文章目录
前言一、需求二、分析1. 查看网页源码(ctrl+u)2、进一步分析 三、处理四、运行效果
前言
为了更好的掌握数据处理的能力,因而开启Python网络爬虫系列小项目文章。
小项目小需求驱动,每篇文章会使用两种以上的方式(Xpath、Bs4、PyQuery、正则)获取想要的数据。博客系列完结后,将会总结各种方式。一、需求
批量爬取简历下载到本地文件中二、分析
1. 查看网页源码(ctrl+u)

网页源码中有各简历下载模板地址,如下图。
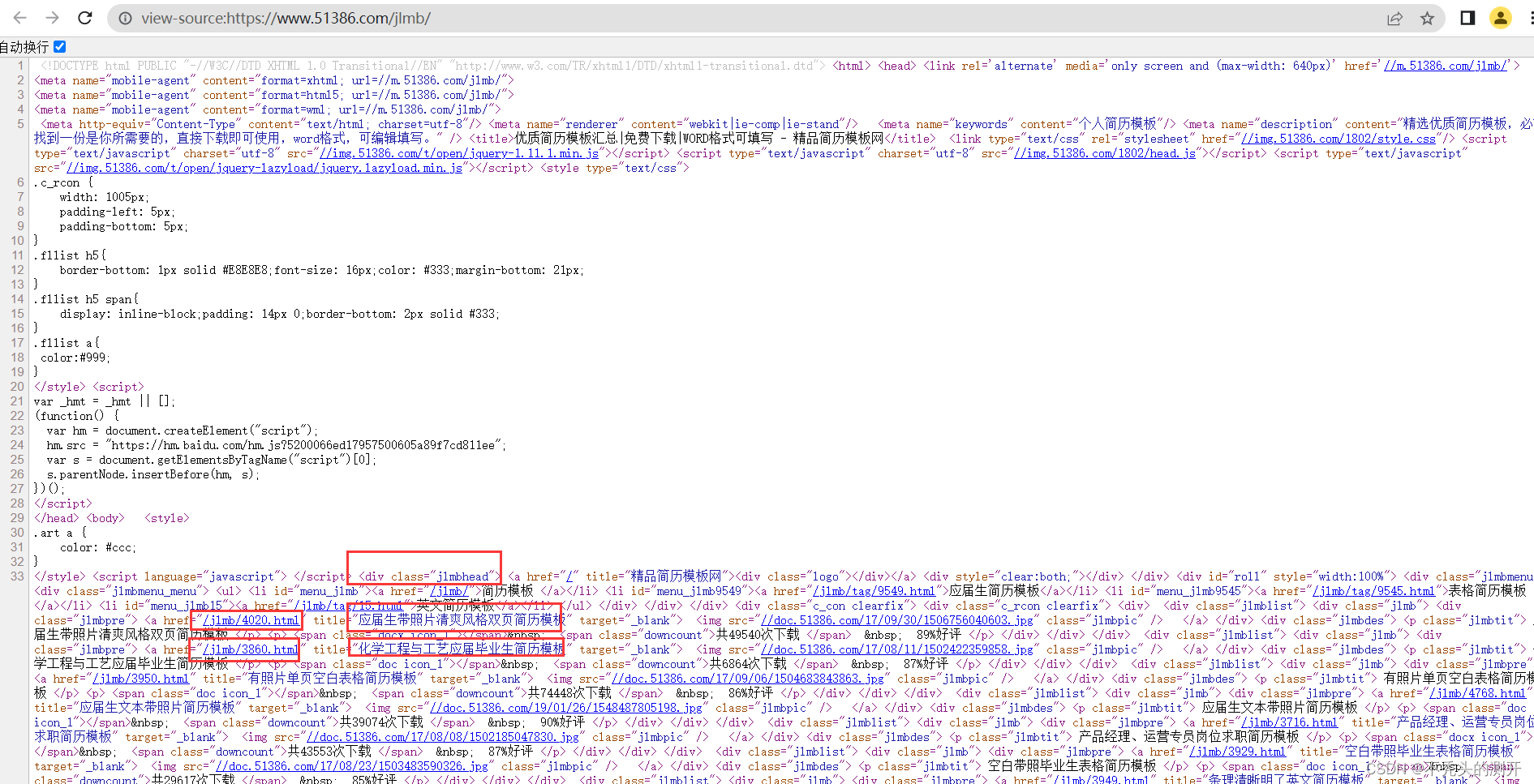
2、进一步分析
进入具体简历模板页面
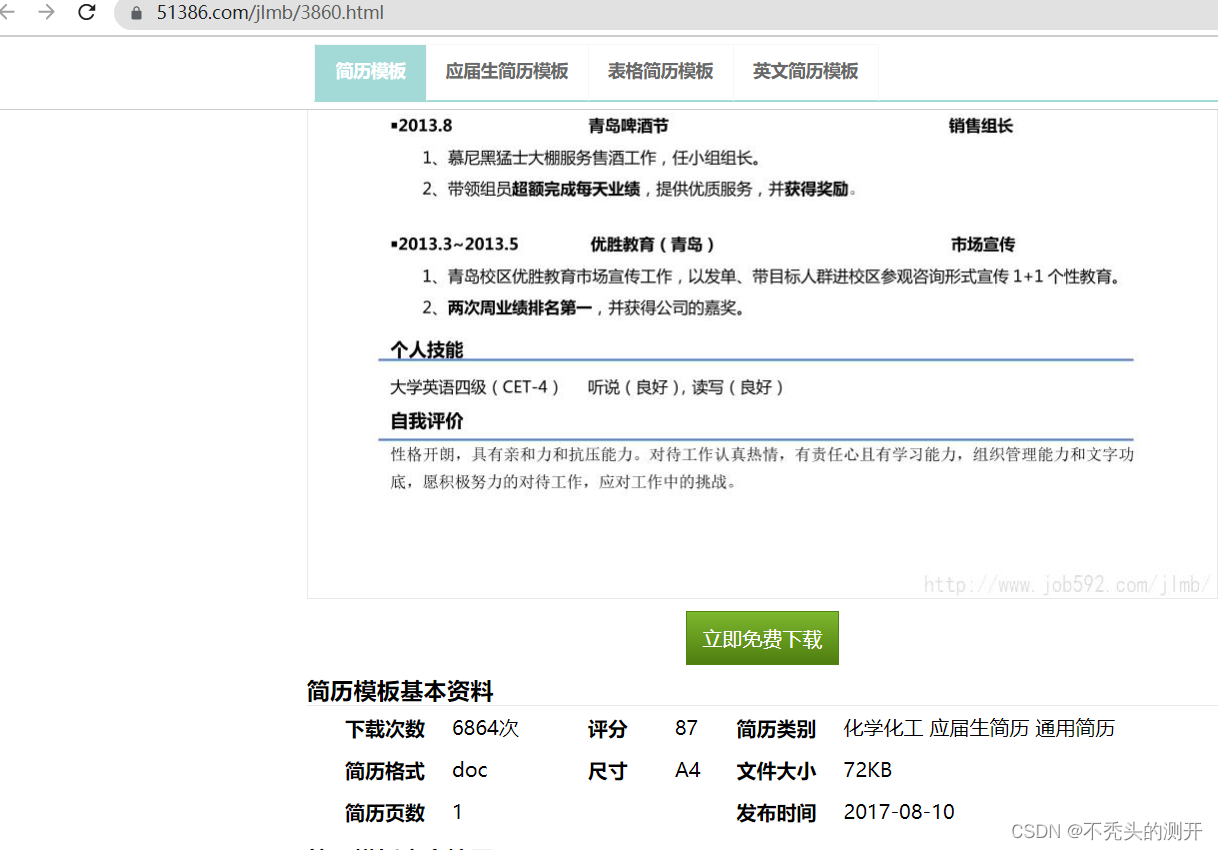
F12进行抓包 ,分析点击免费下载的具体流程。
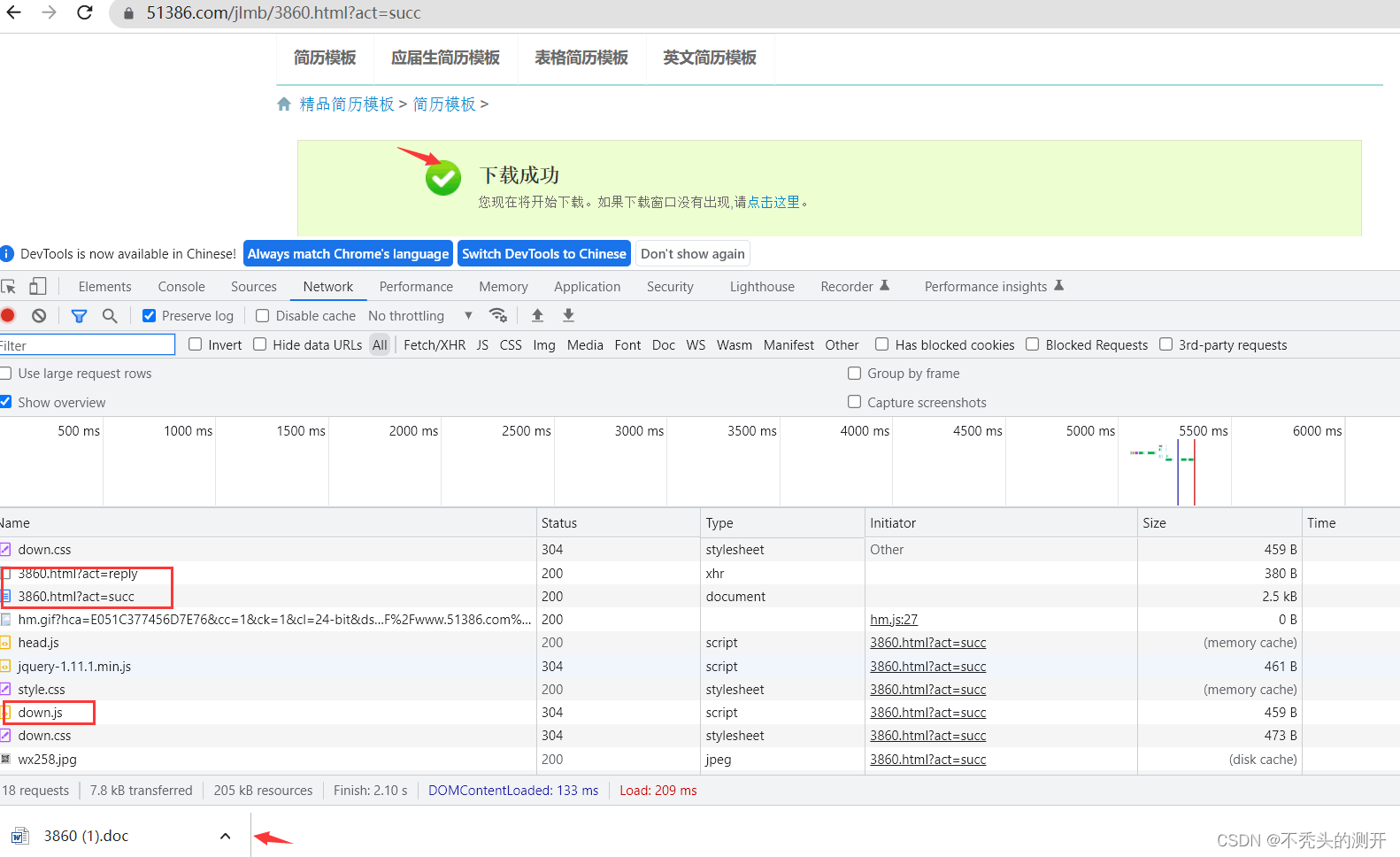
分析接口
https://www.51386.com/jlmb/3860.html?act=reply
https://www.51386.com/jlmb/3860.html?act=succ(页面返回下载资源)
https://oss.51386.com/3860.doc?Expires=1667648595&OSSAccessKeyId=OpPa5NVGTtEGvNCR&Signature=KAMPsVBwfE6p1g0OZbvdSEDuwl0%3D(最后下载资源的请求路径)
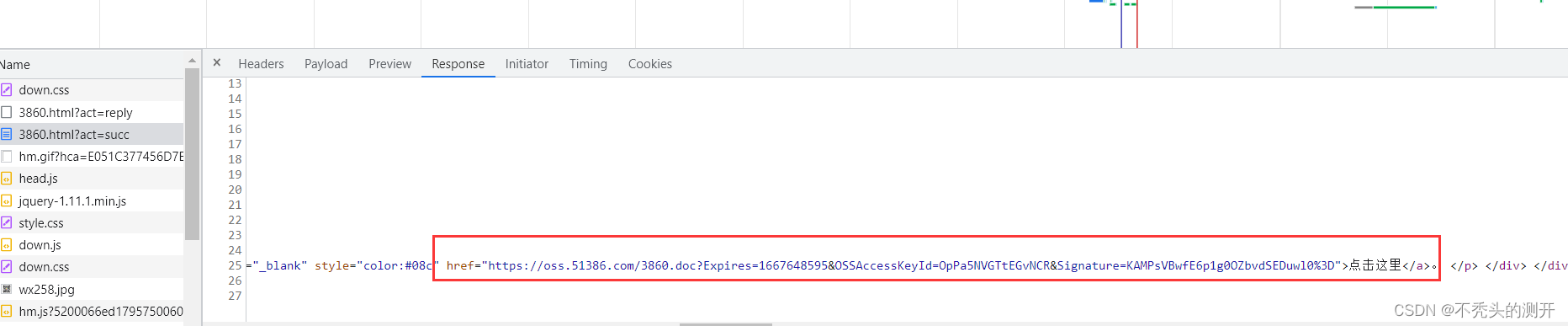
分析js文件
https://img.51386.com/1802/head.js(ip统计来控制下载次数)
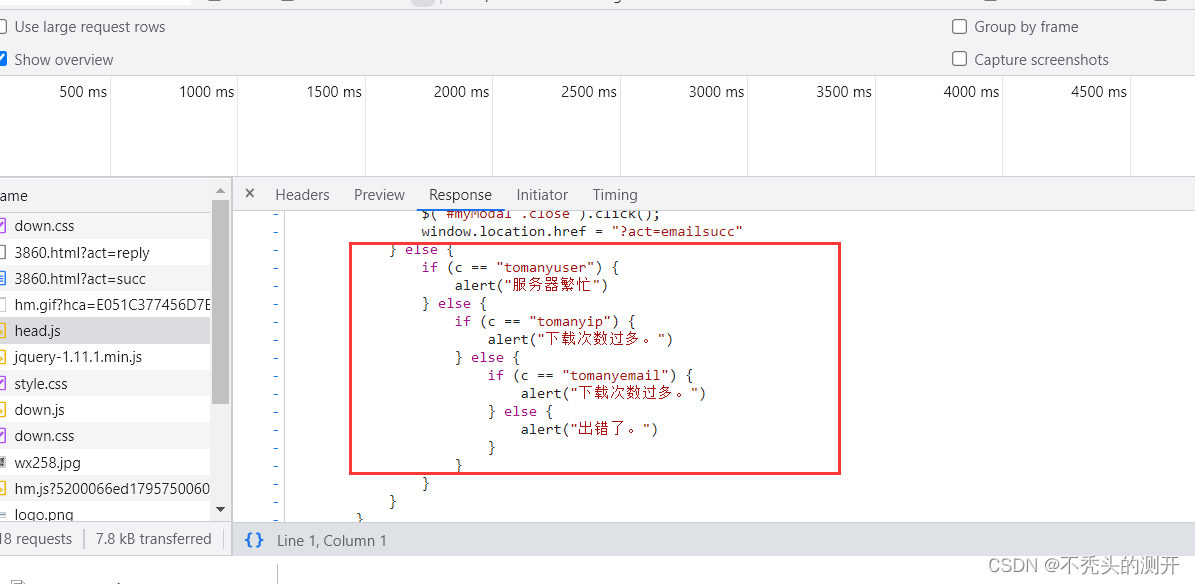
三、处理
获取简历模板url
from pyquery import PyQuery as pqINDEX_URL = "https://www.51386.com/"def get_download_url(code): doc = pq(code) # 通过-jlmblist class属性获取简历url content = doc(".jlmblist") resume_dict = {} for resume in content.items(): title = resume("a").attr("title") url = resume("a").attr("href") # 这里拼接了直接形成第二个接口https://www.51386.com/jlmb/3860.html?act=suc resume_dict[title] = f"{INDEX_URL}{url}?act=succ" return resume_dict下载简历
import requestsimport redef get_resume_url(url): headers ={ "referer": "https://www.51386.com/jlmb/4020.html?act=down" } res = requests.request("GET", url, headers=headers) # print(res.text) # 正则拿到oss下载资源 try: deal = re.compile(r'"color:#08c" href="(?P<oss_url>.*?)">点击这里</a>',re.S) result = deal.search(res.text) oss_url = result.group("oss_url") except Exception as e: print(f"正则获取oss_url失败,{e}") return oss_url整体代码
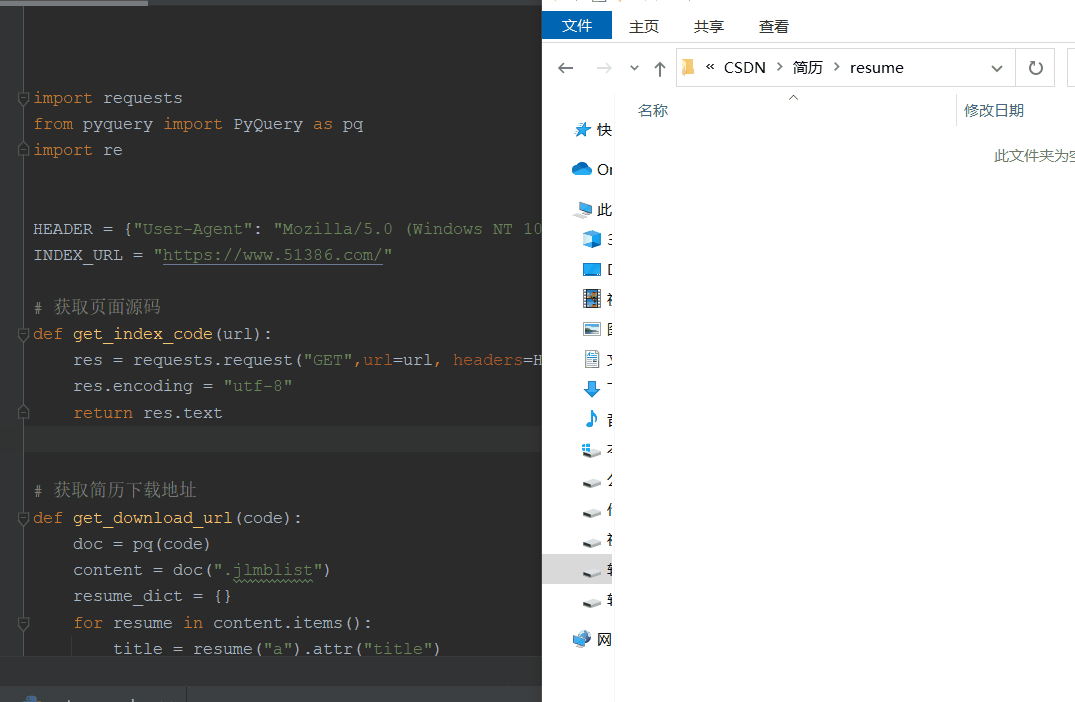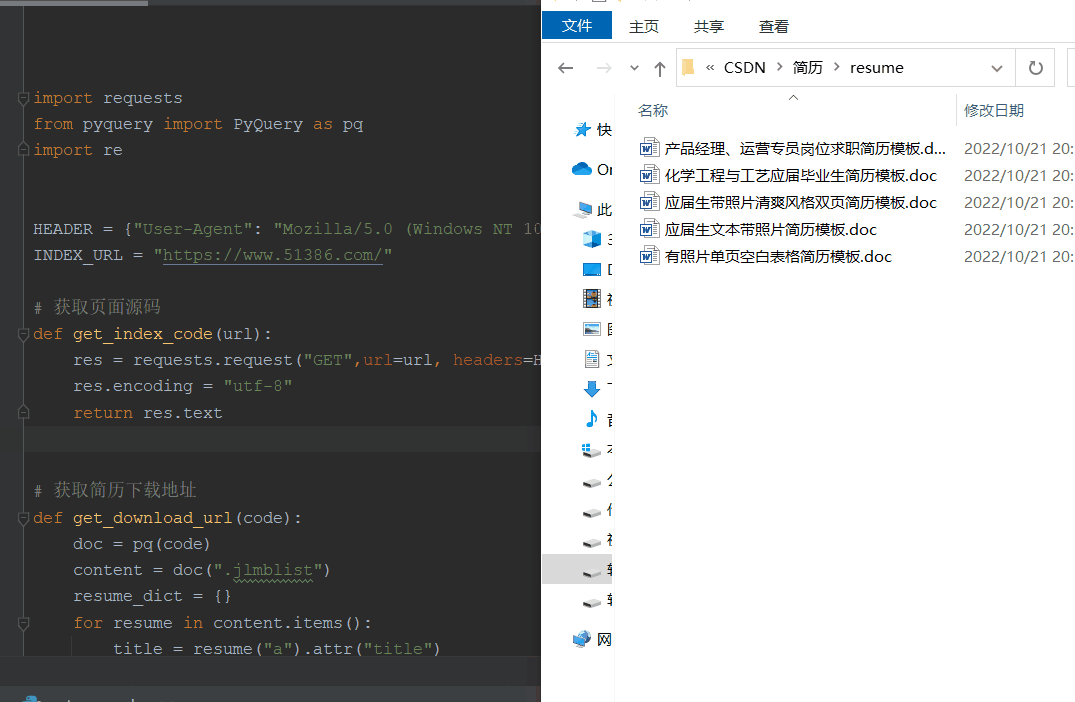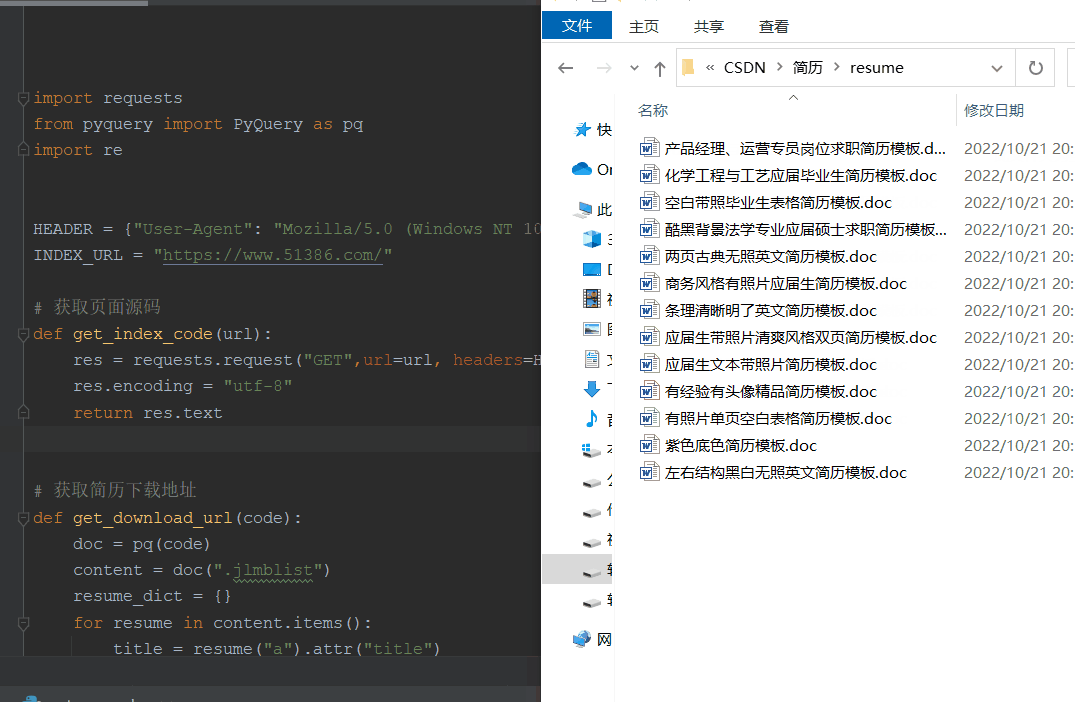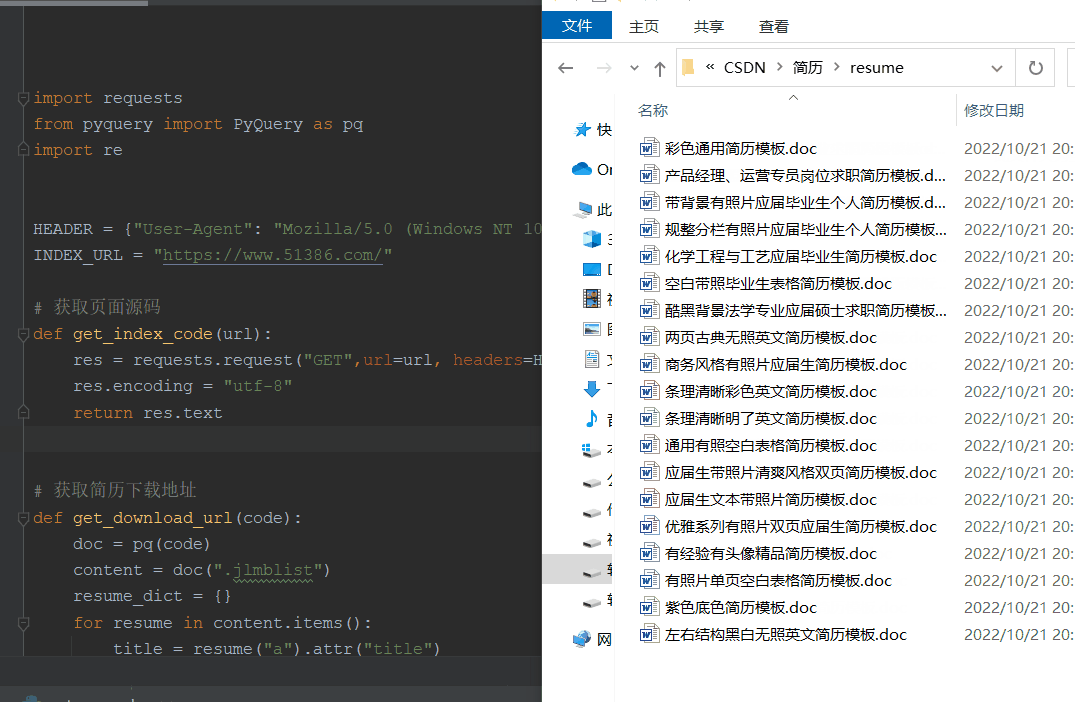
# -*- encoding:utf-8 -*-__author__ = "Nick"__created_date__ = "2022/10/21""""待补充1、下载受限(统计ip来控制下载)---代理IP"""import requestsfrom pyquery import PyQuery as pqimport reHEADER = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"}INDEX_URL = "https://www.51386.com/"# 获取页面源码def get_index_code(url): res = requests.request("GET",url=url, headers=HEADER) res.encoding = "utf-8" return res.text# 获取简历下载地址def get_download_url(code): doc = pq(code) content = doc(".jlmblist") resume_dict = {} for resume in content.items(): title = resume("a").attr("title") url = resume("a").attr("href") resume_dict[title] = f"{INDEX_URL}{url}?act=succ" return resume_dict# 获取简历下载地址oss_urldef get_resume_url(url): headers ={ "referer": "https://www.51386.com/jlmb/4020.html?act=down" } res = requests.request("GET", url, headers=headers) # print(res.text) # 正则拿到oss下载资源 try: deal = re.compile(r'"color:#08c" href="(?P<oss_url>.*?)">点击这里</a>',re.S) result = deal.search(res.text) oss_url = result.group("oss_url") except Exception as e: print(f"正则获取oss_url失败,{e}") return oss_url# 下载简历def get_download_resume(url,name): if url: res = requests.get(url,headers=HEADER).content f = open(f"resume/{name}.doc",'wb') f.write(res) f.close() else: print("oss资源获取失败")if __name__ == '__main__': code = get_index_code(url="https://www.51386.com/jlmb/") resume_dict = get_download_url(code) try: for title, url in resume_dict.items(): oss_url = get_resume_url(url) get_download_resume(oss_url,title,ip_dict) except Exception as e: print(e)四、运行效果