博客主页:【夜泉_ly】
本文专栏:【C++】
欢迎点赞?收藏⭐关注❤️

C++ -引用-详解
1.引用基础1.1是什么1.2特点 2.引用的意义3.引用的应用场景3.1作为参数3.2作为返回值传值返回引用返回 4.权限问题5.与指针的区别6.总结
1.引用基础
1.1是什么
引用(Reference)是C++中的一个重要概念,它允许你为变量创建一个别名,从而使你能够简洁地操作同一个变量。
引用通过在类型后加上&符号来定义,例如:
int a = 0; // 定义一个整型变量a并赋值为0int& b = a; // b是a的别名,任何对b的操作都会影响aint& c = b; // c也是a的别名,c和b共享同一内存位置使用cout输出这些变量的地址时,可以清楚地看到它们指向同一块内存空间:
std::cout << &a << std::endl; // 输出变量a的内存地址std::cout << &b << std::endl; // 输出变量b的内存地址,显示与a相同std::cout << &c << std::endl; // 输出变量c的内存地址,依旧与a和b相同运行结果如下图:
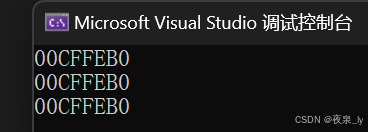
这形象的展示了引用不是定义一个新的变量,而是给已存在的变量取了一个别名。
因此,在概念上通常认为,引用不会开辟新的内存空间。
1.2特点
如果对其中任何一个变量进行自增操作,所有引用变量都会受到影响:
a++;b++;c++;//一个++,全部++如当a最初为0时,执行完这三条语句后,a变为3。
引用在定义时必须初始化,这点可以和指针做对比:
int& b;//这样写是不行的int* b;//这样写是可以的如果不初始化,不能通过编译:

再看看下面这段代码:
int x = 11;c = x;是c变为x的引用(别名),还是x赋值给c?
是赋值,C++的引用不能改变指向。
2.引用的意义
虽然直接定义别名在某些情况下看似没有实际意义,但在实际开发中,引用提供了更灵活和安全的参数传递方式,大大提高了代码的可读性和效率。
例如,现在要写一个函数用来交换两个变量的值:
void Swap(int a, int b);这段代码的问题非常明显——形参是实参的临时拷贝,形参的修改不影响实参。
方法一:使用指针
void Swap(int* a, int* b);这是在C语言中的常见写法,通过传递指针,能够直接操作变量的内存地址,从而实现交换:
Swap(&a, &b); // 通过地址传递,直接影响原始变量方法二:使用引用
相比之下,使用引用可以使代码更简洁、直观,避免了指针可能带来的复杂性:
void Swap(int& a, int& b);传参:
Swap(x, y); // 形参是实参的别名,交换a和b等于交换x和y。交换指针的方式:
以前:传二级指针。
现在:
void Swap(int*& a, int*& b); // 通过引用传递指针,允许直接修改指针的指向顺序表尾插的更新:
在处理数据结构时,引用的优势更加明显。例如,以前的写法可能如下:
ListPushBack(struct ListNode** pphead, int x); // 传递二级指针而更新后的写法则显得更加简洁和安全:
ListPushBack(struct ListNode*& phead, int x); // 使用引用,减少了指针的复杂性定义顺序表节点
有书这样写:
typedef struct ListNode{XXXX;}LTNode,*pLTNode;//注,*pLTNode指的是://typedef struct ListNode* pLTNode;这时,它们的尾插就能这样定义了:
LTPushBack(pLTNode& phead, int x);二级指针就这样被干没了?。
3.引用的应用场景
3.1作为参数
输出型参数:
形参的改变直接影响实参,避免了额外的内存开销。
提高效率:
在处理大对象或深拷贝类对象时,引用能显著提高效率,降低程序的内存消耗。
例如,对于一个大型结构体,使用引用传递可以避免不必要的拷贝,提升性能:
struct{ int a[10000]; // 大对象的定义};传参时的速度:引用快于拷贝,引用和指针差不多。
3.2作为返回值
返回值时,如果直接返回一个值,会涉及到创建临时变量的问题。以此为例:
int func(); // 普通返回int& func(); // 返回引用传值返回
例如:
int func() { int n = 0; return n;}int main() { int ret = func();}n是直接返回给ret吗? 不是。中间会生成临时变量,有可能是寄存器代替,做为表达式的返回值,再传给ret。
因为出了作用域,函数栈帧被销毁,n也会被销毁。
如果:
{static int n = 0;}会,不搞特例。
因此,如果传值返回(全局变量,静态变量,局部变量),都会生成临时变量。
如果不想生成,怎么办?
引用返回
int& func();返回n的别名(引用)
意义:
int&SLAt(SQList&s,int pos);) 注意事项: 直接返回局部变量的引用是极其危险的,可能导致未定义行为。
栈帧销毁了,但未清理,ret的结果侥幸正确;栈帧销毁了,且清理了,ret的结果是随机值。例如:
int& func(){int n = 0;cout << &n <<endl;return n;}int main(){int& ret = func();//ret是个引用,是n的别名的别名。cout << &ret;return 0;}运行结果如下图:
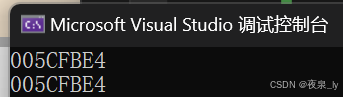
会发现,n与ret的地址一样。
再来看看下面这段代码:
int& func(int x){int n = x;n++;return n;}int main(){int& ret = func(10);cout << ret << endl;func(20);cout << ret << endl;return 0;}运行结果如下图:
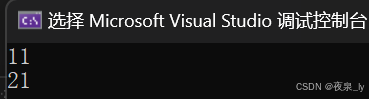
现在稍作修改,将func(20);改为任一其它函数:
//func(20);printf("HaHa\n");运行结果如下图:
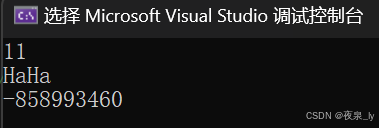
最终打印11和随机值。
因为,下一个函数建立的栈帧会覆盖func之前建立的栈帧。
系统不同,也可能都是随机值。
所以,返回局部对象的引用是危险的行为:
为了避免这一问题,可以返回一个静态变量的引用:
int& func() { static int n = 0; // n在静态区,生命周期持续到程序结束 return n; // 返回静态变量的引用,安全且有效}返回静态对象的引用不危险:函数栈帧的销毁不会影响n。
4.权限问题
引用过程中,权限不能放大。
const int a = 0;int& b = a;// 不行int c = a;// 可以c只拷贝了a的值,c的修改不会影响a,权限没有放大。
b的修改会影响a,权限放大,编译不能通过。
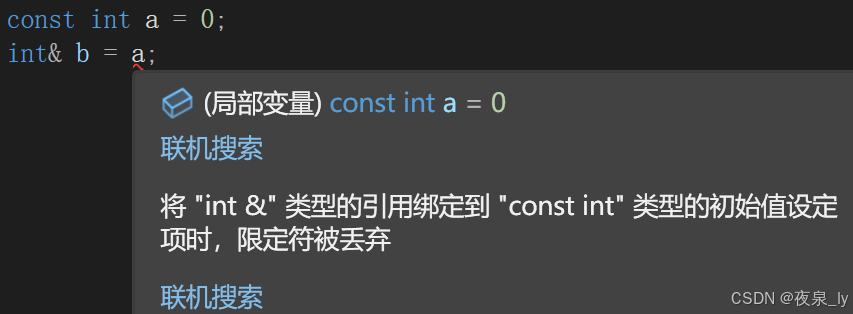
int x = 0;int& y = x;// 可以const& z = x;// 可以,缩小了z作为别名的权限权限可以平移、缩小。
再看下面这段代码:
double d = 1.1;int i = d;int& ri = d;
需注意,这并不是因为类型不同,而是权限的问题:
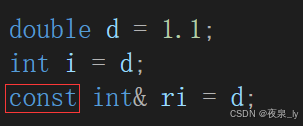
为什么?
因为发生类型转换时,如整型提升、强制转换、隐式类型转换,都会产生一个新的临时变量:
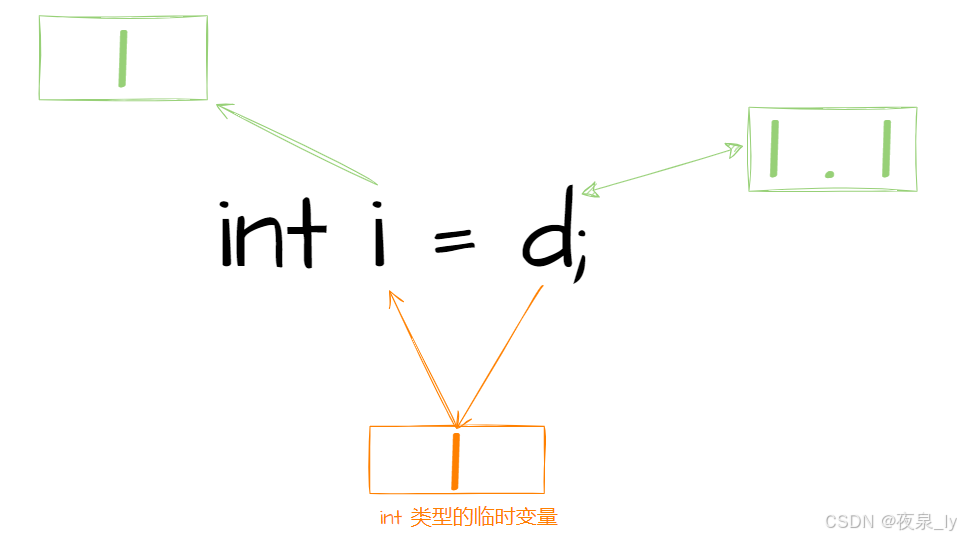
而这个临时变量具有常性,所以int&不行的原因是权限的放大。
再例如:
int func1(){static int x = 0;return x;}int& func2(){static int x = 0;return x;}int main(){int ret1 = func1();int& ret2 = func1();const int& ret3 = func1();int& ret4 = func2();const int& ret5 = func2();return 0;}其中,只有ret2会报错:
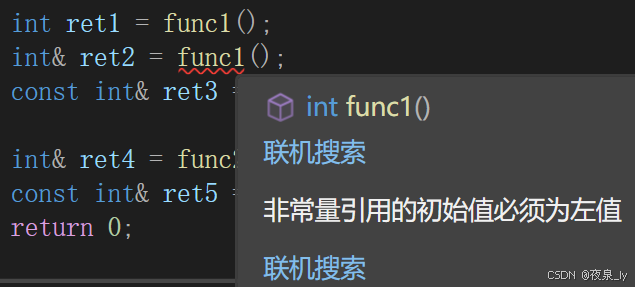
ret1:拷贝,无引用,不涉及权限。
ret2:权限放大,传值返回的不是x,而是临时变量,临时变量具有常性。
ret3:权限平移。
ret4:权限平移。
ret5:权限缩小。
5.与指针的区别
int a = 0;语法层面:不开空间,是对a取别名
int& ra = a;ra = 10;语法层面:开空间,存的是a的地址
int* pa = &a;*pa = 20;而从底层汇编指令实现的角度看,引用是类似指针的方式实现的:
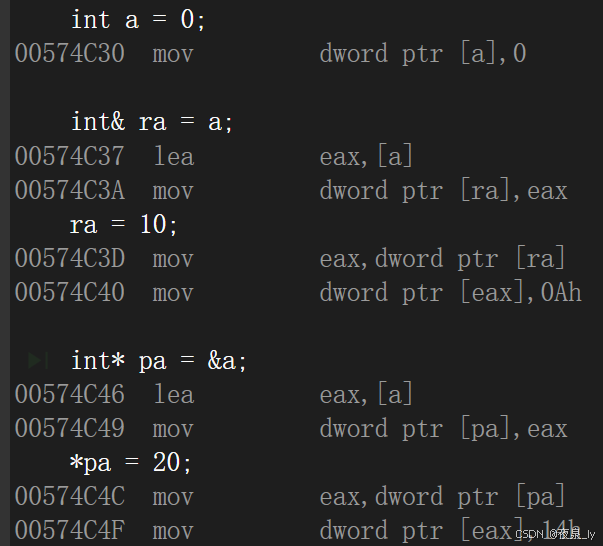
指针会出现野指针、空指针等情况,相比之下,引用更加安全。
6.总结
引用传参: 引用是一种高效且安全的参数传递方式,适用于几乎所有场景,特别是在处理大型对象和复杂数据结构时,能够显著提高性能。
引用返回: 返回引用时应谨慎,仅在全局、静态和堆对象中使用,以避免潜在的未定义行为。直接返回局部变量的引用是极其危险的,因为一旦局部变量超出作用域,引用将指向无效的内存地址,从而可能导致程序崩溃或不可预知的结果。
引用与指针的区别: 虽然在语法上引用和指针都可以用来间接访问变量,但引用更安全,不会出现野指针或空指针的情况。它们的实现原理相似,但在使用时,引用提供了更简洁和直观的语法。
总结: 通过引用,我们可以在保持高效的同时,使代码更加易读和安全。无论是在参数传递还是返回值处理中,引用都是一种极具价值的工具。
希望本篇文章对你有所帮助!并激发你进一步探索编程的兴趣!
本人仅是个C语言初学者,如果你有任何疑问或建议,欢迎随时留言讨论!让我们一起学习,共同进步!