最近大家应该刷到过“雷总”的语音视频了吧,这期内容与AI语音有关

今天来教大家如何快速制作这种音频,并送上几款模型,以后只要有新模型就会更新
~其实我想用雷总语音的,但是目前效果不是最好的,有机会的话,我自己训练一下~
老样子,我来简化所有步骤
一、下载程序整合包和模型包
~先介绍一下软件作者:B站[花儿不哭],同时也是RVC变声器的创始人;
下载方式:
该项目GitHub主页内文档里有下载地址项目名:[GPT-SoVITS];
目前程序最新版为 【GPT-SoVITS-v2-240821】
这个就是软件本体,
![]()
下载好后解压,打开 go-webui.bat 程序,出现一个cmd窗口,再等一会就会自己打开一个网页
![]()
以下就是成功进入到软件界面了
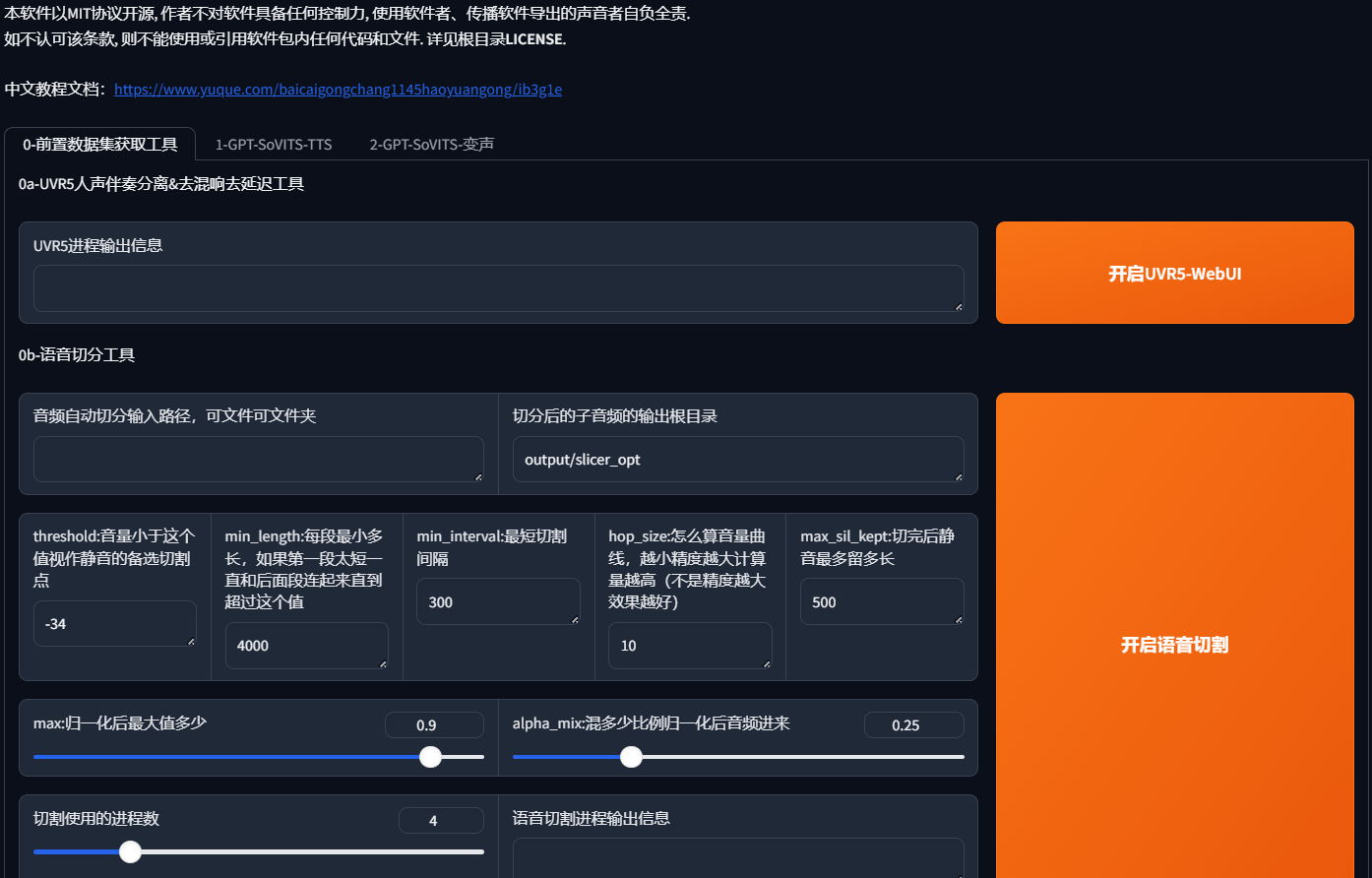
二、文本转语音
~设置模型和输入文本后即可输出语音~
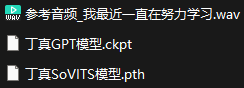
将下载的模型文件解压后,可以看到三个文件
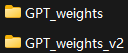
将.ckpt文件放入 GPT_weights_v2文件夹(也可以放进GPT_weights,放_v2是因为我默认它向下兼容了,但是它还是创建了两个文件夹,这个争论等我明确后再来修改)
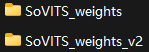
将.pth文件放入 SoVITS_weights_v2文件夹
2. 点击 1-GPT-SoVITS-TTS,点击1C-推理,点击刷新模型路径,选择你新添加的.ckpt和.pth模型;

此处的 启用并行推理版本(推理速度更快) 按照需求选择,建议打开;
![]()
3. 点击 开启TTS推理WebUI,等待片刻会打开一个新的网页;
4. 导入 参考音频 参考音频_我最近一直在努力学习.wav;
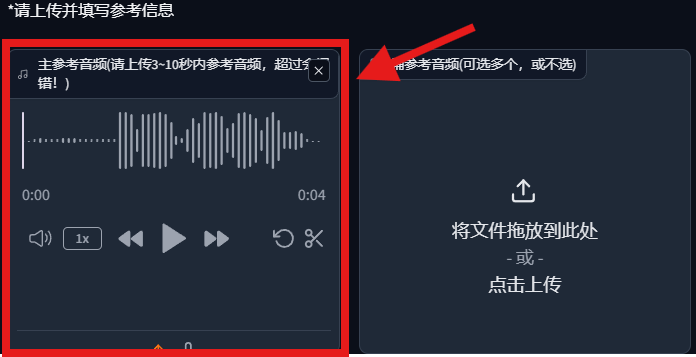
5.填写主参考音频的文本;

6.填写 需要合成的文本,最后点击 合成语音;

三、提升环节
~一些使用技巧~
1.如果你的文本是中文加英文的混合形式,需要更改 需要合成的文本的语种 设置;
2.如果你的文本太长,那么有些时候合成的语音里会漏掉某些语句,此时需要用到文本切分工具,也就是快速帮你换行,之后复制粘贴到 需要合成的文本;
至此,你已经学会了如何使用本软件了,快去试一试吧。
对了,电脑配置是有要求的,至少需要6G以上独立显卡;
本期软件序列号:
【24A01】
模型资源上传到CSDN了,大家可以试一试