文章目录
- 1 Spark参数优化
- 1.1 num-executors
- 1.2 executor-memory
- 1.3 executor-cores
- 1.4 driver-memory
- 1.5 spark.default.parallelism
- 1.6 spark.shuffle.memoryFraction
- 1.7 spark.storage.memoryFraction
- 1.8 资源参考示例
- 2 RDD优化
- 2.1 RDD 复用
- 2.2 RDD 持久化
- 2.3 RDD 过滤
- 3 算子优化
- 4 Shuffle优化
- 5 数据倾斜优化
- 5.1 增大key的粒度
- 5.2 过滤导致倾斜的key
- 5.3 使用随机的key
- 5.4 map join
- 5.5 序列化优化
- 5.6 广播变量优化
1 Spark参数优化
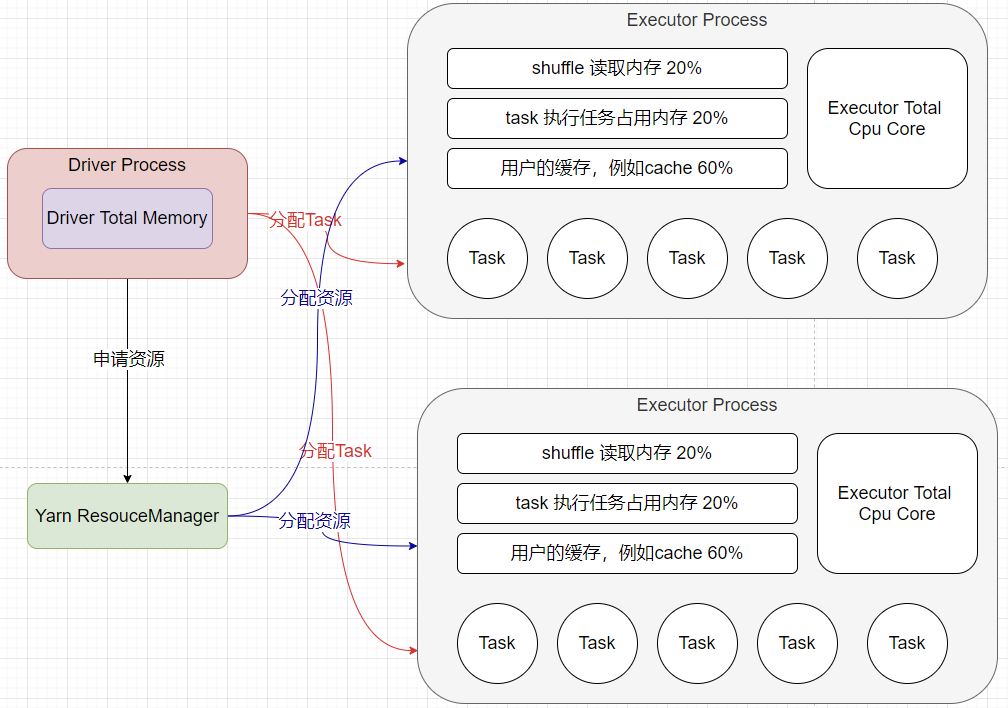
Executor端的内存主要分为三块:第一块就是让Task执行我们自己编写的代码时使用,默认占用总内存的20%;第二块是让task通过shuffle过程拉取上一个stage的task的输出后,进行聚合等操作时使用,默认也是占用总内存的20%;第三块是让RDD持久化时使用,默认占用总内存的60%。
1.1 num-executors
参数建议:一般每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太多和太少都不合适,太少的话,无法有效充分利用集群资源,太多的话,Yarn无法基于充分的资源,只能陷入等待或终止。
1.2 executor-memory
参数建议:一般每个Executor的内存设置为4G~8G,这里给的是一个参考值,还是得具体情况具体分析,num-exeutors*executor-memory应该等于你能够调用的所有内存,如果是团队公用的内存,那么最好不要超过最大内存的1/3 - 1/2
1.3 executor-cores
参数建议:一般每个Executor的cpu cores 数量设置2~4个较为合适,这里给的是一个参考值,还是得具体情况具体分析,num-exeutors*executor-cores应该等于你能够调用的所有核数,如果是团队公用的资源,那么最好不要超过最大核数的1/3 - 1/2
1.4 driver-memory
参数建议:一般默认就行,1G够用了,但是如果在程序中使用了大的集合,或者调用collect算子,需要将driver-memory设置的大一点,否则很容易就溢出了,即OOM。
1.5 spark.default.parallelism
参数建议:Spark官网建议的设置原则:设置参数为num-exeutors*executor-cores的2-3倍,比如Executor的总CPU cores为300(75个executor*4个executor-cores),那么设置为1000个task是可以的,可以充分利用集群资源
1.6 spark.shuffle.memoryFraction
默认0.2(20%),如果shuffle操作较多,可以调高该内存值
1.7 spark.storage.memoryFraction
默认0.6(60%),如果你的缓存的RDD比较多,可以调高该内存值
1.8 资源参考示例
bin/spark-submit \
--master yarn \
--num-executors 100 \
--executor-memory 6G \
--executor-cores 4 \
--driver-memory 1G \
--conf spark.default.parallelism=1000 \
--conf spark.shuffle.memoryFraction=0.3 \
--conf spark.storage.memoryFraction=0.5
2 RDD优化
2.1 RDD 复用
val filter1: RDD[(String, Int)] = words.map((_,1)).filter(_._1%2==0)
val filter2: RDD[(String, Int)] = words.map((_,1)).filter(_._1%2==1)
filter1.union(filter2).collect
val maprdd: RDD[(String, Int)] = words.map((_,1))
val filter1: RDD[(String, Int)] = maprdd.filter(_._1%2==0)
val filter2: RDD[(String, Int)] = maprdd.filter(_._1%2==1)
filter1.union(filter2).collect
2.2 RDD 持久化
对于多次用到的rdd最好进行持久化,减少计算次数
rdd.cache()
rdd.persist(StorageLevel.MEMORY_ONLY)
2.3 RDD 过滤
为了减少数据量,数据如果能提前过滤就提前过滤
3 算子优化
- mapPartitions:包裹在map外
- foreachPartition:包裹在foreach外,用于写库操作,创建连接
- filter+coalesce:过滤后数据分配不均匀,需要重分区操作,多分区变少分区
- repartition:当少分区边多分区的时候,和coalesce效果一样
- reduceByKey本地聚合:能用reduceByKey的时候尽量不要使用groupByKey
4 Shuffle优化
spark shuffle演进的历史
- Spark 0.8及以前Hash Based Shuffle
- Spark 0.8.1为Hash Based Shuffle引入File Consolidation机制
- Spark 0.9引入ExternalAppendOnlyMap
- Spark 1.1引入Sort Based Shuffle,但默认仍为Hash Based Shuffle
- Spark 1.2默认的Shuffle方式改为Sort Based Shuffle
- Spark 1.4引入Tungsten-Sort Based Shuffle
- Spark 1.6 Tungsten-sort并入Sort Based Shuffle. Spark 2.0 Hash Based Shuffle退出历史舞台
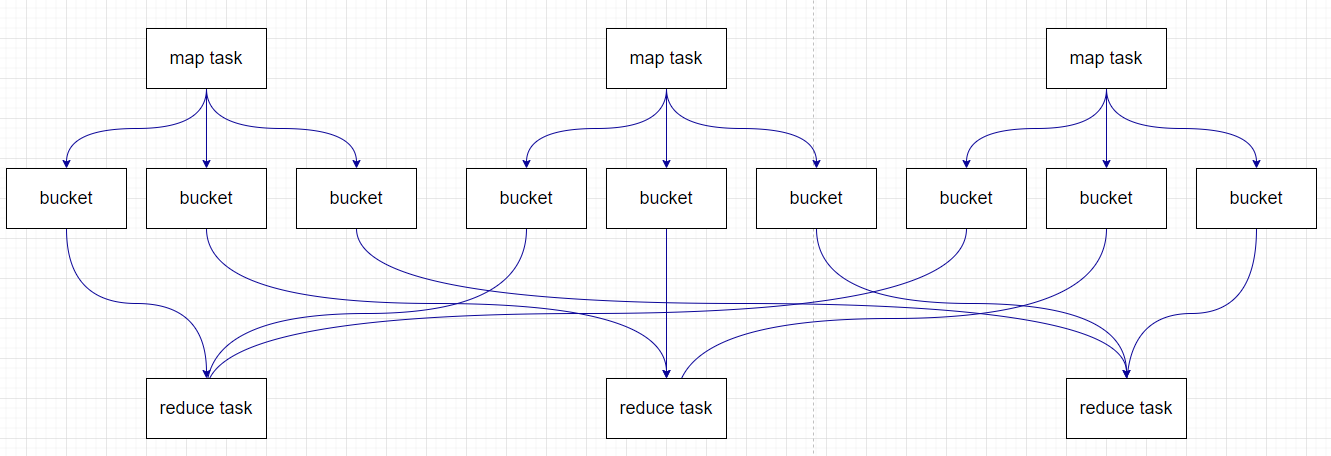
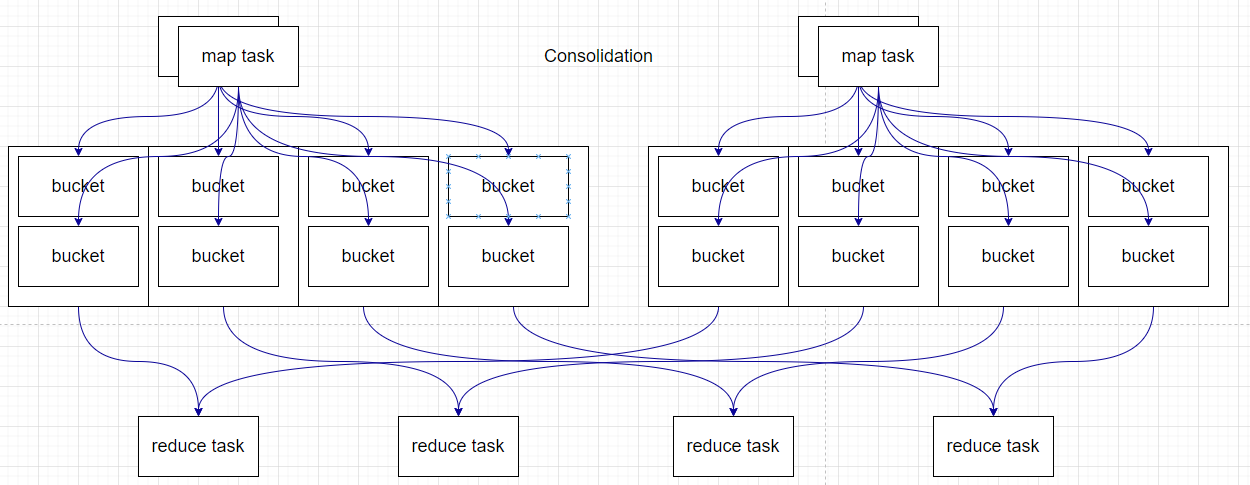
在之后引入了Sort Base Shuffle,map端会按照partitionId以及key对记录进行排序,同时将全部结果写到一个文件中,同时带有一个索引文件。
5 数据倾斜优化
5.1 增大key的粒度
比如原来的key是(省份+城市),那么我们在满足业务需求的前提下可以将key改为(省份),可以减少数据倾斜发生的概率
5.2 过滤导致倾斜的key
有时候数据倾斜是因为业务字段为大量空值,导致了数据倾斜的发生,有时候这种空值对我们来说是没有意义的,所以我们可以直接过滤掉
提高Shuffle中reduce的并行度,可以减少数据倾斜发生的概率,并没有从本质上解决数据倾斜
假设有三个分区,然后所有的key的hash值如下
123
456
789
333
224
前4个值对3取模都为0,会导致0号的task计算的数量过大,这里就可以增加并行度进行计算了
5.3 使用随机的key
在没有增加前缀时的shuffle阶段,可以看出,大量的hello进入到了一个task中,导致运行速度不统一,有的快,有的慢
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pD6McXkB-1631974248650)(K12题目自测推荐系统面试指导.pic/image-20210914084856902.png)]
在增加了随机前缀之后,将key打散分配到不同的task里,进行聚合,然后再将前缀去掉,进行二次聚合,可以有效的避免数据倾斜
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6kkcfe0E-1631974248651)(K12题目自测推荐系统面试指导.pic/image-20210914085110505-16315967549041.png)]
5.4 map join
普通的join是会走shuffle过程的,而一旦shuffle,就相当于会将相同key的数据拉取到一个shuffle read task中再进行join,此时就是reduce join。但是如果一个RDD是比较小的,则可以采用广播小RDD全量数据+map算子来实现与join同样的效果,也就是map join,此时就不会发生shuffle操作,也就不会发生数据倾斜。
(注意,RDD是并不能进行广播的,只能将RDD内部的数据通过collect拉取到Driver内存然后再进行广播)
不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。将较小RDD中的数据直接通过collect算子拉取到Driver端的内存中来,然后对其创建一个Broadcast变量;接着对另外一个RDD执行map类算子,在算子函数内,从Broadcast变量中获取较小RDD的全量数据,与当前RDD的每一条数据按照连接key进行比对,如果连接key相同的话,那么就将两个RDD的数据用你需要的方式连接起来。
根据上述思路,根本不会发生shuffle操作,从根本上杜绝了join操作可能导致的数据倾斜问题。
当join操作有数据倾斜问题并且其中一个RDD的数据量较小时,可以优先考虑这种方式,效果非常好。
5.5 序列化优化
默认情况下,Spark使用Java的序列化机制。Java的序列化机制使用方便,不需要额外的配置,在算子中使用的变量实现Serializable接口即可,但是,Java序列化机制的效率不高,序列化速度慢并且序列化后的数据所占用的空间依然较大。
Kryo序列化机制比Java序列化机制性能提高10倍左右,Spark之所以没有默认使用Kryo作为序列化类库,是因为它不支持所有对象的序列化,同时Kryo需要用户在使用前注册需要序列化的类型,不够方便,但从Spark 2.0.0版本开始,简单类型、简单类型数组、字符串类型的Shuffling RDDs 已经默认使用Kryo序列化方式了。
Kryo序列化注册方式的实例代码
public class MyKryoRegistrator implements KryoRegistrator
{
@Override
public void registerClasses(Kryo kryo)
{
kryo.register(StartupReportLogs.class);
}
}
配置Kryo序列化方式的实例代码
//创建SparkConf对象
val conf = new SparkConf().setMaster(…).setAppName(…)
//使用Kryo序列化库,如果要使用Java序列化库,需要把该行屏蔽掉
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
//在Kryo序列化库中注册自定义的类集合,如果要使用Java序列化库,需要把该行屏蔽掉
conf.set("spark.kryo.registrator", "com.kgc.MyKryoRegistrator");
5.6 广播变量优化
默认情况下,task中的算子中如果使用了外部的变量,每个task都会获取一份变量的复本,这就造成了内存的极大消耗。一方面,如果后续对RDD进行持久化,可能就无法将RDD数据存入内存,只能写入磁盘,磁盘IO将会严重消耗性能;另一方面,task在创建对象的时候,也许会发现堆内存无法存放新创建的对象,这就会导致频繁的GC,GC会导致工作线程停止,进而导致Spark暂停工作一段时间,严重影响Spark性能。
假设当前任务配置了20个Executor,指定500个task,有一个20M的变量被所有task共用,此时会在500个task中产生500个副本,耗费集群10G的内存,如果使用了广播变量, 那么每个Executor保存一个副本,一共消耗400M内存,内存消耗减少了5倍。
广播变量在每个Executor保存一个副本,此Executor的所有task共用此广播变量,这让变量产生的副本数量大大减少。
在初始阶段,广播变量只在Driver中有一份副本。task在运行的时候,想要使用广播变量中的数据,此时首先会在自己本地的Executor对应的BlockManager中尝试获取变量,**如果本地没有,BlockManager就会从Driver或者其他节点的BlockManager上远程拉取变量的复本,**并由本地的BlockManager进行管理;之后此Executor的所有task都会直接从本地的BlockManager中获取变量。