AIGC实战——生成式人工智能总结与展望
0. 前言1. 生成式人工智能发展历程1.1 VAE 和 GAN 时代1.2 Transformer 时代1.3 大模型时代 2. 生成式 AI 的当前进展2.1 大语言模型2.2 文本生成代码模型2.3 文本生成图像模型2.4 其他应用 3. 生成式人工智能发展展望3.1 生成式 AI 在工作场所中的应用3.2 生成式AI在教育中的应用4. 生成式 AI 伦理与挑战 总结系列链接
0. 前言
近年来,生成模型取得了突破性进展,生成式人工智能拥有了无限可能性和潜在影响,有着无限的实际应用潜力,我们期待着生成式人工智能够产生更广泛的影响。生成模型领域不仅仅是关于创建图像、文本或音乐的应用,而且生成式深度学习隐藏着人工智能的本质。在本节中,将概述生成式人工智能的发展历史,然后探讨生成式人工智能面临的机遇和挑战,介绍可能的发展方向,以及它对社会的潜在影响,并解决主要的伦理和实践问题。
1. 生成式人工智能发展历程
下图中给出了的生成建模的主要模型,不同的类型的模型用不同的颜色表示。
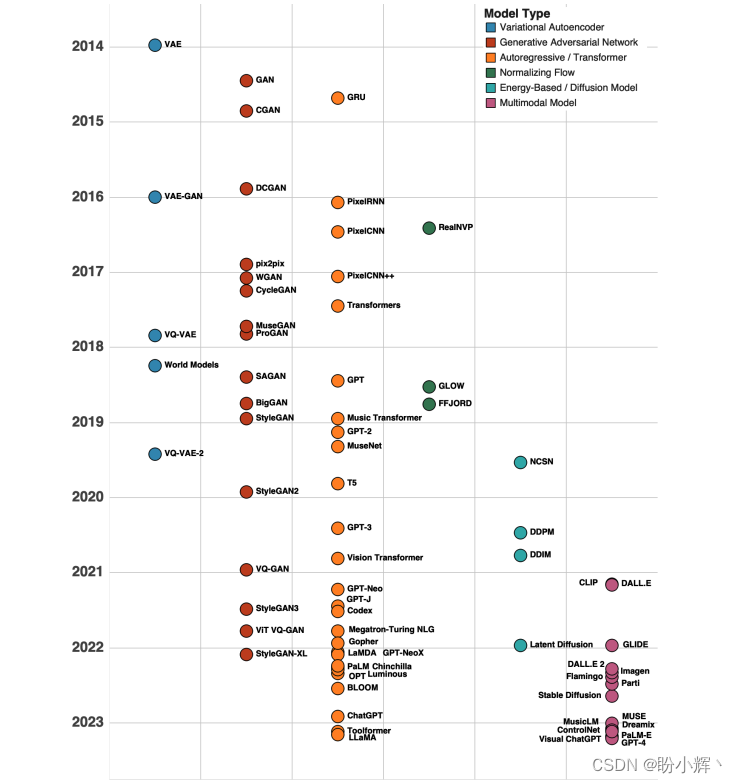
生成式人工智能领域建立在深度学习的发展基础上,例如反向传播和卷积神经网络,这些方法使模型能够在大规模数据集上学习复杂关系。在本节中,我们将了解从 2014 年开始的生成式人工智能发展历史。我们可以将生成式人工智能的发展历史大致分为三个主要时代:
2014 年至 2017 年:VAE 和 GAN 时代2018 年至 2019 年:Transformer 时代2020年至今:大模型时代 1.1 VAE 和 GAN 时代
2013 年底提出的变分自编码器 (Variational Autoencoder, VAE) 可以说是点燃生成式人工智能 (Artificial Intelligence, AI) 火花。VAE 不仅能够生成简单图像(例如 MNIST 数据集中的数字),还能生成更复杂的图像(比如脸部图像),而且这些图像可以在一个连续的潜空间中平滑地遍历。紧随其后,2014 年引入了生成对抗网络 (Generative Adversarial Network, GAN),这是一种用于解决生成模型问题的全新框架。
接下来的三年,GAN 领域呈现出夺目的进展。除了对 GAN 模型架构(如 DCGAN)、损失函数(如 Wasserstein GAN )和训练过程(如 ProGAN )进行改进外,还将 GAN 还应用于多个领域,比如图像转换(例如 pix2pix 和 CycleGAN )和音乐生成(例如 MuseGAN)等。同时,研究人员也对 VAE 进行了许多重要改进,比如 VAE-GAN 和 VQ-VAE,并且在 “World Models” 中还将其应用于强化学习。
在这一阶段里,长短期记忆网络 (Long Short-Term Memory Network, LSTM) 和门控循环单元等传统自回归模型仍然是文本生成的主流力量。同时,也有研究人员将这些自回归思想应用于图像生成,提出了 PixelRNN 和 PixelCNN 作为图像生成的新思路。此外,也提出了一些其他图像生成方法,比如 RealNVP 模型,为后续各种归一化流模型的发展奠定了基础。
1.2 Transformer 时代
2017 年 6 月,《Attention Is All You Need》 论文发发表,标志着 Transformer 时代的开始。
Transformer 的核心是注意力机制,它消除了自回归模型中对循环层的依赖。Transformer 凭借 GPT (仅有解码器的 Transformer )和 BERT (仅有编码器的 Transformer )的引入迅速得到关注。接下来的一年中,通过将各种任务视为纯文本生成问题,逐渐构建了越来越大的语言模型,这些模型在各种任务上表现出色,其中包括 GPT-2 和 T5 等优秀模型。Transformer 也开始成功应用于音乐生成,例如 Music Transformer和 MuseNet 模型的引入。
在这两年中,还发布了几个优秀的 GAN 模型,巩固了 GAN 在图像生成领域的地位。包括 SAGAN 和规模更大的 BigGAN 将注意力机制引入 GAN 框架,取得了惊人的效果;而 StyleGAN 和 StyleGAN2 展示了如何细粒度控制生成图像的风格和内容。
此外,另一类生成式人工智能领域也开始逐渐发展,即基于分数的模型,它为生成式人工智能领域的下一个重大变革——扩散模型奠定了基础。
1.3 大模型时代
大模型时代,许多模型将不同类型的生成模型的思想结合起来,为现有的架构注入了强大动力。例如,VQ-GAN 将 GAN 鉴别器引入了 VQ-VAE 架构中,而 Vision Transformer 展示了如何训练 Transformer 来处理图像。2022 年发布了 StyleGAN-XL,是 StyleGAN 架构的进一步改进,可以生成 1024 × 1024 像素的图像。
2020 年提出的两个模型为所有图像生成大模型奠定了基础:DDPM 和 DDIM。扩散模型成为在生成图像质量上能够与 GAN 相抗衡的对手。扩散模型的图像质量非常出色,并且只需要训练一个 U-Net 网络,而不需要 GAN 的双网络设置,使得训练过程更加稳定。
与此同时,GPT-3 发布了,这是一个拥有 1750 亿参数的庞大的 Transformer,可以生成几乎任何主题的文本。该模型通过 Web 应用程序和 API 发布,用户可以在其之上构建产品和服务。ChatGPT 便是 OpenAI 最新版本 GPT 的一个 Web 应用程序和 API 封装,允许用户与 AI 就任何主题进行对话。
在 2021 年和 2022 年,一系列大语言模型被提出,包括 Megatron-Turing NLG,Gopher、Chinchilla,LaMDA、PaLM,以及 Luminous。除了上述模型外,研究人员还发布了一些开源模型,如 GPT-Neo、GPT-NeoX,Flan-T5 和 BLOOM 等。这些模型都是基于 Transformer 的变体,并使用大规模数据集进行训练。
用于文本生成的 Transformer 模型和用于图像生成的扩散模型的迅速崛起意味着,生成式 AI 的发展开始逐步聚焦于多模态模型上,即在多个域(例如文本生成图像模型)上运行的模型。
这一趋势始于 2021 年,OpenAI 提出了 DALL.E,一个基于离散 VAE (类似于 VQ-VAE )和 CLIP (一种预测图像/文本对的 Transformer 模型)的文本生成图像模型。之后又提出了 GLIDE 和 DALL.E 2,更新了模型的生成部分,使用扩散模型替代离散 VAE,取得了惊人的性能表现。另外,Google 还提出了三个文本生成图像模型:Imagen (使用 Transformer 和扩散模型)、Parti (使用 Transformers 和 ViT-VQGAN 模型)以及 MUSE (使用 Transformers 和 VQ-GANs)。DeepMind 还提出了 Flamingo 模型,这是一个基于大语言模型 Chinchilla 的视觉语言模型,其允许使用图像作为提示数据的一部分。
扩散模型的另一项重要进展是潜扩散,即在自编码器的潜在空间内训练扩散模型,这项技术成为构建 Stable Diffusion 模型的基础。与 DALL.E 2、Imagen 和 Flamingo 不同,Stable Diffusion 的代码和模型权重是开源的,任何人都可以在本地设备上运行该模型。
2. 生成式 AI 的当前进展
接下来,我们介绍生成式人工智能迄今为止的进展和主要成就。
2.1 大语言模型
生成文本的 AI 现在几乎完全专注于构建大语言模型 (Large Language Model, LLM),这些模型的目的是直接对来自大规模文本语料库的语言进行建模,训练大模型用于预测下一个单词,类似解码器 Transformer。
大语言模型方法之所以被广泛采用,是由于大语言模型的灵活性和优异的表现性能。同一个模型可以用于问答、文本摘要、内容创作等多种场景,因为每个应用本质上都可以看作是文本到文本问题,其中具体的任务指令(提示)作为模型输入的一部分给出。
需要注意的是,无论是在文本摘要还是内容创作应用总,提示中都包含了相关的指令。GPT-3 的任务只是逐符号地续写提示。它并没有可以查找信息的数据库,也没有可以复制到答案中的文本片段。模型仅仅需要预测接下来最可能出现在现有符号后的新符号,并将这个预测附加到提示后以生成下一个符号,以此类推。这一简单的设计足以使语言模型在各种任务上表现出色。此外,它赋予了语言模型极大的灵活性,以对任意提示生成逼真的预测文本。
下图展示了自 2018 年发布原始 GPT 模型以来,大语言模型的规模的增长情况。参数量一直呈指数级增长,到 2021 年底,Megatron-Turing NLG 拥有 5300 亿个参数。近来,研究人员开始构建使用较少参数的高效语言模型,因为更大的模型在生产环境中运行速度较慢。
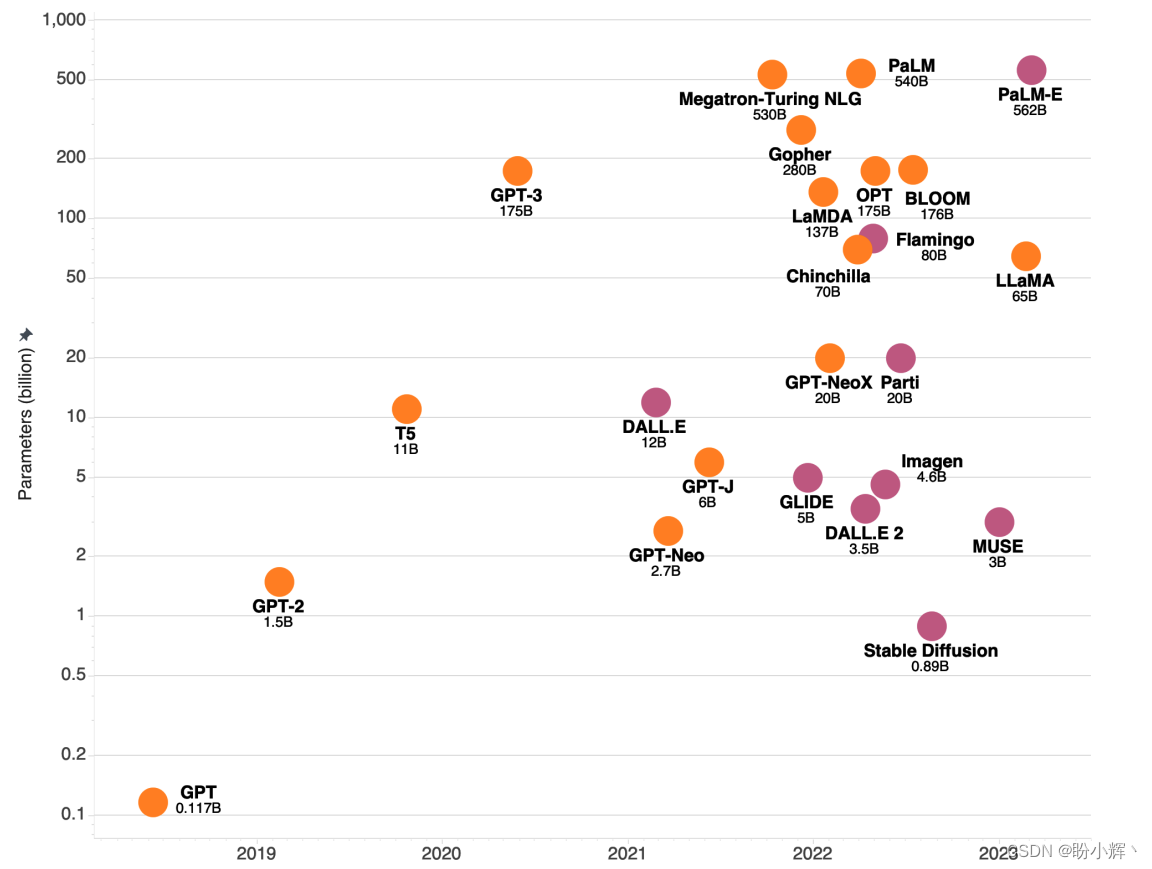
OpenAI 的 GPT 系列( GPT-3、GPT-3.5、GPT-4 等)仍然是最强大的语言模型之一,可供个人和商业用途使用,每个模型都通过 Web 应用程序和 API 访问。
Meta AI (LLaMA) 是由 Meta 提出的一系列大语言模型,模型参数量从 70 亿到 650 亿参数不等,其基于公开可用的数据集进行训练。
下表列出了当前存在的强大 LLM。其中包含一些系列模型,如 LLaMA 包含多个不同规模的模型,在这种情况下,我们给出最大模型的大小。其中一些模型的预训练权重完全开源,这意味着任何人都可以免费使用它们。
| 模型 | 提出时间 | 作者 | 参数量 | 是否开源 |
|---|---|---|---|---|
| GPT-3 | 2020 | OpenAI | 175000000000 | 否 |
| GPT-Neo | 2021 | EleutherAI | 2700000000 | 是 |
| GPT-J | 2021 | EleutherAI | 6000000000 | 是 |
| Megatron-Turing NLG | 2021 | Microsoft & NVIDIA | 530000000000 | 否 |
| Gopher | 2021 | DeepMind | 280000000000 | 否 |
| LaMDA | 2022 | 137000000000 | 否 | |
| GPT-NeoX | 2022 | EleutherAI | 20000000000 | 是 |
| Chinchilla | 2022 | DeepMind | 70000000000 | 否 |
| PaLM | 2022 | 540000000000 | 否 | |
| Luminous | 2022 | Aleph Alpha | 70000000000 | 否 |
| OPT | 2022 | Meta | 175000000000 | 是 |
| BLOOM | 2022 | Hugging Face Collaboration | 175000000000 | 是 |
| Flan-T5 | 2022 | 11000000000 | 是 | |
| GPT-3.5 | 2022 | OpenAI | - | 否 |
| LLaMA | 2023 | Meta | 65000000000 | 否 |
| GPT-4 | 2023 | OpenAI | - | 否 |
尽管大语言模型具有广泛的应用,但仍然存在一些需要克服的挑战。最明显的是,它们容易虚构事实,无法可靠地应用逻辑思维过程。需要注意的是,LLMs 只是被训练用于预测下一个单词。它们与现实没有其他联系,无法可靠地识别事实或逻辑错误。因此,在生产中使用这些强大的文本预测模型时,我们必须非常谨慎,并非任何事情都可以使用大语言模型精确推理。
2.2 文本生成代码模型
大语言模型的另一个应用是代码生成。在 2021 年 7 月,OpenAI 推出了一个名为 Codex 的模型,这是一个进行了微调的 GPT 语言模型。该模型能够仅凭问题的注释或函数名提供的提示,成功地编写出一系列问题的代码解决方案。这一技术推动了 GitHub Copilot 服务的诞生,它是一款能够您输入代码时实时提供建议代码的 AI 编程助手。
下图展示了两个自动生成的代码片段示例。第一个示例是使用 TWitter API 根据给定用户获取推文的函数。通过给出函数名和参数,Copilot 能够自动完成函数定义的其余部分。第二个示例要求 Copilot 解析一组费用,还在 docstring 中包含了一个解释输入参数格式和与任务相关的文本说明,Copilot 能够仅凭描述自动完成整个函数。
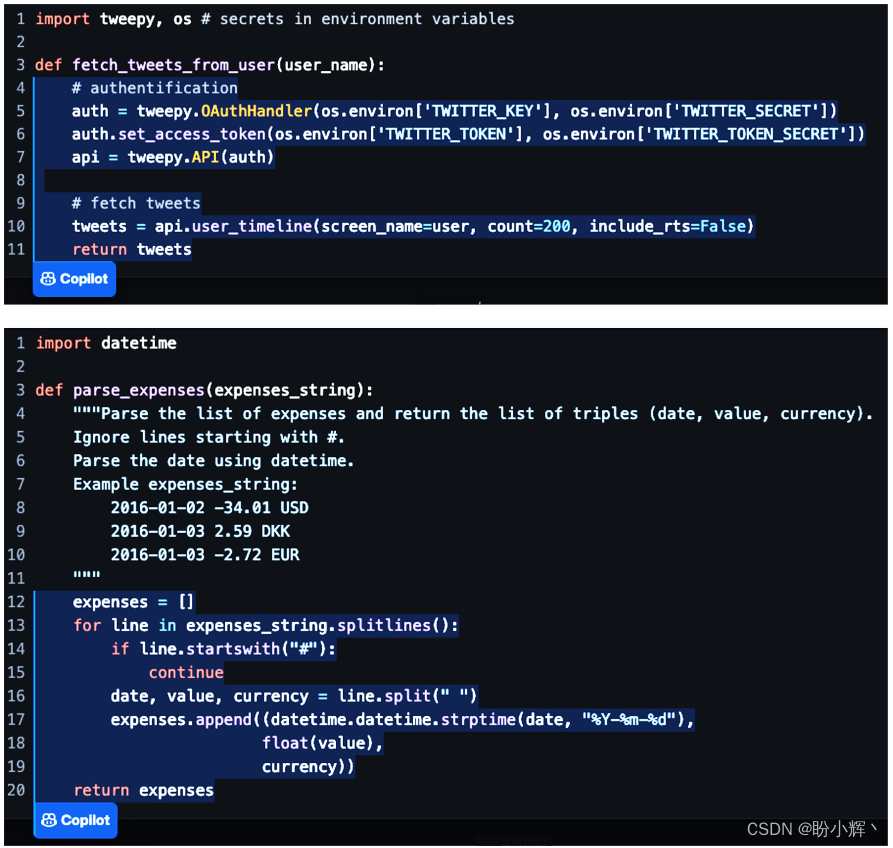
这一技术已经开始改变程序员处理特定任务的方式。程序员通常会花费相当大的时间搜索特定问题的现有解决方案。这意味着我们需要离开正在进行编写代码的交互式开发环境 (Interactive Development Environment, IDE),切换到一个网页浏览器,并从网页中复制粘贴代码片段并测试这些代码能否解决实际问题。在大部分情况下,Copilot 消除了这一系列繁琐的操作,因为我们可以在 IDE 内从 AI 生成的潜在解决方案中进行选择。
2.3 文本生成图像模型
当今最先进的图像生成技术主要是由多模态大模型来实现的,这些模型可以将给定的文本提示转换成图像。文本生成图像模型非常有用,因为它们允许用户通过自然语言轻松操作生成的图像。与诸如 StyleGAN 之类的模型相比,后者虽然非常出色,但无法通过描述生成的所需图像。
目前可供商业和个人使用的三个重要的文本生成图像生成模型分别是 DALL.E 2、Midjourney 和 Stable Diffusion。
OpenAI 的 DALL.E 2 是按使用量结算的服务,可以通过 Web 应用程序和 API 访问。Midjourney 通过其 Discord 频道提供基于订阅的文本生成图像服务。
Stable Diffusion 则是完全开源的。模型权重和训练模型的代码都可以在 GitHub 上获取,因此任何人都可以在本地设备上运行该模型。用于训练 Stable Diffusion 的数据集也是开源的,LAION-5B 的数据集包含了 58.5 亿个图像-文本对,目前是世界上最大的公开可访问的图像-文本数据集。
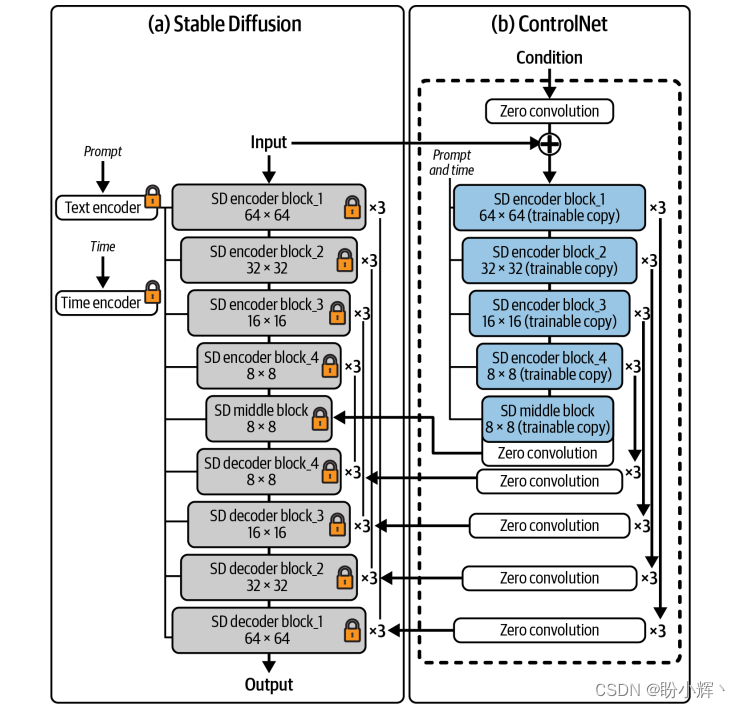
通过改进基线 Stable Diffusion 模型,可以将其应用于不同场景。其中,包含 ControlNet,其通过添加额外条件来对 Stable Diffusion 的输出进行精细控制。例如,输出图像可以以给定输入图像的 Canny 边缘图条件为基础,如下图所示。
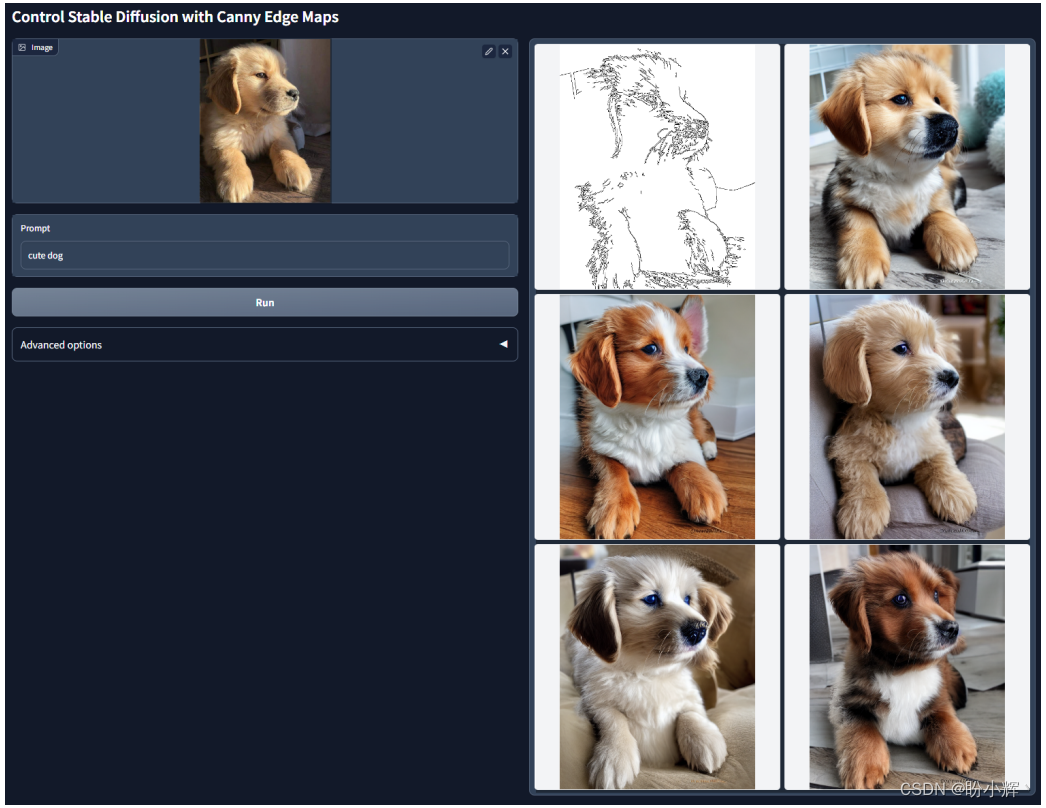
ControlNet 包含一个可训练的 Stable Diffusion 编码器,以及一个冻结权重的完整的 Stable Diffusion 模型。可训练的编码器的任务是学习如何处理输入条件(例如 Canny 边缘图),而冻结权重的 Stable Diffusion 保留了原始模型的能力。这样,只需要少量图像对就可以对 Stable Diffusion 进行微调。零卷积是指所有权重和偏差都为零的 1 x 1 卷积,在训练之前,ControlNet 不会产生任何效果。
Stable Diffusion 的另一个优点是它可以在一块只有 8GB 的 GPU 上运行,这使得它能够在边缘设备上运行,而不需要调用云服务。随着文本生成图像服务被包内置在下游产品中,生成速度变得越来越重要。
这三个模型的示例输出如下图所示,这些模型都能够捕捉到给定描述的内容和风格。

下表总结了当前的一些强大的文本生成图像模型。
| 模型 | 提出时间 | 作者 | 参数量 | 是否开源 |
|---|---|---|---|---|
| DALL.E 2 | 2022 | OpenAI | 3500000000 | 否 |
| Imagen | 2022 | 4600000000 | 否 | |
| Parti | 2022 | 20000000000 | 否 | |
| Stable Diffusion | 2022 | Stability AI, ComVis, and Runway | 890000000 | 是 |
| MUSE | 2023 | 3000000000 | 否 |
使用文本生成图像模型需要能创建一个既描述所要生成的图像内容又使用关键词鼓励模型产生特定风格或类型图像的提示。并不是同样的提示在不同的模型上都能很好地工作,这取决于用于训练模型的特定文本-图像数据集的内容。获取适合特定模型的有效提示的技术称为提示工程 (prompt engineering)。
2.4 其他应用
从图像到文本,从强化学习到多模态模型,生成式人工智能正在迅速在各种领域得到应用。
例如,2022 年 Meta 发表了一篇关于 CICERO 的论文,这是一个训练用于进行桌游 《Diplomacy》 的 AI 智能体。在这个游戏中,玩家代表第一次世界大战前欧洲的不同国家,必须与其他玩家进行谈判以控制整个大陆。对于一个 AI 智能体来说,这是一个非常复杂的游戏,因为玩家必须与其他玩家进行商谈,以获得盟友、协调行动并提出战略目标。为了实现这一点,CICERO 包含了一个语言模型,可以启动对话并回应其他玩家的消息。关键在于,对话与智能体战略计划保持一致,这些计划由模型的另一部分生成,以适应不断变化的情况。其中包括智能体在与其他玩家对话时虚张声势的能力,即说服另一个玩家与智能体合作,然后在后续回合采取攻击性行动。在一个拥有 40 场在线 《Diplomacy》 联赛中,CICERO 的得分是人类玩家平均水平的两倍多,在参与者中排名前 10%,这充分说明了生成式人工智能可以成功地与强化学习相结合。
嵌入式大语言模型的开发是一个重要的研究领域,谷歌的 PaLM-E 模型将语言模型 PaLM 与一个 Vision Transformer 结合起来,将视觉和传感器数据转化为可以与文本指令交互的符号,从而使机器人能够根据文本提示和其他感官模式的持续反馈执行任务。
文本生成视频模型的目标是根据文本输入创建视频,这是在文本生成图像模型的基础上进行的扩展,但是在其中融入了时间维度。例如,2022年 Meta 发表了 Make-A-Video,可以根据文本提示创建短视频。该模型还能在两个静态图像之间添加动作,并生成给定输入视频的变体。值得注意的是,它只需要在配对的文本-图像数据和无监督视频镜头上进行训练,并不直接使用文本-视频对。无监督的视频数据足够让模型学习世界的运动方式,然后使用文本-图像对学习如何映射文本和图像模态之间的关系,并为其添加动画。Dreamix 模型能够进行视频编辑,可以根据给定的文本提示转换输入视频,同时保留其他风格属性。例如,一杯牛奶被倒的视频可以转换为一杯咖啡被倒,同时保留原始视频的摄像机角度、背景和光照元素。
类似地,文本生成 3D 模型也是将传统的文本生成图像方法扩展到第三个维度。谷歌在 2022 年发表了 DreamFusion,这是一个给定文本提示生成 3D 模型的扩散模型。关键是,该模型不需要标记的 3D 模型进行训练,使用预训练的文本生成图像模型 (Imagen) 作为先验知识,然后训练一个 3D 神经辐射场 (Neural Radiance Field, NeRF),以便在随机角度渲染时能够产生良好的图像。OpenAI 在 2022 年发布的 Point-E 是另一种文本生成 3D 模型。Point-E 是一个基于扩散的系统,可以根据给定的文本提示生成 3D 点云。尽管其输出的质量不如 DreamFusion,但这种方法的优势在于它比基于 NeRF 的方法快得多,它可以在单个 GPU 上在一到两分钟内生成输出。
由于文本和音乐之间的相似性,创造文本生成音乐模型也可以得到广泛研究。MusicLM 是谷歌在 2023 年发布的一种语言模型,能够将关于音乐作品的文本描述转化为准确反映描述的音频,音频长度可以达到数分钟。它是在 AudioLM 的基础上发展而来的,增加了由文本提示引导模型的能力。
3. 生成式人工智能发展展望
在本节中,我们将探讨的生成式人工智能对我们生活、工作和学习等可能产生的影响,以及它所面临的实践和伦理挑战。
生成式人工智能在人们的日常生活中扮演越来越重要的角色,尤其是大型语言模型。使用 OpenAI 的 ChatGPT,生成式 AI 已经可以为求职者生成完美的求职信、针对某个主题在社交媒体上发布有趣的帖子。ChatGPT 提供了真正的交互性:它能够理解请求的具体细节,做出回应,并在有不清楚的地方提出自己的问题。
这种应用最直接的影响可能是提升书面沟通质量。使用用户友好的界面访问大语言模型能够快速将人们粗略的想法转化为连贯、高质量的段落。电子邮件写作、社交媒体帖子都将因这项技术而发生改变。它不仅消除了与拼写、语法和可读性相关的常见障碍,还直接将我们的思考过程与可用的输出联系起来,往往能够消除了参与段落构建的需要。
本文输出仅是大语言模型的应用之一,我们可以使用这些模型进行创意生成、提供建议和信息检索。这可以看作是获得、共享、检索和综合信息能力的第四个阶段,第一阶段时,我们从身边的人那里获取信息,或者通过亲自实践获取知识;印刷术的发明使书籍成为分享思想的主要载体,这是第二阶段;互联网的诞生使我们能够通过点击按钮即时搜索和检索信息,这是第三阶段;生成式 AI 开启了一个信息综合的新时代,它具有取代当前搜索引擎的潜力,我们可以将其视为第四阶段。
例如,OpenAI 的 GPT 系列模型可以提供定制的旅行推荐,如下图所示,也可以用于详细解释一个晦涩的概念。ChatGPT 是用户增长最快的技术平台;它在发布后的 5 天内就获得了 100 万用户。

3.1 生成式 AI 在工作场所中的应用
除了一般用途,生成式 AI 也可以用于具有创造力的特定工作:
AI 可以用于创建针对特定人群的个性化广告(基于他们的浏览和购买历史)推荐音乐制作:生成式 AI 可以用于创作原创音乐建筑:生成式 AI 可以综合考虑风格和布局等因素设计建筑物时尚设计:生成式 AI 可以综合潮流和穿着者的偏好创造独特多样的服装设计汽车设计:生成式 AI 可以用于设计和开发新的车型影视制作:生成式 AI 可以用于创建特效和动画,并设计对话情节药物研究:生成式 AI 可以用于发现新的药物,有助于开发新的治疗方案创意写作:生成式 AI 可以用于生成文字内容,如虚构故事、诗歌、新闻文章等游戏设计:生成式 AI 可以用于设计和开发新的游戏关卡和内容 但是,人工智能并不会对这些领域工作者的存在构成危机,AI 只是这些工作者工具箱中的另一种工具,而不是对角色本身的替代,使用这些新技术将能够帮助它们更快地探索新的想法。
3.2 生成式AI在教育中的应用
教育将是另一个将受到显著影响的领域,生成式 AI 将引发自互联网出现以来教育方式的又一次转变。
互联网使学生能够即时、清晰地检索信息,使仅测试记忆考试显得过时。这引发了教育方法的转变,注重测试学生以新颖方式综合思想的能力,而不仅仅是测试事实知识。
而生成式 AI 将引发教育领域的另一次转变,需要重新评估和调整当前的教学方法和评估标准。如果每个学生现在都可以随意使用 ChatGPT,那么基于作文的课程将变得并无意义。
因此,很多人呼吁禁止使用这种 AI 工具,就像禁止剽窃一样,但检测 AI 生成的文本要比检测剽窃困难得多。此外,如果学生可以使用 AI工 具为论文生成一个框架草稿,然后根据需要添加额外细节并修正错误的信息。在这种情况下,难以断言这究竟是原创作品还是 AI 生成的作品。
显然,这些都是需要解决的问题,但简单的抵制在教育领域中使用 AI 工具是没有意义的,因为它们已经开始在日常生活逐渐普及,试图限制它们的使用是徒劳的。相反,我们需要找到方法来拥抱这项新技术,并思考如何设计开放式 AI 课程,并鼓励学生通过互联网和 AI 工具进行开放性研究。
生成式 AI 同样具备促进学习过程本身的潜力,基于 AI 的导师可以帮助学生学习新话题,或生成针对性的学习计划。辨别事实与虚构与在互联网上获取信息时面临的挑战并没有什么不同,这也是在大模型时代我们应当掌握的关键的生活技能。
4. 生成式 AI 伦理与挑战
尽管在生成式 AI 领域取得了突破性进展,但仍然存在许多待解决的问题,包括实践问题和伦理问题。
例如,大语言模型的一个主要问题是,当询问一个陌生或矛盾的话题时,它们很容易生成错误信息。我们很难得知生成的回答中包含的信息是否真实准确。即使我们要求语言模型解释其推理过程或引用来源,它可能会编造引用或输出一系列不符合逻辑的陈述。这一问题并不容易解决,因为语言模型本质上只是一组权重(捕捉给定一组输入符号后最可能出现的下一个单词),并没有真实信息的数据库可供参考。
解决这个问题的一种方法是为大语言模型提供调用结构化工具(如计算器、代码编译器和在线信息源)的能力,以完成需要精确执行或准确事实的任务。例如,下图展示了 Meta 在 2023 年发布的 Toolformer 模型的输出。
Toolformer 能够显式地调用 API 获取信息,作为其输出的一部分。例如,它可能使用维基百科 API 检索有关某个人的信息,而不是将这些信息内嵌在其模型权重中。这种方法在精确数学运算中特别有用,Toolformer 可以说明想要输入到计算器 API 中的操作,而不是以自回归的方法生成答案。
生成式 AI 面临的另一个伦理问题是,大公司利用从网络上获取的大规模数据来训练自己的模型,而原始创作者并没有明确同意这样做。通常,这些数据甚至没有公开发布,因此无法知道数据是否被用来训练大语言模型或多模态文本生成图像模型。此外,使用模型生成风格与原作类似的艺术作品会降低内容的独特性。
Stability AI 正在致力于解决这个问题,多模态模型 Stable Diffusion 是在开源数据集 LAION-5B 的子集上进行训练的,他们还推出了一个名为 “Have I Been Trained?” 的网站,在该网站上可以搜索训练数据集中的特定图像或文本段落,并选择不再纳入模型训练过程中。这样一来,原始创作者就能够控制自己的作品是否用于模型训练,并确保所使用的数据具有透明度。然而,大多数可用的生成式 AI 模型并不公开其数据集或模型权重,也没有提供任何选择退出训练过程的选项。
总之,虽然生成式 AI 对于日常生活、工作和学习是一种强大的工具,但其广泛使用既有优势也存在一定的风险。我们需要意识到使用生成式 AI 模型的潜在风险,尽管如此,生成AI的未来仍然充满乐观。
总结
在本专栏中,我们介绍了经典生成模型,从 VAE、GAN、自回归模型、归一化流模型、能量模型和扩散模型等基本思想出发,介绍了 VQ-GAN、Transformers、世界模型和多模态模型等最先进技术,拓展了生成模型的应用边界。生成建模很可能成为更深层次的人工智能的关键,超越特定任务,并允许机器在其环境中有机地制定自己的奖励、策略。
系列链接
AIGC实战——生成模型简介
AIGC实战——深度学习 (Deep Learning, DL)
AIGC实战——卷积神经网络(Convolutional Neural Network, CNN)
AIGC实战——自编码器(Autoencoder)
AIGC实战——变分自编码器(Variational Autoencoder, VAE)
AIGC实战——使用变分自编码器生成面部图像
AIGC实战——生成对抗网络(Generative Adversarial Network, GAN)
AIGC实战——WGAN(Wasserstein GAN)
AIGC实战——条件生成对抗网络(Conditional Generative Adversarial Net, CGAN)
AIGC实战——自回归模型(Autoregressive Model)
AIGC实战——改进循环神经网络
AIGC实战——像素卷积神经网络(PixelCNN)
AIGC实战——归一化流模型(Normalizing Flow Model)
AIGC实战——能量模型(Energy-Based Model)
AIGC实战——扩散模型(Diffusion Model)
AIGC实战——GPT(Generative Pre-trained Transformer)
AIGC实战——Transformer模型
AIGC实战——ProGAN(Progressive Growing Generative Adversarial Network)
AIGC实战——StyleGAN(Style-Based Generative Adversarial Network)
AIGC实战——VQ-GAN(Vector Quantized Generative Adversarial Network)
AIGC实战——基于Transformer实现音乐生成
AIGC实战——MuseGAN详解与实现
AIGC实战——多模态模型DALL.E 2
AIGC实战——多模态模型Flamingo
AIGC实战——世界模型(World Model)