大家好,我是辣条。
上回我爬了班花的空间发现她喜欢的人是王俊凯,室友算是彻底死了心,跟我大醉一场后郁郁不振至今,作为他的死党(爸比)我很难受(开心),决心让他重新振作。于是毅然爬了一个网站分享给他,才有了今天这篇文章,分享给大家纯粹是技术交流!请大家备好纸巾...呸呸,请大家备好笔纸,今天的学习开始啦!
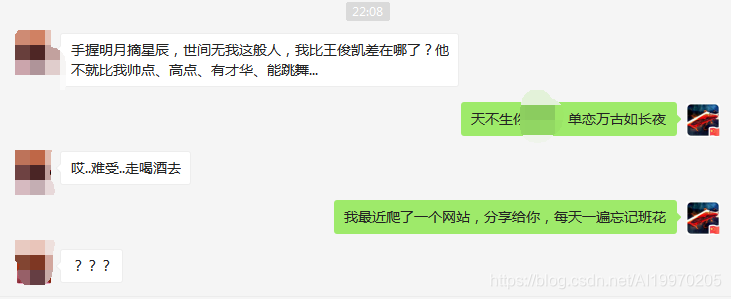
效果展示

爬取目标
网址:(网站地址不提供了,我求生欲很强了,审核大大手下留情)

【兄弟萌,不是我整活恶心大家,而是不打码过不了,我怀着赤诚之心跟大家交流技术!】
工具使用
开发环境:win10、python3.7
开发工具:pycharm、Chrome
工具包:requests,lxml,threading
项目思路解析
首页信息为动态加载的数据 数据为动态加载的网页源代码
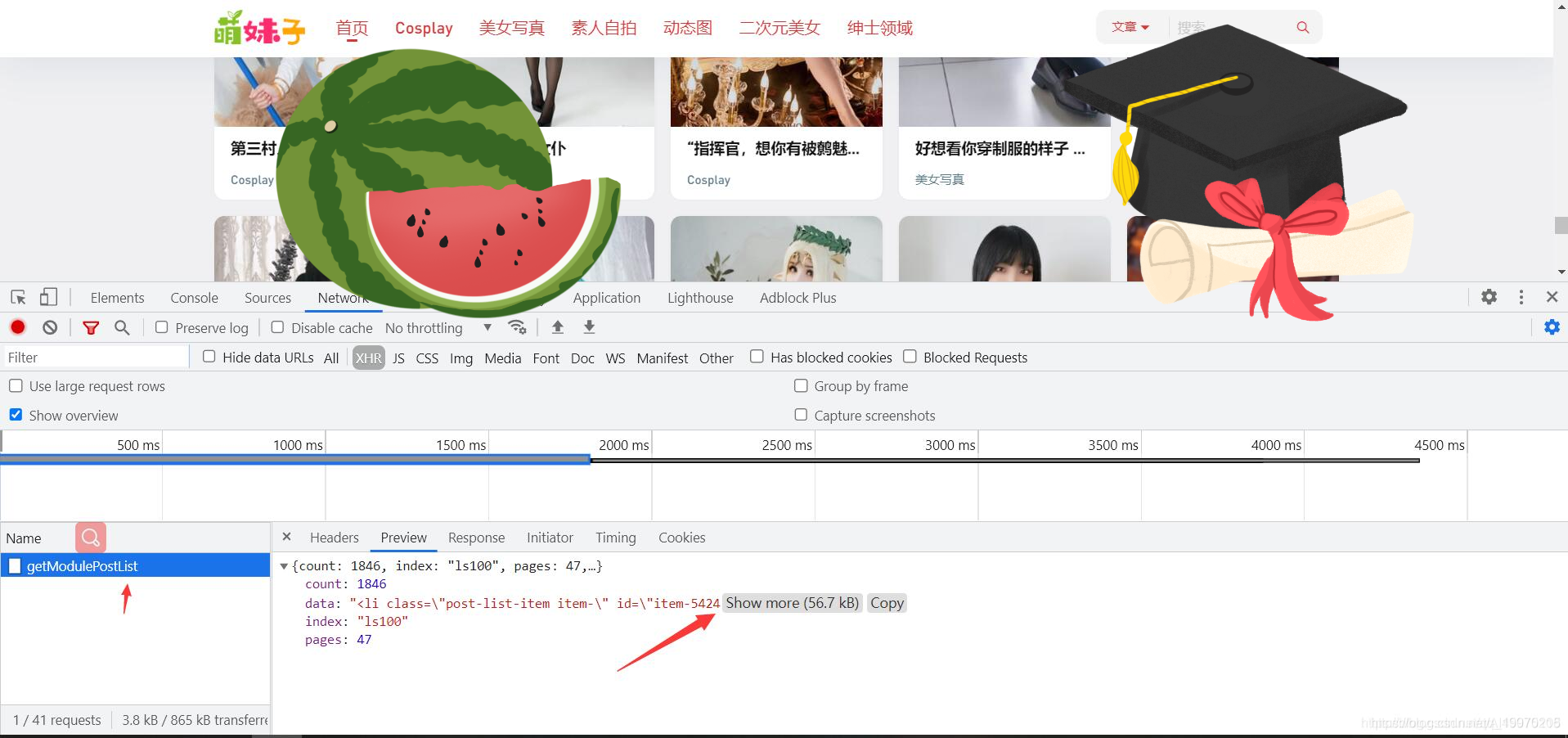
请求为post请求 传递的参数一个是页面的分类 ,一个是你需要的页数信息

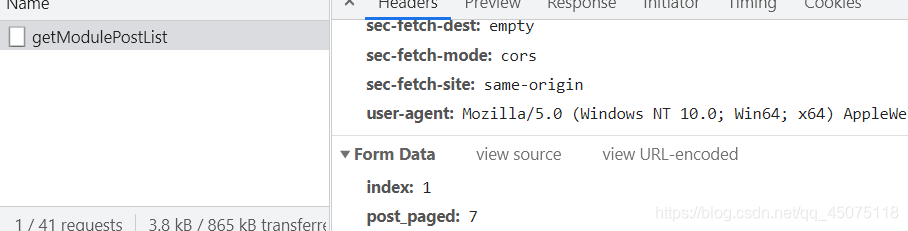
发送请求获取到json数据里的网页源代码 在通过xpath的方式提取出图片的详情页面地址 以及图片对应的名字

response = requests.post(url, headers=headers, data=data).json()
print(response)
html_data = etree.HTML(response['data'])
href_list = html_data.xpath('//div[@class="post-module-thumb"]//a/@href')
name_list = html_data.xpath('//div[@class="post-module-thumb"]//img/@alt')请求详情页面的地址获取详细数据信息  提取到对应图片地址 保存对应图片数据
提取到对应图片地址 保存对应图片数据
简易源码分享
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @File : 萌妹子.py
import os
import requests
from lxml import etree
import threading
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
def get_img(href_list, name_list):
for href, name in zip(href_list, name_list):
res = requests.get(href, headers=headers)
# print(res.text)
html = etree.HTML(res.text)
img_url_list = html.xpath('//div[@class="entry-content"]/p/img/@src')
num = 0
for img_url in img_url_list:
result = requests.get(img_url).content
path = '图片'
if not os.path.exists(path):
os.mkdir(path)
f = open(path + '/' + name.replace(':', '').replace(':', '') + str(num) + '.jpg', 'wb')
f.write(result)
num += 1
print('正在下载{}第{}张图片'.format(name, num))
def get_data(url, data):
response = requests.post(url, headers=headers, data=data).json()
print(response)
html_data = etree.HTML(response['data'])
href_list = html_data.xpath('//div[@class="post-module-thumb"]//a/@href')
name_list = html_data.xpath('//div[@class="post-module-thumb"]//img/@alt')
get_img(href_list, name_list)
if __name__ == '__main__':
for i in range(1, 4):
data = {
'index': '1',
'post_paged': str(i)
}
url = '网站地址不提供,想用来技术学习可以私信我拿'
t1 = threading.Thread(target=get_data, args=(url, data))
t1.start()最好的爱情是双向奔赴,祝大家有情人终成眷属,单身狗们早日脱单!
PS:欢迎大家在评论中交流技术,辣条意在让编程变的更有趣学起来更轻松,不低俗不媚俗不违法违纪,学习新思想,争做新青年