C++第八讲:STL--stack和queue的使用及模拟实现
1.stack的使用2.queue的使用3.栈和队列OJ题3.1题目1:最小栈3.2题目2:栈的压入、弹出序列3.3题目3:逆波兰表达式求值3.4题目4:用栈实现队列 4.栈的模拟实现5.队列的模拟实现6.deque6.1什么是deque6.2deque的底层实现6.3deque迭代器的讲解6.4库中deque实现细节 7.prioriry_queue的介绍和使用7.1什么是priority_queue7.2在OJ题中的使用7.3priority_queue的模拟实现7.3.1仿函数7.3.1.1仿函数的其它应用场景
1.stack的使用
有了前面的基础之后,栈和队列的使用都很简单,而且其中的接口我们在数据结构中都实现过,所以我们直接看一遍即可:
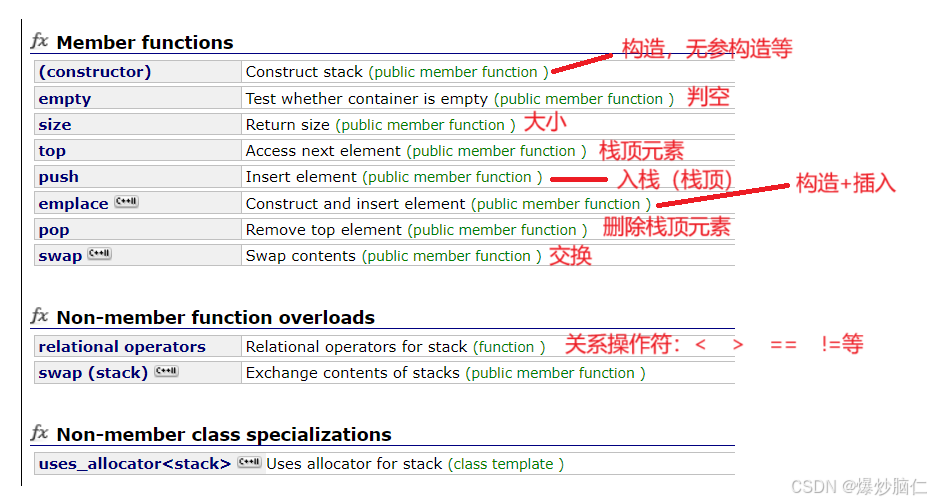
不同的是,栈中没有实现迭代器,这其实与栈和队列的实现有关:

那么它的访问方式只有循环出栈和获取栈顶元素:
#include <stack>int main(){ stack<string> s1; s1.emplace("hello world!"); s1.emplace("Xxxxxxxxxxxxx"); while (!s1.empty()) { cout << s1.top(); s1.pop(); } cout << endl;//Xxxxxxxxxxxxxhello world! cout << s1.empty() << endl;//1,表示此时栈为空 return 0;}2.queue的使用
queue的使用和stack相同,这里不再看:
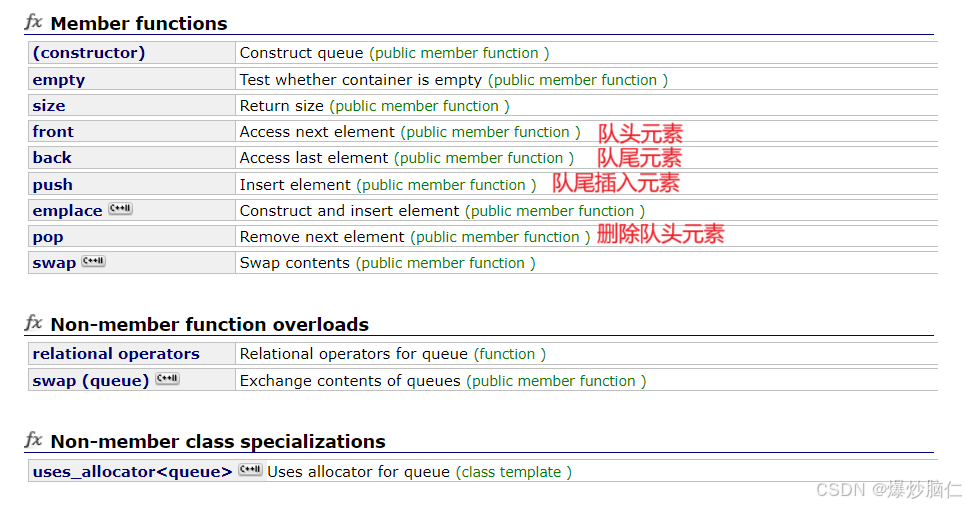
#include <queue>int main(){ queue<string> q1; q1.emplace("hello world!"); q1.emplace("Xxxxxxxxxxxx"); while (!q1.empty()) { cout << q1.front(); q1.pop(); } cout << endl;//hello world!Xxxxxxxxxxxx cout << q1.empty() << endl;//1,表示队列为空 return 0;}3.栈和队列OJ题
3.1题目1:最小栈
链接: 最小栈

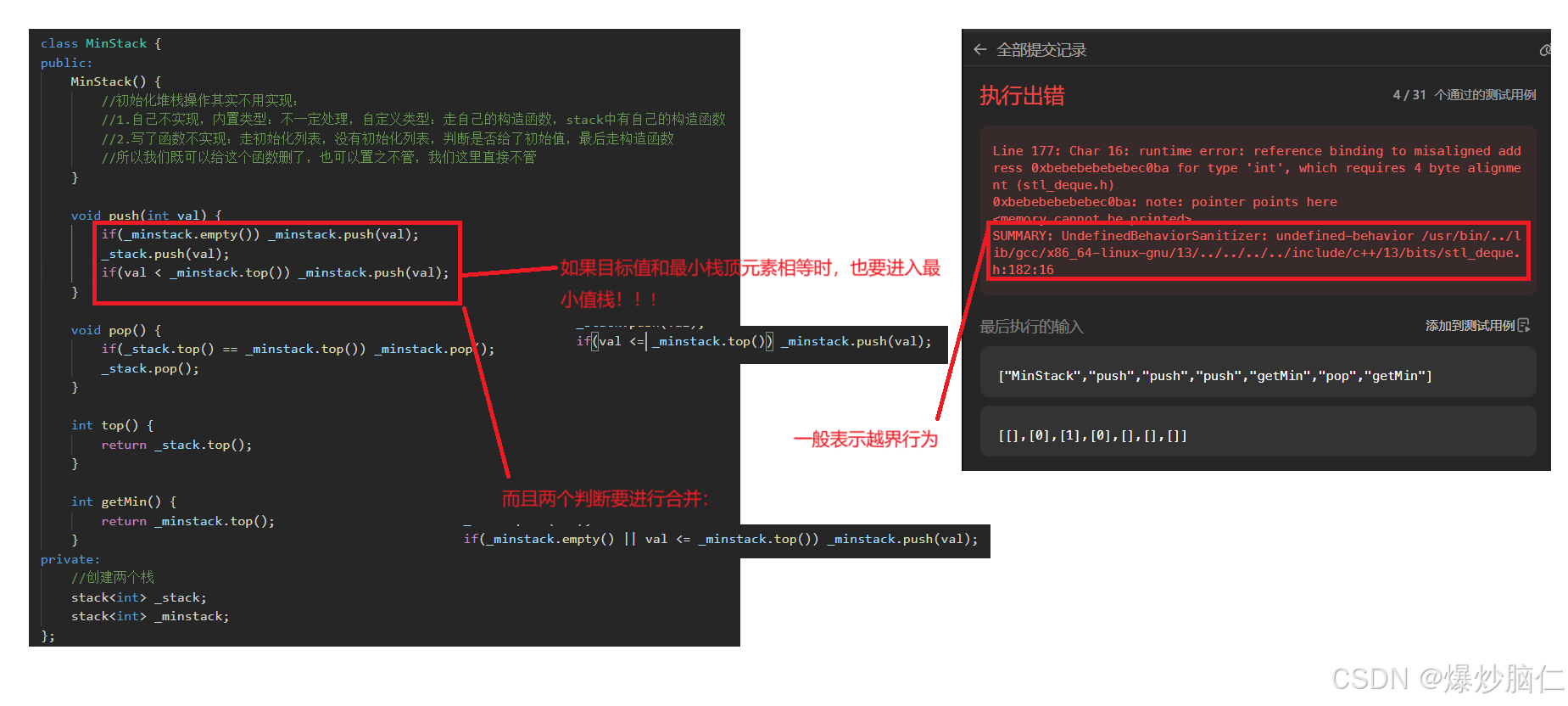
class MinStack {public: MinStack() { //初始化堆栈操作其实不用实现: //1.自己不实现,内置类型:不一定处理,自定义类型:走自己的构造函数,stack中有自己的构造函数 //2.写了函数不实现:走初始化列表,没有初始化列表,判断是否给了初始值,最后走构造函数 //所以我们既可以给这个函数删了,也可以置之不管,我们这里直接不管 } void push(int val) { _stack.push(val); if(_minstack.empty() || val <= _minstack.top()) _minstack.push(val); } void pop() { if(_stack.top() == _minstack.top()) _minstack.pop(); _stack.pop(); } int top() { return _stack.top(); } int getMin() { return _minstack.top(); }private: //创建两个栈 stack<int> _stack; stack<int> _minstack;};3.2题目2:栈的压入、弹出序列
链接: 栈的压入、弹出序列
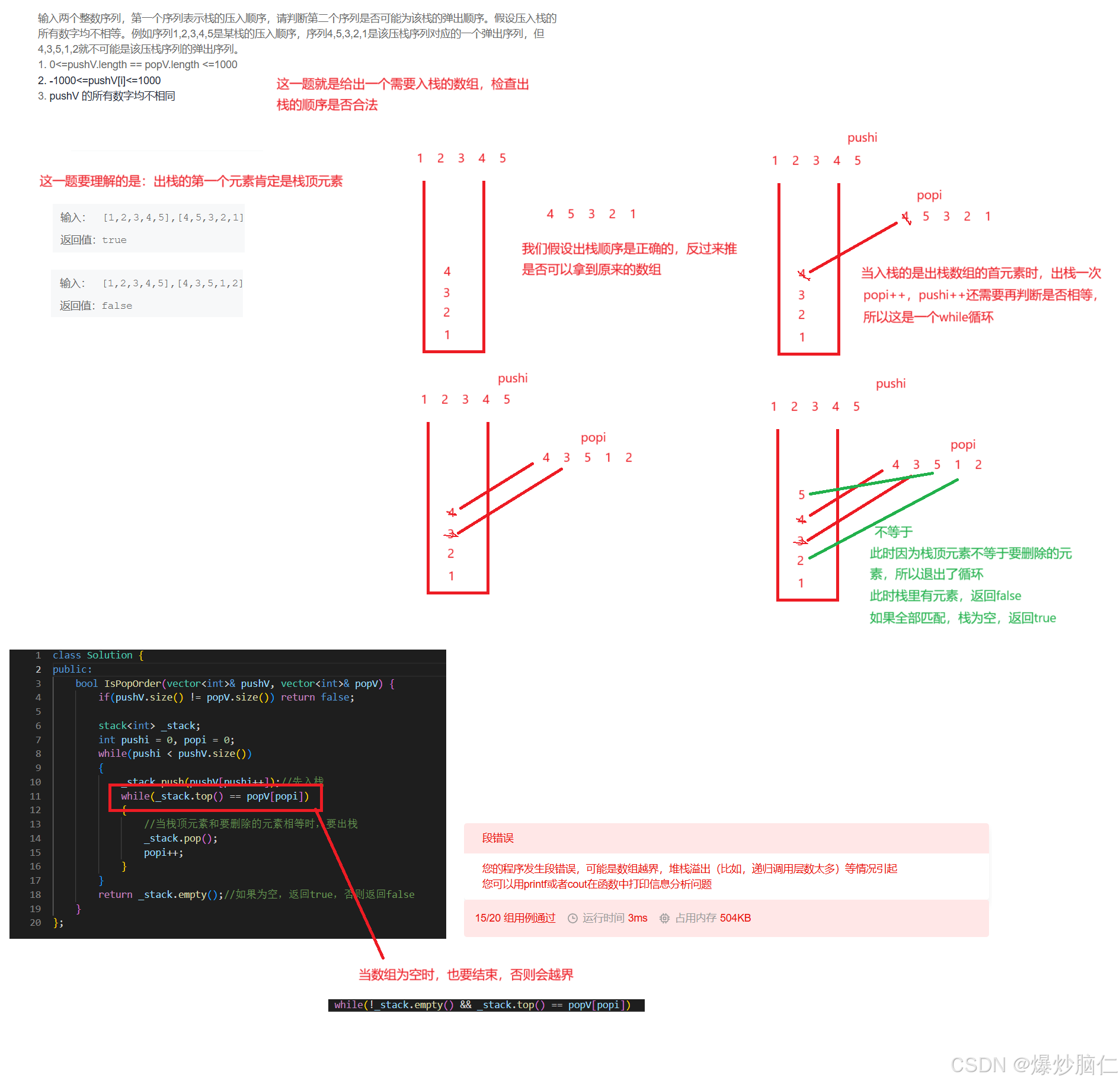
class Solution {public: bool IsPopOrder(vector<int>& pushV, vector<int>& popV) { if(pushV.size() != popV.size()) return false; stack<int> _stack; int pushi = 0, popi = 0; while(pushi < pushV.size()) { _stack.push(pushV[pushi++]);//先入栈 while(!_stack.empty() && _stack.top() == popV[popi]) { //当栈顶元素和要删除的元素相等时,要出栈 _stack.pop(); popi++; } } return _stack.empty();//如果为空,返回true,否则返回false }};3.3题目3:逆波兰表达式求值
链接: 逆波兰表达式求值
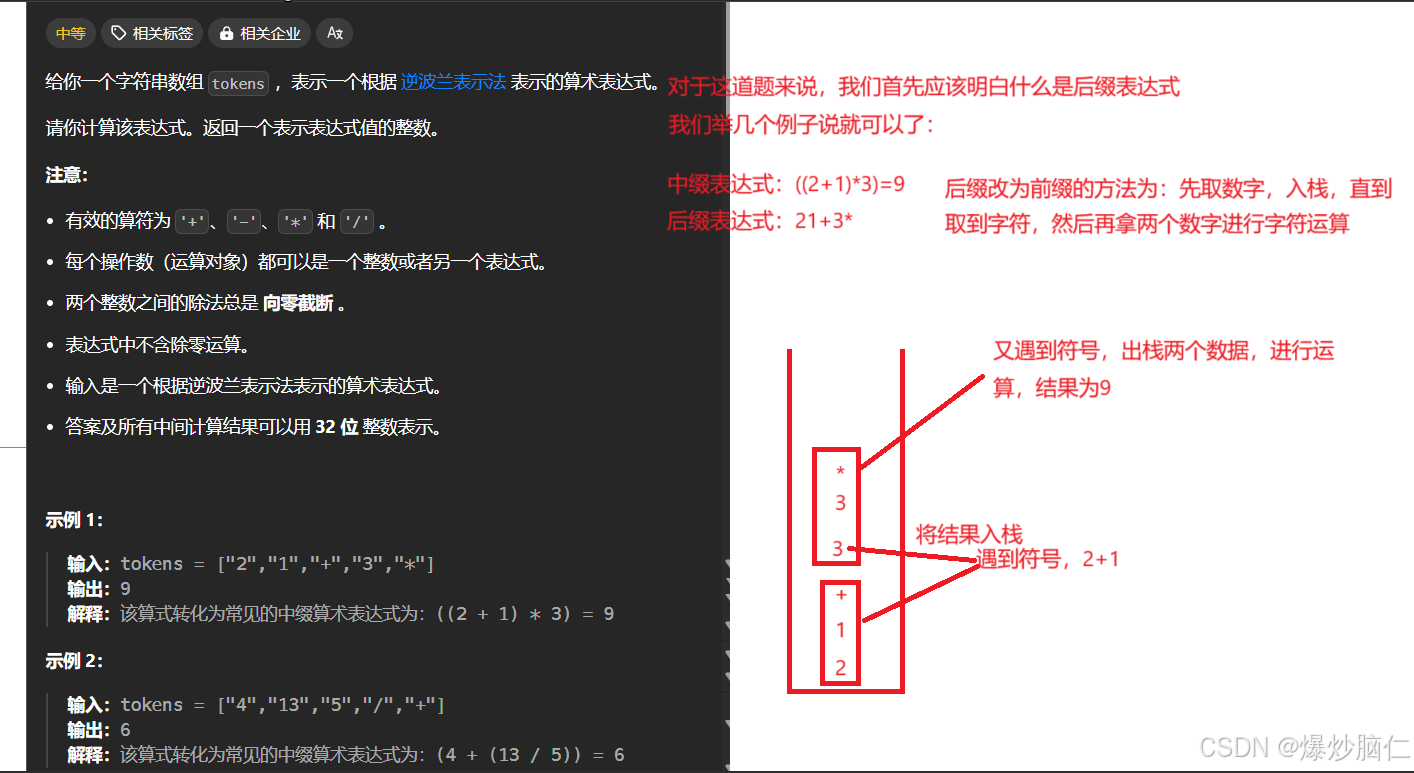
class Solution {public: int evalRPN(vector<string>& tokens) { //首先要先取值入栈 stack<int> s1; for(int i = 0; i<tokens.size(); i++) { string& s = tokens[i]; //枚举数字很困难,那么我们就枚举符号 //s是string类型,而s[0]是第一个字符 if(s == "+" || s == "-" || s == "*" || s == "/") { //是字符的话,就拿两个数据进行运算 int right = s1.top(); s1.pop(); int left = s1.top(); s1.pop(); switch(s[0]) { case '+': s1.push(left + right); break;//注意break别忘记写了 case '-': s1.push(left - right); break; case '*': s1.push(left * right); break; case '/': s1.push(left / right); break; } } else { //是数字,就入栈 s1.push(atoi(s.c_str())); } } return s1.top(); }};3.4题目4:用栈实现队列
链接: link

class MyQueue {public: MyQueue() { } void push(int x) { //入队列就是直接向入栈中插入数据 Push.push(x); } int pop() { //如果出栈中有数据,直接出栈,否则,先入栈,再出栈 if(Pop.empty()) { while(!Push.empty()) { Pop.push(Push.top()); Push.pop(); } } int ret = Pop.top(); Pop.pop(); return ret; } int peek() { if(Pop.empty()) { while(!Push.empty()) { Pop.push(Push.top()); Push.pop(); } } return Pop.top(); } bool empty() { return Push.empty() && Pop.empty(); }private: //应该是要两个栈,一个是入栈,一个是出栈 stack<int> Push; stack<int> Pop;};4.栈的模拟实现
栈的实现较为简单,我们直接来看:
//栈的模拟实现1.我们可以按照之前数据结构讲的那样,开辟数组来实现栈//template<class T>//class Stack//{//private://T* _a;//size_t _top;//size_t _capacity;//};//但是库中的栈并不是这样实现的,而是使用了一个适配器:namespace Mine{template<class T, class container>class Stack{public://入栈void push(const T& x){_con.push_back(x);//因为使用了之前我们用过的容器来实例化栈,所以我们可以直接使用容器的函数来实现栈!}//出栈void pop(){_con.pop_back();}//获取栈顶元素const T& top() const{return _con.back();}//栈中的数个数size_t size() const{return _con.size();}//判空bool empty() const{return _con.empty();}private:container _con;//这时我们可以直接使用容器来创建一个对象};}///#include "Stack.h"int main(){Mine::Stack<int, vector<int>> s1;s1.push(1);s1.push(2);s1.push(3);while (!s1.empty()){cout << s1.top() << " ";s1.pop();}cout << endl << s1.size();//3 2 1 0(size)return 0;}但是我们可能会有疑惑:为什么我们可以直接使用到std中的stack以及它的函数呢?因为:using namespace std;我们在一开始就已经展开了,如果我们不展开的话,还要加上std::,如果展开在#include "Stack.h"后面,也是没有问题的,因为stack是模板参数,当实例化时才会进行错误的检查
5.队列的模拟实现
队列的实现也比较简单,我们直接看即可:
//队列的模拟实现//队列的实现也是这样:namespace Mine{//在模板定义时可以直接为模板参数赋初始值template <class T, class container = list<int>>class Queue{public://入队列void push(const T& x){_con.push_back(x);}//出队列void pop(){//对于vector来说,它没有相应的头删函数,因为头删的消耗太大了,所以容器不能够使用vector_con.pop_front();}//获取队头元素const T& front() const{return _con.front();}//获取队尾元素const T& back() const{return _con.back();}//队列大小size_t size() const{return _con.size();}//队列判空bool empty() const{return _con.empty();}private:container _con;};}/#include <list>#include "Queue.h"int main(){Mine::Queue<int, list<int>> q1;q1.push(1);q1.push(2);q1.push(3);while (!q1.empty()){cout << q1.front() << " ";q1.pop();}cout << endl;//1 2 3return 0;}6.deque
上面我们已经实现了栈和队列,但是我们看库中的栈和队列时,会发现:

库中实现的栈和队列的适配器传入的都是一个叫deque的容器,那么这个容器究竟是什么呢?这个容器的底层实现是什么呢?:
6.1什么是deque

我们可以看一下deque实现的功能:

6.2deque的底层实现
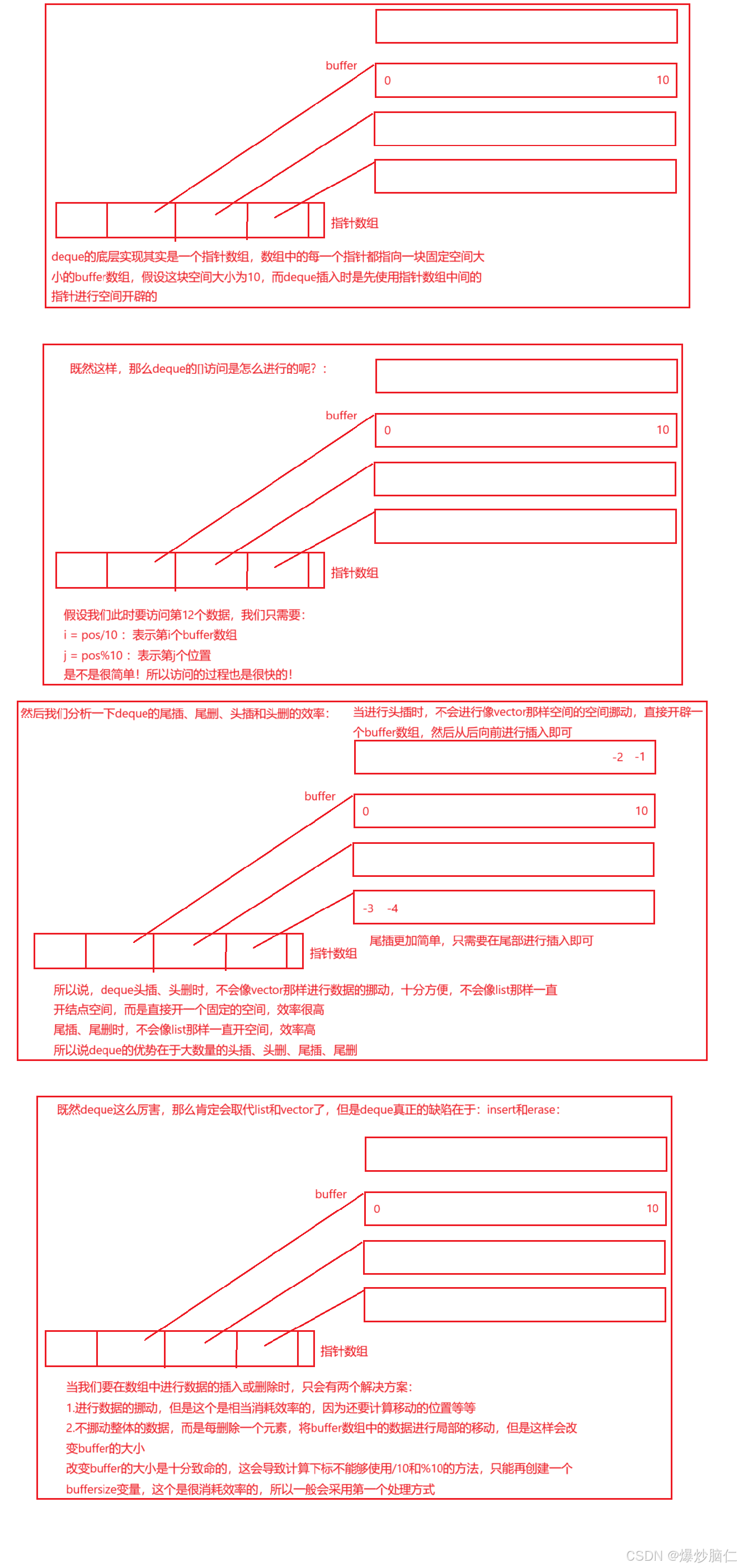
所以说deque的缺陷在于[]访问这里,通过代码验证可知,在对10000个数据进行排序时,使用vector比使用deque快将近两倍多,而且如果将deque中的数据拷贝到vector中进行排序,排序之后再拷贝过来的效率也要比单独在deque中进行排序快两倍左右!
所以deque的访问是一个大问题,而拷贝其实是不怎么消耗时间的
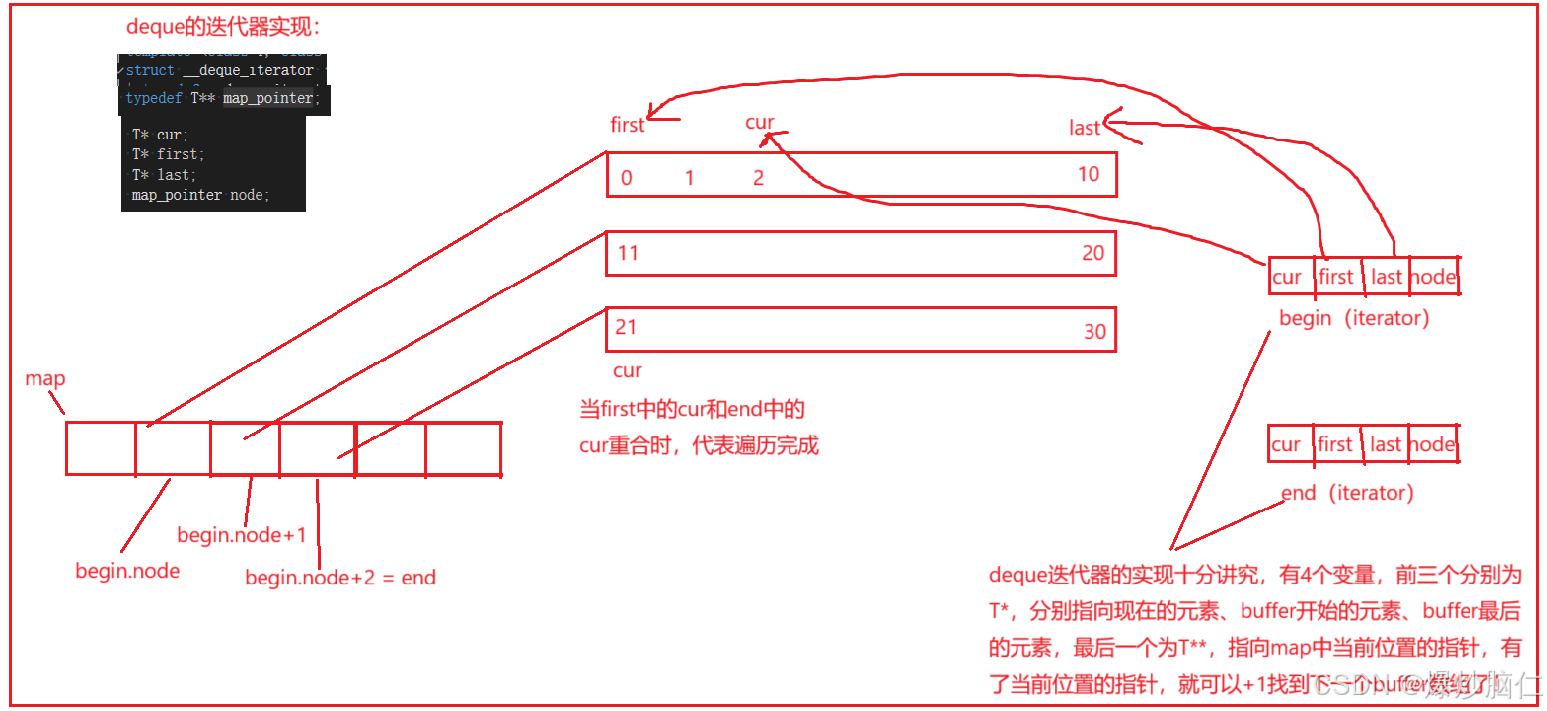
6.3deque迭代器的讲解
所以说,对于栈和队列那种不经常插入删除的容器来说,使用deque是再好不过的了
下面我们来看一下deque的迭代器是怎么实现的:
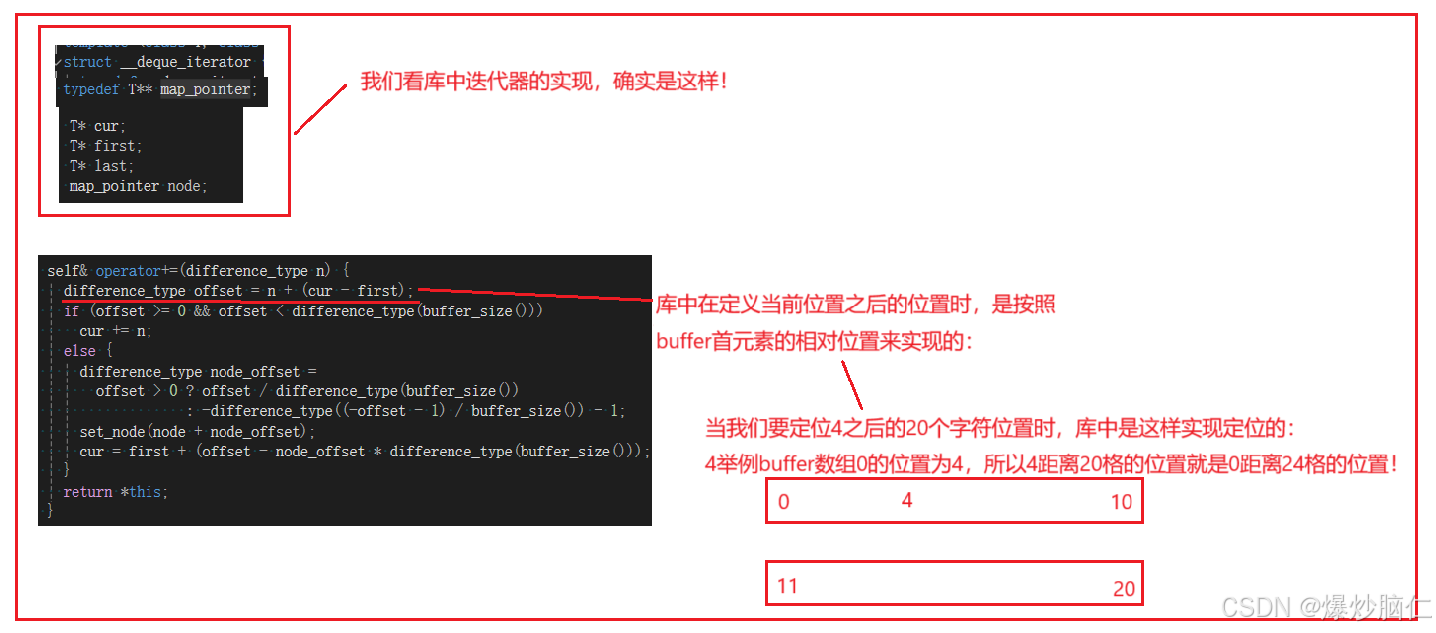
6.4库中deque实现细节
7.prioriry_queue的介绍和使用
7.1什么是priority_queue

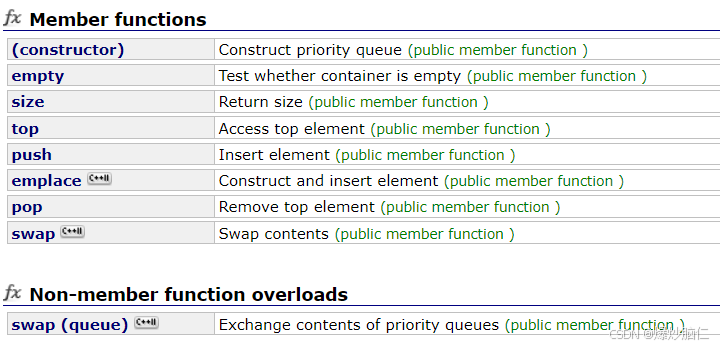
翻译为优先级队列,包含在queue头文件中,可以按照数据的优先级对数据进行排序,默认是较大值,它的第一个元素总是大于它所包含的其它元素,它的使用如下:
int main(){priority_queue<int> pq1;pq1.push(5);pq1.push(1);pq1.push(2);pq1.push(9);//默认是按照大的优先级排列while (!pq1.empty()){cout << pq1.top() << " ";pq1.pop();}cout << endl;//9 5 2 1return 0;}我们看到这个是不是感觉很熟悉,那就是堆,大堆、小堆和这个相似,所以我们可以使用堆的方法来实现这个容器
int main(){//如果我们想要让小的数据优先级高,需要这样使用://priority_queue<int, vector<int>, less<int>> pq1;priority_queue<int, vector<int>, greater<int>> pq1;pq1.push(5);pq1.push(1);pq1.push(2);pq1.push(9);while (!pq1.empty()){cout << pq1.top() << " ";pq1.pop();}cout << endl;//1 2 5 9return 0;}7.2在OJ题中的使用
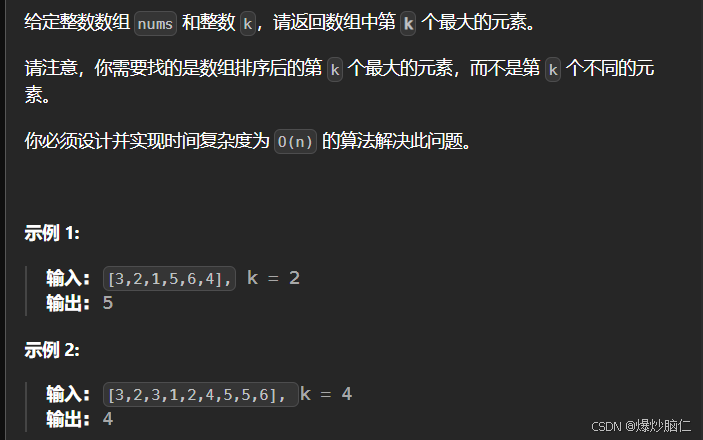
链接: 数组中的第k个最大元素
有了这个容器,该题目实现起来很简单:
class Solution {public: int findKthLargest(vector<int>& nums, int k) { priority_queue<int> pq1; //先插入数据 for(int i = 0; i<nums.size(); i++) { pq1.push(nums[i]); } while(--k)//再将k前边的数据进行删除 { pq1.pop(); } return pq1.top();//最后只剩下数据k了,直接返回 }};7.3priority_queue的模拟实现
模拟实现需要使用堆中的算法,所以需要先进行复习:
链接: link
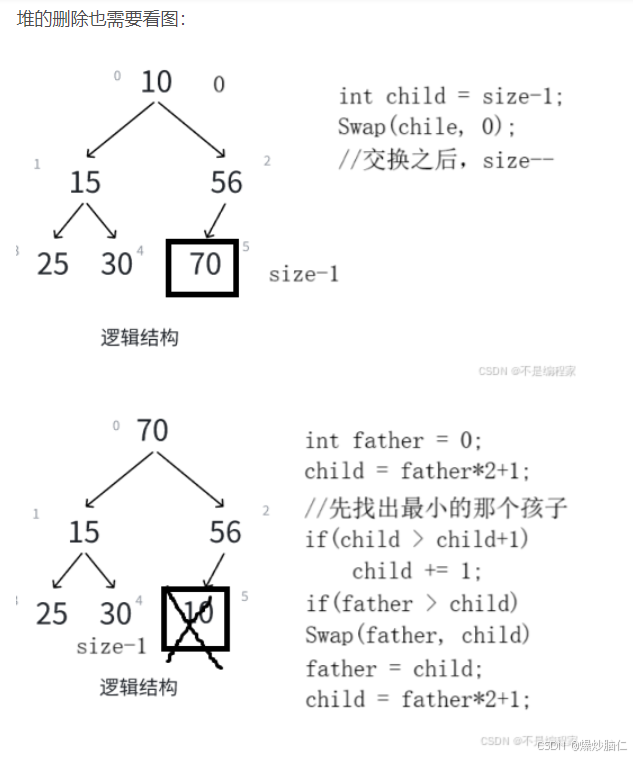
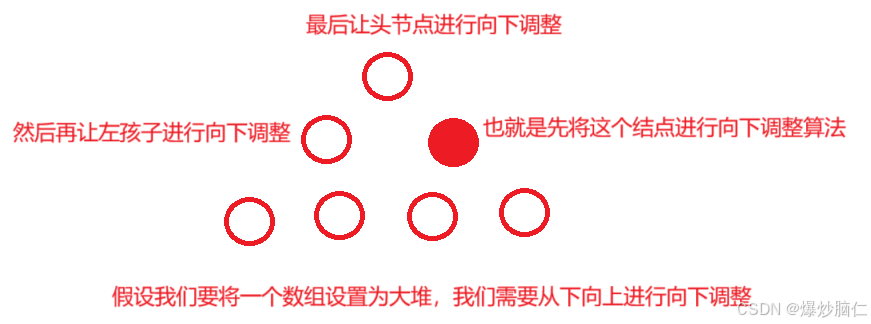
向上调整算法:
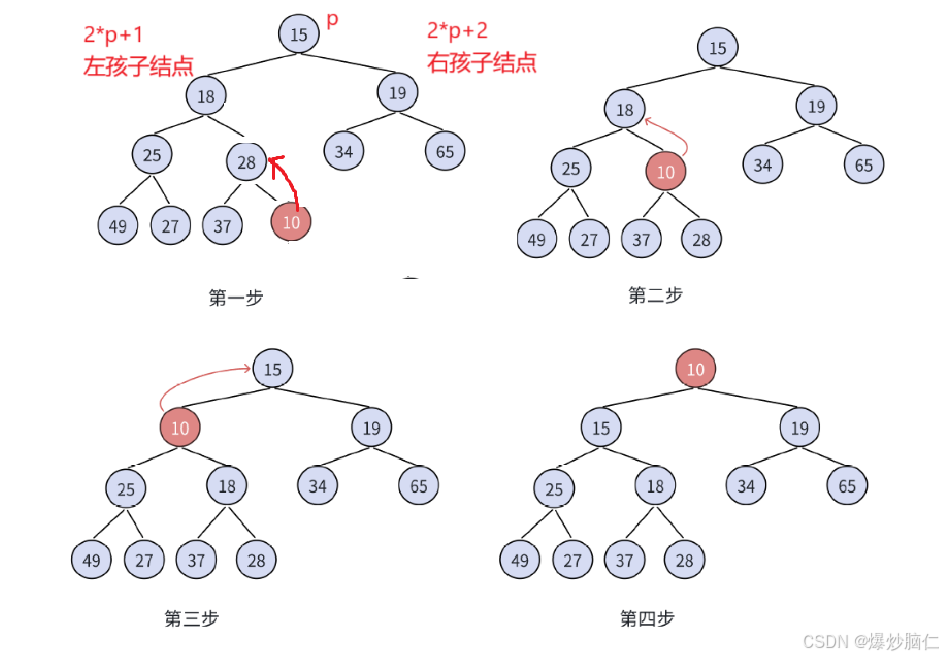
上面的图是按照小的优先级高来画的,但是默认是大的优先级大,但是实现思路相同
7.3.1仿函数
我们先实现一下优先级队列的迭代器区间构造:
//迭代器区间构造template<class Inputiterator>priority_queue(Inputiterator begin, Inputiterator end):_con(begin, end){//迭代器区间插入之后,要将_con设置成为大堆for (int i = (_con.size()-1-1)/2; i >= 0; i--){AdjustDown(i);}}int main(){int a[] = { 1, 5, 3, 9, 7 };//Mine::priority_queue<int> pq(a, a+sizeof(a)/sizeof(int));Mine::priority_queue<int> pq;//err:没有合适的默认构造可用while (!pq.empty()){cout << pq.top() << " ";pq.pop();}cout << endl;return 0;}当我们不写默认构造的话,编译器会自己提供一个默认构造,但是这里我们写了默认构造,但是不想写_con,也就是容器适配器(vector)的默认构造,有没有什么办法?:
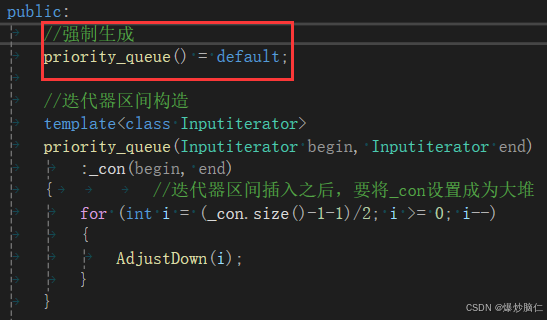
这需要写这个就可以强制生成一个默认构造来使用
但是我们知道,库中的优先级队列的实现可以通过传入greater或less参数来实现优先级的更改的,那么我们如何实现这个操作呢?这时候就要看仿函数这个概念了:
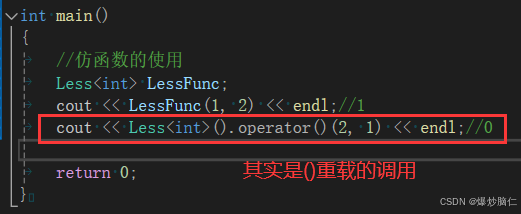
template<class T>struct Less{bool operator()(const T& x, const T& y) const{return x < y;}};template<class T>struct Greater{bool operator()(const T& x, const T& y) const{return x > y;}};int main(){//仿函数的使用Less<int> LessFunc;cout << LessFunc(1, 2) << endl;//1//如果我们只看LessFunc(1, 2)这个的话,很想一个函数调用,所以被称为仿函数return 0;}可以看出,仿函数的使用还是很简单的,而仿函数调用的原理其实是:
仿函数在我们实现的优先级队列中的应用为:
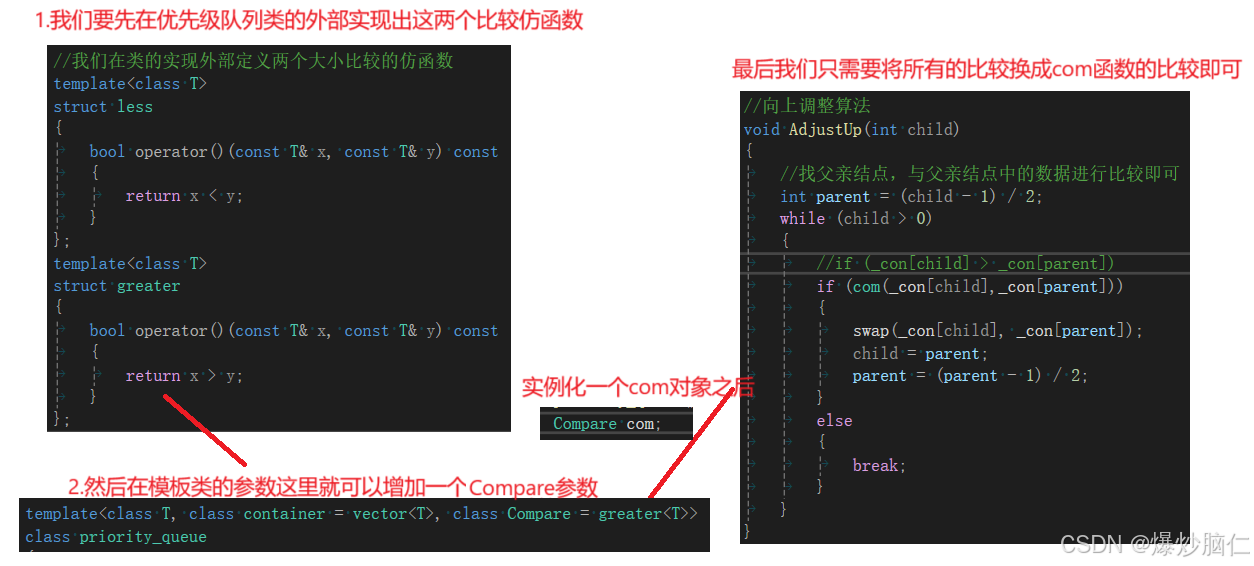
但是库中在实现优先级队列时,传入的是less,创建的是大堆,传入的是greater,创建的是小堆,所以我们也要做一下更改:

7.3.1.1仿函数的其它应用场景
//假设我们实现了一个日期类,其中实现了日期类的传参构造,>和<的比较,以及流插入的重载class Date{public:Date(int year = 1900, int month = 1, int day = 1): _year(year), _month(month), _day(day){}bool operator<(const Date& d)const{return (_year < d._year) ||(_year == d._year && _month < d._month) ||(_year == d._year && _month == d._month && _day < d._day);}bool operator>(const Date& d)const{return (_year > d._year) ||(_year == d._year && _month > d._month) ||(_year == d._year && _month == d._month && _day > d._day);}friend ostream& operator<<(ostream& _cout, const Date& d);private:int _year;int _month;int _day;};ostream& operator<<(ostream& _cout, const Date& d){_cout << d._year << "-" << d._month << "-" << d._day;return _cout;}int main(){Mine::priority_queue<Date> q1;q1.push({ 2024, 10, 23 });q1.push({ 2024, 5, 27 });q1.push({ 2024, 11, 2 });while (!q1.empty()){cout << q1.top() << " ";q1.pop();}cout << endl;return 0;}这里我们可以看到,该程序成功实现了我们的需求,但是我们这样改一下:
int main(){//这里传入的参数为Date*类型Mine::priority_queue<Date*> q1;q1.push(new Date{ 2024, 10, 23 });q1.push(new Date{ 2024, 5, 27 });q1.push(new Date{ 2024, 11, 2 });while (!q1.empty()){cout << *q1.top() << " ";q1.pop();}cout << endl;return 0;}
这时我们看到,因为传入的是地址,而地址在new开辟时是不确定的,所以通过比较地址大小来排序是完全不行的,谁最大都有可能出现,所以我们要解决这个问题:
struct Dateless{bool operator()(const Date* d1, const Date* d2) const{return *d1 < *d2;}};struct Dategreater{bool operator()(const Date* d1, const Date* d2) const{return *d1 > *d2;}};int main(){//Mine::priority_queue<Date*> q1;Mine::priority_queue<Date*, vector<Date*>, Dateless> q1;q1.push(new Date{ 2024, 10, 23 });q1.push(new Date{ 2024, 5, 27 });q1.push(new Date{ 2024, 11, 2 });while (!q1.empty()){cout << *q1.top() << " ";q1.pop();}cout << endl;return 0;}可以看出,我们的解决方法为:再写出两个比较的类进行传入,如果我们需要比较的是两个指针的话,那么走的就是这个解引用的函数,所以仿函数的优点在于:如果库中不支持这个比较,而且我们访问不到这个类时,我们就可以自己写一个仿函数,实现我们想要的需求,但是如果我们不像每次比较时都要传参的话要怎么办呢?:这个之后会讲到!
我们现在还要看的一个是sort的传参和模板参数的问题:
