目录
1.tensor到底是啥
2.tensor的创建
直接创建
从numpy中获得数据
内置的tensor创建方式
3、tensor转换
tensor 转为numpy
tensor 转为list
4、张量的运算
加法
减法
乘法
其他的一些运算
总结
再不入坑就晚了,深度神经网络概念大整理,最简单的神经网络是什么样子?https://gamwatcher.blog.csdn.net/article/details/120012457![]() https://gamwatcher.blog.csdn.net/article/details/120012457
https://gamwatcher.blog.csdn.net/article/details/120012457
本科生学深度学习,搭建环境,再不入坑就晚了https://gamwatcher.blog.csdn.net/article/details/119941843![]() https://gamwatcher.blog.csdn.net/article/details/119941843
https://gamwatcher.blog.csdn.net/article/details/119941843
评论包邮送书了!!!深度学习基础之numpy,小白轻松入门numpyhttps://gamwatcher.blog.csdn.net/article/details/120073767![]() https://gamwatcher.blog.csdn.net/article/details/120073767
https://gamwatcher.blog.csdn.net/article/details/120073767
深度学习基础之matplotlib,一文搞定各个示例,建议收藏以后参考https://gamwatcher.blog.csdn.net/article/details/120159760![]() https://gamwatcher.blog.csdn.net/article/details/120159760
https://gamwatcher.blog.csdn.net/article/details/120159760
大家好,我是香菜,原创不易,欢迎点赞评论,一起学习
pytorch 和tensorflow 中最重要的概念就是tensor了,tensorflow 这个框架的名字中很直白,就是tensor的流动,所以学习深度学习的第一课就是得搞懂tensor到底是个什么东西了,今天就来学习下,OK,起飞
1.tensor到底是啥
tensor 即“张量”(翻译的真难理解,破概念)。实际上跟numpy数组、向量、矩阵的格式基本一样。但是是专门针对GPU来设计的,可以运行在GPU上来加快计算效率,不要被吓到。
在PyTorch中,张量Tensor是最基础的运算单位,与NumPy中的NDArray类似,张量表示的是一个多维矩阵。不同的是,PyTorch中的Tensor可以运行在GPU上,而NumPy的NDArray只能运行在CPU上。由于Tensor能在GPU上运行,因此大大加快了运算速度。
一句话总结:一个可以运行在gpu上的多维数据而已
x = torch.zeros(5)调试看下这个东西到底在内存中是什么,都有哪些属性,别说话,看图。
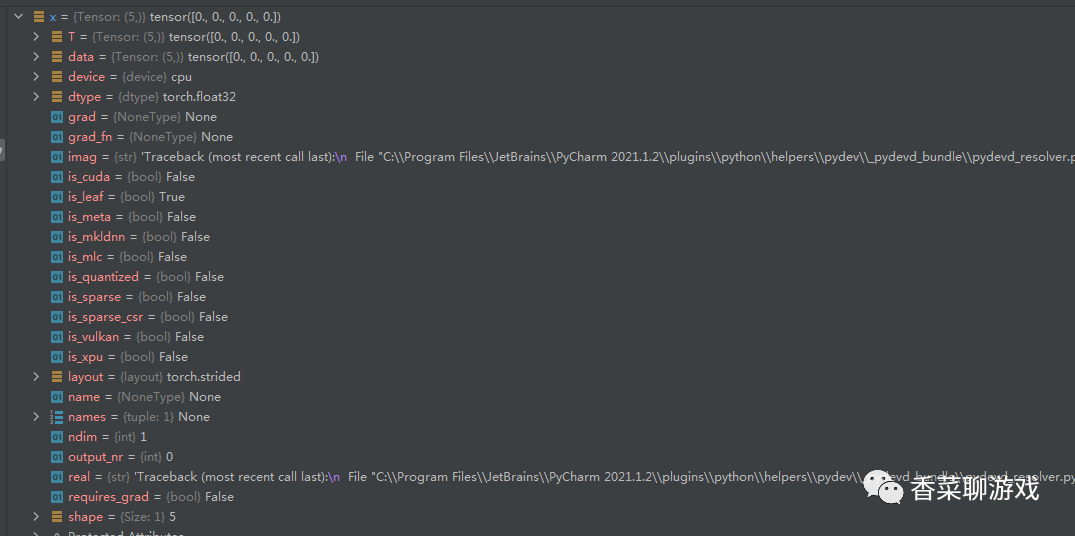
2.tensor的创建
tensor 概念再怎么高级也只是一个数据结构而已,一个类,怎么创建这个对象呐,有下面几种方式。
-
直接创建
pytorch 提供的创建tensor的方式
torch.tensor(data, dtype=None, device=None,requires_grad=False)data - 可以是list, tuple, numpy array, scalar或其他类型
dtype - 可以返回想要的tensor类型
device - 可以指定返回的设备
requires_grad - 可以指定是否进行记录图的操作,默认为False
快捷方式创建
t1 = torch.FloatTensor([[1,2],[5,6]])-
从numpy中获得数据
numpy是开发中常用的库,所以怎么将numpy中的数据给到tensor中,这个pytorch也提供了接口,很方便
torch.from_numpy(ndarry)注:生成返回的tensor会和ndarry共享数据,任何对tensor的操作都会影响到ndarry,反之亦然
内置的tensor创建方式
-
torch.empty(size)返回形状为size的空tensor -
torch.zeros(size)全部是0的tensor -
torch.zeros_like(input)返回跟input的tensor一个size的全零tensor -
torch.ones(size)全部是1的tensor -
torch.ones_like(input)返回跟input的tensor一个size的全一tensor -
torch.arange(start=0, end, step=1)返回一个从start到end的序列,可以只输入一个end参数,就跟python的range()一样了。实际上PyTorch也有range(),但是这个要被废掉了,替换成arange了 -
torch.full(size, fill_value)这个有时候比较方便,把fill_value这个数字变成size形状的张量 -
torch.randn(5)随机一个生成一个tensor
3、tensor转换
tensor数据的转换在开发中也是常用的,看下常用的两种转换方式
tensor 转为numpy
a = torch.ones(5) print(a) b = a.numpy() print(b)
tensor 转为list
data = torch.zeros(3, 3) data = data.tolist() print(data)
4、张量的运算
维度提升
tensor的broadcasting是不同维度之间进行运算的一种手段,和不同的数据类型进行运算时的原则差不多,比如整型和float 进行运算的时候,将数据往精度更高的数据类型进行提升,tensor的维度扩张也是类似。
方法:
遍历所有的维度,从尾部维度开始,每个对应的维度大小要么相同,要么其中一个是 1,要么其中一个不存在。不存在则扩展当前数据,可以看到下图红框部分,就数据进行了扩展
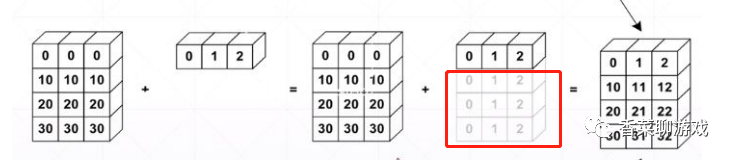
a = torch.zeros(2, 3)
b = torch.ones(3)
print(a)
print(b)
print(a + b)验证下结果,可以看到最后的结果都是1:
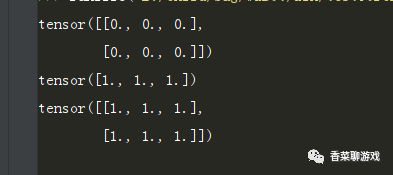
总结:和不同数据类型相加时精度提升一个道理,这里是维度的提升
加法

y = t.rand(2, 3) # 使用[0,1]均匀分布构建矩阵 z = t.ones(2, 3) # 2x3 的全 1 矩阵 # 3 中加法操作等价 print(y + z) ### 加法1 t.add(y, z) ### 加法2
减法
a = t.randn(2, 1) b = t.randn(2, 1) print(a) ### 等价操作 print(a - b) print(t.sub(a, b)) print(a) ### sub 后 a 没有变化
乘法
矩阵的乘法大学的时候都学过,我们简单复习下,交叉相乘,理解原理就行,因为多维度的矩阵乘法更复杂,还是pytorch提供了支持

t.mul(input, other, out=None):矩阵乘以一个数
t.matmul(mat, mat, out=None):矩阵相乘
t.mm(mat, mat, out=None):基本上等同于 matmul
a=torch.randn(2,3)
b=torch.randn(3,2)
### 等价操作
print(torch.mm(a,b)) # mat x mat
print(torch.matmul(a,b)) # mat x mat
### 等价操作
print(torch.mul(a,3)) # mat 乘以 一个数
print(a * 3)其他的一些运算
pytorch还支持更多的运算,这些运算就不一一介绍了,在使用的时候测试一下就知道结果了
t.div(input, other, out=None)#:除法
t.pow(input, other, out=None)#:指数
t.sqrt(input, out=None)#:开方
t.round(input, out=None)#:四舍五入到整数
t.abs(input, out=None)#:绝对值
t.ceil(input, out=None)#:向上取整
t.clamp(input, min, max, out=None)#:把 input 规范在 min 到 max 之间,超出用 min 和 max 代替,可理解为削尖函数
t.argmax(input, dim=None, keepdim=False)#:返回指定维度最大值的索引总结
tensor是深度学习的基础,也是入门的,可以简单的理解为一个多维的数据结构,并且内置了一些特殊运算,你品,你细品,这似乎没什么复杂的,常规操作而已,稳住,不慌,我们能赢,看透了本质就没什么难的了。