Apache Flink 社区很高兴宣布 Flink 1.13.0 的发布!200 多个贡献者为这个新版本处理了 1000 多个问题。
该版本使我们迈出了一大步:将流处理应用程序变得与其他任何应用程序一样自然且易于管理。新的反应式扩展模式意味着通过仅更改并行进程数,就可以像在任何其他应用程序中一样扩展和扩展流应用程序。
该版本还突出显示了一系列改进,可以帮助用户更好地了解应用程序的性能。当流的流动速度不如您期望的那样快时,它们可以帮助您理解原因:加载和反压可视化可识别瓶颈,CPU 火焰图可识别应用程序中的热代码路径,以及状态访问延迟以了解如何 国家后端正在跟上。
除了这些功能之外,Flink 社区还对整个系统进行了很多改进,其中一些我们将在本文中进行讨论。我们希望您喜欢新版本和新功能。在本文结尾处,我们描述了从早期版本的 Apache Flink 升级时要注意的更改。
Notable features
Reactive scaling
响应式缩放是 Flink 计划的最新成果,旨在使流处理应用程序像其他任何应用程序一样自然且易于管理。
Flink 在资源管理和部署方面具有双重性质:您可以将Flink应用程序部署到诸如 Kubernetes 或 Yarn 之类的资源协调器上,从而 Flink 可以主动管理资源并根据需要分配和释放工作人员。这对于快速更改其所需资源的作业和应用程序(例如批处理应用程序和临时 SQL 查询)特别有用。应用程序并行性规则将遵循工作程序的数量。在 Flink 应用程序的上下文中,我们称此为主动缩放。
对于长时间运行的流应用程序,将其像其他任何长时间运行的应用程序一样部署通常是一个更好的模型:该应用程序实际上不需要知道它可以在K8,EKS,Yarn 等上运行,并且不需要 设法获得一定数量的工人;取而代之的是,它仅使用分配给它的工人数。工人规则的数量,应用程序并行度会对此进行调整。在 Flink 的上下文中,我们称之为反应式缩放。
应用程序部署模式开始了这项工作,使部署更像应用程序(通过避免两个单独的部署步骤来(1)启动集群和(2)提交应用程序)。响应式缩放模式可以完成此操作,现在您不必再使用额外的工具(脚本或 K8s 运算符)来保持工作程序的数量和应用程序并行性设置的同步。
现在,您可以像其他典型应用程序一样在 Flink 应用程序周围放置自动缩放器—只要您在配置自动缩放器时注意重新缩放的成本即可:有状态的流应用程序在缩放时必须四处移动状态。
要尝试反应式扩展模式,请添加调度程序模式:反应性配置条目并部署应用程序集群(独立或 Kubernetes )。查看反应式缩放文档以获取更多详细信息。
Analyzing application performance
像任何应用程序一样,分析和理解 Flink 应用程序的性能至关重要。由于 Flink 应用程序通常是数据密集型(处理大量数据),并且同时有望在(接近)实时延迟范围内提供结果,因此通常甚至更为关键。
当某个应用程序不再符合数据速率,或者某个应用程序占用的资源超出您的预期时,这些新工具可以帮助您查找原因:
Bottleneck detection, Back Pressure monitoring
性能分析期间的第一个问题通常是:瓶颈是哪个操作?
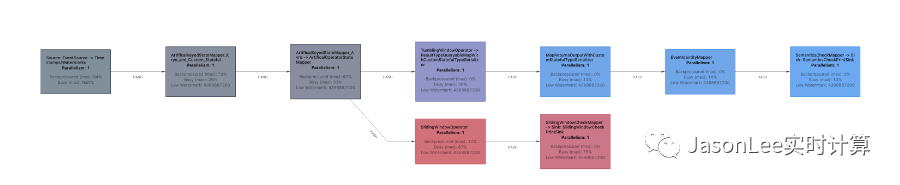
为了帮助回答这个问题,Flink 公开了有关任务繁忙(正在执行工作)和背压(具有执行工作的能力,但不能执行任务的原因,因为其后继操作员无法接受更多结果)的度量标准。瓶颈的候选者是繁忙的操作员,其前任承受了压力。
Flink 1.13 带来了改进的背压度量系统(使用任务邮箱计时而不是线程堆栈采样),并且重新制作了工作数据流的图形表示,并带有颜色编码以及繁忙度和背压比率。
CPU flame graphs in Web UI
性能分析过程中的下一个问题通常是:哪一部分的操作是昂贵的?
一种可视有效的调查方法是火焰图。它们有助于回答以下问题:-哪些方法当前正在消耗 CPU 资源?-一种方法的 CPU 消耗与其他方法相比如何?-堆栈上的哪一系列调用导致执行特定方法?
火焰图是通过重复采样线程堆栈轨迹而构造的。每个方法调用都由一个条形图表示,其中该条形图的长度与它在样本中出现的次数成正比。启用后,将在新的 UI 组件中为选定的操作员显示图形。
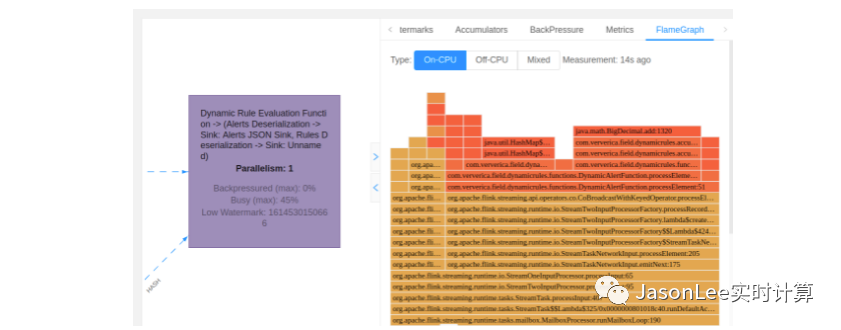
火焰图的创建成本很高:它们可能会导致处理开销,并给 Flink 的度量系统带来沉重的负担。因此,用户需要在配置中显式启用它们。
Access Latency Metrics for State
另一个可能的性能瓶颈可能是状态后端,尤其是当您的状态大于 Flink 可用的主内存并且您正在使用 RocksDB 状态后端时。
这并不是说 RocksDB 的运行速度很慢(我们喜欢 RocksDB!),但是它对达到良好的性能有一些要求。例如,很容易因磁盘资源类型错误而使 RocksDB 在云设置上对 IOP 的需求感到饥饿。
在 CPU 火焰图的顶部,新的状态后端延迟指标可以帮助您了解状态后端是否响应。例如,如果您看到 RocksDB 状态访问开始花费毫秒,那么您可能需要研究内存和 I / O 配置。可以通过设置 state.backend.rocksdb.latency-track-enabled 选项来激活这些指标。对指标进行了采样,并且这些指标的收集应对 RocksDB 状态后端性能产生边际影响。
Switching State Backend with savepoints
从保存点恢复时,您现在可以更改 Flink 应用程序的状态后端。这意味着应用程序的状态不再被锁定在最初启动该应用程序时所使用的状态后端中。
例如,这使它有可能首先从 HashMap 状态后端(JVM Heap 中的纯内存)开始,然后在状态变得太大时切换到 RocksDB 状态后端。
在后台,Flink 现在具有规范的保存点格式,在为保存点创建数据快照时,所有状态后端都使用该格式。
User-specified pod templates for Kubernetes deployments
Kubernetes 本地部署(Flink 在其中与 K8S 主动对话以启动和停止 Pod)现在支持自定义 Pod 模板。
使用这些模板,用户可以以 Kubernetes-y 的方式设置和配置 JobManagers 和 TaskManagers 窗格,并具有 Flink的Kubernetes 集成中直接内置的配置选项之外的灵活性。
Unaligned Checkpoints - production-ready
未对齐的检查点已经成熟到可以鼓励所有用户尝试的程度,如果他们发现应用程序存在背压问题。
特别是,这些更改使“未对齐检查点”更易于使用:
现在,您可以从未对齐的检查点重新缩放应用程序。如果您需要从保留的检查点扩展应用程序,这将非常方便,因为您无法(负担得起)创建保存点。
对于没有反压的应用程序,启用未对齐的检查点比较便宜。现在,未对齐的检查点可以超时自动适应性地触发,这意味着如果对齐阶段花费的时间比未对齐的检查点更长,则检查点将从对齐的检查点开始(不存储任何进行中的事件),然后退回到未对齐的检查点(存储一些正在进行的事件)。一定的时间。
在检查点文档中找到有关如何启用未对齐检查点的更多信息。
Machine Learning Library moving to a separate repository
为了加快 Flink 机器学习工作(流式,批处理和统一机器学习)的开发,该工作已移至 Flink 项目下的新存储库 flink-ml。我们在这里采用类似有状态功能的方法,在这种方法中,一个单独的存储库通过允许更多轻量级的贡献工作流和单独的发布周期来帮助加快了开发速度。
请继续关注机器学习方面的更多更新,例如与 ALink(Flink 上许多常见的机器学习算法的套件)或 Flink 和 TensorFlow 集成的相互作用。
Notable SQL & Table API improvements
像以前的版本一样,SQL 和 Table API 仍然是一大发展领域。
Windows via Table-valued functions
定义时间窗口是流 SQL 查询中最常见的操作之一。Flink 1.13 介绍了一种定义窗口的新方法:通过表值函数。这种方法不仅表达能力更强(允许您定义新的窗口类型),而且完全符合 SQL 标准。Flink 1.13 支持新的语法中的 TUMBLE 和 HOP 窗口,后续的版本中还会有 SESSION 窗口。为了演示增加的表达能力,考虑下面两个例子。一种新的累积窗函数,它给窗口分配一个扩展步长直到达到最大窗口大小
SELECT window_time, window_start, window_end, SUM(price) AS total_price
FROM TABLE(CUMULATE(TABLE Bid, DESCRIPTOR(bidtime), INTERVAL '2' MINUTES, INTERVAL '10' MINUTES))
GROUP BY window_start, window_end, window_time;
您可以引用表值窗口函数的窗口开始时间和窗口结束时间,从而使新类型的构造成为可能。例如,除了常规的窗口聚合和窗口连接之外,您现在可以表示窗口 Top-K 聚合
SELECT window_time, ...
FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY total_price DESC)
as rank
FROM t
) WHERE rank <= 100;
Improved interoperability between DataStream API and Table API/SQL
这个版本从根本上简化了 DataStream API 和 Table API 程序的混合。Table API 是开发应用程序的好方法,它具有声明性和许多内置函数。但有时,您需要转到 DataStream API,以获得其表达性、灵活性和对状态的显式控制。
新方法 StreamTableEnvironment.toDataStream()/.fromDataStream()可以将 DataStream API 中的数据流建模为表源或汇。自动转换类型、事件时间和水印。此外,Row 类(表示来自表 API 的行事件)已经得到了很大的改进(改进了 toString()/hashCode()/equals()方法的行为),现在支持按名称访问字段,并支持稀疏表示。
Table table=tableEnv.fromDataStream(
dataStream,Schema.newBuilder()
.columnByMetadata("rowtime","TIMESTAMP(3)")
.watermark("rowtime","SOURCE_WATERMARK()")
.build());
DataStream<Row> dataStream=tableEnv.toDataStream(table)
.keyBy(r->r.getField("user"))
.window(...)
SQL Client: Init scripts and Statement Sets
SQL 客户端是直接运行和部署 SQL 流和批处理作业的便捷方法,而无需从命令行编写任何代码,也无需将其作为 CI / CD 工作流的一部分。
此版本大大改进了 SQL 客户端的功能。现在,SQL 客户端和 SQL 脚本都支持 Java 应用程序可用的几乎所有操作(通过编程方式从TableEnvironment 启动查询时)。这意味着 SQL 用户在其 SQL 部署中需要的粘合代码少得多。
Easier Configuration and Code Sharing
将不再支持 YAML 文件来配置 SQL 客户端。而是,客户端在执行主 SQL 脚本之前接受一个或多个初始化脚本来配置会话。
这些初始化脚本通常将在团队/部署之间共享,并且可用于加载公用目录,应用公用配置设置或定义标准视图。
./sql-client.sh -i init1.sql init2.sql -f sqljob.sql
More config options
更大的可识别配置选项集和改进的 SET / RESET 命令使从 SQL 客户端和 SQL 脚本中定义和控制执行变得更加容易。
Multi-query Support with Statement Sets
多查询执行使您可以将多个 SQL 查询(或语句)作为单个 Flink 作业执行。这对于无限期运行的 SQL 查询流特别有用。
语句集是将应该一起执行的查询组合在一起的机制。
以下是可以通过 SQL 客户端运行的 SQL 脚本的示例。它设置和配置环境并执行多个查询。该脚本捕获端到端的查询以及所有环境设置和配置工作,从而使其成为一个独立的部署工件。
-- set up a catalog
CREATE CATALOG hive_catalog WITH ('type' = 'hive');
USE CATALOG hive_catalog;
-- or use temporary objects
CREATE TEMPORARY TABLE clicks (
user_id BIGINT,
page_id BIGINT,
viewtime TIMESTAMP
) WITH (
'connector' = 'kafka',
'topic' = 'clicks',
'properties.bootstrap.servers' = '...',
'format' = 'avro'
);
-- set the execution mode for jobs
SET execution.runtime-mode=streaming;
-- set the sync/async mode for INSERT INTOs
SET table.dml-sync=false;
-- set the job's parallelism
SET parallism.default=10;
-- set the job name
SET pipeline.name = my_flink_job;
-- restore state from the specific savepoint path
SET execution.savepoint.path=/tmp/flink-savepoints/savepoint-bb0dab;
BEGIN STATEMENT SET;
INSERT INTO pageview_pv_sink
SELECT page_id, count(1) FROM clicks GROUP BY page_id;
INSERT INTO pageview_uv_sink
SELECT page_id, count(distinct user_id) FROM clicks GROUP BY page_id;
END;
Hive query syntax compatibility
现在,您可以使用 Hive SQL 语法针对 Flink 编写 SQL 查询。除了 Hive 的 DDL 方言外,Flink 现在还接受常用的 Hive DML 和 DQL 方言。
要使用 Hive SQL 方言,请将 table.sql-dialect 设置为 hive 并加载 HiveModule。后者很重要,因为 Hive 的内置功能对于正确的语法和语义兼容性是必需的。以下示例说明了这一点:
CREATE CATALOG myhive WITH ('type' = 'hive'); -- setup HiveCatalog
USE CATALOG myhive;
LOAD MODULE hive; -- setup HiveModule
USE MODULES hive,core;
SET table.sql-dialect = hive; -- enable Hive dialect
SELECT key, value FROM src CLUSTER BY key; -- run some Hive queries
请注意,Hive 方言不再支持 Flink 的 SQL 语法的 DML 和 DQL 语句。切换回 Flink 语法的默认方言。
Improved behavior of SQL time functions
与时间打交道是任何数据处理的关键要素。但是同时,处理数据时,处理不同的时区,日期和时间是一项非常棘手的任务。
在 Flink 1.13 中。我们在简化与时间相关的函数的使用上付出了很多努力。我们调整了(更具体的)函数的返回类型,例如:PROCTIME(),CURRENT_TIMESTAMP,NOW()。
此外,您现在还可以在 TIMESTAMP_LTZ 列上定义事件时间属性,以在夏时制的支持下优雅地执行窗口处理。
请参阅发行说明以获取完整的更改列表。
Notable PyFlink improvements
PyFlink 中此发行版的总体主题是使 Python DataStream API 和 Table API 更接近于与 Java / Scala API 的功能对等。
Stateful operations in the Python DataStream API
借助 Flink 1.13,Python 程序员现在还可以充分享受 Apache Flink 的状态流处理 API 的全部潜能。Flink 1.12 中引入的经过重新设计的Python DataStream API 现在具有完整的有状态功能,允许用户记住状态中事件的信息并稍后对其采取行动。
有状态处理能力是许多更复杂的处理操作的基础,这些操作需要记住各个事件之间的信息(例如,窗口操作)。
此示例显示使用状态的自定义计数窗口实现:
class CountWindowAverage(FlatMapFunction):
def __init__(self, window_size):
self.window_size = window_size
def open(self, runtime_context: RuntimeContext):
descriptor = ValueStateDescriptor("average", Types.TUPLE([Types.LONG(), Types.LONG()]))
self.sum = runtime_context.get_state(descriptor)
def flat_map(self, value):
current_sum = self.sum.value()
if current_sum is None:
current_sum = (0, 0)
# update the count
current_sum = (current_sum[0] + 1, current_sum[1] + value[1])
# if the count reaches window_size, emit the average and clear the state
if current_sum[0] >= self.window_size:
self.sum.clear()
yield value[0], current_sum[1] // current_sum[0]
else:
self.sum.update(current_sum)
ds = ... # type: DataStream
ds.key_by(lambda row: row[0]) \
.flat_map(CountWindowAverage(5))
User-defined Windows in the PyFlink DataStream API
Flink 1.13 在 PyFlink DataStream API 中添加了对用户定义窗口的支持。程序现在可以使用标准窗口定义以外的窗口。
因为 Windows 是处理无限制流的所有程序的核心(通过将流拆分为有界大小的“桶”),所以这大大提高了 API 的可表达性。
Row-based operation in the PyFlink Table API
Python Table API 现在支持基于行的操作,即行上的自定义转换函数。这些函数是在内置函数之外的表上应用数据转换的简便方法。
这是在 Python Table API 中使用 map()操作的示例:
@udf(result_type=DataTypes.ROW(
[DataTypes.FIELD("c1", DataTypes.BIGINT()),
DataTypes.FIELD("c2", DataTypes.STRING())]))
def increment_column(r: Row) -> Row:
return Row(r[0] + 1, r[1])
table = ... # type: Table
mapped_result = table.map(increment_column)
除了 map()之外,API 还支持 flat_map(),aggregate(),flat_aggregate()和其他基于行的操作。这使 Python Table API 在与Java Table API 的功能奇偶性方面迈出了一大步。
Batch execution mode for PyFlink DataStream programs
PyFlink DataStream API 现在还支持有界流的批处理执行模式,这是 Flink 1.12 中为 Java DataStream API 引入的。
批处理执行模式通过利用受限流的本质来绕过状态后端和检查点,从而简化了操作并提高了受限流上程序的性能。
Other improvements
Flink Documentation via Hugo
Flink 文档已从 Jekyll 迁移到 Hugo。如果您发现缺少的东西,请告诉我们。我们也很想知道您是否喜欢新的外观。
Exception histories in the Web UI
Flink Web UI 将显示最多 n 个导致作业失败的最后异常。这有助于调试根故障导致后续故障的方案。根源故障原因可以在异常历史记录中找到。
Better exception / failure-cause reporting for unsuccessful checkpoints
Flink 现在为失败或中止的检查点提供统计信息,从而使无需分析日志即可更轻松地确定失败原因。
仅在检查点成功的情况下,以前版本的 Flink 才报告指标(例如,持久数据的大小,触发时间)。
Exactly-once JDBC sink
从 1.13 开始,JDBC 接收器可以通过在检查点上事务性地提交结果,来保证一次准确地交付符合 XA 的数据库的结果。目标数据库必须具有(或链接到)XA 事务管理器。
该连接器当前仅适用于 DataStream API,并且可以通过 JdbcSink.exactlyOnceSink(...)方法(或直接实例化 JdbcXaSinkFunction)来创建。
PyFlink Table API supports User-Defined Aggregate Functions in Group Windows
PyFlink 的 Table API 中的 Group Windows 现在支持常规的 Python 用户定义的集合函数(UDAF)和 Pandas UDAF。这些功能对于许多分析和ML培训计划而言至关重要。
Flink 1.13 在以前的版本中进行了改进,以前的版本仅在无限制的 Group-by 聚合中支持这些功能。
Improved Sort-Merge Shuffle for Batch Execution
Flink 1.13 改进了批处理执行程序的内存稳定性和排序合并阻塞改组的性能,该程序最初是通过 FLIP-148 在 Flink 1.12 中引入的。
具有更高并行度(1000s)的程序不应再频繁触发 OutOfMemoryError:Direct Memory。通过更好的 I / O 调度和广播优化,可以提高性能(尤其是在旋转磁盘上)。
HBase connector supports async lookup and lookup cache
HBase 查找表源现在支持异步查找模式和查找缓存。通过针对 HBase 的查找联接,这极大地提高了表/ SQL作业的性能,同时在典型情况下减少了对 HBase 的 I / O 请求。
在以前的版本中,HBase 查找源仅同步通信,从而降低了管道利用率和吞吐量。
Changes to consider when upgrading to Flink 1.13
FLINK-21709 - The old planner of the Table & SQL API has been deprecated in Flink 1.13 and will be dropped in Flink 1.14. The Blink engine has been the default planner for some releases now and will be the only one going forward. That means that both the
BatchTableEnvironmentand SQL/DataSet interoperability are reaching the end of life. Please use the unifiedTableEnvironmentfor batch and stream processing going forward.FLINK-22352 The community decided to deprecate the Apache Mesos support for Apache Flink. It is subject to removal in the future. Users are encouraged to switch to a different resource manager.
FLINK-21935 - The
state.backend.asyncoption is deprecated. Snapshots are always asynchronous now (as they were by default before) and there is no option to configure a synchronous snapshot anymore.FLINK-17012 - The tasks’
RUNNINGstate was split into two states:INITIALIZINGandRUNNING. A task isINITIALIZINGwhile it loads the checkpointed state, and, in the case of unaligned checkpoints, until the checkpointed in-flight data has been recovered. This lets monitoring systems better determine when the tasks are really back to doing work by making the phase for state restoring explicit.FLINK-21698 - The CAST operation between the NUMERIC type and the TIMESTAMP type is problematic and therefore no longer supported: Statements like
CAST(numeric AS TIMESTAMP(3))will now fail. Please useTO_TIMESTAMP(FROM_UNIXTIME(numeric))instead.FLINK-22133 The unified source API for connectors has a minor breaking change: The
SplitEnumerator.snapshotState()method was adjusted to accept the Checkpoint ID of the checkpoint for which the snapshot is created.
Resources
现在,可以在 Flink 网站的更新的“下载”页面上找到二进制分发和源工件,并且可以在 PyPI 上获得 PyFlink 的最新分发。
如果您打算将安装程序升级到 Flink 1.13,请仔细阅读发行说明。此版本与以前的 1.x 版本的 API 兼容,这些版本的 API 使用 @Public 注释进行了注释。
您还可以查看完整的发行版变更日志和更新的文档,以获取变更和新功能的详细列表。
这次的版本更新带来了非常多的新特征,具体的改动可以查看官网,后面我也会针对新的功能做进一步的解析.
推荐阅读
Flink SQL 如何实现列转行?
Flink SQL 结合 HiveCatalog 使用
Flink SQL 解析嵌套的 JSON 数据
Flink SQL 中动态修改 DDL 的属性
Flink WindowAssigner 源码解析
Flink 1.11.x WatermarkStrategy 不兼容问题
Flink mysql-cdc connector 源码解析
Java SPI 机制在 Flink 中的应用(源码分析)

如果你觉得文章对你有帮助,麻烦点一下赞和在看吧,你的支持是我创作的最大动力.