目录结构:
1、项目介绍
2、网络设计
3、数据采集
4、APP开发
5、APP下载
6、效果展示
1、项目介绍:
该项目主要在于探索是否能在通用的安卓手机上实现一个辅助驾驶功能的APP。
功能与性能:
-
能够检测行人、自行车、电瓶车、汽车、卡车、公交车等常规交通参与者。
-
在行人等数量较多的情况下,可以发出提醒。
-
在前车距离过小的情况下,可以发出提醒。
-
能够检测出车道线(下一版本增加)
-
在偏离车道线的时候能够发出提醒(下一版本增加)
-
能在手机上较为实时的运行(>=10fps)
2、网络设计
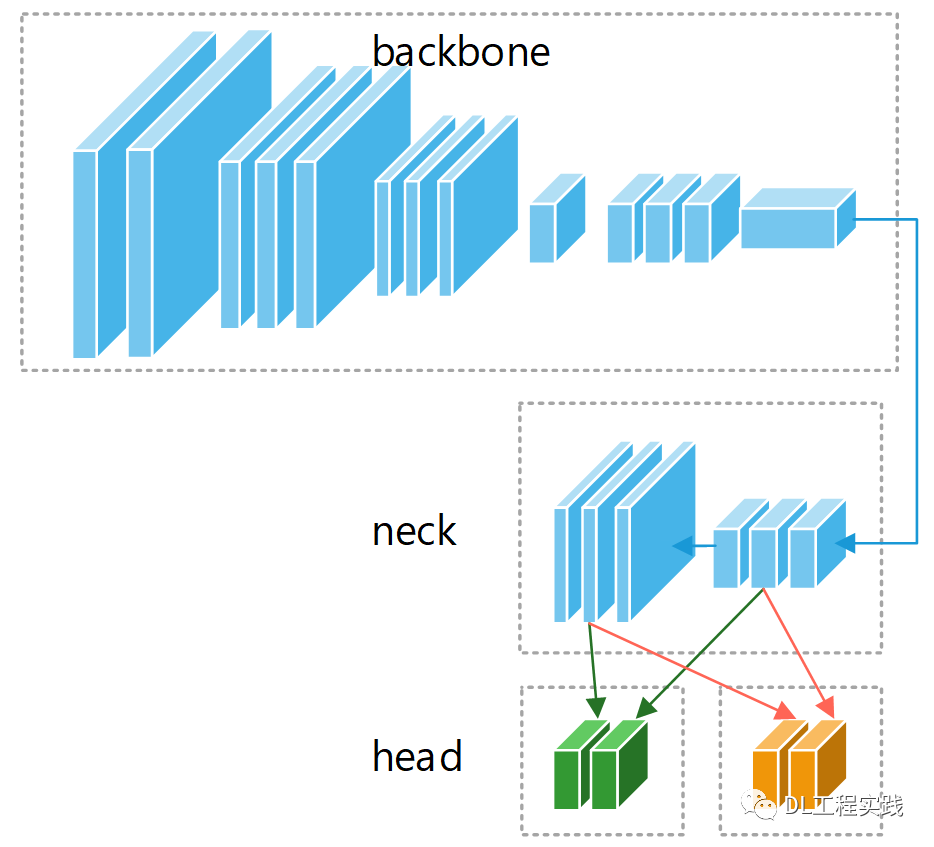
要实现车辆,行人等的检测,需要一个常规的目标检测网络(不考虑物体方向,否则手机性能不够),实现车道线检测需要一个车道线检测网络。如果使用串行方式,势必会增加延时,导致手机端无法流畅运行。因此这里考虑将两个网络合并,共享backbone以及neck部分,目标检测头和车道线检测头相互独立。如下图所示:
目标检测网络:
轻量级的目标网络实际上有很多,例如mobilenetSSD,yolo-lite,yolo-fastest,nanodet,yolov5s等。综合算力与精度,yolov5s是一个不错的选择。总的来说,yolov5在yolov3的基础上,增加了一些降低计算量的模块,例如FOCUS模块,CSP模块等,降低了yolo的计算量,另一方面,使用了PAN,SPP等,增加了网络的精度。本次的目标检测就选择yolov5s。
虽然yolov5s已经是一个相对轻量级的通用目标检测框架,但是对于手机这样的设备来说,想要实现实时的检测,依然具有极大的挑战。使用官方的yolov5s模型在手机上运行,检测一张图片的时间大约在800ms-1.5s之间,远远达不到实时。因此需要对yolov5s做一个精简。如下图所示为yolov5s的网络结构图(输入640*640)。

下面先简单介绍一下网络结构。主要由backbne+neck+head组成,如图中的三个灰色模块。关于网络中使用的各个模块,其细节如图中的米黄色模块所示 。其中CBH为yolov5中的基础模块,包含一个卷积,一个BN层以及一个Swish的激活层。FOCUS是一种快速降采样的方式。在传统的 CNN网络 中,一般使用两个大卷积7*7或者5*5进行快速的降低输入图像的分辨率。但是大卷积核就意味着大计算量。FOCUS首先将输入图片进行切片,然后在cat在一起,用一个卷积融合信息。极大的降低了网络前期的计算量。再来看网络的Neck部分。很明显的是增加了另外一个分支,原来的FPN将小分辨率的特征图上采样之后融合进行各个level的预测。现在的PAN增加了从大分辨率下采样到小分辨率的路径,进一步融合了各个level之间的信息,使得每个level能够很好的保留空间信息与语义信息。
Yolov5s计算量
接下来分析一下yolov5s的计算量。如图中的红色字体已经标注了各个模块的计算量占比。可以看到backbone大约占据了72%的计算量,而neck占据了27%的计算量。总的计算量大约为7.59G的计算量。这个计算量相对于手机来说还是非常巨大的。一般要想在手机上比较流畅的运行,计算量最好能降低到<1G的范围。由于目前的计算量实在巨大,可以考虑降低输入图片的分辨率。我们知道CNN关于输入图片分辨率的计算复杂度可以表达为:O(H*W),其中H为输入图片的高度,W为输入图片的宽度。因此降低图像分辨率可以得到一个平方倍的计算复杂度降低,这个收益还是比较大的。例如将图像的输入分辨率降低到原来的一半,计算复杂度就变成了O(1/2H*1/2W) = 1/4O(H*W)。也就是 说将分辨率降低一半,计算量减小为原来的1/4。通常轻量级分类网络的。考虑到我们辅助驾驶只需要判断车辆附近的对象,不需要对远处的小目标进行识别,那么选择320*320的分辨率作为输入。这样计算量就 大约变成了1/4*7.59G = 1.89G。
Yolov5s裁剪
继续观察网络结构,由于neck使用PAN,增加了一路数据通路,使得neck部分的计算量增加了一倍,那么可以考虑将PAN修改为FPN来降低计算量。如下图所示:

还有一种方式就是减少输出的level。Yolov5s默认输出3个level的特征图分别对应stride=8,16,32。由于输入分辨率已经被我们降低,且为了实现实时运行目标,我们也可以考虑将stride=8的level删除,这样也能降低比较多的计算量。如下图所示:
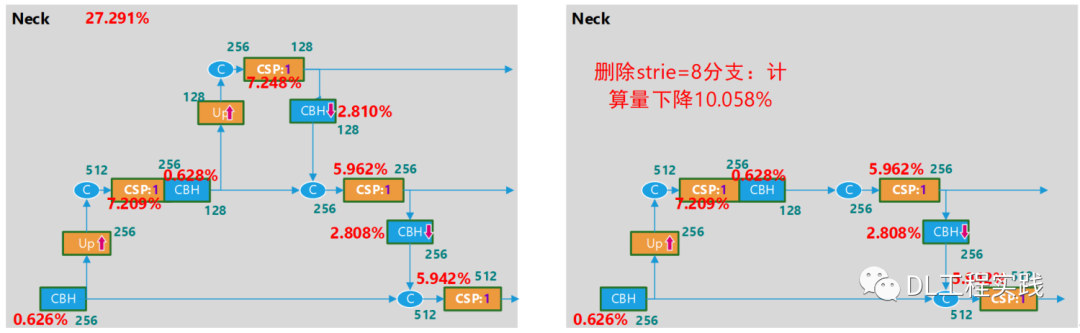
对过对比两种方案,删除PAN通路降低的计算量相对多一些,但是结合训练的最终精度(MAP),删除PAN通路的方式精度下降的比较明显,而删除stride=8的方案,可以取得一个比较好的平衡。因此最终的精简版本的网络结构为:

车道线检测网络:
轻量级的车道线检测网络并不是很多。因为大部分车道线检测是基于分割任务来做的。大家都知道,分割任务的一个特点是需要保持一个较高的分辨率,因此对于计算量,内存都是一个不小的挑战。这里引用一篇比较创新的车道线检测算法:《Ultra Fast Structure-aware Deep Lane Detection》,效果一般,并且官方网络只支持4车道线检测,但是特点就是快。论文的动机就是为了解决传统基于分割方法检测车道线的延时大的问题。下面来解读一下这篇论文(论文地址:https://arxiv.org/abs/2004.11757)
核心方法
将车道线检测定义为寻找车道线在图像中某些行的位置的集合,即基于行方向上的位置选择与分类(row-based classification)。这句话是整片论文的核心,如下图所示。

基于分割任务的车道线检测中,分类对象是每个像素点,对一个像素点进行C+1个类别的分类(C为车道线的预设数目,+1表示背景类别,由于使用CE损失,所以需要增加一个背景类,如果不用CE损失,+1可以不需要)。而该方案是对一行进行分类,分类的类别数为w+1(w表示图片在宽度上被分割的数目,即grid_cell的数量,+1表示该行上面无车道线),表示的是行上面的哪个位置有车道。因此,两种方案的分类含义不同。分割任务的分类是:H*W*(C+1), 该论文的分类是:C*h*(w+1)。由于该论文的这种分类方式,可以很方便的做一些先验约束,例如相领行之间的平滑与刚性等。而基于原始分割任务的却很难做这方面的约束。
如何解决速度慢
由于我们的方案是行向选择,假设我们在h个行上做选择,我们只需要处理h个行上的分类问题,只不过每行上的分类问题是W维的。因此这样就把原来HxW个分类问题简化为了只需要h个分类问题,而且由于在哪些行上进行定位是可以人为设定的,因此h的大小可以按需设置,但一般h都是远小于图像高度H的。(作者在博客中是这么说的,但是我认为虽然该方案的分类问题变少了,但是每个分类的维度变大了由原来的C+1变成了w+1, 即原来是H*W个分类问题,每个分类的维度是C+1, 现在是C*h个分类问题,每个分类的维度是w+1, 所以最终的分类总维度是从 H*W*(C+1) 变成了 C*h*(w+1),所以变快的主要原因是h<<H且w<<W,而不是分类数目的减少。)
如何解决感受野小
局部感受野小导致的复杂车道线检测困难问题。由于我们的方法不是分割的全卷积形式,是一般的基于全连接层的分类,它所使用的特征是全局特征。这样就直接解决了感受野的问题,对于我们的方法,在检测某一行的车道线位置时,感受野就是全图大小。因此也不需要复杂的信息传递机制就可以实现很好的效果。(这也带来了参数量大的问题,因为h和w不像分类网络下降的那么多,所以对于最后的全连接层来说,参数量将会很大)
先验约束
平滑性约束:

刚性约束:
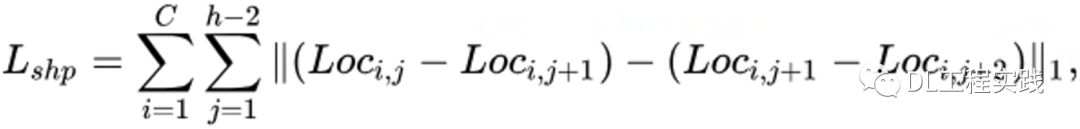
整体网络结构
整体网络结构如下图所示(分割模块作为训练负责模块,推理的时候不需要)

3、数据采集
通常来说,深度学习依赖大量的训练数据。好在对于交通场景,已经有比较多的开源数据集存在。例如kitti,bdd100k,apploscape,cityscapes,tuSimple Lane,Culane等。由于手头上只有mocrosoft的coco数据集,且coco数据集中包含了常规的行人,非机动车(自行车),机动车(car,bus,trunk),信号灯等。于是笔者准备先使用coco数据集进行训练。
COCO数据集筛选
由于原生的coco数据集有80类别,对于我们的辅助驾驶来说很多都是没有意义的,因此需要从里面选出带有交通类别的数据。这里笔者写了一个python脚本来进行自动化的筛选工作。
from pycocotools.coco import COCOimport numpy as npimport skimage.io as ioimport matplotlib.pyplot as pltimport osfrom PIL import Imagefrom PIL import ImageDrawimport csvimport shutildef create_coco_maps(ann_handle):coco_name_maps = {}coco_id_maps = {}cat_ids = ann_handle.getCatIds()cat_infos = ann_handle.loadCats(cat_ids)for cat_info in cat_infos:cat_name = cat_info['name']cat_id = cat_info['id']if cat_name not in coco_name_maps.keys():coco_name_maps[cat_name] = cat_idif cat_id not in coco_id_maps.keys():coco_id_maps[cat_id] = cat_namereturn coco_name_maps, coco_id_mapsdef get_need_cls_ids(need_cls_names, coco_name_maps):need_cls_ids = []for cls_name in coco_name_maps.keys():if cls_name in need_cls_names:need_cls_ids.append(coco_name_maps[cls_name])return need_cls_idsdef get_new_label_id(name, need_cls_names):for i,need_name in enumerate(need_cls_names):if name == need_name:return ireturn Noneif __name__ == '__main__':# create coco ann handleneed_cls_names = ['person','bicycle','car','motorcycle','bus','truck','traffic light']dst_img_dir = '/dataset/coco_traffic_yolov5/images/val/'dst_label_dir = '/dataset/coco_traffic_yolov5/labels/val/'min_side = 0.04464 # while 224*224, min side is 10. 0.04464=10/224dataDir='/dataset/COCO/'dataType='val2017'annFile = '{}/annotations/instances_{}.json'.format(dataDir,dataType)ann_handle=COCO(annFile)# create coco maps for id and namecoco_name_maps, coco_id_maps = create_coco_maps(ann_handle)# get need_cls_idsneed_cls_ids = get_need_cls_ids(need_cls_names, coco_name_maps)# get all imgidsimg_ids = ann_handle.getImgIds() # get all imgidsfor i,img_id in enumerate(img_ids):print('process img: %d/%d'%(i, len(img_ids)))new_info = ''img_info = ann_handle.loadImgs(img_id)[0]img_name = img_info['file_name']img_height = img_info['height']img_width = img_info['width']boj_infos = []ann_ids = ann_handle.getAnnIds(imgIds=img_id,iscrowd=None)for ann_id in ann_ids:anns = ann_handle.loadAnns(ann_id)[0]obj_cls = anns['category_id']obj_name = coco_id_maps[obj_cls]obj_box = anns['bbox']if obj_name in need_cls_names:new_label = get_new_label_id(obj_name, need_cls_names)x1 = obj_box[0]y1 = obj_box[1]w = obj_box[2]h = obj_box[3]#x_c_norm = (x1) / img_width#y_c_norm = (y1) / img_heightx_c_norm = (x1 + w / 2.0) / img_widthy_c_norm = (y1 + h / 2.0) / img_heightw_norm = w / img_widthh_norm = h / img_heightif w_norm > min_side and h_norm > min_side:boj_infos.append('%d %.4f %.4f %.4f %.4f\n'%(new_label, x_c_norm, y_c_norm, w_norm, h_norm))if len(boj_infos) > 0:print(' this img has need cls')shutil.copy(dataDir + '/' + dataType + '/' + img_name, dst_img_dir + '/' + img_name)with open(dst_label_dir + '/' + img_name.replace('.jpg', '.txt'), 'w') as f:f.writelines(boj_infos)else:print(' this img has no need cls')
4、APP开发
模型转换
由于训练过程使用的是pytorch框架,而pytorch框架是无法直接在手机上运行的,因此需要将pytorch模型转换为手机上支持的模型,这其实就是深度学习模型部署的问题。可以选择的开源项目非常多,例如mnn,ncnn,tnn等。这里我选择使用ncnn,因为ncnn开源的早,使用的人多,网络支持,硬件支持都还不错,关键是很多问题都能搜索到别人的经验,可以少走很多弯路。但是遗憾的是ncnn并不支持直接将pytorch模型导入,需要先转换成onnx格式,然后再将onnx格式导入到ncnn中。另外注意一点,将pytroch的模型到onnx之后有许多胶水op,这在ncnn中是不支持的,需要使用另外一个开源工具:onnx-simplifier对onnx模型进行剪裁,然后再导入到ncnn中。因此整个过程还有些许繁琐,为了简单,我编写了从"pytorch模型->onnx模型->onnx模型精简->ncnn模型"的转换脚本,方便大家一键转换,减少中间过程出错。我把主要流程的代码贴出来。
# 1、pytroch模型导出到onnx模型torch.onnx.export(net,input,onnx_file,verbose=DETAIL_LOG)# 2、调用onnx-simplifier工具对onnx模型进行精简cmd = 'python -m onnxsim ' + str(onnx_file) + ' ' + str(onnx_sim_file)ret = os.system(str(cmd))# 3、调用ncnn的onnx2ncnn工具,将onnx模型准换为ncnn模型cmd = onnx2ncnn_path + ' ' + str(new_onnx_file) + ' ' + str(ncnn_param_file) + ' ' + str(ncnn_bin_file)ret = os.system(str(cmd))# 4、对ncnn模型加密(可选步骤)cmd = ncnn2mem_path + ' ' + str(ncnn_param_file) + ' ' + str(ncnn_bin_file) + ' ' + str(ncnn_id_file) + ' ' + str(ncnn_mem_file)ret = os.system(str(cmd))
APP结构
当完成了所有的算法模块开发之后,APP开发实际上是水到渠成的事情。这里沿用运动技术APP中的框架,如下图所示:

APP主要源码:
参考计数APP开发中的源码示例:
Activity类核心源码
Camera类核心源码
Alg类核心源码
5、APP下载
语雀平台下载:
https://www.yuque.com/lgddx/xmlb/ny150b
百度网盘下载:
链接:https://pan.baidu.com/s/13YAPaI_WdaMcjWWY8Syh5w
提取码:hhjl

6、效果展示
手持手机在马路口随拍测试:
https://www.yuque.com/lgddx/xmlb/wyozh2
>堆堆星微信:15158106211
>官方微信讨论群:先加堆堆星,再拉进群
>官方QQ讨论群:885194271