点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis (已更完)Kafka(已更完)Spark(已更完)Flink(已更完)ClickHouse(已更完)Kudu(正在更新…)章节内容
上节我们完成了如下的内容:
Apache Kudu 的基本概述数据模型、使用场景等内容
Kudu 对比
Kudu 和 HBase、HDFS 之间的对比:

Kudu的架构
与HDFS和HBase相似,Kudu使用单个Master节点,用来管理集群的元数据,并且使用任意数量的TabletServer节点用来存储实际数据,可以部署多个Master节点来提高容错性。
Master
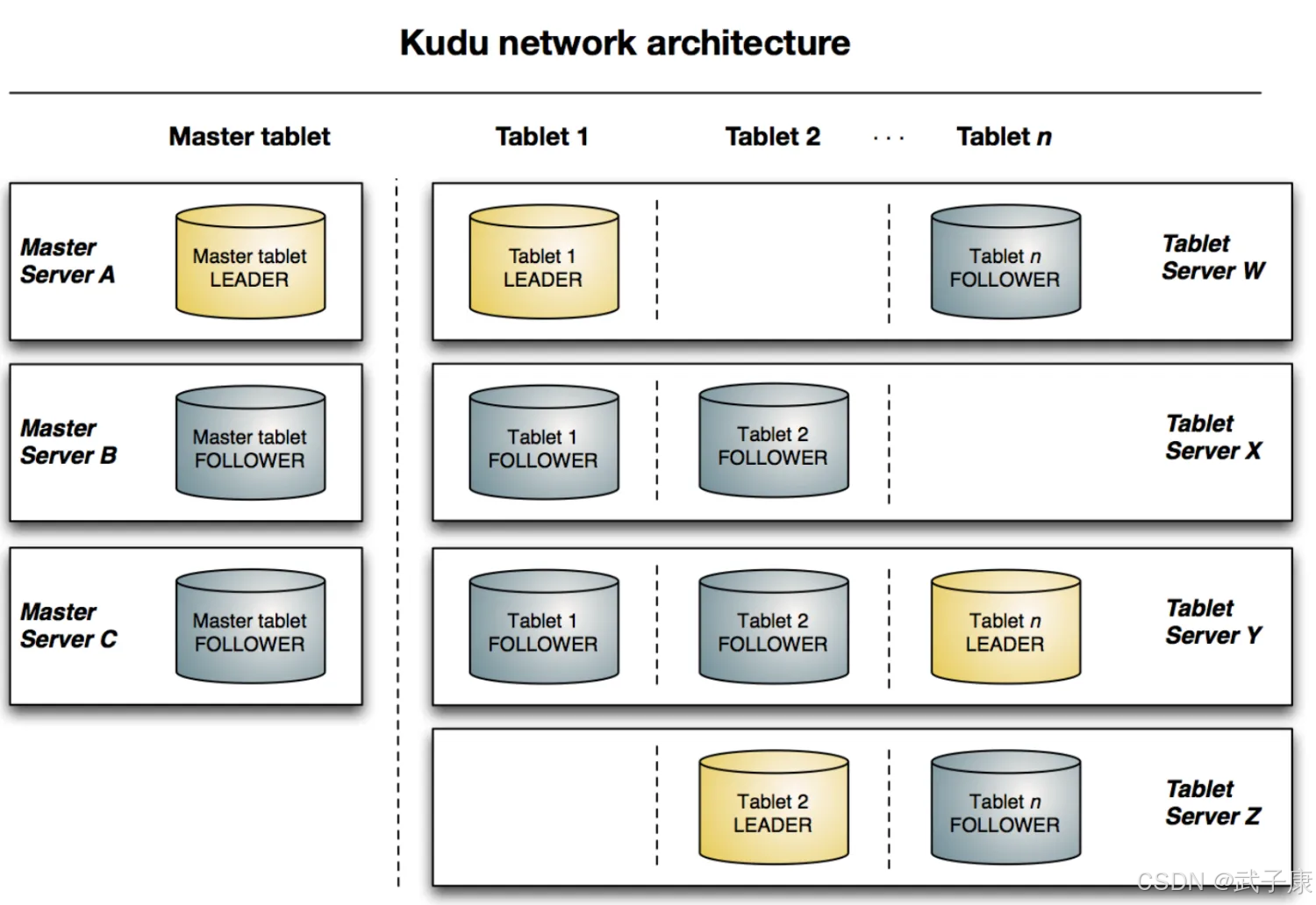
高可用与容错机制:Kudu 的高可用和容错能力基于其副本管理机制。每个 Tablet 都有多个副本,副本之间通过 Raft 协议进行同步:
Leader 选举:如果某个 Tablet 的 Leader 副本发生故障,系统会自动选举一个新的 Leader 来接管读写操作,确保服务不间断。
副本恢复:当某个 Tablet Server 节点发生故障,Master 节点会将失效的副本重新分配到其他健康的 Tablet Server 上,并同步数据。
Master
Kudu的Master节点负责整个集群的元数据管理和服务协调,它承担着如下的功能:
作为Catalog Manager,Master节点管理集群中所有Tablet和Schema及一些其他的元数据。作为Cluster Coordinate,Master节点追踪着所有Server节点是否存活,并且当Server节点挂掉后协调数据重新分布。作为TabletDirectory,Master跟踪每个Tablet的位置。Catalog Manager
Kudu的Master节点会持有一个单Tablet的Table-CatalogTable,但是用户是不能直接访问的,Master将内部的Catalog信息写入Tablet,并且将整个Catalog的信息缓存到内存中。随着现在商用服务器上的内存越来越大,并且元数据信息占用空间其实并不大,所以Master不容易存在性能瓶颈,CatalogTable保存了所有Tablet的Schema的版本与Table的状态(创建、运行、删除等等)。
Cluster Coordination
Kudu集群中的每个Tablet Server都需要配置Master的主机名列表,在集群启动时,TabletServer会向Master注册,并发送所有Tablet信息。
TabletServer第一次向Master发送信息时会发送所有Tablet的全量信息,后续每次发送则只会发送增量信息,仅包含新创建、删除或修改Tablet的信息,作为ClusterCoordination,Master只是集群状态的观察者。对于TabletServer中Tablet的副本位置、Raft配置和Schema版本等信息的控制和修改由TabletServer自身完成。Master只要下达命令,TabletServer执行成功后会自动上报处理的结果。
Tablet Directory
因为Master上缓存了集群的元数据,所以Client读写数据的时候,肯定是要通过Master才能获取到Tablet的位置灯信息,但是如果每次读写都要通过Master节点的话,那Master就会成为这个集群的瓶颈,所以Client会在本地缓存一份它需要访问的Tablet的位置信息,这样就不用每次都从Master读取了。因为Tablet的信息也可能会发生改变(比如掉线或者宕机),所以当Tablet的值发生变化的时候,Client会收到通知,然后再从Master重新拉取一份新的。
Table
在数据存储方面,Kudu选择完全由自己实现,而没有借助于已有的开源方案,Tablet存储主要想实现的目标为:
快速的列扫描低延迟的随机读写一致性的性能RowSets
在Kudu中,Tablet被细分为更小的单元,叫做RowSets,一些RowSets仅存于内存中,被称为MemRowSets,而另一些则同时使用内存和硬盘,被称为DiskRowSets。任何一行未被删除的数据都只能存一个RowSet中。无论任何时候,一个Tablet仅有一个MemRowSet用来保存最新插入的数据,并且有一个后台线程会定期把内存中的数据Flush到磁盘上。当一个MemRowSet被Flush到磁盘上后,一个新的MemRowSet会替代它。而原有的MemRowSet会变成一到多个DiskRowSet。Flush操作是完全同步进行的,在进行Flush时,Client同样可以进行读写操作。
MemRowSets
MemRowSets是一个可以被并发访问并进行优化的B-Tree,主要是基于MassTree来设计的,但存在几点不同:
Kudu并不支持直接删除操作,由于使用了MVCC,所以在Kudu中删除操作其实是插入一条标志着删除的数据,这样就可以推迟删除操作。类似删除操作,Kudu也不支持原地更新操作将Tree的Leaf链接起来,就像B+Tree,这一步关键的操作可以明显的提升Scan操作的性能。没有实现字典树(trie树),而是只用了单个Tree,因为Kudu并不适用于极高的随机读写的场景。与Kudu中其他模块中的数据结构不同,MemRowSet中的数据使用行存储,因为数据都在内存中,所以性能也是可以接受的,而且Kudu在MemRowSet中的数据结构进行了一定的优化。
DiskRowSet
当MemRowSet被Flush到磁盘后,就变成了DiskRowSet,当MemRowSet被Flush硬盘的时候,每32M就会形成一个新的DiskRowSet,这主要是为了保证每个DiskRowSet不会太大,便于后续的增量Compaction操作。Kudu通过将数据氛围BaseData和DeltaData,来实现数据的更新操作。Kudu会将数据按列存储,数据被切分多个Page,并使用B-Tree进行索引。除了用户写入数据,Kudu还会将主键索引存入一个列中,并且提供布隆过滤器来进行高效的查找。
Compaction
为了提供查询性能,Kudu会定期进行Compaction操作,合并DeltaData与BaseData,对标记了删除的数据进行删除,并且会合并一些DiskRowSet。
分区
选择分区策略需要理解数据模型和标的预期工作负载:
对于写量大的工作负载,重要的是要设计分区,使写分散在各个Tablet上,以避免单个Tablet超载。对于涉及许多短扫描的工作负载(其中联系远程服务器的开销占主导地位),如果扫描的所有数据都位于同一块Tablet上,则可以提高性能。理解这些基本的权衡是设计有效分区模式的核心。
没有默认分在创建表时,Kudu不提供默认的分区策略。建议预期具有繁重读写工作负载的新表至少拥有与Tablet服务器相同的Tablet。
和需要分布式存储系统一样,Kudu的Tablet是水平分区的,BigTable只提供了Range分区,Cassandra只提供Hash分区,而Kudu同时提供了这两种分区方式,使分区较为灵活。
当用户创建了一个Table时,可以同时指定Table的PartitionSchema,PartitionSchema会将primary key映射为Partition key。一个PartitionSchema 包括0到多个Hash-Partitioning规则和一个Range-Partitioning规则,通过灵活的组合各种Partition规则,用户可以创造适用于自己业务场景分区方式。
Kudu 支持两种分区策略:范围分区(Range Partitioning) 和 哈希分区(Hash Partitioning)。
范围分区
范围分区基于主键范围划分 Tablet。用户可以通过设置分区键的范围,手动或自动地将数据分布到不同的 Tablet 上。例如,按时间戳划分数据表可以将不同时间段的数据分配到不同的分区。
哈希分区
哈希分区通过对主键进行哈希运算,将数据均匀分布到不同的 Tablet 中。哈希分区适用于那些查询中没有明显范围条件的场景,如主键查询或随机访问场景。
查询与写入流程
写入流程
客户端将数据写入 Tablet Server 时,首先被写入到 MemRowSet 中。MemRowSet 达到一定容量后,数据会通过后台线程刷入磁盘(DiskRowSet)。刷盘过程中,Tablet Server 会将数据同步到其他副本,以保证数据的一致性。查询流程
客户端查询数据时,查询请求首先发送到 Master 节点,Master 节点根据请求的主键范围定位到相应的 Tablet Server。Tablet Server 从磁盘中的 DiskRowSet 中读取对应列的数据,返回给客户端。如果查询只涉及部分列,Kudu 只读取涉及的列数据,利用列式存储的优势提高查询效率。Tablet 和 Raft 共识协议
Kudu 的数据被切分为多个Tablet,每个 Tablet 是表的一部分,类似于水平分片(Horizontal Partitioning)。
每个 Tablet 通过主键范围进行划分,确保数据均匀分布在不同的 Tablet Server 上。
为了保证数据的可靠性和一致性,Kudu 使用了 Raft 共识协议 来进行副本管理。每个 Tablet 通常有多个副本(默认是三个),这些副本通过