型的迭代器调用//typedef __list_const_iterator<T> const_iterator;//这样我们就自己实现了一个const类型的迭代器,这样const类型的begin和end函数就可以使用const迭代器了iterator begin(){//iterator it(_head->_next);//此时的这句代码就是在调用上述的那个迭代器(使用上面的迭代器去帮我们构造一个it出来)//return it;//此时要注意,只有当传上来的值和修改的值都是自己本身的时候,才return *this,而当传上来的值是自己,都返回的值不是自己的时候(是重新构造出来的),此时就应该返回那个重新构造出来的结点//这边反而是不喜欢上述的写法,喜欢直接使用经典的匿名对象就行替换return iterator(_head->_next);}const_iterator begin()const{return const_iterator(_head->_next);}iterator end()//此时这个位置我们的end给给哨兵位的意思是,我们的迭代器是左闭右开的,迭代器中最后一个位置是最后一个数据的后一个位置(所以此时表示的就是哨兵位的位置,所以不是给给_head->prev,而就是哨兵位,因为此时end是迭代器中的end){return iterator(_head);//使用_head去构造一个迭代器对象(匿名),就是去调用上述迭代器中的构造函数,然后用括号里面的这个结点去初始化一个新的结点(这个结点就是我要的结点)}const_iterator end()const{return const_iterator(_head);//此时为什么_head是const类型,还可以改变呢?原因:表示的是_head不可以改变,但是_head中的指针(_next/_prev)是允许指向别的东西的(所以可以改变),并且由于此时是涉及拷贝问题,所以也是允许拷贝的}void empty_init(){_head = new node;_head->_next = _head;_head->_prev = _head;}my_list()//带头双向循环链表 (明白此时的这个东西叫链表),所以遍历方式此时就只有使用迭代器,使用方括号和下标的方式纯属是搞笑的{//此时我们没有像源码一样,使用嵌套一个空初始化的函数,而是直接new//_head = new node;//此时这个的意思表示的是开辟一个哨兵位的头结点出来(但是要注意,new后面跟的一定是一个类型,所以我们的ListNode是一个模板类型,那么此时就需要把它的模板参数给带上)//_head->_next = _head;//然后此时让这个哨兵位的next指向自己//_head->_prev = _head;//哨兵位的prev指针也指向自己//此时有了一个专门用来初始化头结点的函数,所以直接调用就行empty_init();}//注意:一定要把类名和类型给区分开来,类名是类名,类型是类型,类名加上模板参数就是类型//这个位置还可以来一个迭代器类型的构造函数template<class iterator>my_list(iterator first, iterator last)//迭代器的构造函数{//但是由于,此时这个迭代器构造函数是需要有头结点才可以进行初始化,所以需要把头结点拿过来初始化一下 empty_init();//调函数初始化头结点while (first != last){push_back(*first);++first;}}//构造函数搞定之后,就是拷贝构造函数//my_list(const my_list<T>& lt)//记住,构造函数的本质就是为了去初始化另一个创建的还没初始化对象,所以给的就是此时这个类类型的一个变量//{//此时我们使用最现代的写法,不使用那种传统的写法了(就是通过遍历,插入,把另一个对象的数据拷贝到新对象中(由于是形参,所以不会改变函数外部中的数据))////lt1(lt2)//这个写法的话,此时的lt就是lt2,lt1就是this指针//empty_init();//for (auto e : lt)//{//push_back(e);//}//}void swap(my_list<T>& tmp)//此时使用引用交换,就是经典的去指针化交换两个数据{std::swap(_head, tmp._head);//此时的_head(this),本质上是要去调用初始化头结点,去把头结点初始化好之后,才可以进行交换}my_list(const my_list<T>& lt)//切记,此时的构造函数需要防止无限拷贝,所以不能进行传值调用,要使用传引用调用,把类和模板看成类型就行,例:string类{//构造函数超级现代化写法empty_init();//此时使用现代写法,是需要把this进行初始化的(初始化this之后,才可以让其去和tmp交换)my_list<T> tmp(lt.begin(), lt.end());//让tmp去调用拷贝构造(迭代器类型的构造函数)swap(tmp);//现代写法,窃取别人的劳动果实}//lt1 = lt3my_list<T>& operator=(my_list<T> lt)//此时这个位置不可以使用引用(因为此时赋值使用的是交换的方法(现代写法)),如果使用引用的话,就有会导致lt3中的值变成原来lt1中的值(如果不使用引用交换过程,就不会影响外部的lt3),并且此时lt3中开辟的空间会自动调用析构函数释放掉{swap(lt);//表示的意思就是把lt(lt3)的值赋值给lt1(this指针)return *this;//交换完之后lt3会自动调用析构函数释放掉//并且上述的构造函数可以使用传引用的原因是,我们使用的是tmp这个临时变量,让tmp通过(已经初始化的对象的地址)去调用迭代器类型的构造函数,所以本质上也没有改变外部的对象}~my_list(){clear();//析构函数直接调用clear清理资源就行delete _head;//头结点也是new开辟出来的_head = nullptr;//置空防止别的东西会调用它(好习惯)}void clear()//清理资源调用这个函数就可以了{iterator it = begin();while (it != end()){it = erase(it);//链表的erase是会导致迭代器失效的,所以这里,我们就要接收它的下一个位置(删除后的位置)//erase(it++);//这样写也是可以的,因为此时的加加是list迭代器的加加,本质就是next(并且因为此时的是后置加加,返回的是形参,并不会改变it本身)}}//上述的知识比下面这些list功能的知识更重要(特别就是构造函数和拷贝构造函数,真的需要好好理解)void push_back(const T& x)//这种位置一定要搞清楚该函数的作用是什么,自然而然就知道了,我们传递的参数是什么,自然而然就知道怎么写了,最多就是多用了const+引用而已,并且一定要注意,此时的数据类型就是模板类型T{//这个就是普通的数据结构的写法,这边不需要太在意,带头双向循环链表,注意好头尾的位置就行node* tail = _head->_prev;//这句代码要注意,此时不是tail在控制_head->_prev,而是_head->_prev在控制_tail node* new_node = new node(x);//注意好,此时的node是typedef过的(反正就是一个类类型的数据)例:string s1;tail->_next = new_node;//注意是双向循环new_node->_prev = tail;//注意是双向循环new_node->_next = _head;_head->_prev = new_node;//这样写就是一个经典的双向循环尾插(在哨兵位的前面找尾,然后插入,最快,根本不需要遍历)}void push_front(const T& x){insert(begin(), x);//复用insert//如果是尾插的话,也是一个道理//insert(end(), x);//这里可以直接调用begin()或者end()的原因是,我们上述写了这两个函数,间接的通过_head获得了开始位置和最后位置}void insert(iterator pos, const T& x){node* cur = pos._node;node* prev = cur->_prev;node* new_node = new node(x);prev->_next = new_node;new_node->_prev = prev;new_node->_next = cur;cur->_prev = new_node;}//void erase(iterator pos)//因为erase会导致迭代器失效,所以我们需要给一个返回值iterator erase(iterator pos){assert(pos != end());//此时因为是带哨兵位的,所以不允许把哨兵位的头结点被删除(并且此时要注意的是,不可以用head去和pos比较,和pos比较需要是一个相同类型的迭代器才可以)node* prev = pos._node->_prev;node* next = pos._node->_next;prev->_next = next;next->_prev = prev;delete pos._node;return iterator(next);//此时就让next去构造,然后再返回(此时返回的就是下一个结点的地址啦)}void pop_back(){erase(--end());//意思是end返回了一个迭代器对象,然后让这个对象去调用减减运算符,调用减减运算符的本质就是在找该结点的前一个结点} //减减的本质是因为,此时的end是迭代器中的end,是最后一个数据的下一个数据(_head),所以需要减减一下,表示的才是最后一个尾结点void pop_front(){erase(begin());}private://struct ListNode* _head;//在C语言中正常的写法是这样的,但是在C++中的时候,就可以发现,我们不一定要跟上struct也可以//ListNode* _head;//记得因为是模板类型,所以要跟上模板参数node* _head;//看到这个就要注意是typedef过的};