数据库(Oracle)
开发组成 :前端 后端 数据库
数据库分类
关系型数据库(把复杂的数据结构归结为简单的二元关系即二维表格形式,对数据的操作几乎全部建立在一个或多个
关系表格上,通过对这些关联的表格分类、合并、连接、或选取来实现数据库的管理。
传统实例:Oracle 、Mysql 、Microsoft SQL Server…
非关系型数据库(NoSQL泛指非关系型数据库): 传统关系型数据库在应付web2.0网站,特别是超大规模和高并发SNS类型
的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库由于其本身特点得到迅速发展
。Nosql数据库在特定的场景下可以发挥出难以想象的高效率和高性能,它是作为对传统关系型数据库的一个有效的补充
分类:(1)键值(key-value)存储数据库 Redis
(2)列存储(Column-oriented)数据库
(3)面向文档数据库 MongoDB CouchDB
(4)图形数据库 Neo4j InforGird
(5)时序数据库InfluxDB Prometheus OpenTSDB(底层基于HBase)
··· 数据库发展阶段
人工管理阶段
文件系统阶段
数据库系统阶段
数据库的主要特点有:
1. 实现数据共享
数据共享包含所有用户可同时存取数据库中的数据,也包括用户可以用各种方式通过接口使用数
据库,并提供数据共享。
2. 减少数据的冗余度
同文件系统相比,由于数据库实现了数据共享,从而避免了用户各自建立应用文件。减少了大量
重复数据,减少了数据冗余,维护了数据的一致性。
3. 数据的独立性
数据的独立性包括数据库中数据库的逻辑结构和应用程序相互独立,也包括数据物理结构的变化
不影响数据的逻辑结构。
4. 数据实现集中控制
文件管理方式中,数据处于一种分散的状态,不同的用户或同一用户在不同处理中其文件之间毫
无关系。利用数据库可对数据进行集中控制和管理,并通过数据模型表示各种数据的组织以及数
据间的联系。
5. 数据一致性和可维护性,以确保数据的安全性和可靠性
安全性控制:以防止数据丢失、错误更新和越权使用;
完整性控制:保证数据的正确性、有效性和相容性;
并发控制:使在同一时间周期内,允许对数据实现多路存取,又能防止用户之间的不正常
交互作用;
故障的发现和恢复:由数据库管理系统提供一套方法,可及时发现故障和修复故障;
6. 故障恢复
由数据库管理系统提供一套方法,可及时发现故障和修复故障,从而防止数据被破坏。数据库系
统能尽快恢复数据库系统运行时出现的故障,可能是物理上或是逻辑上的错误。比如对系统的误
操作造成的数据错误等。
3.数据库对象
数据库对象是数据库的组成部分,常常用 CREATE 命令进行创建,可以使用 ALTER 命令修改,用 DROP执行删除操作。常见的数据库对象有:
用户(user)
表(table)
视图(view)
索引(index)
触发器(trigger)
存储过程(procedure)
同义词(synonym)
序列(sequence)
在学习的过程中,所接触到的内容,都与这些oralce数据库对象有关系
4.sql
SQL(Structured Query Language),结构化查询语言,是专门操作关系型数据库的一种语言
第一代编程语言,机器语言,是面向机器的,通过二进制代码对其计算机操作
第二代编程语言, 汇编语言,使用指令对应的符号,来代替二进制代码
第三代编程语言,高级开发语言 ,例如C、C++ Java等,语言更加简单,操作更方便
第四代编程语言,只告诉计算机需要做什么,不需要告诉计算机怎么做,更加接近自然语言
例如:select name from tbl_student;
这时候只是告诉计算机,我们需要查看表中的name字段的值,但是没说该怎么做
sql语句的分类:
DQL (Data Query Language),数据查询语言
用于检索数据库中的数据,主要是 SELECT 语句
DML (Data Manipulation Language),数据操纵语言
用于改变数据库中的数据,主要是 INSERT , UPDATE , DELETE 语句
DDL(Data Define Langage),数据定义语言
用来建立、修改、删除数据库对象,主要是 CREATE 、 ALTER 、 DROP 、 TRUNCATE 语句
TCL (Transaction Control Language),事务控制语言
用于维护数据的一致性,主要是 COMMIT , ROLLBACK , SAVEPOINT 语句
DCL(Data Control Language),数据控制功能
用于执行权限授予和权限收回操作,主要是 GRANT , REVOKE 语句
注意,DML语句需要事务的支持(产生事务),DDL语句会自动提交事务
sql、sqlplus、pl/sql的区别:
sql,结构化的查询语句,操作关系型数据库的语言
sqlplus,oracle数据库软件自带工具,可以接收用户输入的sql语句,然后将sql执行结果显示出来
pl/sql,程序化的sql语句,在sql语句的基础上加入一定的逻辑操作,如 if for 等
不同的关系型数据库中,sql语句的基本语法都是相同的,但是在特殊的情况下,也会有稍许差异
select
1 基础
select语句,可以通过列名,把一行行的数据给查询出来,语法为:
select [distinct] *{col_name1,col_name2,..} from tb_name;
注意1,语法中出现的中括号[],表示该部分可有可无
注意2,*号表示所有列
注意3,col_name1,col_name2代表列名,如果有多个可以逗号分开
例如,查看所有员工的id,名字(last_name)和薪资(salary)
select id,last_name,salary
from s_emp;
运算
例如,查看每个员工的员工id,名字和年薪
select id,last_name,salary*12
from s_emp;
注意,select语句永远不会对原始数据进行修改;
例如,查看每个员工的员工id,名字和月薪涨100以后的年薪
select id,last_name,(salary+100)*12
from s_emp;
别名
语法:
select old_column [as] new_column_name from tb_name;
注意,中括号里面的as是可选的
例如,查看员工的员工id,名字和年薪,年薪列名为annual
select id,last_name,salary*12 as annual
from s_emp;
或者
select id,last_name,salary*12 annual
from s_emp;
拼接
语法:
select col_name||'spe_char'||col_name from tb_name
例如,查看员工的员工id,全名
select id,first_name||last_name
from s_emp;
例如,查看员工的员工id,全名和职位名称,全名和职位名称合并成一列显示,且格式为:姓名,职位
名称
select id,first_name||' '||last_name||','||title as name
from s_emp;
nvl
使用nvl函数可以将null进行替换
语法:
select nvl(col_name,change_value) from tb_name;
例如,查看所有员工的员工id,名字和提成,如果提成为空,显示成0
select id,last_name,nvl(commission_pct,0) commission_pct
from s_emp;
distinct
该关键字可以将重复数据去除。
语法:
select distinct col_name,col_name...
from tb_name;
例如,下面sql的语法错误!
select id,distinct title
from s_emp;
如果 distinct 关键词后面如果出现多列,表示多列联合去重,即多列的值都相同的时候才会认为是重
复的记录。
//test表中的数据为:
id id2
1 2
1 3
2 4
3 4
3 4
select distinct id,id2
from test;
//查询结果为:
id id2
1 2
1 3
2 4
3 4
例如,查看所有员工的职位名称和部门id,同职位同部门的只显示一次
select distinct dept_id,title
from s_emp;
format
使用 format 可以将查询结果显示的宽度进行调整。
例如
select id,last_name
from s_emp;
运行结果为:
ID LAST_NAME
---------- --------------------------------------------------
1 Velasquez
2 Ngao
3 Nagayama
4 Quick-To-See
5 Ropeburn
6 Urguhart
7 Menchu
使用 format 调整last_name列所占的宽度,其实就是“-”的个数
例如
//表示last_name列的下方有15个“-”
column last_name format a15
//或者简写为
col last_name for a15; select id,last_name
from s_emp;
运行结果:
ID LAST_NAME
---------- ---------------
1 Velasquez
2 Ngao
3 Nagayama
4 Quick-To-See
5 Ropeburn
6 Urguhart
7 Menchu ......
可以清除设置的格式:
clear column //或者 clear co
注意,format只能设置字符类型的字段列
sqlplus
使用 sqlplus 登录之后,可以使用buff(缓存)来存储/执行/修改上一条运行的sql语句 。
buff中只能存储一条sql语句,但是这条sql语句可能有很多行
每次放入新的sql语句,会把之前的覆盖掉
每次执行sql语句,都会把这个sql语句放到buff里面
sqlplus 相关的命令:
l 查看缓存中的sql语句
a 在[定位]的那一行后面追加新的内容
i 在[定位]的那一行下面插入新的一行
c 替换[定位]的那一行中的某些字符串 ,格式为:c/老的字符串/新的字符串
del 删除[定位]的那一行内容
n 后面加内容可以重写这一行
$ 后面跟一个终端命令,例如$cls清屏,linux中使用!
/ 执行缓存sql命令
注意,使用 l 命令查看buff中的sql后,可以直接输入行数,然后回车,这就是定位到了这一行
如果要清空buff中的sql:
clear buffer
其他的一些命令:
save test.sql //buff中的sql语句保存在test.sql文件中
get test.sql //把test.sql中的内容在加载到buff中,但是没有运行
start test.sql //把test.sql中的内容在加载到buff中并且执行
@test.sql //把test.sql中的内容在加载到buff中并且执行
edit file_name //使用系统默认编辑器去编辑文件
spool 命令:可以记录操作的过程
spool file_name //将接下来的sql语句以及sql的运行结果保存到文件中
sql1 result1 sql2 result2 ... spool off //关闭spool功能
排序
查询数据的时候进行排序,就是根据某个字段的值,按照升序或者降序的情况将记录显示出来
语法:
select col_name,...
from tb_name order by col_name [asc|desc]
注意1,order by语句,只对查询记录显示调整,并不改变查询结果,所以执行权最低,最后执行
注意2,排序的默认值是asc:表示升序,desc:表示降序
注意3,如果有多个列排序,后面的列排序的前提是前面的列排好序以后有重复(相同)的值。
例如,
//假设test表中有以下数据
id id2
1 2
2 3
3 4
4 1
4 2
select id,id2
from test
order by id asc,id2 desc;
//查询结果:
id id2
1 2
2 3
3 4
4 2
4 1
注意,先升序排第一列,如果第一列有重复的值,再降序排第二列,以此类推
注意,上面的asc可以省去不写,因为是默认值
例如,查看员工的id,名字和薪资,按照薪资的降序排序显示,工资相同就按名字升序排
select id,last_name,salary
from s_emp
order by salary desc,last_name;
条件查询
语法:
select col_name,...
from tb_name
where col_name 比较操作表达式
注意1,限制查询条件,使用where子句
注意2,条件可以多个,使用逻辑操作符或者小括号进行条件的逻辑整合
注意3,where子句的优先级别最高
注意4,比较操作表达式由操作符和值组成
逻辑比较操作符= > < >= <= !=
不等于操作符,以下三个都表示不等于的意思,经常用的是 !=
!= <> ^=
例如,查看员工工资小于1000的员工id和名字
select id,last_name,salary
from s_emp
where salary < 1000;
between and 操作符,表示在俩个值之间
例如,查看员工工资在700 到 1500之间的员工id和名字
select id,last_name,salary
from s_emp
where salary between 700 and 1500;
in() ,表示值在一个指定的列表中
例如,查看员工号1,3,5,7,9员工的工资
select id,last_name,salary
from s_emp
where id in (1,3,5,7,9);
like ,模糊查询,在值不精确的时候使用
% ,通配0到多个字符
_ ,通配一个字符,并且是一定要有一个字符
\ ,转义字符,需要使用 escape 关键字指定,转义字符只能转义后面的一个字符
例如,查看员工名字以C字母开头的员工的id,工资
select id,last_name,salary
from s_emp
where last_name like 'C%';
注意,数据库中的字符串,需要使用单引号括起来
例如,查看员工名字长度不小于5,且第四个字母为n字母的员工id和工资
select id,last_name,salary
from s_emp where last_name like '___n_%';
例如,查看员工名字中包换一个_的员工id和工资
select id,last_name,salary
from s_emp where last_name like '%\_%' escape '\';
is null ,判断值为null的时候使用,null值的判断不能使用等号
例如,查看员工提成为为空的员工的id和名字
select id,last_name,commission_pct
from s_emp
where commission_pct is null;
注意,类似的,还有 is not null
and 、 or ,逻辑操作符,当条件有多个的时候可以使用
注意,and比or的优先级要高
例如,查看员工部门id为41且职位名称为Stock Clerk(存库管理员)的员工id和名字
select id,last_name,dept_id,title
from s_emp
where dept_id = 41 and title = 'Stock Clerk';
例如,查看员工部门为41 或者 44号部门,且工资大于1000的员工id和名字
select id,last_name,dept_id,title
from s_emp
where salary > 1000 and (dept_id = 41 ordept_id = 44 );
例如,查看员工部门为41且工资大于1000,或者44号部门的员工id和名字
select id,last_name,dept_id,title
from s_emp
where salary > 1000 and dept_id = 41 ordept_id = 44;
注意,以上俩个sql语句,执行的结果是不一样的,它们的区别就是第一个sql在条件中多了个小括
号
查询s_emp表中最大工资数,并且显示出这个最大工资的员工的名字
select max(s1.salary),s2.last_name
from s_emp s1,s_emp s2
group by s2.salary,s2.last_name
having max(s1.salary) =s2.salary;
第一步,查出最大工资数
select max(salary)
from s_emp;
第二步,加上last_name的显示
select last_name,max(salary)
from s_emp;
第三步,select后面出现组函数,没有被组函数修饰的列放到group by后面,
select last_name,max(salary)
from s_emp
group by last_name;
注意,这时候会发现查询结果并不是想要结果,因为这是按名字分组,每个人的名字都不同,那
么就是每一个人就是一个小组。其实表里有俩个人的名字都叫Patel,所以本来25条数据,这时候
会查出24条
第四步,修改为多表查询(起别名),从s1表中查询出最大的工资数是多少,然后再和s2表连接起来,选
出s2表中这个最大工资数的员工名字
select s2.last_name,max(s1.salary)
from s_emp s1,s_emp s2
where s2.salary = max(s1.salary)
group by s2.last_name;
注意,这时候会报错,因为where后面不能出现组函数
第五步,where后面不能出现组函数,所以改为having
select s2.last_name,max(s1.salary)
from s_emp s1,s_emp s2
group by s2.last_name,s2.salary
having s2.salary = max(s1.salary);
//运行结果: LAST_NAME MAX(S1.SALARY)
--------------------- --------------
Velasquez 2500
例如,查询s_emp表每个部门的最大工资数,并且显示出这个最大工资的员工的名字,以及该部门的名
字、该部门所属区域,并且使用部门编号进行排序
select
max(s1.salary),s2.last_name,s2.dept_id,sr.name,sd.name
from
s_emp s1,s_emp s2,s_dept sd,s_region sr
where
s1.dept_id =s2.dept_id
and
s1.dept_id=sd.id
and
sd.region_id = sr.id
group by
s2.dept_id,s2.last_name,s2.salary,sr.name,sd.name
having
max(s1.salary) =s2.salary
order by
s2.dept_id;
oracle(2)函数、多表查询、结果集、伪列
常用函数分类(三类)
1.单行函数
- 字符函数
- 日期函数
- 数字函数
2.转换函数
3.聚合函数
常用函数用法
单行函数,也可以称为单值函数,每操作一行数据(某个字段值),都会返回一个结果
例如,查询id小于5的员工信息(id、last_name、salary)
select id,last_name,salary
from s_emp
where id<5;
//运行结果:ID LAST_NAME SALARY
---------- --------------- ----------
1 Velasquez 2500
2 Ngao 1450
3 Nagayama 1400
4 Quick-To-See 1450
例如,使用单行函数,将上面的结果中每一个last_name转换为大写
select id,upper(last_name) as last_name,salary
from s_emp
where id<5;
//运行结果:
ID LAST_NAME SALARY
---------- --------------- ----------
1 VELASQUEZ 2500
2 NGAO 1450
3 NAGAYAMA 1400
4 QUICK-TO-SEE 1450
可以看到,单行函数,对每一行中的last_name字段值都进行了操作,并返回了转换结果
- 字符函数 (常用)
- ASCII(X) 返回字符X的ASCII码
- CONCAT(X,Y) 连接字符串X和Y
- INSTR(X,STR[,START][,N) 从X中查找str,可以指定从start开始,也可以指定从n开始
- LENGTH(X) 返回X的长度
- LOWER(X) X转换成小写
- UPPER(X) X转换成大写
- INITCAP(X) X首字母转换为大写,其他字母小写
- LTRIM(X[,TRIM_STR]) 把X的左边截去trim_str字符串,缺省截去空格
- RTRIM(X[,TRIM_STR]) 把X的右边截去trim_str字符串,缺省截去空格
- TRIM([TRIM_STR FROM]X) 把X的两边截去trim_str字符串,缺省截去空格
- REPLACE(X,old,new) 在X中查找old,并替换成new
- SUBSTR(X,start[,length]) 返回X的字串,从start处开始,截取length个字符,缺省length,默认到结尾
例子:INSTR(X,STR[,START][,N) ,从X中查找str,可以指定从start开始,也可以指定从n开始
select instr('Hello World','o') as result
from dual;
//运行结果:
RESULT
----------
5
select instr('Hello World','o',6) as result
from dual;
//从前往后查找,从下标为6开始
//运行结果:
RESULT
----------
8
select instr('Hello World','o',-1) as result
from dual;
//从后往前查找,从最后一个开始
//运行结果:
RESULT
----------
8
-
数字函数(专门操作数字的函数,常用)
- INITCAP(X) X首字母转换为大写,其他字母小写
- LTRIM(X[,TRIM_STR]) 把X的左边截去trim_str字符串,缺省截去空格
- RTRIM(X[,TRIM_STR]) 把X的右边截去trim_str字符串,缺省截去空格
- TRIM([TRIM_STR FROM]X) 把X的两边截去trim_str字符串,缺省截去空格
- REPLACE(X,old,new) 在X中查找old,并替换成new
- SUBSTR(X,start[,length]) 返回X的字串,从start处开始,截取length个字符,缺省length,默认到结尾
例子:INSTR(X,STR[,START][,N) ,从X中查找str,可以指定从start开始,也可以指定从n开始
select instr('Hello World','o') as result
from dual;
//运行结果:
RESULT
----------
5
select instr('Hello World','o',6) as result
from dual;
//从前往后查找,从下标为6开始
//运行结果:
RESULT
----------
8
select instr('Hello World','o',-1) as result
from dual;
//从后往前查找,从最后一个开始
//运行结果:
RESULT
----------
8
- 数字函数(专门操作数字的函数,常用)

日期函数
-
sysdate ,是Oracle中用来表示当前时间的关键字,并且可以使用它来参与时间运算。
例如,
//显示当前时间 select sysdate from dual;例如,
//显示时间:明天的这个时候 select sysdate + 1 from dual; //显示时间:昨天的这个时候 select sysdate - 1 from dual; //显示时间:1小时之后的这个日期 select sysdate + 1/24 from dual;注意, sysdate 参与时间的加减操作的时候,单位是天
特别注意,oracle中不同的会话环境中,日期数据默认的格式也不同
中文
SQL> alter session set nls_language='simplified chinese';
会话已更改。
SQL> select sysdate
from dual;
SYSDATE
--------------
02-9月 -20
SQL>
注意,观察中文环境的会话中的默认日期格式的特点。
英文
SQL> alter session set nls_language=english;
Session altered.
SQL> select sysdate
from dual;
SYSDATE
------------
02-SEP-20
SQL>
**常见的日期函数**
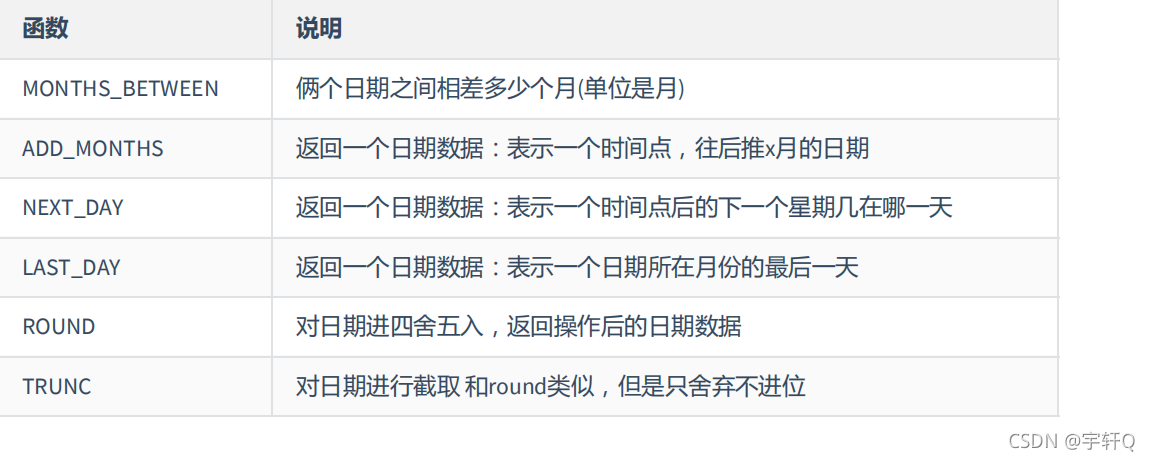
months_between
例如,30天之后和现在相差多少个月
select months_between(sysdate+30,sysdate) as result
from dual;
//运行结果:
RESULT
----------
1
add_months
例如,指定日期,往后推2个月
alter session set nls_language='simplified chinese';
select add_months('01-10月-2020',2) as result
from dual;
//运行结果:
RESULT
--------------
01-12月-20
alter session set nls_language=english;
select add_months('01-OCT-2020',2) as result
from dual;
//运行结果:
RESULT
------------
01-DEC-20
注意,这个数字也可以是负数,表示之前多少月
2.转换函数
转换函数,可以将一个类型的数据,转换为另一种类型的数据。
转换函数主要有三种:
- TO_CHAR ,把一个数字或日期数据转换为字符
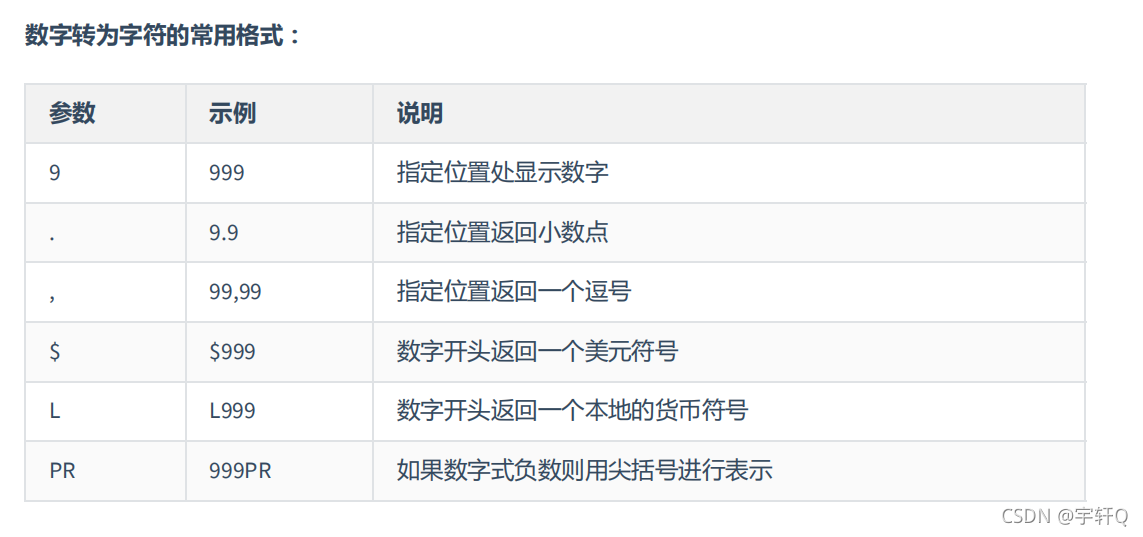
select to_char(salary,’$999,999.00’) as result
from s_emp;
//运行结果:
RESULT
$2,500.00
$1,450.00
$1,400.00
$1,450.00
$1,550.00
…
select to_char(salary,‘L999,999.00’) as result
from s_emp;
//运行结果:
RESULT
¥2,500.00
¥1,450.00
¥1,400.00
¥1,450.00
¥1,550.00
…
select to_char(-10,‘999PR’) as result
from dual;
//运行结果:
RESULT
<10>
日期转为字符的常用格式:
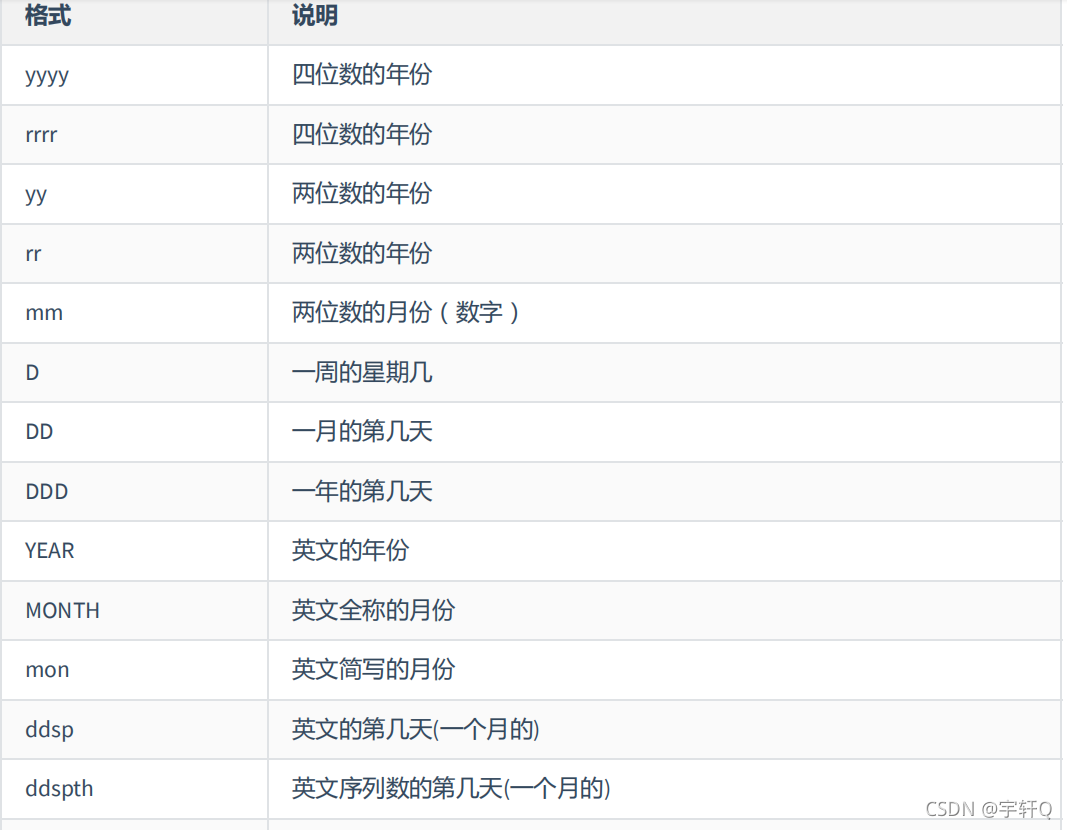
例如
select to_char(sysdate,'yyyy mm MONTH mon MON D DD DDD DAY DY')
from dual;
select to_char(sysdate,'dd-mm-yy')
from dual;
select to_char(sysdate,'yy-mm-dd')
from dual;
select to_char(sysdate,'yy-mm-dd hh24:mi:ss')
from dual;
select to_char(sysdate,'yy-mm-dd hh:mi:ss AM')
from dual;
2.TO_NUMBER ,把字符转换为数字
例如,
select to_number('1000') //不能写abc这种字符,不能转换为数字,会报错
from dual;
-
TO_DATE ,把字符转换为日期
select to_date('10-12-2022','dd-mm-yyyy') as result from dual; alter session set nls_language='simplified chinese'; select to_date('25-5月-22','dd-month-yy') as result from dual;
聚合函数,也可以称为多行函数、分组函数、组函数,它可以操作多行数据,并返回一个结果,一般会
结合着group分组来使用,当然也可以单独使用,那么默认全部数据就是一个小组。
例如,查询id小于5的所有员工的平均工资
select avg(salary)
from s_emp
where id<5;
//运行结果:
AVG(SALARY)
\-----------
1700
例如,查询每个部分的员工人数、以及该部门的平均工资,并且按照平均工资的降序排序
select dept_id,count(*),avg(salary) as avgSalary
from s_emp
group by dept_id
order by avgSalary desc;
//运行结果:
DEPT_ID COUNT(*) AVGSALARY
---------- ---------- ----------
50 2 2025
33 1 1515
32 1 1490
10 1 1450
35 1 1450
31 2 1400
41 4 1247.5
34 2 1160
45 3 1089
42 3 1081.66667
44 2 1050
DEPT_ID COUNT(1) AVGSALARY
---------- ---------- ----------
43 3 900
2.6 函数嵌套
以上介绍的常用函数,在数据类型正确的情况下,是可以嵌套使用的。
例如,先把’hello’和’world’连接起来,再转换为全部字母大写,然后再从第4个字符开始,连着截取4个字符
select substr(upper(concat('hello','world')),4,4) as result
from dual;
注意,函数f1的返回类型,必须是函数f2的参数类型,那么它们之间才可以嵌套
哑表
Oracle中,有一张特殊的表:dual
dual被称之为哑表,它是一个单行单列的虚拟表,是Oracle内部自动创建的,这个表只有1列:DUMMY,
数据类型为VERCHAR2(1),dual表中只有一个数据’X’,Oracle有内部逻辑保证dual表中永远只有一条数
据。
在实际使用中,Dual表主要用来选择系统变量或求一个表达式的值,因为要使用dual来构造完成的查询
语法
例如,查询表达式1+1的结果
select 1+1
from dual;
//运行结果:
1+1
----------
2
注意,按照sql语句的要求,没有表就没法查询,而表达式1+1,不属于任何表,那么就有了哑表
dual的概念了
3 多表查询
多表查询,又称表联合查询,即一条sql语句涉及到的表有多张,表中的数据通过特定的连接,进行联合显示
3.1 笛卡尔积
在数学中,两个集合X和Y的笛卡尓积(Cartesian product),又称直积,表示为X × Y
例如,假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b,
2)}。
在数据库中,如果直接查询俩张表,那么其查询结果就会产生笛卡尔积。
例如,
select count(*)
from s_emp;
select count(*)
from s_dept;
select count(*)
from s_emp,s_dept;
注意,s_emp表中25条数据,s_dept表中12条数据,查询俩张表,数据俩俩组合,会得到300条数据
其实,s_emp表中的每一条数据,和s_dept表中的每一条数据进行俩俩组合,这里面大多数的数据是没
有意义的,为了这种避免笛卡尔积的产生,在多表查询的时候,可以使用连接查询来解决这个问题。
连接查询又可以大致分为:
-
等值连接
利用一张表中某列的值,和另一张表中某列的值相等的关系,把俩张表连接起来,满足条件的数据才会组合
例如,查询员工的名字、部门编号、部门名字
select last_name,dept_id,s_dept.id,name from s_emp,s_dept where s_emp.dept_id=s_dept.id; -
不等值连接
-
外连接
左外连接
右外连接
全连接
-
自连接
嵌套查询
查询工资 大于Simth的
select salary,last_name
from s_emp
where salary>(
select salary
from s_emp
where last_name='Smith'
);
例如,查询平均工资比 41号部门的平均工资 高 的部门中员工的信息
第一步,查询41号部门的平均工资
select avg(salary)
from s_emp
where dept_id=41;
//运行结果: AVG(SALARY)
-----------
1247.5
第二步,查询平均工资比1247.5高的部门编号
select dept_id
from s_emp
group by dept_id
having avg(salary)>1247.5;
//运行结果: DEPT_ID
----------
313235503310 已选择6行。
第三步,查询平均工资比1247.5高的部门中员工信息
select last_name,salary,dept_id
from s_emp
where dept_id in(10,31,32,33,35,50);
第四步,把in条件后的数据进行替换
select last_name,salary,dept_id
from s_emp
where dept_id in(
select dept_id
from s_emp
group by dept_id
having avg(salary)>1247.5
);
第五步,把1247.5进行替换
select last_name,salary,dept_id
from s_emp
where dept_id in(
select dept_id
from s_emp
group by dept_id
having avg(salary)>(
select avg(salary)
from s_emp
where dept_id=41 )
);
分页查询
伪列
select t.id,t.last_name,t.dept_id
from (
select rownum rn,id,last_name,dept_id
from s_emp
where rownum<=10
) t
where t.rn>=6;