张士玉小黑屋
一个关注IT技术分享,关注互联网的网站,爱分享网络资源,分享学到的知识,分享生活的乐趣。
当前位置:首页 » 《随便一记》 - 第117页
【华为OD机试 真题2023 Q1】
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 432次

2023Q1新题库,实时更新中!!!!!【华为OD机试】-真题!!点这里!!【华为OD机试】真题考点分类!!点这里!!这些题目每一道博主都刷了至少两遍,对每一个题目都有自己的见解和思考。每行代码都蕴含着了博主从业以来所积累的经验和技巧,可谓干货满满。对于一些难度较大的题目,博主在网上搜集了各位大佬的思路,花费了大量时间精力筛选出最优的解题方法分享给大家,避免了各位东拼西凑去找答案的窘迫,只要能帮助大家顺利通过机考,我的所有努力和付出都是值得的!也希望大家考试通过后,都能来博主这里分享成功的经验!100分题目序号题目分数1租车骑绿岛1002字符串重新排列1003箱子之字形摆放1004完美走位1005模拟商场优惠打折1006密室逃生游戏1007核酸检测安排1008
Mybatis(五):动态SQL
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 363次

Mybatis(五):动态SQL前言一、if二、where三、trim四、choose、when、otherwise五、foreach1.示例一2.示例二六、SQL片段前言本博主将用CSDN记录软件开发求学之路上亲身所得与所学的心得与知识,有兴趣的小伙伴可以关注博主!也许一个人独行,可以走的很快,但是一群人结伴而行,才能走的更远!分享ChatGPT的相关资料文档、最新资讯、玩法和创意,获取第一手信息,一起走在AI时代的最前线!前100名加入可赠送ChatGPT账号!加入链接:https://t.zsxq.com/0cStvoskDMybatis框架的动态SQL技术是一种根据特定条件动态拼装SQL语句的功能,它存在的意义是为了解决拼接SQL语句字符串时的痛点问
[ 环境搭建篇 ] 安装python环境并配置环境变量(附python3.10.3安装包)
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 522次
![[ 环境搭建篇 ] 安装python环境并配置环境变量(附python3.10.3安装包)](http://zhangshiyu.com/zb_users/upload/2023/04/20230415174905168155214558428.png)
?博主介绍??博主介绍:大家好,我是_PowerShell,很高兴认识大家~✨主攻领域:【渗透领域】【数据通信】【通讯安全】【web安全】【面试分析】?点赞➕评论➕收藏==养成习惯(一键三连)??欢迎关注?一起学习?一起讨论⭐️一起进步?文末有彩蛋?作者水平有限,欢迎各位大佬指点,相互学习进步!文章目录?博主介绍一、下载安装python1、下载python2、安装python1.选择安装方式2.配置安装选项3.开始安装4.查看安装目录5.进入python交互式解释器6.检查环境变量二、python环境变量配置过程1、配置环境变量2、配置成功三、相关资源一、下载安装python1、下载python下载链接在文末给出,下载之后是一个p
chatgpt实际是怎样工作的?
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 405次
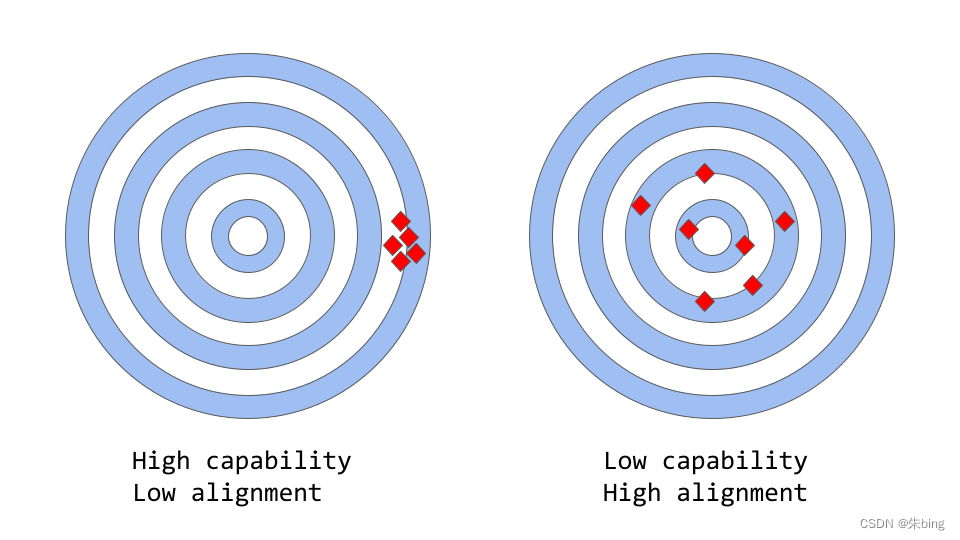
文章翻译自:https://www.assemblyai.com/blog/how-chatgpt-actually-works/ChatGPT是OpenAI的最新语言模型,比其前身GPT-3有了重大改进。与许多大型语言模型类似,ChatGPT能够为不同目的生成多种样式的文本,但具有更高的精确度、细节和连贯性。它代表了OpenAI大型语言模型系列的下一代产品,其设计非常注重交互式对话。创建者结合使用监督学习和强化学习来微调ChatGPT,但正是强化学习组件使ChatGPT独一无二。创作者使用一种称为人类反馈强化学习(RLHF)的特殊技术,该技术在训练循环中使用人类反馈来最大限度地减少有害、不真实和/或有偏见的输出。在了解RLHF的工作原理和了解Chat
【第十一届泰迪杯数据挖掘挑战赛】A 题:新冠疫情防控数据的分析 思路+代码(持续更新)
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 369次
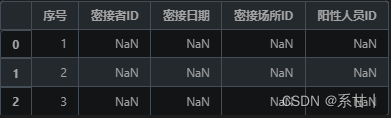
【第十一届泰迪杯数据挖掘挑战赛】A题:新冠疫情防控数据的分析思路+代码(持续更新)问题背景解决问题代码下载数据分析Task1Task2Task3Task4问题背景自2019年底至今,全国各地陆续出现不同程度的新冠病毒感染疫情,如何控制疫情蔓延、维持社会生活及经济秩序的正常运行是疫情防控的重要课题。大数据分析为疫情的精准防控提供了高效处置、方便快捷的工具,特别是在人员的分类管理、传播途径追踪、疫情研判等工作中起到了重要作用,为卫生防疫部门的管理决策提供了可靠依据。疫情数据主要包括人员信息、场所信息、个人自查上报信息、场所码扫码信息、核酸采样检测信息、疫苗接种信息等。本赛题提供了某市新冠疫情防疫系统的相关数据信息,请根据这些数据信息进行综合分析,主要任务包括数据仓库设计、疫情传播
spring boot中使用雪花算法生成雪花ID
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 375次
目录1、什么是雪花算法2、雪花算法的优缺点3、springboot项目中使用雪花算法使用1、什么是雪花算法雪花算法(Snowflake)是一种生成全局唯一ID的算法,由Twitter公司开发。它可以在分布式系统中生成全局唯一的ID,解决分布式系统中的数据合并和分片等问题。雪花算法生成的ID是一个64位的长整型数字,由以下部分组成:1个bit:符号位,始终为0。41个bit:时间戳,精确到毫秒级别,可以使用69年。10个bit:工作机器ID,可以部署在1024个节点上。12个bit:序列号,每个节点每毫秒内最多可以生成4096个ID。雪花算法生成ID的过程非常简单,首先记录一个开始时间,然后每次生成ID时计算当前时间和开始时间之间的时间差,将时间戳和工作机器
基于yolov5的遥感图像目标检测(NWPU VHR-10)
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 587次

最近在做毕设,感觉网上信息不是很全,把自己的训练过程写下来供做这个方向的友友学习。只有简单的复现,其余的还没探索到。一、数据集以及数据预处理首先就是数据集:我用的数据集是西工大发布的数据集,NWPUVHR-10链接:https://pan.baidu.com/s/1vfhDU2ORWUpL-aGM1PllGw 提取码:d5au西工大数据集有十个类别,有三个文件夹,分别是positiveimageset(650张图片),negativeimageset(150张图片)和groundtruth(650个txt文件)。negativeimageset中的影像无对应的地物目标,positiveimageset中的影像包括1个及以上对应的地物目标,groundtr
【机器学习(一)】线性回归之最小二乘法
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 337次

文章目录专栏导读1、线性回归简介2、最小二乘法原理3、实战案例专栏导读✍作者简介:i阿极,CSDNPython领域新星创作者,专注于分享python领域知识。✍本文录入于《数据分析之术》,本专栏精选了经典的机器学习算法进行讲解,针对大学生、初级数据分析工程师精心打造,对机器学习算法知识点逐一击破,不断学习,提升自我。✍订阅后,可以阅读《数据分析之术》中全部文章内容,详细介绍数学模型及原理,带领读者通过模型与算法描述实现一个个案例。✍还可以订阅基础篇《数据分析之道》
【深度学习】详解 BEiT
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 773次

目录摘要 一、引言二、方法2.1图像表示2.1.1图像patch2.1.2视觉token2.2主干网络:图像Transformer2.3预训练BEiT:掩码图像建模2.4从变分自动编码器的角度来看2.5预训练设置 2.6在下游视觉任务微调BEiT三、实验3.1图像分类3.2语义分割3.3消融实验四、相关工作五、总结六、核心代码Title:BEIT:BERTPre-TrainingofImageTransformersPaper:https://arxiv.org/abs/2106.08254GitHub: unilm/beitatmaster·microsoft/unilm·GitHub摘要
目标检测算法——YOLOv5/YOLOv7改进之结合ASPP(空洞空间卷积池化金字塔)
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 417次

??>>>加勒比海带,QQ2479200884<<<????>>>【YOLO魔法搭配&论文投稿咨询】<<<??✨✨>>>学习交流|温澜潮生|合作共赢|共同进步<<<✨✨??>>>人工智能|计算机视觉|深度学习Tricks|第一时间送达<<<??目录一、前沿介绍1.空洞卷积(AtrousConvolution)2.空洞空间卷积池化金字塔(AtrousSpatialPyramidPooling)二、YOLOv5/YOLOv7改进之结合ASPP1.配置common.py文件2.配置yolo.
Copyright © 2020-2022 ZhangShiYu.com Rights Reserved.豫ICP备2022013469号-1