Python + CDSAPI 批量下载ERA5再分析数据
Copernicus Programme(哥白尼计划) 是欧盟发起的地球监测计划
ECMWF(European Centre for Medium-Range Weather Forecast) 是欧洲中期天气预报中心,一个组织/机构
Copernicus Programme中有多个项目,每个项目交给专门的组织负责,其中CAMS(Copernicus Atmosphere Monitoring Service,大气监测服务) 和 C3S(Copernicus Climate Change Service,气候变化服务) 就是交由ECMWF负责
CAMS,该项目主要提供大气成分、大气质量、温室气体…大气相关的数据,链接

C3S,该项目主要提供气候相关变量的数据,包括再分析资料 eq:ERA5,预报资料,链接
具体的,CAMS和C3S分别通过基于的ADS(Atmosphere Data Store)和CDS(Climate Data Store)平台来实现这些数据资料的存储、管理和分发…
ADS和CDS都是基于Common Data Store Engine(也缩写为CDS,注意区分),所以结构基本相同:前端Web界面、后端软件引擎、托管服务和核心数据存储库…
后面内容以CDS中下载"reanalysis-era5-single-levels"数据集中的vertical integral of eastward water vapour flux变量数据为例
通过CDS的Web下载数据文件
首先,(注册)登陆一个ECMWF账号
选择想要的数据集

点击Download选项卡,填写表单(即勾选所需的产品类型、变量、时空范围、数据格式和文件格式),不用管API request(后面第二种方法下载数据时会用到)。填完表单后,点击Submit form,提交表单并发送请求
在Your requests中可以查看刚才提交的数据请求,每个请求会被CDS分配一个唯一的ID,它先进行排队,排到后CDS会进行处理,处理结果有成功Complete和失败Failed。成功后就可以把数据下载到本地了
Web下载数据的特点:请求在排队受理时具有更高的优先级
由于CDS本身的原因,一个请求只能对应一个文件,且这个文件是有最大限制的。所以,当对数据文件有要求时,比如要批量下载2018~2020年隔6h的经纬向的ivt数据,要求一个月一个变量一个文件,如果通过Web手动提交申请,则需要3 * 12 * 2次的填表勾选、提交和下载,虽然也可以把它们先全部下在一个文件中,再通过别的方法对该文件进行拆分,当然这还是不考虑该文件是否超过最大限制的情况。那么,这种情况下就可以通过编写程序然后运行,实现自动循环提交请求并下载
Python + CDSAPI批量下载数据文件
API(Application Programming Interface)应用程序接口,在软件A中接入软件B提供的API,就可以在软件A中获得软件B的部分服务,API实现了不同程序间的交互。简单理解,就是造了一个机器,但需要电,可自己不会造发电机,而发电厂会造发电机,此时他们牵了电线过来,接上电线就能让机器获得电,在这里面,电线是发电厂提供的API,它连接了机器和发电厂,并使得机器能够获得发电厂生产的电
CDSAPI就是ADS/CDS提供的API,Python脚本接入(导入)CDSAPI模块,再提供必要的参数后运行,就能在本地的Python程序中获得CDS的检索分发数据文件的服务。在此基础上,往脚本中添加循环判断语句进行控制,就能实现批量下载数据文件
在一个Python环境中安装CDSAPI库:
conda install -c conda-forge cdsapi / pip install cdsapi
修改cdsapi库的配置文件.cdsapi:
(注册)登陆CDS后,点击 User guide, 再点击Get data programmatically(API service)
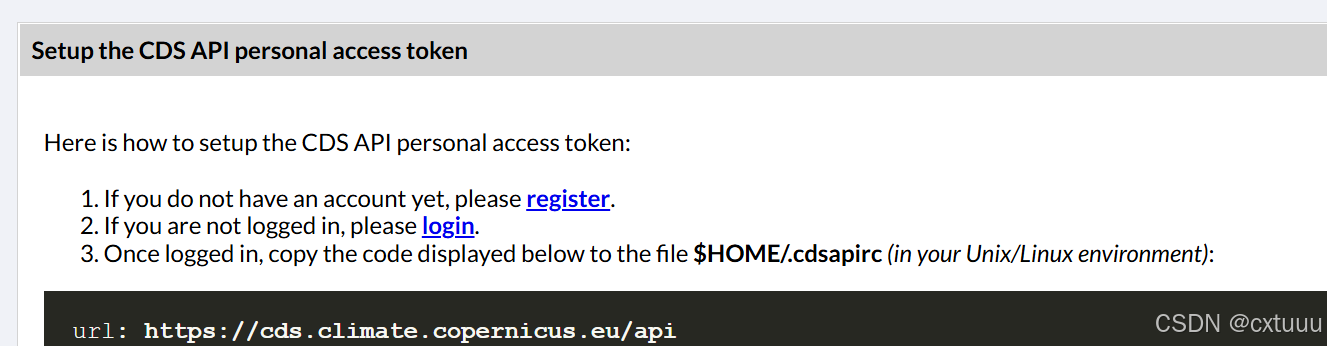
复制url:......key:......,粘贴到用户目录下的.cdsapi文件中
在初次导入cdsapi库前,C:\Users\user_name\下应该是没有.cdsapirc配置文件的,需要自己手动创一个:可以打开记事本,然后复制、粘贴、保存,文件名为.cdsapi,注意保存类型选择所有文件
cdsapi库在导入运行时默认读取用户目录下的.cdsapirc配置文件,url:…是CDS的服务器地址,key:…是用户密钥,即配置文件为CDSAPI提供了“去哪下载数据”和“谁在下载数据“的必要信息
编写Python脚本并运行
前面通过Web下载数据文件的过程中,在勾选完表单后有个API request,点击Show API request code会显示与表单对应的代码,例如勾选了 :
Product type:Reanalysis;
Variable:Vertical integral of eastward water vapour flux;
Year:2020;
Month:1;
Day:01;
Time:00:00;
Geographic area:Whole available region;
Data format:NetCDF4;
Download format:Unarchived
得到的代码:
import cdsapidataset = "reanalysis-era5-single-levels"request = { "product_type": ["reanalysis"], "variable": ["vertical_integral_of_eastward_water_vapour_flux"], "year": ["2020"], "month": ["01"], "day": ["01"], "time": ["00:00"], "data_format": "netcdf", "download_format": "unarchived"} client = cdsapi.Client() # 创建一个客户端client.retrieve(dataset, request).download() # 给定参数检索并下载数据文件,默认下载到和该.py脚本相同目录下这段代码包含了完整的调用cdsapi库下载数据的特定语法,直接复制粘贴保存一个.py脚本然后运行,cdsapi把请求发送到CDS服务器去排队受理,处理完请求后CDS服务器再通过cdsapi把数据传给Python程序,Python程序将数据文件下载到本地
官方强烈建议先去Web上填表单然后获取代码,在此代码的基础上按要求构建程序。因为这代码结构很完整,是一个非常好的模板
例如现在要下载2018~2020年隔6h的经纬向的ivt数据,并要求一个月一个变量一个文件,且文件名格式为”e-ivt-year-month.nc“,那么代码可以这样写:
import cdsapidataset = "reanalysis-era5-single-levels"request = { "product_type": ["reanalysis"], "variable": [], "year": [], "month": [], "day": [ "01", "02", "03", "04", "05", "06", "07", "08", "09", "10", "11", "12", "13", "14", "15", "16", "17", "18", "19", "20", "21", "22", "23", "24", "25", "26", "27", "28", "29", "30", "31" ], "time": [ "02:00", "08:00", "14:00", "20:00" ], "data_format": "netcdf", "download_format": "unarchived", # "grid": [1.5, 1.5] 可以在脚本中指定数据的水平分辨率}client = cdsapi.Client()variable_list = [ "vertical_integral_of_eastward_water_vapour_flux", "vertical_integral_of_northward_water_vapour_flux"]year_list = ["2018", "2019", "2020"]month_list = [ "01", "02", "03", "04", "05", "06", "07", "08", "09", "10", "11", "12",]file_path = "xxx"for v in variable_list: request["variable"] = v if v == "vertical_integral_of_eastward_water_vapour_flux": v_abbreviation = "e" else: v_abbreviation = "n" for y in year_list: request["year"] = y for m in month_list: request["month"] = m # target指定数据文件的绝对路径和文件名 target = file_path + v_abbreviation + "-ivt-" + y + "-" + str(int(m)) + ".nc" client.retrieve(dataset, request, target)这样就可以自动批量下载数据文件了,需要注意:
运行一次client.retrieve提交一个请求,并不是一次性提交所有请求在脚本中可以指定数据的水平分辨率,但在Web的表单中却没有分辨率选项当client.retrieve中加了target参数后,需要把后面的.download()删掉,否则在第一个文件下载后会提示错误(字符串没有download属性)从而打断循环 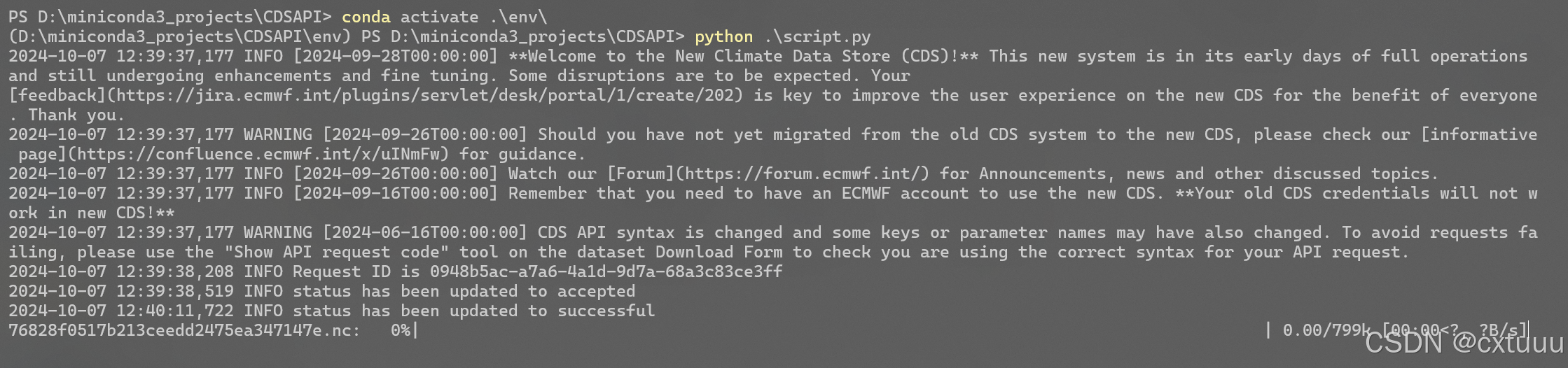
CLI中可以看到当前请求被分配的唯一ID、状态(在Web的Your requests中也会同步更新),请求受理成功后会自动下载到本地,并显示下载进程
CLI中开始的5个INFO/WARNING其实就是Web中上边的5条提示
其他注意事项
批量下载数据时,单个文件应该不会很大,所以每个请求的排队受理时间较短,但下载到本地的过程受网络条件影响很大,有时候能快到10MB/s,有时候慢到十几KB/s(当下载速度太慢时,可以按Ctrl + C取消进程),有时候会发生数据传输中断的错误(我一般是先删掉下一半的数据文件,然后修改Python脚本,筛出下完的文件,再重新运行
若下载速度实在太慢,可以试着利用国内镜像提高cdsapi下载速度,本质上是将要访问的国外服务器替换成国内的镜像站服务器,但它也受网络环境影响
ADS下载数据的流程是一样的,因为它和CDS的结构相同,区别就是两个不在同个服务器上,所以在修改.cdsapirc配置文件时url是不同的。如果ADS和CDS都经常使用,又不想每更改一次平台就修改一次配置文件,可以为它们分别建立配置文件并放在不同目录,cdsapi只是默认读取用户目录中的配置文件,但也可以在Python脚本中指定特定的配置文件,链接
所有详细内容参考CDS/ADS的官方用户指南