哈喽大家好 ! 我是唐宋宋宋,很荣幸与您相见!!!
一.代码
yolov5的代码需要大家上github自己扒 链接已经提供。
GitHub - ultralytics/yolov5: YOLOv5 ? in PyTorch > ONNX > CoreML > TFLite
二.新建存放数据的文件
首先需要创建三个文件用来存放需要的数据。(名字自己定义,注意区分)

images和labels文件里需要创建train,val文件具体如下:

LOVE_PRE文件里需要创建Annotations(标注),JPEGImages(照片),labels(类别标签)文件具体如下:

三.填入需要的数据
*文件我们先备好,接下来看文件内需要放哪些内容。
说一下,既然是训练自己的数据集就需要我们对自己寻找的数据集进行标注,这边我使用的是labelimg 它是用Python编写的,并将Qt用于其图形界面 具体怎么使用大家可以参考
(21条消息) labelImg 使用教程 图像标定工具_Dontla的博客-CSDN博客_labelimg
注:标注好的.xml文件放入Annotations内。
我们知道使用labelimg标注好的文件格式是.xml文件 如果我们要使用yolov5就需要把它转换成yolov5需要的文件格式 .txt (这是重点) 代码附下:
# -*- coding: utf-8 -*-import osimport xml.etree.ElementTree as ETdirpath = r'D:\pythonProject1\yolov5-6.0\bottle_dataset\stronger\xml' # 原来存放xml文件的目录newdir = r'D:\pythonProject1\yolov5-6.0\bottle_dataset\stronger\labels' # 修改label后形成的txt目录if not os.path.exists(newdir): os.makedirs(newdir)dict_info = {'green': 0, 'transparent': 1, 'white': 2, 'blue': 3, 'unknown': 4, 'orange': 5} # 有几个 类别 填写几个label namesfor fp in os.listdir(dirpath): if fp.endswith('.xml'): root = ET.parse(os.path.join(dirpath, fp)).getroot() xmin, ymin, xmax, ymax = 0, 0, 0, 0 sz = root.find('size') width = float(sz[0].text) height = float(sz[1].text) filename = root.find('filename').text for child in root.findall('object'): # 找到图片中的所有框 sub = child.find('bndbox') # 找到框的标注值并进行读取 label = child.find('name').text label_ = dict_info.get(label) if label_: label_ = label_ else: label_ = 0 xmin = float(sub[0].text) ymin = float(sub[1].text) xmax = float(sub[2].text) ymax = float(sub[3].text) try: # 转换成yolov3的标签格式,需要归一化到(0-1)的范围内 x_center = (xmin + xmax) / (2 * width) x_center = '%.6f' % x_center y_center = (ymin + ymax) / (2 * height) y_center = '%.6f' % y_center w = (xmax - xmin) / width w = '%.6f' % w h = (ymax - ymin) / height h = '%.6f' % h except ZeroDivisionError: print(filename, '的 width有问题') with open(os.path.join(newdir, fp.split('.xml')[0] + '.txt'), 'a+') as f: f.write(' '.join([str(label_), str(x_center), str(y_center), str(w), str(h) + '\n']))print('ok')代码只需要更改5,6行的文件路径和第11行你所标注的类别即可。
注:.xml转化成.txt文件放入labels内。
注:我们用到的所有照片放入JPEGImage内。
生成的.txt内容如下(以我的数据为例)第一列是设定的标签,后面是坐标位置
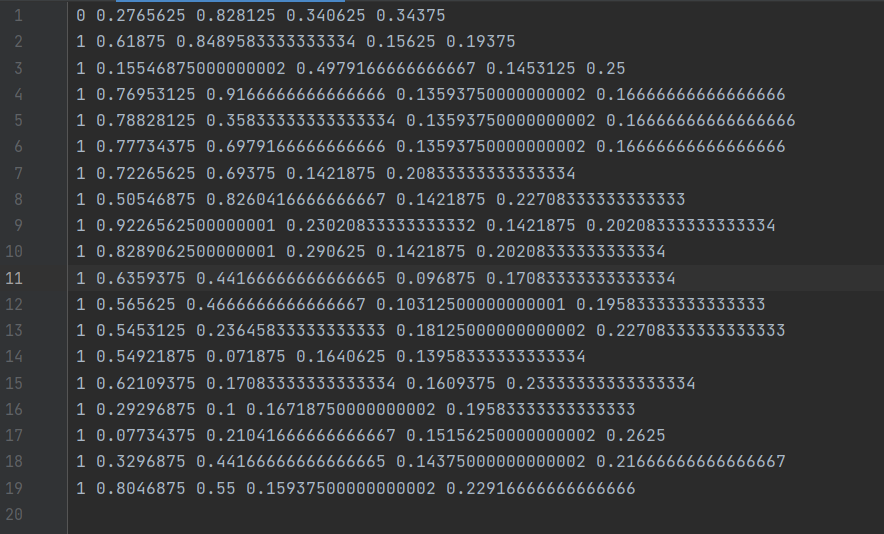
接下来切分数据集,对于我们标注的图片需要进行切分成训练集和验证集(一般比例是8:2)训练集放入创建的images/train中,验证集放入images/val中,训练的图片对应的.txt文件放入labels/train中,验证的图片对应的.txt文件放入labels/val中。(训练和验证的图片和.txt文档的数量一定要对应)
*以上是完整的对于数据文件的划分。
四.构造自己的.yaml文件
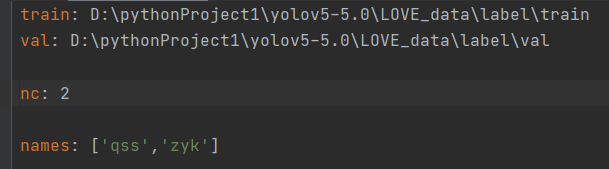
因为yolov5训练数据调用的都是.yaml文件,所以我们需要在date目录下创建一个xxx.yaml文件来存放我们已经整理好的数据,其中train存放的是我们切分好的训练.txt文件,需要存放其绝对路径(可以放相对,但要调整好目录级别)val存放的是我们切分好的验证.txt文件,路径同train一样。
nc: 存放类别个数
name:存放类别的名字(个数和nc对应)
如图:
五.运行train.py文件训练
开始训练我们的数据集,运行train.py需要注意这几个参数。
--weight 先选用官方的yolov5s.pt权重
--cfg 选用model目录下的yolov5s模型
--date选用自己编写的.yaml文件
--epoch指的就是训练过程中整个数据集将被迭代多少次,显卡不行你就调小点
--bath_size一次看完多少张图片才进行权重更新,梯度下降的mini-batch,显卡不行你就调小点
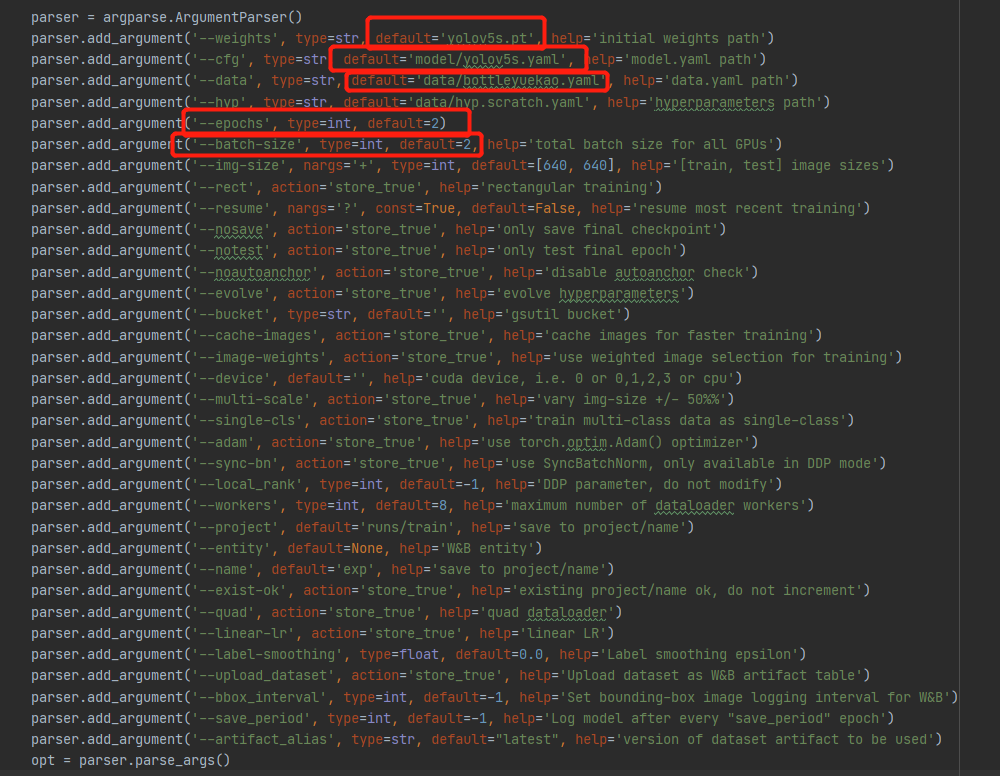
以上的参数解释如下:
img-size:输入图片宽高,显卡不行你就调小点。
rect:进行矩形训练
resume:恢复最近保存的模型开始训练
nosave:仅保存最终checkpoint
notest:仅测试最后的epoch
evolve:进化超参数
bucket:gsutil bucket
cache-images:缓存图像以加快训练速度
weights:权重文件路径
name: 重命名results.txt to results_name.txt
device:cuda device, i.e. 0 or 0,1,2,3 or cpu
adam:使用adam优化
multi-scale:多尺度训练,img-size +/- 50%
single-cls:单类别的训练集
六.查看训练好的权重及可视化日志
训练生成好的文件会在一个run文件中(代码跑完自己生成)。
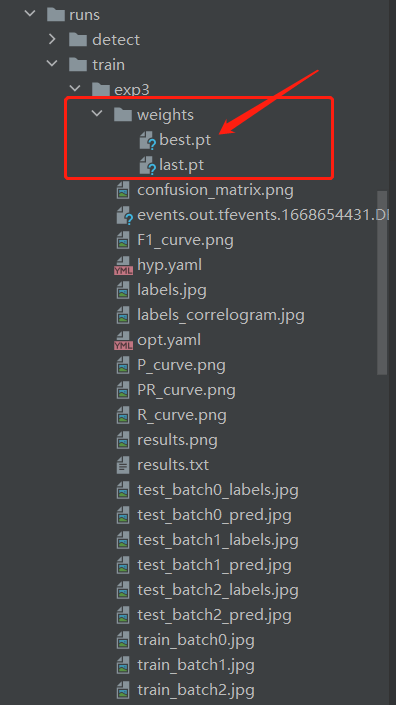
注:生成的一些信息都存在这个文件里面,红标箭头标出的权重就是我们所训练好以后需要的内容。
*训练过程可视化
利用tensorboard可视化训练过程,使用tensorboard打开即可查看训练日志。
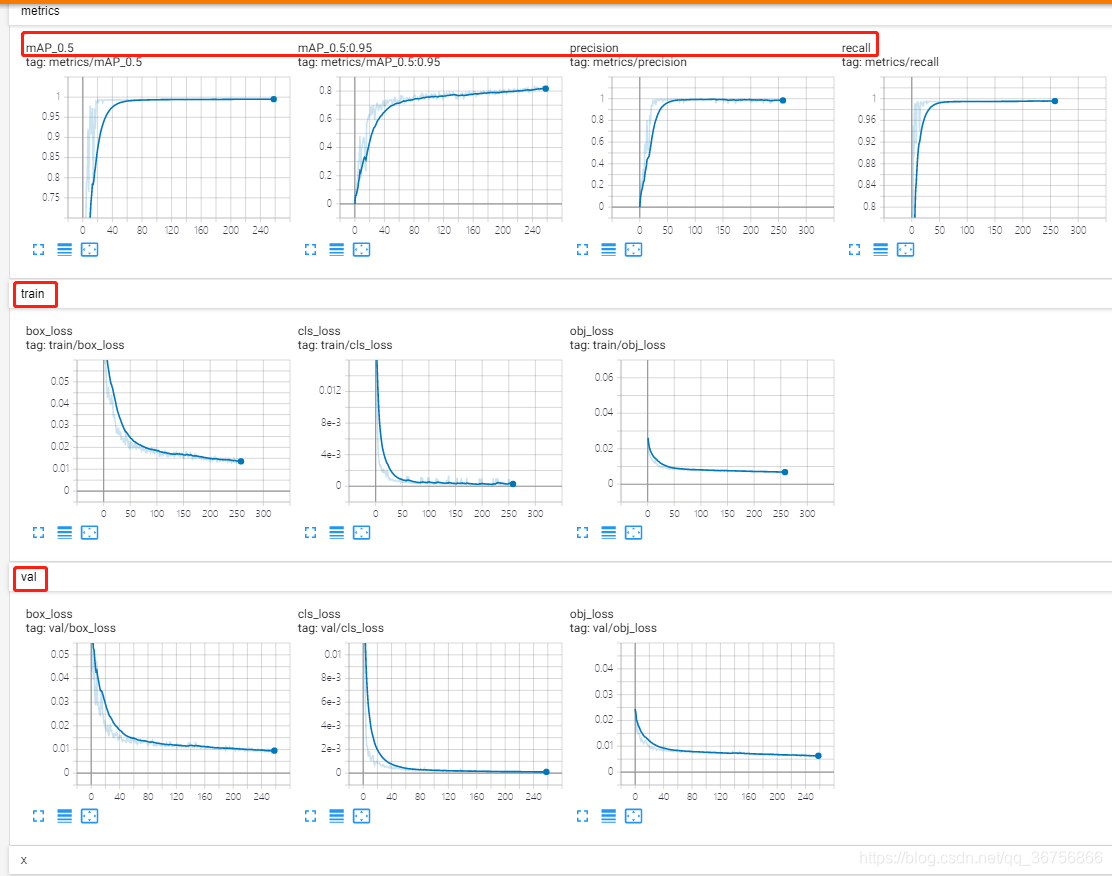
我们可以拿出best.pt权重来进行测试和推理这些会在另一篇博客中讲解,以上就是使用yolov5训练自己的数据集的全部内容。
感谢大家阅读!???