张士玉小黑屋
一个关注IT技术分享,关注互联网的网站,爱分享网络资源,分享学到的知识,分享生活的乐趣。
当前位置:首页 » 计划 - 第1页
ndnSIM学习(三)——ndnSIM源码阅读计划_MamiyaHasaki的博客
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 458次

文章目录源码阅读计划官方给的文件目录结构目标制定源码阅读计划作为一个ndnSIM的初学者,根据师姐的建议,先看这些内容,用以对整个ndnSIM的结构有着初步的了解(注意:我的目录中的newndnSIM对于普通人而言一般是ndnSIM目录,xxx.*代表xxx.cppxxx.hpp等)——~/newndnSIM/ns-3/src/ndnSIM/apps目录
MybatisPlus实现分页查询和动态SQL查询_在这个充满危险的乱世之中,只有学会烤鸡才能顽强的活下去。
发布 : zsy861 | 分类 : 《休闲阅读》 | 评论 : 0 | 浏览 : 451次
一、描述实现下图中的功能,分析一下该功能,既有分页查询又有根据计划状态、开始时间、公司名称进行动态查询。二、实现方式Controller层/***@paramuserId专员的id*@paramplanState计划状态*@paramplanStartTime计划开始时间*@paramemtCode公司名称-分身id*
最高年薪201万!武大94年计算机博士入选华为“天才少年”计划_idol24的博客
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 520次

点击上方“机器学习与生成对抗网络”,关注星标获取有趣、好玩的前沿干货!文自新智元 来源:武汉大学等 编辑:David【新智元导读】近日,27岁武大计算机博士江奎入选华为“天才少年”计划,这项计划于2019年设立,旨在用“顶级的挑战和顶级的薪酬去吸引顶尖人才”,最高年薪可达201万元。一起来认识这位阳光满满的学霸。江山代有才人出,今年出得格外快!近日,又一位计算机领域的青年才俊入选华为的“天才少年”计划!“天才少年”计划是华为创始人任正非201
性能分析之子锁存器(latch)到 SQL(Oracle)_Mo小泽的技术博客
发布 : zsy861 | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 453次

这几天碰到一个事情,有必要记录一下。在一个项目中,压力测试工具中一个业务响应时间变长,数据库(Oracle)CPU使用率99%以上。从AWR报告上看到如下信息:在性能项目的沟通中,经常是在这样的时候,我们就去告诉开发说现在的状态是CPU使用率高,把AWR报告往开发那里一发,性能团队的人员就喝咖啡去了。但是性能如果只是做到这里,沟通其实
通过扩展 Spark SQL ,打造自己的大数据分析引擎_麒思妙想
发布 : zsy861 | 分类 : 《关注互联网》 | 评论 : 0 | 浏览 : 522次

SparkSQL的Catalyst,这部分真的很有意思,值得去仔细研究一番,今天先来说说Spark的一些扩展机制吧,上一次写Spark,对其SQL的解析进行了一定的魔改,今天我们按套路来,使用砖厂为我们提供的机制,来扩展Spark...首先我们先来了解一下SparkSQL的整体执行流程,输入的查询先被解析成未关联元数据的逻辑计划,然后根据元数据和解析规则,生成逻辑计划,再经过优化规则,形成优化过的逻辑计划(RBO)&
Python 之父爆料:明年至少令 Python 提速 1 倍!_Python猫
发布 : zsy861 | 分类 : 《资源分享》 | 评论 : 0 | 浏览 : 556次
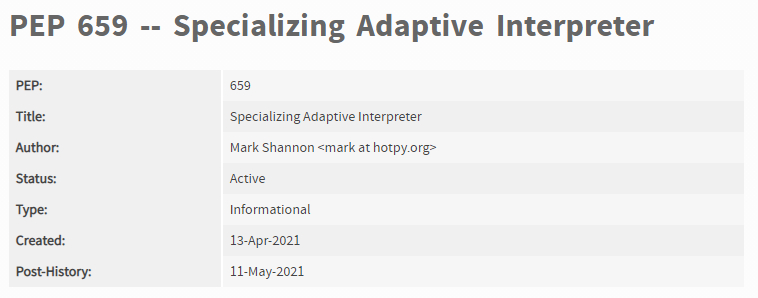
大概在半年前,我偶然看到一篇文章,有人提出了给Python提速5倍的计划,并在寻找经费赞助。当时并没有在意,此后也没有看到这方面的消息。但是,就在5月13日“2021年Python语言峰会”上,Python之父GuidovanRossum作了一场《MakingCPythonFaster》的分享,他已经投入了这项计划!据Guido爆料,他因为“退休
Copyright © 2020-2022 ZhangShiYu.com Rights Reserved.豫ICP备2022013469号-1