先说图像/视频处理(计算机视觉的底层,不低级)
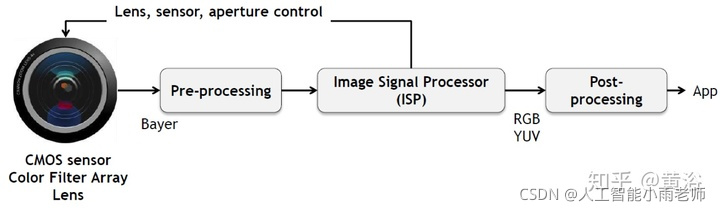
图像处理,还有视频处理,曾经是很多工业产品的基础,现在电视,手机还有相机/摄像头等等都离不开,是技术慢慢成熟了(传统方法),经验变得比较重要,而且芯片集成度越来越高,基本上再去研究的人就少了。经典的ISP,A3,都是现成的,当然做不好的也很难和别人竞争,成本都降不下来。这是一个典型成像处理的流程图:
我整理了一份关于pytorch、python基础,图像处理opencv\自然语言处理、机器学习、数学基础等资源库,想学习人工智能或者转行到高薪资行业的,大学生都非常实用,无任何套路免费提供,,加我裙:361598961
也可以领取的内部资源,人工智能题库,大厂面试题 学习大纲 自学课程大纲还有200G人工智能资料大礼包免费送哦~
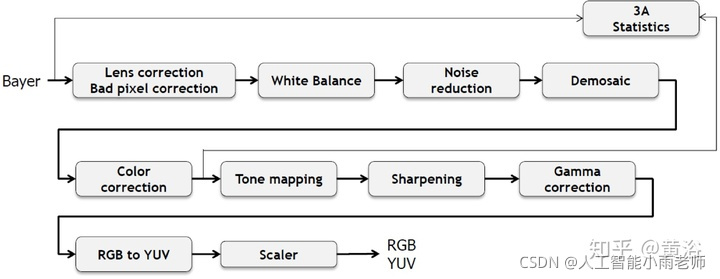
经典的ISP流程图如下:
图像处理,根本上讲是基于一定假设条件下的信号重建。这个重建不是我们说的3-D重建,是指恢复信号的原始信息,比如去噪声,内插。这本身是一个逆问题,所以没有约束或者假设条件是无解的,比如去噪最常见的假设就是高斯噪声,内插实际是恢复高频信号,可以假设边缘连续性和灰度相关性,著名的TV(total variation)等等。以前最成功的方法基本是信号处理,机器学习也有过,信号处理的约束条件变成了贝叶斯规则的先验知识,比如sparse coding/dictionary learning,MRF/CRF之类,现在从传统机器学习方法过渡到深度学习也正常吧。
1 去噪/去雾/去模糊/去鬼影;
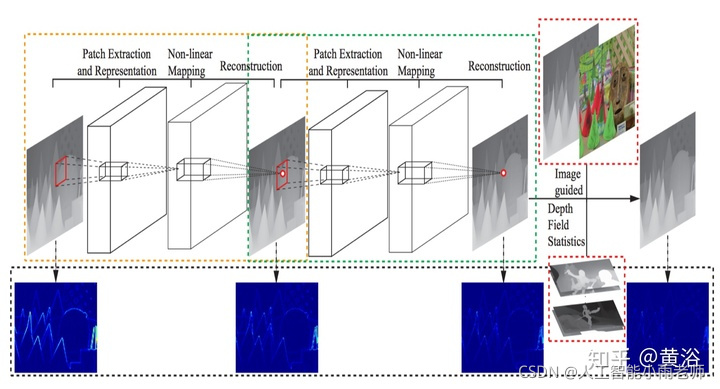
先给出一个encoder-decoder network的AR-CNN模型(AR=Artifact Reduction):
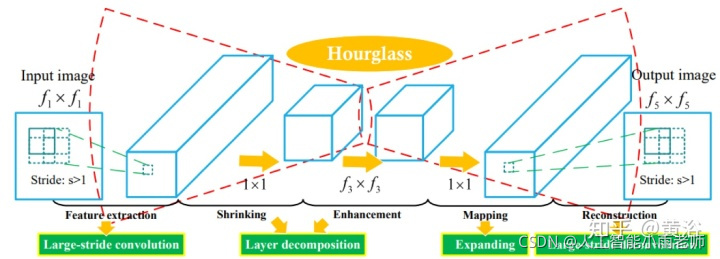
这是一个图像处理通用型的模型框架:
2 增强/超分辨率(SR);
Bilateral filter是很有名的图像滤波器,这里先给出一个受此启发的CNN模型做图像增强的例子:
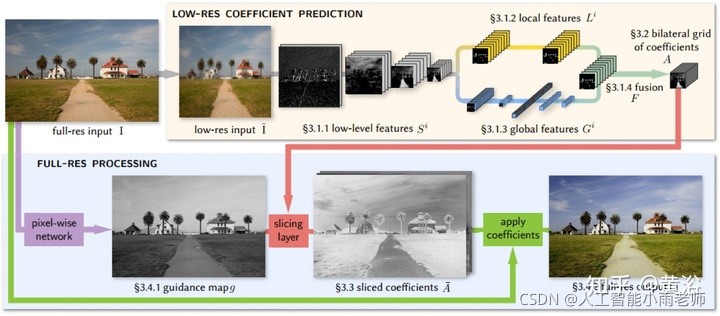
前面说过内插的目的是恢复失去的高频信息,这里一个做SR的模型就是在学习图像的高频分量:
3 修补/恢复/着色;
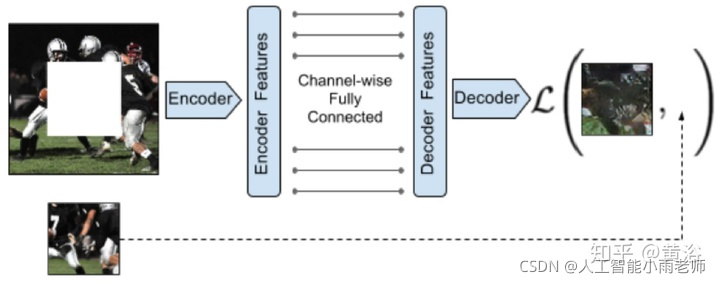
用于修补的基于GAN思想的Encoder-Decoder Network模型:
用于灰度图像着色(8比特的灰度空间扩展到24比特的RGB空间)的模型框架:

还有计算机视觉的预处理(2-D)
计算机视觉需要图像预处理,比如特征提取,包括特征点,边缘和轮廓之类。以前做跟踪和三维重建,首先就得提取特征。特征点以前成功的就是SIFT/SURF/FAST之类,现在完全可以通过CNN形成的特征图来定义。
边缘和轮廓的提取是一个非常tricky的工作,细节也许就会被过强的图像线条掩盖,纹理(texture)本身就是一种很弱的边缘分布模式,分级(hierarchical)表示是常用的方法,俗称尺度空间(scale space)。以前做移动端的视觉平台,有时候不得不把一些图像处理功能关掉,原因是造成了特征畸变。现在CNN这种天然的特征描述机制,给图像预处理提供了不错的工具,它能将图像处理和视觉预处理合二为一。
1 特征提取;
LIFT(Learned Invariant Feature Transform)模型,就是在模仿SIFT:

2 边缘/轮廓提取;
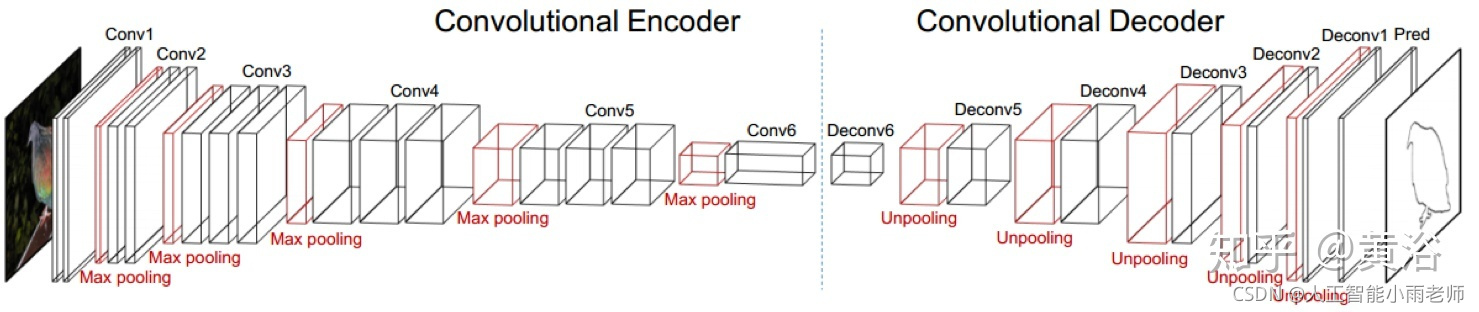
一个轮廓检测的encoder-decoder network模型:
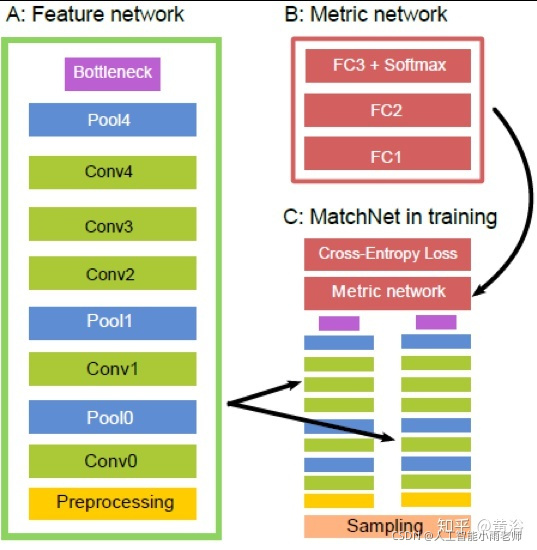
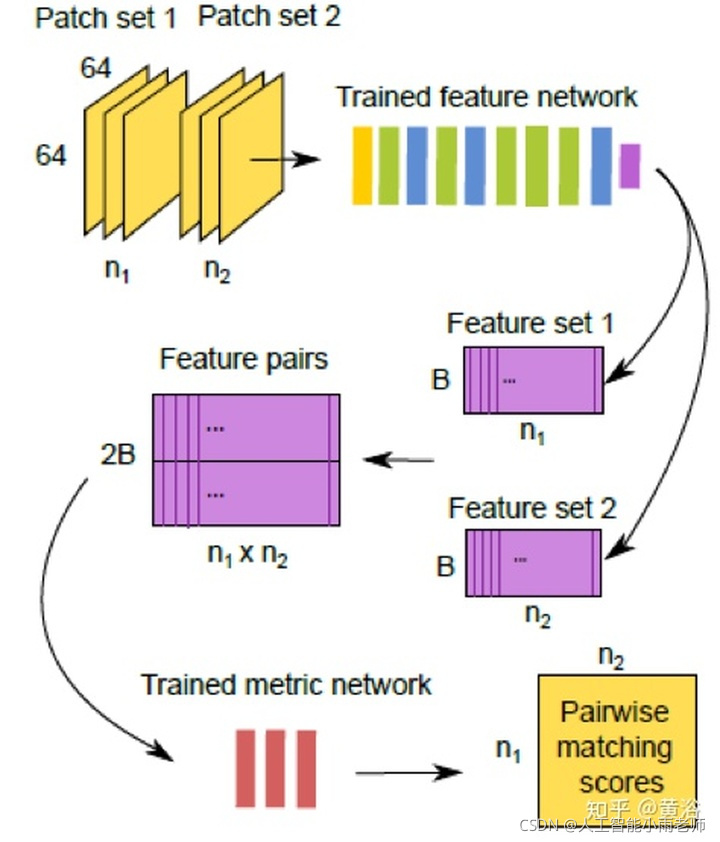
3 特征匹配;
这里给出一个做匹配的模型MatchNet:
再说2.5-D计算机视觉部分(不是全3-D)
涉及到视差或者2-D运动的部分一般称为2.5-D空间。这个部分和前面的2-D问题是一样的,作为重建任务它也是逆问题,需要约束条件求解优化解,比如TV,GraphCut。一段时间(特别是Marr时代)计算机视觉的工作,就是解决约束条件下的优化问题。
后来,随机概率和贝叶斯估计大行其事,约束条件变成了先验知识(prior),计算机视觉圈里写文章要是没有 P (Probability) 和 B (Bayes),都不好意思发。像SVM, Boosting,Graphical Model,Random Forest,BP(Belief Propagation),CRF(Conditional Random Field),Mixture of Gaussians,MCMC,Sparse Coding都曾经是计算机视觉的宠儿,现在轮到CNN出彩:)。
可以说深度学习是相当“暴力”的,以前分析的什么约束呀,先验知识呀在这里统统扔一边,只要有图像数据就可以和传统机器学习方法拼一把。
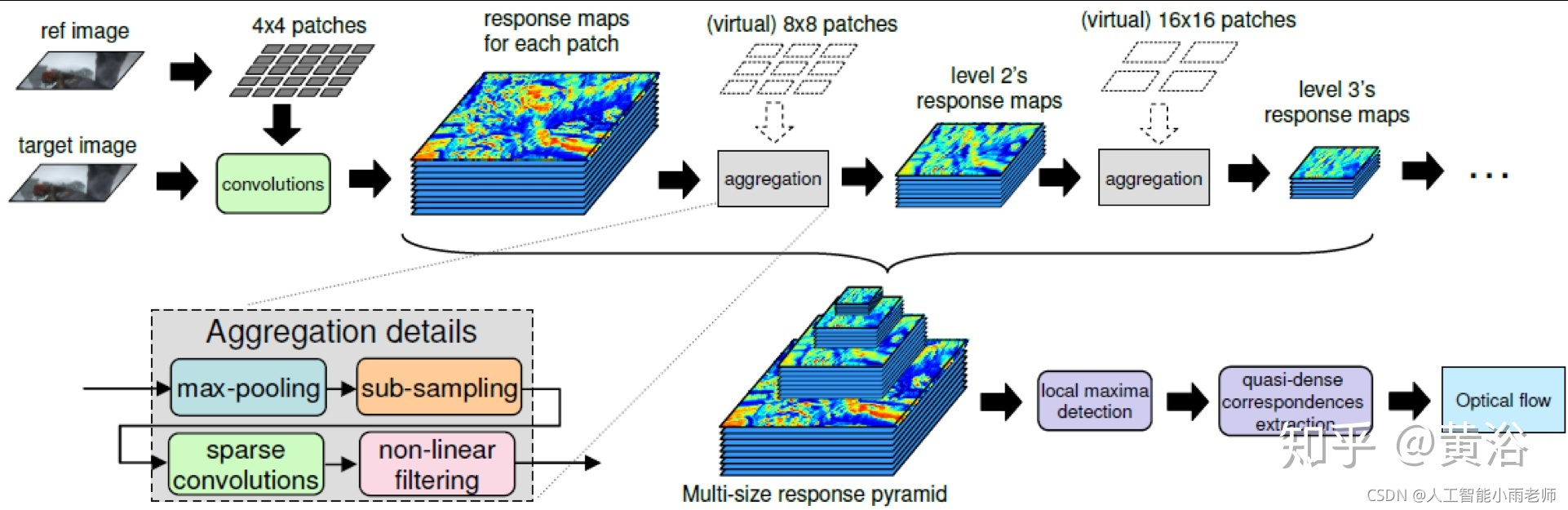
1 运动/光流估计;
传统的方法包括局部法和全局法,这里CNN取代的就是全局法。这里是一个光流估计的模型:
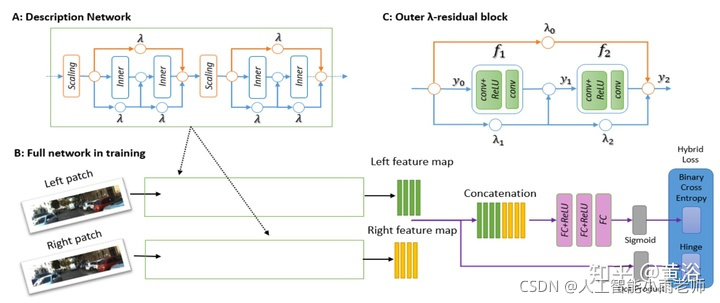
2 视差/深度图估计;
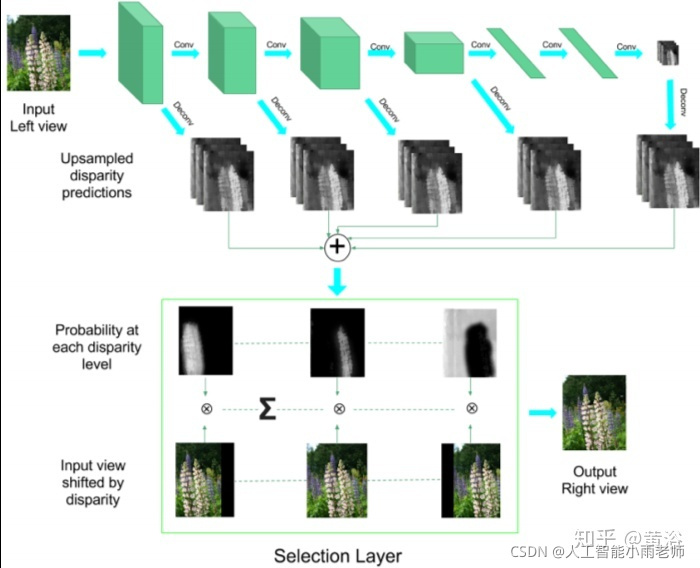
深度图估计和运动估计是类似问题,唯一不同的是单目可以估计深度图,而运动不行。这里是一个双目估计深度图的模型:
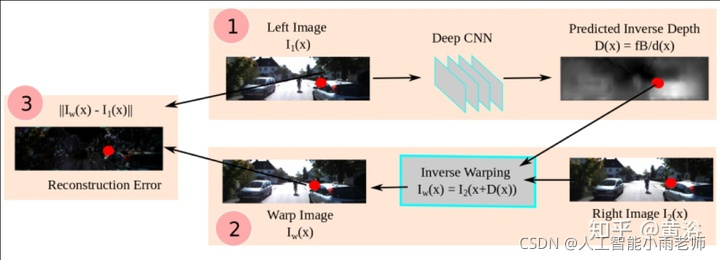
而这个是单目估计深度图的模型:巧妙的是这里利用双目数据做深度图估计的非监督学习
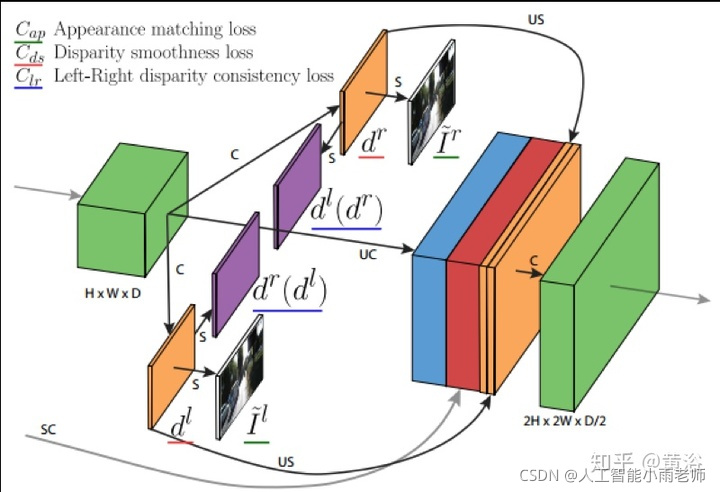
另外一个单目深度估计的模型:也是利用双目的几何约束做非监督的学习
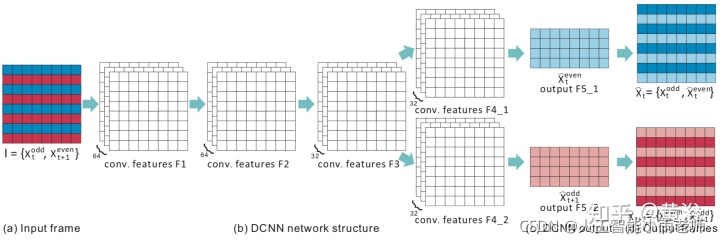
3 视频去隔行/内插帧;
Deinterlacing和Framerate upconversion视频处理的经典问题,当年Sony和Samsung这些电视生产商这方面下了很大功夫,著名的NXP(从Philips公司spin-off)当年有个牛逼的算法在这个模块挣了不少钱。
基本传统方法都是采用运动估计和补偿的方法,俗称MEMC,所以我把它归类为2.5-D。前面运动估计已经用深度学习求解了,现在这两个问题自然也是。
首先看一个做MEMC的模型:
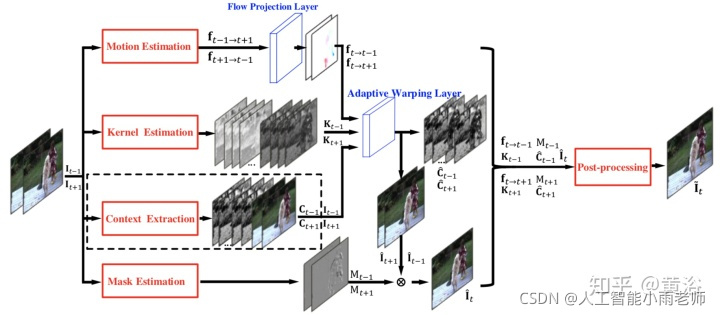
这是做Deinterlacing的一个模型:
这是Nvidia的Framerate Upconversion方面模型:
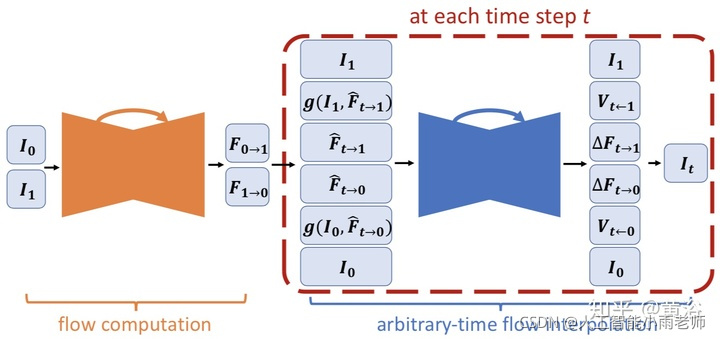
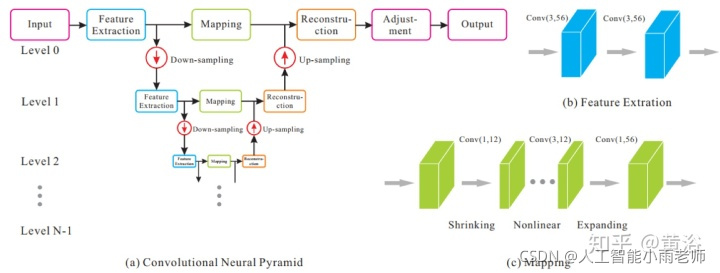
因为它采用optic flow方法做插帧,另外附上它的flow estimation模型:就是一个沙漏(hourglass)模式
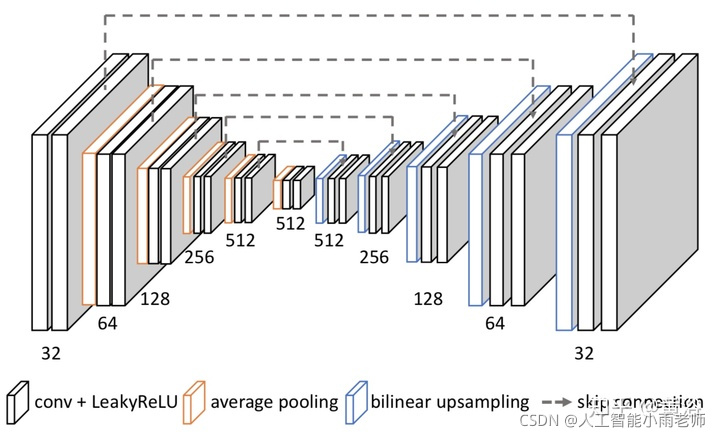
4 新视角图像生成;刚才介绍单目估计深度图的时候,其实已经看到采用inverse warping方法做新视角生成的例子,在IBR领域这里有一个分支叫Depth Image-based Rendering (DIBR)。
和上个问题类似,采用深度图学习做合成图像,也属于2.5-D空间。在电视领域,曾经在3-D电视界采用这种方法自动从单镜头视频生成立体镜头节目。以前也用过机器学习,YouTube当年采用image search方法做深度图预测提供2D-3D的内容服务,但性能不好。现在感觉,大家好像不太热衷这个了。
这是一个产生新视角的模型:
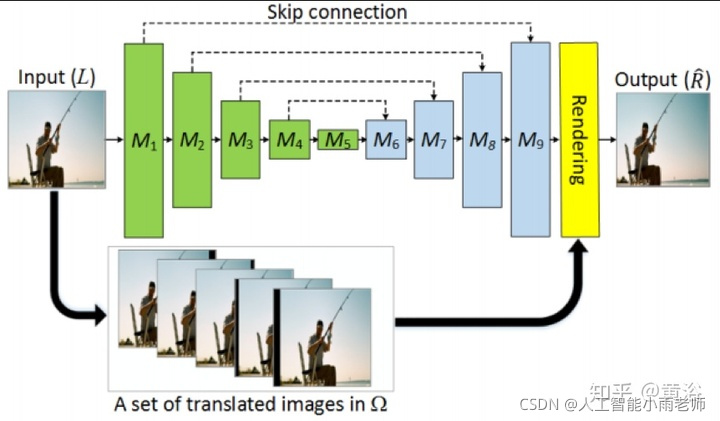
而这个是从单镜头视频生成立体视频的模型:
有做编码/解码的,也是采用运动或者相似变换为基础,但性能不如传统方法,这里忽略。
更多人工智能精品课程欢迎加微领取哟~
