【CV语义分割】全卷积神经网络FCN(更新ing)_明确目标,勿欺骗自己,小白冲冲冲
学习总结
(1)paper《Fully Convolutional Networks for Semantic Segmentation》
(2)论文翻译可以参考:https://www.cnblogs.com/xuanxufeng/p/6249834.html
(3)当前最成功的图像分割深度学习技术都是基于一个共同的先驱:FCN(Fully Convolutional Network,全卷积神经网络)
(4)-
文章目录
- 学习总结
- 一、语义分割介绍
- 0.总结优秀的语义分割模型特性
- 1.图像分割的历史
- 2.FCN发展历程
- 3.基础知识铺垫
- 1)全局信息与局部信息
- 二、FCN模型
- 0.回顾CNN
- 1.什么是FCN模型?
- 2.传统 CNN 有几个缺点:
- 3.将全连接层换成卷积有什么好处呢?
- 4.FCN上采样
- 1)反卷积上采样
- 2)双线性插值上采样
- 3)反池化上采样(略)
- 5.跳跃结构(跳级结构)
- 6.总结
- 6.1 基本概念
- 6.2 FCN 的缺点
- 三、FCN代码实践
- 1.导入库
- 2.构造FCN基础模型
- 创建一个全卷积网络实例net
- 3.初始化转置卷积层
- 4.读取数据集
- 5.训练
- 6.预测
- 7.小结
- 8.练习(待完成)
- 附:常识科普-一次文献和二次文献
- Reference
前期知识储备:

一、语义分割介绍

语义分割简单地说,分割就是抠图(按图像中物体表达的含义进行抠图),用不同颜色将不同目标标记出来。

摄像头采集到车前景象,通过模型分析,我们可以自动筛选出地面、交通线、人行道、行人、建筑、树、还有其他基础设施。
相比传统的目标识别,语义分割它更强大。语义分割模型不仅可以识别简单的类别,而且还可以进行多目标、多类别、复杂目标以及分割目标。
比如图中我们可以看到路面和交通标识线有清晰的分割,路面和人行道也同样如此,甚至路灯和建筑也可以清楚地分离出来。这项技术在医学上也同样作用巨大,我们可以识别病灶并将其与正常组织分割,大脑神经系统内我们可以分离出同一组功能的神经结构,这些如何依赖人工去完成,所需的时间至少为数小时,而交给机器,那么数秒钟即可完成。
因此依靠分离模型,我们可以把重复性的劳动交给它去完成,人工只需要对输出结果进行二次分析和筛选,大大加快了提取过程和分析精度。
分割的相关术语:

0.总结优秀的语义分割模型特性
- 分割出来的不同语义区域对某种性质如灰度、纹理而言具有相似性,区域内部比较平整相邻语义区域对分割所依据的性质有明显的差异
- 不同语义区域边界上是明确和规整的
- 语义分割模型方法进阶
1.图像分割的历史
所有的发展都是漫长的技术积累,加上一些外界条件满足时就会产生质变。我们简单总结了图像分割的几个时期:
2000年之前,数字图像处理时我们采用方法基于几类:阈值分割、区域分割、边缘分割、纹理特征、聚类等。
2000年到2010年期间, 主要方法有四类:基于图论、聚类、分类以及聚类和分类结合。
2010年至今,神经网络模型的崛起和深度学习的发展,主要涉及到几种模型:

参考文献:http://www/arocmag.com/article/02-2017-07-064.html
截至到2017年底,我们已经分化出了数以百计的模型结构。当然,经过从技术和原理上考究,我们发现了一个特点,那就是当前最成功的图像分割深度学习技术都是基于一个共同的先驱:FCN(Fully Convolutional Network,全卷积神经网络)。

2010年前,CNN 是非常高效的视觉处理工具,因为它能够学习到层次化的特征。研究人员将全连接层替换为卷积层来输出一种空间域映射(反卷积)而非简单输出类别的概率,从而将图像分割问题转换为端对端的图像处理问题。
端对端的好处:通过缩减人工预处理和后续处理,尽可能使模型从原始输入到最终输出,给模型更多可以根据数据自动调节的空间,增加模型的整体契合度。
端对端的坏处:通过大量模型的组合,增加了模型复杂度,降低了模型可解释性。
2.FCN发展历程
2014年 FCN 模型,主要贡献为在语义分割问题中推广使用端对端卷积神经网络,使用反卷积进行上采样
2015年 U-net 模型,构建了一套完整 的编码解码器
2015年 SegNet 模型,将最大池化转换为解码器来提高分辨率
2015年 Dilated Convolutions(空洞卷积),更广范围内提高了内容的聚合并不降低分辨率
2016年 DeepLab v1&v2
2016年 RefineNet 使用残差连接,降低了内存使用量,提高了模块间的特征融合
2016年 PSPNet 模型
2017年 Large Kernel Matters
2017年 DeepLab V3
以上几种模型可以按照语义分割模型的独有方法进行分类,如专门池化(PSPNet、DeepLab),编码器-解码器架构(SegNet、E-Net),多尺度处理(DeepLab)、条件随机场(CRFRNN)、空洞卷积(DiatedNet、DeepLab)和跳跃连接(FCN)。
3.基础知识铺垫
1)全局信息与局部信息
上图的上方是局部信息,下方不太清楚的一块的图是全局信息。注意FCN一共有5次下采样,所以上图画出是3个块不太对,应该是5个。
全局信息:也称为语义信息,用来确定目标是什么
局部信息:也称为表征信息,用来确定目标在哪里,感受域(感受野)小,图像的小破坏(浅层次)。当感受域小时,如下图的奶牛图的颈椎为界限,图(b)就划分开识别了。

二、FCN模型
0.回顾CNN
CNN 最后输出的是类别的概率值。CNN在最后的卷积层之后会连接上若干个全连接层,将卷积层产生的特征图(feature map)映射成为一个固定长度的特征向量。一般的CNN结构适用于图像级别的分类和回归任务,因为它们最后都期望得到输入图像的分类的概率,如ALexNet网络最后输出一个1000维的向量表示输入图像属于每一类的概率。
CNN 的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征:较浅的卷积层感知域较小,学习到一些局部区域的特征。
较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征。这些抽象特征对物体的大小、位置和方向等敏感性更低,从而有助于识别性能的提高。
1.什么是FCN模型?
因为模型网络中所有的层都是卷积层,故称为全卷积网络。
全卷积神经网络主要使用了三种技术:
- 卷积化(Convolutional)
- 上采样(Upsample)
- 跳跃结构(Skip Layer)
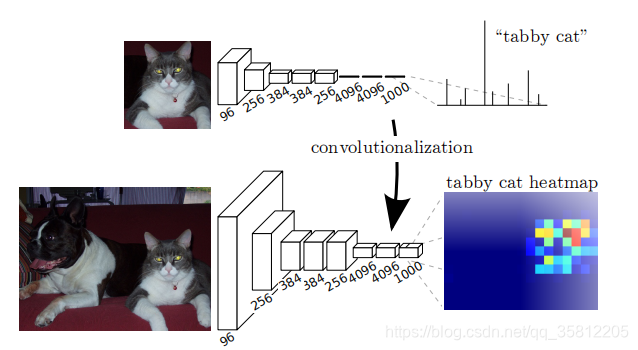
简单说就是将CNN(下图为李宏毅ppt图)最后的 Fully Connected 全连接层换成了卷积层,直接输出目标物体所属的像素范围,即输出一张已经标记好的图(而非像CNN输出一个概率值,如上图的上方,中间的网络最后三层为全连接层,最后概率最高值为tabby cat)。

2.传统 CNN 有几个缺点:
(1)存储开销大,滑动窗口较大,每个窗口都需要存储空间来保存特征和判别类别,而且使用全连接结构,最后几层将近指数级存储递增
(2)计算效率低,大量重复计算
(3)滑动窗口大小是相对独立的,末端使用全连接只能约束局部特征。
为了解决上面的部分问题,FCN 将传统 CNN 中的全连接层转化成卷积层,对应 CNN 网络 FCN 把最后三层全连接层转换成为三层卷积层(4096,4096,1000)。
虽然通过上面两个图观察,卷积核全连接数值没有变化,但是卷积核全连接概念不一样,所以表达的含义就截然不同。
3.将全连接层换成卷积有什么好处呢?
这里我们要理解一句比较专业的话:如果卷积核的 kernel_size 和输入 feature maps 的 size 一样,那么相当于该卷积核计算了全部 feature maps 的信息,则相当于是一个 kernel_size∗1 的全连接。
我们怎么去理解这句话?
大概意思为:当我们输入的图片大小和卷积核大小一致时,其实等价于建立全连接,但是还是有区别。
全连接的结构是固定的,当我们训练完时每个连接都是有权重的。而卷积过程我们其实为训练连接结构,学习了目标和那些像素之间有关系,权重较弱的像素我们可以忽略。
全连接不会学习过滤,会给每个连接分权重并不会修改连接关系。卷积则是会学习有用的关系,没用得到关系它会弱化或者直接 dropout。这样卷积块可以共用一套权重,减少重复计算,还可以降低模型复杂度。
4.FCN上采样
FCN网络一般是用来对图像进行语义分割的,于是就需要对图像上的各个像素进行分类,这就需要一个上采样将最后得到的输出上采样到原图的大小。
上采样对于低分辨率的特征图,常常采用上采样的方式将它还原高分辨率,以下是上采样的常用的三种方法(双线性插值方法实现简单,无需训练;反卷积上采样需要训练,但能更好的还原特征图)。
1)反卷积上采样

a 是输入图像,b 是经过卷积得到的特征图,分辨率明显下降。经过上采样(反卷积)提升分辨率得到同时,还保证了特征所在区域的权重,最后将图片的分辨率提升原图一致后,权重高的区域则为目标所在区域。
FCN 模型处理过程也是这样,通过卷积和反卷积我们基本能定位到目标区域,但是,我们会发现模型前期是通过卷积、池化、非线性激活函数等作用输出了特征权重图像,我们经过反卷积等操作输出的图像实际是很粗糙的,毕竟丢了很多细节。因此我们需要找到一种方式填补丢失的细节数据,所以就有了跳跃结构。
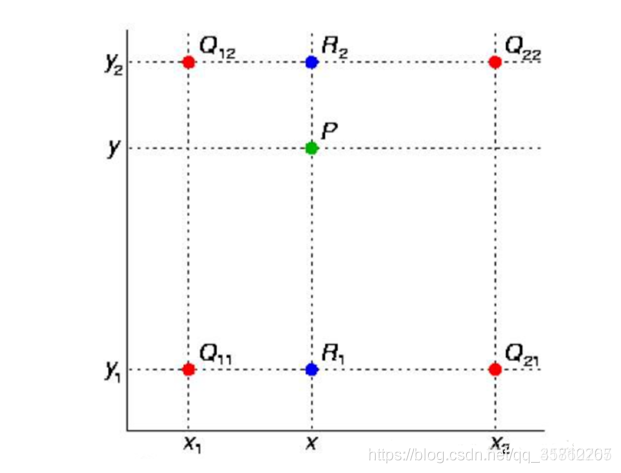
2)双线性插值上采样
单线性插值(一个方向上)就是已知两个点的值,并将两点连成一条直线来确定中间的点的值。现在双线性插值(两个方向上)就是三维的坐标系,需要找到4个点来确定中心点坐标:
详细参考:https://blog.csdn.net/qq_41760767/article/details/97521397
3)反池化上采样(略)
5.跳跃结构(跳级结构)
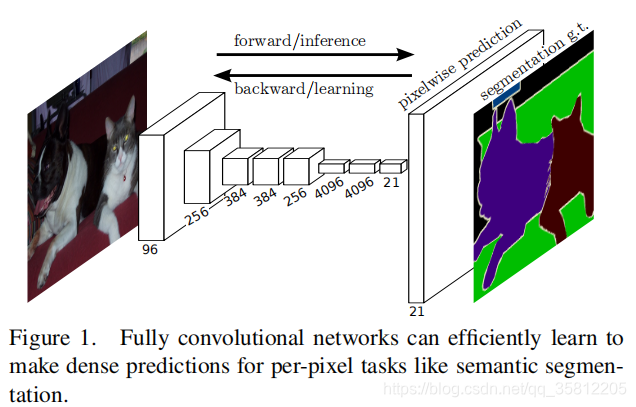
我们通过回查学习过的知识,可以帮助理解当前的知识。这里的原理也有些许类似,我们正向过程的卷积、池化等操作都会输出每个层的特征,我们使用反卷积然后和历史中的池化和卷积数据结合,利用它们的数据填补我们缺失的数据。

三个技术都已经构建如模型之中,通过一定标记数据的训练后,模型已经学会了如何识别类别,并且能反卷积得到对应类别所在的像素区域。输出的效果如下:
6.总结
6.1 基本概念
卷积化:全连接层(6,7,8)都变成卷积层,适应任意尺寸输入,输出低分辨率的分割图片。
反卷积:低分辨率的图像进行上采样,输出同分辨率的分割图片。
跳层结构:结合上采样和上层卷积池化后数据,修复还原的图像。
6.2 FCN 的缺点
- 分割的结果不够精细。图像过于模糊或平滑,没有分割出目标图像的细节
- 因为模型是基于CNN改进而来,即便是用卷积替换了全连接,但是依然是独立像素进行分类,没有充分考虑像素与像素之间的关系
- 也是因为每个模型都有自己的不足,所以才会出现各式各样的模型来解决它们的问题。(如果能分析出每个模型的缺点,那我们也可以构建新的模型去完善他们的模型,这其实就是创新的过程)
三、FCN代码实践
这部分是学习李沐的《动手学深度学习》FCN部分(https://zh-v2.d2l.ai/chapter_computer-vision/fcn.html)的笔记。
1.导入库
语义分割能对图像中的每个像素分类。
FCN采用卷积神经网络实现了从图像像素到像素类别的变换。 与我们在图像分类或目标检测部分的CNN不同,全卷积网络将中间层特征图的高和宽变换回输入图像的尺寸:这是通过 转置卷积(transposed convolution)层实现的。 因此,输出的类别预测与输入图像在像素级别上具有一一对应关系:给定空间维上的位置,通道维的输出即该位置对应像素的类别预测。
%matplotlib inline
import torch
import torchvision
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
注意上面的最后一个库d2l,如果木有下载,需要pip install d2l torch torchvision -i https://pypi.mirrors.ustc.edu.cn/simple。
2.构造FCN基础模型
FCN先使用CNN抽取图像特征,然后通过 1 × 1 1\times 1 1×1卷积层将通道数变换为类别个数,最后通过转置卷积层将特征图的高和宽变换为输入图像的尺寸。
因此,模型输出与输入图像的高和宽相同,且最终输出的通道包含了该空间位置像素的类别预测。

使用在ImageNet数据集上预训练的ResNet-18模型来提取图像特征,并将该网络实例记为pretrained_net。 该模型的最后几层包括全局平均汇聚层和全连接层,然而全卷积网络中不需要它们。
pretrained_net = torchvision.models.resnet18(pretrained=True)
list(pretrained_net.children())[-3:]
可以看出网络结构如下,倒数第一层为线性层(输入是512,即通道数,而输出是1000,是因为image类别是1000);倒数第二层是平均的池化层(把7×7的宽和高变成1×1,而通道数不变);
[Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
),
AdaptiveAvgPool2d(output_size=(1, 1)),
Linear(in_features=512, out_features=1000, bias=True)]
创建一个全卷积网络实例net
它复制了Resnet-18中大部分的预训练层,但除去最终的全局平均汇聚层和最接近输出的全连接层。
net = nn.Sequential(*list(pretrained_net.children())[:-2])
给定高度和宽度分别为320和480的输入,net的前向计算将输入的高和宽减小至原来的 1/32 ,即10和15。通道数从3变成512.
X = torch.rand(size=(1, 3, 320, 480))
net(X).shape
# 打印出 torch.Size([1, 512, 10, 15])
接着使用 1×1 卷积层将输出通道数转换为Pascal VOC2012数据集的类数(21类)。
最后,需要将要素地图的高度和宽度增加32倍,从而将其变回输入图像的高和宽。
回想一下CNN 6.3节(填充和步幅)中卷积层输出形状的计算方法: 由于 (320−64+16×2+32)/32=10 且 (480−64+16×2+32)/32=15 ,我们构造一个步幅为 32 的转置卷积层,并将卷积核的高和宽设为 64 ,填充为 16 。
可以看到如果步幅为 s ,填充为 s/2 (假设 s/2 是整数)且卷积核的高和宽为 2s ,转置卷积核会将输入的高和宽分别放大 s 倍。
下面的num_classed选21可以让计算变少
num_classes = 21
net.add_module('final_conv', nn.Conv2d(512, num_classes, kernel_size=1))
net.add_module(
'transpose_conv',
nn.ConvTranspose2d(num_classes, num_classes, kernel_size=64, padding=16,
stride=32))
关于上面的nn库的add_module模块,详细可以参看pytorch源码:
def add_module(self, name: str, module: Optional['Module']) -> None:
r"""Adds a child module to the current module.
The module can be accessed as an attribute using the given name.
Args:
name (string): name of the child module. The child module can be
accessed from this module using the given name
module (Module): child module to be added to the module.
"""
if not isinstance(module, Module) and module is not None:
raise TypeError("{} is not a Module subclass".format(
torch.typename(module)))
elif not isinstance(name, torch._six.string_classes):
raise TypeError("module name should be a string. Got {}".format(
torch.typename(name)))
elif hasattr(self, name) and name not in self._modules:
raise KeyError("attribute '{}' already exists".format(name))
elif '.' in name:
raise KeyError("module name can't contain \".\", got: {}".format(name))
elif name == '':
raise KeyError("module name can't be empty string \"\"")
self._modules[name] = module
3.初始化转置卷积层
在图像处理中,我们有时需要将图像放大,即上采样(upsampling)。 双线性插值(bilinear interpolation) 是常用的上采样方法之一,它也经常用于初始化转置卷积层。
为了解释双线性插值,假设给定输入图像,我们想要计算上采样输出图像上的每个像素。
(1)将输出图像的坐标 (x,y) 映射到输入图像的坐标 (x′,y′) 上。 例如,根据输入与输出的尺寸之比来映射。 请注意,映射后的 x’ 和 y’ 是实数。
(2)在输入图像上找到离坐标 (x′,y′) 最近的4个像素。
(3)输出图像在坐标 (x,y) 上的像素依据输入图像上这4个像素及其与 (x′,y′) 的相对距离来计算。
双线性插值的上采样可以通过转置卷积层实现,内核由以下bilinear_kernel函数构造,其函数如下。
def bilinear_kernel(in_channels, out_channels, kernel_size):
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = (torch.arange(kernel_size).reshape(-1, 1),
torch.arange(kernel_size).reshape(1, -1))
filt = (1 - torch.abs(og[0] - center) / factor) * \
(1 - torch.abs(og[1] - center) / factor)
weight = torch.zeros(
(in_channels, out_channels, kernel_size, kernel_size))
weight[range(in_channels), range(out_channels), :, :] = filt
return weight
用双线性插值的上采样实验它由转置卷积层实现。 可以构造一个将输入的高和宽放大2倍的转置卷积层,并将其卷积核用bilinear_kernel函数初始化。
conv_trans = nn.ConvTranspose2d(3, 3, kernel_size=4, padding=1, stride=2,
bias=False)
conv_trans.weight.data.copy_(bilinear_kernel(3, 3, 4));
读取图像X,将上采样的结果记作Y。为了打印图像,我们需要调整通道维的位置。
img = torchvision.transforms.ToTensor()(d2l.Image.open('../img/catdog.jpg'))
X = img.unsqueeze(0)
Y = conv_trans(X)
out_img = Y[0].permute(1, 2, 0).detach()
可以看到,转置卷积层将图像的高和宽分别放大了2倍。 除了坐标刻度不同,双线性插值放大的图像和在 12.3节(指目标检测与边界框那节)中打印出的原图看上去没什么两样。
d2l.set_figsize()
print('input image shape:', img.permute(1, 2, 0).shape)
d2l.plt.imshow(img.permute(1, 2, 0))
print('output image shape:', out_img.shape)
d2l.plt.imshow(out_img);
打印输入输出的图片size:
input image shape: torch.Size([561, 728, 3])
output image shape: torch.Size([1122, 1456, 3])
在全卷积网络中,我们用双线性插值的上采样初始化转置卷积层。对于 1×1 卷积层,我们使用Xavier初始化参数。
W = bilinear_kernel(num_classes, num_classes, 64)
net.transpose_conv.weight.data.copy_(W);
4.读取数据集
用 12.9节(语义分割和数据集)中介绍的语义分割读取数据集。 指定随机裁剪的输出图像的形状为 320×480 :高和宽都可以被 32 整除。
batch_size, crop_size = 32, (320, 480)
train_iter, test_iter = d2l.load_data_voc(batch_size, crop_size)
#read 1114 examples
#read 1078 examples
5.训练
现在可以训练全卷积网络了。
- 这里的损失函数和准确率计算与图像分类中的并没有本质上的不同,因为我们使用转置卷积层的通道来预测像素的类别,所以在损失计算中通道维是指定的。
- 模型基于每个像素的预测类别是否正确来计算准确率。
def loss(inputs, targets):
return F.cross_entropy(inputs, targets, reduction='none').mean(1).mean(1)
num_epochs, lr, wd, devices = 5, 0.001, 1e-3, d2l.try_all_gpus()
trainer = torch.optim.SGD(net.parameters(), lr=lr, weight_decay=wd)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs, devices)
loss 0.455, train acc 0.859, test acc 0.850
222.8 examples/sec on [device(type='cuda', index=0), device(type='cuda', index=1)]

6.预测
在预测时,我们需要将输入图像在各个通道做标准化,并转成卷积神经网络所需要的四维输入格式。
def predict(img):
X = test_iter.dataset.normalize_image(img).unsqueeze(0)
pred = net(X.to(devices[0])).argmax(dim=1)
return pred.reshape(pred.shape[1], pred.shape[2])
为了可视化预测的类别给每个像素,我们将预测类别映射回它们在数据集中的标注颜色。
def label2image(pred):
colormap = torch.tensor(d2l.VOC_COLORMAP, device=devices[0])
X = pred.long()
return colormap[X, :]
测试数据集中的图像大小和形状各异。 由于模型使用了步幅为32的转置卷积层,因此当输入图像的高或宽无法被32整除时,转置卷积层输出的高或宽会与输入图像的尺寸有偏差。 为了解决这个问题,我们可以在图像中截取多块高和宽为32的整数倍的矩形区域,并分别对这些区域中的像素做前向计算。
注意:这些区域的并集需要完整覆盖输入图像。 当一个像素被多个区域所覆盖时,它在不同区域前向计算中转置卷积层输出的平均值可以作为softmax运算的输入,从而预测类别。
为简单起见,我们只读取几张较大的测试图像,并从图像的左上角开始截取形状为 320×480 的区域用于预测。 对于这些测试图像,我们逐一打印它们截取的区域,再打印预测结果,最后打印标注的类别。
voc_dir = d2l.download_extract('voc2012', 'VOCdevkit/VOC2012')
test_images, test_labels = d2l.read_voc_images(voc_dir, False)
n, imgs = 4, []
for i in range(n):
crop_rect = (0, 0, 320, 480)
X = torchvision.transforms.functional.crop(test_images[i], *crop_rect)
pred = label2image(predict(X))
imgs += [
X.permute(1, 2, 0),
pred.cpu(),
torchvision.transforms.functional.crop(test_labels[i],
*crop_rect).permute(1, 2, 0)]
d2l.show_images(imgs[::3] + imgs[1::3] + imgs[2::3], 3, n, scale=2);

7.小结
- 全卷积网络先使用卷积神经网络抽取图像特征,然后通过 1×1 卷积层将通道数变换为类别个数,最后通过转置卷积层将特征图的高和宽变换为输入图像的尺寸。
- 在全卷积网络中,我们可以将转置卷积层初始化为双线性插值的上采样。
8.练习(待完成)
(1)如果将转置卷积层改用Xavier随机初始化,结果有什么变化?
(2)调节超参数,能进一步提升模型的精度吗?
(3)预测测试图像中所有像素的类别。
(4)最初的全卷积网络的论文中 [Long et al., 2015] 还使用了卷积神经网络的某些中间层的输出。试着实现这个想法。
附:常识科普-一次文献和二次文献
EI论文科普:http://www.eipaperbx.com/index.php?_a=index&_m=frontpage
科技文献大概可以这么区分:一次文献和二次文献。
一次文献指直接出版发行的内容本身。期刊的文章,图书,专利,会议论文集等等等等都属于一次文献。
二次文献可以理解为「一次文献的文献」。类似元数据「meta data」是数据的数据。通常表现为一个收录平台收录一个一次文献的集合,并开放文章的摘要及引文信息。
SCI,EI是两个知名的二次文献数据库。因为收录质量高而在国内常作为研究人员毕业、晋升、职称评定的重要依据。
Sciencedirect是爱思唯尔出版社的一次文献数据库。主要包含爱思唯尔出版的期刊和图书。EI(Engineering Index,工程索引,后被爱思唯尔出版社收购)也是爱思唯尔公司的产品。事实上目前爱思唯尔官方的称呼为EV Compendex。
pytorch文档
(1)pytorch中文文档:https://pytorch-cn.readthedocs.io/zh/latest/
(2)pytorch英文文档:https://pytorch.org/docs/stable/index.html
Reference
(1)https://www.sohu.com/a/270896638_633698
(2)全卷积网络FCN详细讲解
(3)深度之眼论文复现b站:https://www.bilibili.com/video/BV16K411W782?p=4
(4)李沐-动手学深度学习:https://www.bilibili.com/video/BV1af4y1L7Zu?p=3&spm_id_from=pageDriver
对应的课程代码:https://colab.research.google.com/github/d2l-ai/d2l-zh-colab/blob/master/chapter_computer-vision/fcn.ipynb#scrollTo=QoKTkWtmGahx
对应的github:https://github.com/d2l-ai/d2l-zh/blob/master/chapter_computer-vision/fcn.md
登录后可发表评论
点击登录