作者:李如豹 博士,Rateup CTO
1. 介绍:什么是GPU数据库?
在过去十年里,GPU数据库已经成为数据库产品中的一个分支,并且解决了很多大规模数据密集型应用客户的关键问题。然而,虽然GPU数据库频繁出现在各种报道新闻中,但是业界对于GPU数据库的定义、GPU数据库的发展历史以及GPU数据库所能解决的本质应用需求仍然不了解。有鉴于此,本文尝试回答这些问题,并对GPU数据库的发展现状和将来预期进行讨论。
1.1 GPU数据库的定义
GPU数据库是个经常用的术语,但其本质指的是 “利用GPU设备处理某些数据处理功能的数据库管理系统” ,这些功能所涉及的范围可能很广,例如从某些特殊函数的处理到完整的查询引擎(或者其它数据库组件)。因为数据库管理系统的一个特性是允许用户添加自定义的函数来扩展数据库的功能,因此存在不同的场景关于GPU是如何被接入到数据库系统中的,这包括:场景(1)数据库管理系统本身不提供对GPU设备的任何管理和使用,但数据库管理系统提供扩展函数功能允许用户在其自定义函数内使用GPU设备的处理能力来完成某些操作;(2)数据库管理系统的某些内置功能被直接实现在GPU设备上,并且数据库管理系统直接管理底层的GPU设备,但是否其允许上层应用或者其它扩展函数使用或者访问GPU设备均可。
我们所定义的GPU数据库概念包含上述两种情况——只要数据库系统的某个功能使用了GPU设备,那么该数据库系统都可以称之为GPU数据库。最常见的GPU数据库形态(当前主流形态)是利用GPU设备来执行SQL查询,但对于不同产品而言,一个完整SQL查询所涉及的多个算子中,哪些被放置在GPU上执行并不确定;并且这种任务调度的方式完全可以在查询运行动态中完成。需要指出的是,理论上而言GPU并不仅限于执行查询处理,很多学术研究工作也指出在GPU上执行key/value查询和事务处理的可能性,因此当必要时,我们应该区分广义上的GPU数据库可能性和主流产品中的具体形态。根据目前工业界进展,我们所探讨的GPU数据库都是指的是利用GPU来加速查询处理的数据库系统。
1.2 GPU数据库的发展历史
从2003年到现在,GPU数据库这一产品形态或者数据库形态已经走过了18年!已知最早的学术研究工作是2003年的一篇SIGMOD论文: “Hardware Acceleration for Spatial Selections and Joins” 。该工作在通用GPU出现之前首次探讨了如何利用GPU硬件的rendering和searching能力来解决复杂计算几何算法的性能问题。该论文中所述技术方案出现在Nvidia CUDA生态系统之前,属于早期探索复杂数据库运算同底层硬件匹配的核心问题所在。在2010年之后,随着各种新应用的兴起,GPU数据库慢慢发展起来。对GPU数据库的学术研究开发了很多原型系统,例如GDB、GPUDB、Ocelot等,其目的是研究各种数据库并行算法,系统架构以及各种优化技术。工业界的GPU数据库包括了两类,一类是从PostgreSQL等传统开源CPU数据库上扩展而来的系统,例如日本的HeteroDB和英国的Brytlyt数据库;另一类是从头为GPU开发的全新数据库,例如美国的Kinetica和OmniSci,中国的RateupDB,以及以色列的SQream等。
1.3 GPU数据库所解决的工业需求
随着人类社会进入所谓的数据驱动时代,各种新应用需求层出不穷,其背后根本驱动原因是由于遍地普及的终端(例如手机)所带来的各种新经济模式,例如典型的移动计算带来的各种应用需求。这些需求往往超越了传统关系型数据库所提供和优化的数据处理能力,而需要新型数据库。我们总结有如下三种需求:
- 对实时业务价值的需求:这是最重要的业务需求,其目标是在各种及时更新的数据集上利用各种计算分析来获取瞬时的业务价值。一个典型的场景是实时车辆位置管理所带来的一系列业务应用,其典型代表是Uber内部使用的AresDB方案和USPS里面使用的Kinetica方案。对于一个运营几百万载客车辆的出行服务公司来说,实时的路线规划和偏航率分析不仅能够降低运营成本,改进客户体验,并且是实时恶意行为检测和犯罪提前预警的重要手段。
- 对极端计算能力的需求:当前存在对非结构化数据爆炸性的分析需求,而这些分析必须依赖于极端强大的计算能力,特别是这些数据的大规模增长和CPU有限算力之间的矛盾使得很多分析不能有效开展。典型的例子包括图数据分析、DNA序列分析,空间数据分析、3D结构分析等。尽管传统数据库在处理这些数据时存在性能问题,例如“Oracle Spatial and Graph”,各种行业的用户仍然首选一个数据库平台来执行这些分析,这是因为用户最需要数据库的简单接口以分离上层应用和底层系统。
- 对全面数据平台的需求:随着实时分析、智能分析、扩展分析的重要性日渐突出,传统企业内部多套数据库集成的方案越来越不能满足核心需求,特别是多套库之间所带来的业务延迟、协调管理以及维护开销等随着业务规模的增长越来越严重。例如,把大量数据从数据库提取出来送到一个智能分析平台里进行智能分析严重违背了用户对实时智能分析的需求。传统数据库系统通过加入各种扩展来尝试解决这些问题,例如Teradata Vantage,然而由于CPU的算力有限,很多复杂分析只能借助于其它非数据库内置的模块,例如TensorFlow。由于这些模块本身并不被数据库系统管理,因此存在各种数据格式转换以及资源调度冲突等问题。
2 GPU数据库的现状
2.1应用落地之绝对刚需
2.1.1案例分析
GPU数据库在实际行业中的大规模应用起始于用户的上述三个需求。特别是,在车联网中,上述三个需求叠加起来形成一个即重要迫切又非常挑战的场景:如何在实时记录车辆位置的海量瞬时数据的基础上进行各种不同复杂度的数据分析?举例来说,Uber出行服务需要的一个实时计算需求是:如何及时检测出通过GPS欺骗技术来伪造的假行程?这一问题同时涉及上述三个需求:(1)必须实时计算以停止最终的付款,因为其是一个假行程;(2)要求强大算力,因为行程检测需要处理三维GPS坐标位置(经度纬度高度)数据以及利用机器学习模型执行异常检测;(3)要求一站式的平台来同时完成数据入库和计算分析,且支持地理信息数据和机器学习能力。根据Uber AresDB的技术报告,Uber发现没有任何一个CPU数据库产品能满足上述需求,因而Uber内部开发了AresDB这一GPU数据库来解决其绝对刚需。
另外一个商业GPU数据库产品在大规模车联网中的应用是Kinetica对USPS核心业务的支撑,其解决方案赢得了IDC 2016年的高性能计算卓越发明奖(HPC Innovation Excellence Award)。USPS有六十万员工和22万辆邮车,邮递业务涵盖美国的1.5亿个地址。USPS关键业务需求是每天如何保证大量邮递工作的高效率和低成本。为了满足该需求,底层数据库系统必须能够同时高效率的执行两类操作:(1)实时数据写入:每辆邮车每分钟汇报位置信息;(2)实时数据分析:基于实时位置信息,执行各种数据分析以支持实时车辆调度、覆盖度分析、动态路线规划以及并发用户查询等业务。同Uber类似,USPS也实验了其它基于CPU的数据库解决方案,发现均无法完美解决问题。
最终USPS部署Kinetica在一个包含150-200个节点的机群上,其中每个节点包含一个x86刀片服务器、0.5-1TB内存,两个Nvidia Tesla K80 GPU。随着每分钟车辆位置信息汇入,该系统每天可存储和分析超过两亿条的事件信息;并且该系统可最大提供15000个并发会话,以支撑各种上层应用。另外,通过高可用性冗余设计,Kinetica方案达到5个9可靠性。Kinetica方案硬件价格估算为1000万美元(200个节点,每个节点估计5万美元),软件价格按照1:1估算为1000万美元,因此Kinetica方案投入是2000万美元。上线后,该方案可每年为USPS节省百万到千万美元级别的运营成本。每年USPS投递超过1500亿邮件,该方案的实时分析能力可帮助车队少开7000万英里,节省700万加仑汽油,并降低7万吨的碳排放。
2.1.2刚需落地分析
上述案例所反应的刚需点(实时分析、计算密集以及一站式服务)是当前以及可预期未来的典型计算特征。随着5G和IoT的发展,移动终端所贡献的数据量以及所带来的实时计算需求日渐迫切。特别是,AI技术的发展使得复杂分析成为可能,进而成为数据计算闭环中的关键一步,从而衍生出了实时目标识别、异常检测、无人决策等各种过去无法实现的关键业务,分布在军事、民生、健康、金融等各个领域,而这是传统数据库根本无法适应的。最近,Kinetica赢得了美国空军一亿美元的数据仓库合同,为其构造一个综合平台来完成各种移动目标的瞬时识别等智能分析需求,而这种瞬时识别分析所需要处理的对象是美国防空等各种军事单位(本案例中所涉及的只是北美空防司令部和美国北方司令部)所具备的各种雷达及传感器设备所生成的每天10亿条量级的大数据。根据公开报道,这一PB级别数据仓库案例是Kinetica在对比Spark/Hadoop大数据方案的1/10成本下赢得的。
2.2应用落地之竞品对标
GPU数据库产品的落地应用并不仅限于上述绝对刚需,而是可以直接对标传统CPU数据仓库或者数据分析平台(例如Greenplum, Amazon Redshift, Clickhouse等),并取得性能和性价比两方面的绝对优势。正是基于这两方面的优势,考虑到标准数仓软件以及离线非实时数据分析的广泛市场空间,GPU数据库能够在不同行业不同规模的用户场景中落地,例如电信、金融、医疗等。
2.2.1案例分析
SQream对标Greenplum案例: AI是泰国电信运营商中的领头羊,有超过四千万的用户。 电信数据分析作为经典的数据仓库案例需要执行大量耗时的数据聚集联接等复杂数据库查询操作,从而能够把几十亿条数据转换成有价值的商业智能信息,从而有效的提高用户满意率和降低用户流失。AIS原来使用Greenplum数据仓库,然而其查询性能不能满足AIS日益增长的数据规模。一些复杂业务查询经常需要小时级别的执行时间,某些查询甚至一天都不能完成。AIS部署了SQream数据库,利用其GPU加速的分析引擎实现了一个智能基准仪表板系统,从而允许数据分析人员和管理部门能够很容易的分析各种数据并解决全国网络中出现的各种问题。SQream的GPU架构能够使其在秒级完成几亿条的数据记录联接操作,并支持更深的数仓下钻(drilldown),更快的竞争分析和数据聚集。例如,AIS有一个复杂的竞争分析查询,其需要处理一个包含几亿条数据的针对网络速度测试的数据集, 原先Greenplum需要一个小时完成,而SQream只需要50秒。
RateupDB对标Clickhouse案例:中国某公司作为领先的互联网实时结算平台已经服务了超过5800万的个体经营者,并且累计结算金额超过1200亿元。该公司的结算服务严重依赖于后端数据仓库系统所提供的全面数据分析能力,从而供企业内部各种人员及时、准确、完整的了解运营状况,服务质量以及各种及时信息。特别是,其业务特性使其必须构建一个可靠的高性能企业数据仓库系统,其即能提供实时仪表板数据分析,又能提供标准的离线OLAP分析。该公司对数据仓库软件的需求包括(1)必须支持事务处理以供交易修改;(2)必须支持高性能OLAP;(3)必须支持不停机数据库模式修改以满足前端交易系统要求;(4)必须能够部署在华为云既有硬件实例上。然而,其业务痛点是(1)所选用的一套HTAP系统能支持事务处理,但查询性能太慢,且对某些突发查询场景不能保证执行时间;(2)所选用的另一套Clickhouse系统虽能提高查询性能但不支持完整事务,因而不能完整支持全部数仓需求。经过仔细评估比较后,该公司在华为云上部署一套RateupDB系统,运行在一台单机多GPU硬件上。稳定运行后实现了两个效果,即彻底解决该公司的数仓建设问题,又较之原有系统,在性能提高30% 的同时云服务使用成本降至原来的50%(Clickhouse系统原租金成本每月1.6万圆人民币,现在RateupDB是8000圆人民币)。
2.2.2 对标落地分析
上述落地案例都是GPU数据库产品在同某个传统数仓软件直接竞争下来获胜而赢得的业务。事实上,这种模式也是广大行业用户最熟悉的产品选型过程。因为数据库行业已经发展半个世纪有余,用户已经行成了一套完整的闭环逻辑,其中包括功能、性能、性价比、服务质量等多个因素,从而比较和挑选数据库产品。作为一种实现SQL语言的系统,GPU数据库能够参与几乎所有标准竞品竞争。
2.3 RateupDB对标其它软件
2.3.1 云服务:RateupDB对标Amazon Redshift
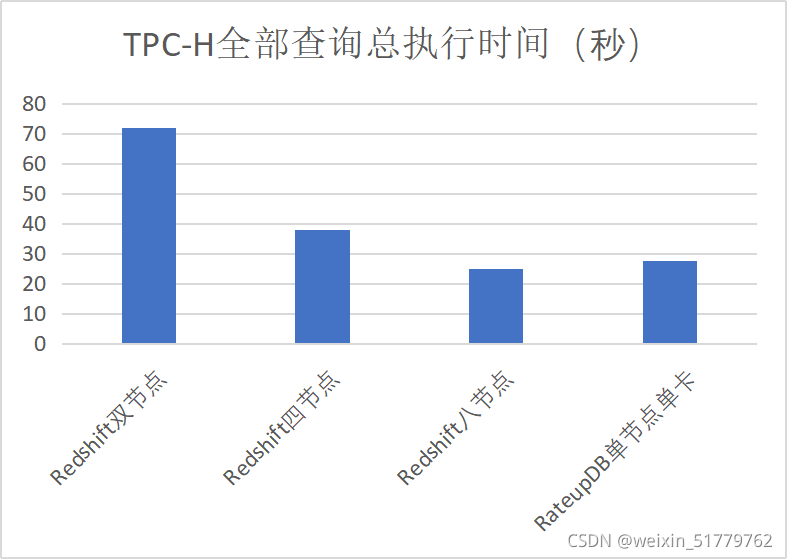
选取目前最具代表性的Amazon Redshift云数据仓库作为对比目标,RateupDB单节点单卡(Nvidia Quadro RTX 8000 GPU, 256GB内存)的性能约等于Redshift在8个ra3.4xlarge节点 (总共96 core, 大约800GB内存)上的性能,如下图所示,且价格只大约是其四分之一(根据RateupDB硬件成本和Amazon Redshift云服务价格对比换算)。
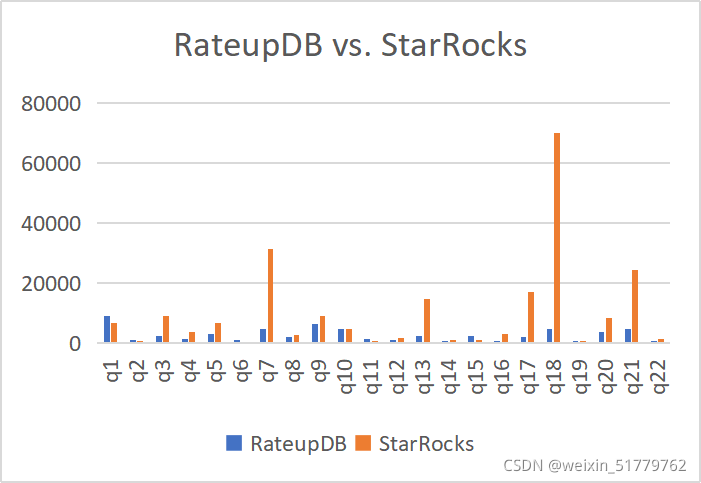
2.3.2 数仓软件:RateupDB对标StarRocks/DorisDB
综合比较二者在工业标准测试基准TPC-H下的性能:
- StarRocks/DorisDB不能通过完整的TPC-H测试基准;
- 只能测试StarRocks/DorisDB的TPC-H只读数据查询性能。
结论:同等云硬件成本下,RateupDB性能是StarRocks/DorisDB的4倍(受限于云上的GPU型号)。

3 GPU数据库的未来预测
我们对未来GPU数据库的预测分为如下两个层面:
- GPU数据库这种产品所解决的需求是什么?它究竟能为人类社会带来什么价值?
- GPU数据库在未来的存在形态会如何?它如何接入到已有IT上下游生态中?
本章内容尝试回答上述问题。
3.1巨大的崭新需求空间
人类社会正处于一个巨大的数据科学变革时代,其根本特征是:过去因为硬件设备的算力不足而导致的无法开展的各种价值巨大的数据计算正开始慢慢随着GPU等硬件的发展而开展起来,进而支撑整个社会走向从当前片面单一的数据计算走向一个全面的数据计算时代!这种新需求背后的根本逻辑是大数据的价值挖掘当前本质上只停留在聚集汇总上,尚没有能够做到反哺大众,让每个人都能够获取其它所有人的大数据而带来的价值。如果我们看待过去所有的数据仓库或者大数据平台,其根本特征是制作各种报表或者计算各种业务指标,而这些计算的根本逻辑是大数据的reduction,目的是为领导层或者决策层在汇总层上大概了解数据背后的情况,因而这些系统被称作“决策支持系统”。然而,梅特卡夫定律(Metcalf’s law)指出,网络的价值与联网的用户的平方成正比,因而互联的数据背后所反映的N对N的平方价值没有被计算或者挖掘出来,而是简单停留在当前的N对1的汇总计算上。这是由于CPU的算力不足导致的,而不是因为应用需求的不足而导致的。举例而言,从政府统计报告上看, “只为领导做报表,不为群众谋实惠” 的统计模式正反映了当前数据计算能力和实际惠及每个个体的精准计算或者精准决策需求之间的巨大矛盾。
精准计算或者精准数据分析的几个典型需求只能通过GPU数据库的强大能力来进行。如下所列,通过举例,我们尝试在几个领域把实际的精准数据分析需求和当前由于算力不足导致的勉强现状进行对比。
- 精准定价:当前电商的定价本质上还没有达到精准定价的程度,对于一个要结账的购物车来说:“总价是既定单价的总和”——虽然能做到一点可以根据用户画像进行一定程度上价格调整(俗称大数据杀熟)。与之相反,我们在菜市场买菜时菜贩都能做到组合定价,即根据篮子里面菜品组合进行现场价格浮动。当我们考虑整个电商平台上所有商品所有用户作为要给巨大的网络的话,有巨大的网络价值可以挖掘,从而能够做到对购物篮进行精准定价(亦或精准推荐),从而即优化用户支付又优化电商收益。然而,当前由于数据分析的算力不足以及实时性分析能力不足,精准电商需求仍然不能被满足。实际上,Uber采用GPU数据库的根本原因之一也是进行实时精准定价——本质上这种精准是对每个个体而言的,这和过去单向的信息汇总完全不一样。
- 精准治理:想必每一个在疫情情况下被小区封锁或者受到出行限制的人都体会到政府一刀切治理所带来的痛苦。然而,把所有人的信息精准收集起来尽管可行,把所有人的信息进行汇总计算行成统一性的政策尽管可行,但是:由于巨大的计算量,实现针对每个人的精准政策却非常困难。这种多目标优化问题难以精确求解。然而,具体到每个个人而言,对其本身的精准政策、帮助、规划或者建议才是最有价值的。举例而言,教育领域的一对一辅导本身最要求的就是精准化,统计数字毫无意义。为什么在美国医生和律师收入较其它行业高,其本质原因这些行业的服务本质上是针对具体个人或者具体个案的。随着人类社会走向大数据时代,目前正是从传统的决策需求汇集计算(单向数据流动)向个体需求精准计算(双向数据流动)的转换时代。
- 精准健康:随着现代医学技术的进展,精准健康的需求和可能的实现程度都已经开始走向了现实。想必每一个有体会的家长,在看到药瓶子上写的儿童减半这种吃药指导都会疑问,它为什么不是降低40%或者60%,而是一刀切的不考虑体重年龄的减半。精准健康因为需要对个人而言,所以其需要的数据管理和分析量是前所未有的巨大的。以3D病理结构分析为例,一个典型的2D显微切片可以包含10万乘10万像素,而一个典型的3D病理组织可以包含几百张切片,以及数千万3D生物对象。这些精准结构是构成精准健康的基础,然而这种巨大的数据量以及运算量当前根本无法展开,除非有GPU提供的具体并行计算能力。当前基于统计的医疗指导理念和精准健康医疗之间的差距是人类接下来数十年最重要的数据科学问题。
还有其他诸多方面正在打开一个巨大的市场空间以满足各种不同针对个体的精准方案,例如精准营销、精准推荐、精准交易、精准UI等。这些应用都符合一个共同特点就是在一个涵盖全人类交互的具体网络空间内,存在网络用户或者节点数量平方级的价值,其体现在针对每个具体用户所能获得的精准信息或者决策(insight)。本质上,GPU数据库所面临的市场空间是这种新需求所带来的新市场,我们称之为数据元宇宙平台。保守预测,根据传统数据库市场的1000亿美元,这一市场空间将是万亿美元级别。(有兴趣的读者可以进一步参考计算所徐志伟研究员在2011年发表在美国计算所协会ACM通信上的文章“Computing for the Masses”)。
这种精确到个体的信息决策其实正是目前所广泛应用的GPU数据库系统之所以能够在绝对刚需市场上获得大规模应用的原因。以Kinetica所做的USPS的案例来看,其一项重要需求就是具体到每辆车的时候如何在运营过程中动态决定路线,这种信息决策同统计上的汇总性信息有关联,但本质上代表一种全新的信息流动模式(网络中所有节点的双向信息流动)。这也是为什么传统数据仓库(例如Teradata或者Greenplum)不能支撑应用的一个关键所在,因为它们本质上是为报表这种单向信息流动所设计的。
3.2 GPU数据库的产品形态
3.2.1 硬件趋势
从硬件层次来看,GPU已经在内存带宽和计算性能两个方面大幅度领先CPU。在可预期的未来,除了GPU之外,没有任何其它加速计算设备能够在性能和通用性两个方面达到一个平衡的状态从而真正能够被用于大规模并行数据处理。通用CPU在这一任务上的表现受限于其并行处理核的数量,而GPU能够在限定并行计算模式(SIMT: Single instruction, multiple threads)的情况下大幅度提高内存带宽和计算能力,如下图所示。
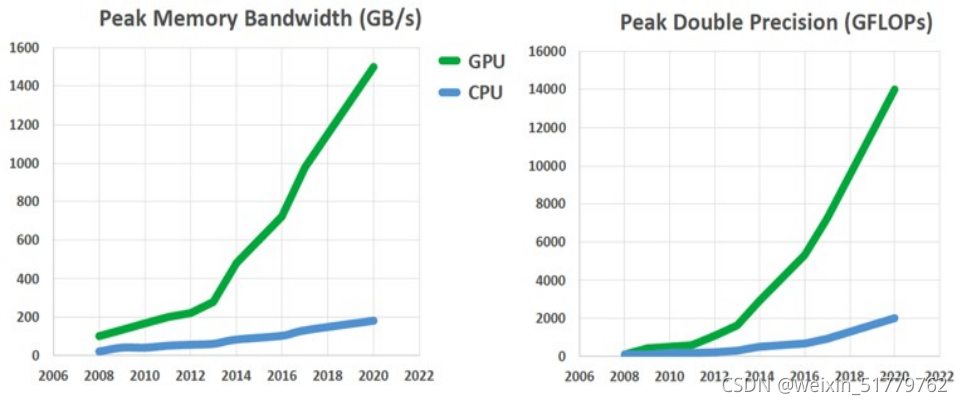
左图:GPU和GPU在绝对内存带宽方面的年度比较曲线;
右图: GPU和CPU在绝对计算能力方面(双精度浮点数运算)方面的年度比较曲线。
无理由相信,这一性能对比趋势在接下来的几年内会被逆转。因此,我们相信GPU数据库系统会随着GPU硬件的强大性能而开始成为很多高性能数据分析领域的首选平台,并开始占据上述精准数据分析蓝图中的各个关键业务产品线。
3.2.2 产品形态
我们预测下一步的GPU数据库系统将会具备如下四个特征,这是我们根据计算机领域的生态发展和应用需求的驱动发展综合判断的结果:
- 瞬时分析(Instant Analytical):所有数据分析都在秒内完成,不管数据规模和分析复杂度;
- 云后不现(Invisible behind Cloud):用户只看见云端标准数据库服务,不知后面有GPU;
- 自我适应(Self-adaptive):无需配置管理运维,数据库自动适应数据特性和业务负载;
- 统一平台(Unified and Versatile):内置各种数据类型支持和分析功能,数据不需出库;
3.2.2.1瞬时分析
GPU数据库的强大计算能力所能给用户带来的极致体验是任何数据分析都可以变成可交互的任务!这种能力意味着每次查询响应必须能够在用户可预期的秒级内完成,否则可交互性只能退化成批处理分析。这两种信息使用模式的一个关键分水岭是Google搜索引擎所带给用户的体验。在整个互联网的内容空间中,在整个人类的知识海洋中,搜索引擎能够交互式的给用户搜索答案,而传统数据库系统无法做到每个查询的交互式响应。因此,将来的GPU数据库系统最关键的特征就是所有查询,无论多复杂,一律都可在秒级内响应。做到这一点的关键诀窍是GPU数据库在云上的自动伸缩特性和大规模并行硬件能力所带来的暴力求解能力。
3.2.2.2云后不现
从上个世纪八十年代到现在,SQL已经被证明是数据库工业中最重要的一个标准接口。随着云计算的兴起,可以预见GPU数据库系统本质上会变成一个硬件透明的标准云上SQL服务。用户只需要在逻辑层定义数据模式、接入各种数据源并进行各种SQL查询分析,丝毫无需考虑背后引擎是否通过CPU、GPU或者其它特定硬件来完成。并且,数据规模的伸缩变化能够被自适应的虚拟机群伸缩能力来匹配,因此用户对GPU数据库背后的硬件即无质也无量的感知。同其它系统类似,GPU数据库系统也会在多云接入等方面实现一种统一可靠的虚拟云服务架构在不同的公有云物理服务上——而这一切对于用户而言只是看见一个具备无限计算和存储能力但数据处理单位价格极具优势的一种标准SQL云服务。
3.2.2.3自我适应
使用数据库系统的各种行业用户一直面临的一大难题是如何快速构建数据库应用以及如何调优数据库性能以满足业务需求,这一痛点即使在企业拥有高级开发队伍以及高级DBA之后依然不能完美解决。任何需要上线一个数据库应用都往往在数据库表索引、存储结构、并发控制算法等庞大的参数空间内设计调整,从而不能快速构建数据库业务,并且后续人工监控调整仍非常关键。然而GPU数据库由于GPU的强大AI能力,使其具备了使用各种强化学习模型所具备的自动索引构建、自动数据源识别、自动并发控制、自动存储结构选择、自动查询优化等各种自动特性,从而使得任何新业务只需简单把数据接入进数据库就可使用,并且随着数据使用的逐渐累积,系统能够自适应优化。这种企业应用现场搭建以及自动运维能力能够给行业用户提供各种前所未有的能力,最主要的是把业务需求在最短时间转换成底层的IT stack,而以往这种转换需要业务需求方、应用软件开发方、数据库开发方以及DBA多方多轮的交互。
3.2.2.4统一平台
将来的GPU数据库会继续沿用当前的统一架构来支撑各种不同的数据类型及相关应用。首先,GPU数据库通过综合利用CPU和GPU能够完美支持混合OLTP/OLAP负载,因此GPU数据库能够在数据产生的第一时间将数据接入,并能够在第一时间对数据进行及时分析。其次,GPU所拥有的强大并行能力使得任何复杂的分析可以在无需对数据进行额外再加工的情况下(例如建立各种索引等辅助数据结构)之际被有效执行,因此从简单聚集到复杂统计分析亦或机器模型分析的各种复杂分析都可以在GPU数据库内完成,而无需把数据导出到其它专门的分析系统;再次,GPU本身是一个独立于CPU的硬件设备,其上的程序功能扩展和其在主板上的插拔扩展不影响CPU上执行的负载服务质量,因此GPU数据库可以被扩展为执行任何可能的特定类型数据分析,例如地理数据;而传统CPU数据库在这一方面必须考虑对CPU上已有负载的影响,因而不能任意扩展分析能力;最后,GPU数据库本身具备强大的数据可视化能力,其大规模并行处理功能可以容易的支撑实时交互性的数据可视化需求。
4 结论
我们预测从现在开始的十年可预期未来内,GPU数据库将成为主流公有云上的一个标准数据库服务。因为硬件趋势的不可逆转性,为保持其核心性价比优势,当前的公有云上的主流数据分析服务,诸如Amazon RedShift, Google Bigquery或者Snowflake,将会逐渐增大其内部引擎对GPU设备的依赖——尽管这种依赖可能会通过对中小型GPU数据库厂商的收购来完成;这些标准服务的存在所带来的大规模计算能力将最终使得精准数据分析的各种场景得以实现,从而真正达到数据驱动社会的一种信息社会模式。
附录
Moore’s law: The number of transistors in a dense integrated circuit (IC) doubles about every two years.
Dennard Scaling: As transistors get smaller, their power density stays constant, so that the power use stays in proportion with area; both voltage and current scale (downward) with length.
Bell’s law of computer classes: Roughly every decade a new, lower priced computer class forms based on a new programming platform, network, and interface resulting in new usage and the establishment of a new industry.
Metcalfe's law: The value of a network is proportional to the square of the number of connected users of the system (n2).