使用 OpenAI 的 Embeddings 接口是有费用的,如果想对大量文档进行测试,使用本地部署的 Embeddings 就能省去大量的费用,所以我们尝试使用本地的 Ollama Embeddings。
首先本地安装 Ollama: https://ollama.com/download
即使你电脑没有性能很强的显卡,仅仅依靠 CPU 也能运行一些参数量较小的模型。ollama 中下载量最多的是 llama2 模型,但是这个模型对中文支持不太好,我们可以试试 Google 开源的 gemma 模型:
https://ollama.com/library/gemma
这个模型包含几个不同的版本,默认为 7b 的版本,可以先试试 7b,如果速度太慢可以换 2b 试试,执行命令 ollama run gemma 时会下载模型并运行,模型默认会下载到用户目录中的 .ollama 中,如果用户目录(一般在C盘)所在盘空间少,可以提前通过环境变量方式修改位置,参考下面的配置(改成自己的路径):
OLLAMA_MODELS=D:\.ollama如果不会在 Windows 创建 .前缀的目录,也可以用正常目录,也可以打开 git bash,使用命令 mkdir .ollama 创建
配置环境变量后一定打开一个新的 CMD 或者 Terminal,然后执行 ollama rum gemma 下载并启动模型(已经下载到用户目录的模型可以整体移动到新的目录)。启动后可以在控制台进行对话,如下所示:
>ollama run gemma>>> 你好你好!我很好,谢谢您的问候。您想让我做什么呢?我能够帮助您吗?接下来在 Spring AI 中使用该模型,首先引入Maven依赖:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-ollama-spring-boot-starter</artifactId></dependency>通过下面示例代码运行:
var ollamaApi = new OllamaApi();var chatClient = new OllamaChatClient(ollamaApi).withModel("gemma").withDefaultOptions(OllamaOptions.create().withModel("gemma").withTemperature(0.9f));Scanner scanner = new Scanner(System.in);while (true) {System.out.print(">>> ");String message = scanner.nextLine();if (message.equals("exit")) {break;}String resp = chatClient.call(message);System.out.println("<<< " + resp);}接口使用很简单,下面再看如何使用 Ollama 的 Embeddings。
var ollamaApi = new OllamaApi();//指定使用的模型var embeddingClient = new OllamaEmbeddingClient(ollamaApi).withDefaultOptions(OllamaOptions.create().withModel("gemma"));//测试数据VectorStore vectorStore = new SimpleVectorStore(embeddingClient);vectorStore.add(List.of(new Document("白日依山尽,黄河入海流。欲穷千里目,更上一层楼。"),new Document("青山依旧在,几度夕阳红。白发渔樵江渚上,惯看秋月春风。"),new Document("一片孤城万仞山,羌笛何须怨杨柳。春风不度玉门关。"),new Document("危楼高百尺,手可摘星辰。不敢高声语,恐惊天上人。")));Scanner scanner = new Scanner(System.in);while (true) {System.out.print("请输入关键词: ");String message = scanner.nextLine();if (message.equals("exit")) {break;}List<Document> documents = vectorStore.similaritySearch(message);System.out.println("查询结果: ");for (Document doc : documents) {System.out.println(doc.getContent());}}在我本地运行时(靠CPU),解析文档耗时如下:
10:33:10.423 - Calling EmbeddingClient for document id = 44d0114f-62ae-4d05-9e6d-457f157386ce10:33:16.201 - Calling EmbeddingClient for document id = ac65024a-26a9-4827-af4c-af48a3321a4b10:33:22.176 - Calling EmbeddingClient for document id = 53747918-8e8e-42e1-b4e6-3792c24b688110:33:26.125 - Calling EmbeddingClient for document id = 63123b8d-b475-48b4-b38e-71dbf1b49250每一条文本耗时在6秒左右。解析完成后输入提示词进行验证:
请输入关键词: 春风查询结果: 青山依旧在,几度夕阳红。白发渔樵江渚上,惯看秋月春风。一片孤城万仞山,羌笛何须怨杨柳。春风不度玉门关。白日依山尽,黄河入海流。欲穷千里目,更上一层楼。危楼高百尺,手可摘星辰。不敢高声语,恐惊天上人。请输入关键词: 黄河查询结果: 青山依旧在,几度夕阳红。白发渔樵江渚上,惯看秋月春风。一片孤城万仞山,羌笛何须怨杨柳。春风不度玉门关。白日依山尽,黄河入海流。欲穷千里目,更上一层楼。危楼高百尺,手可摘星辰。不敢高声语,恐惊天上人。春风的结果还可以,但是黄河的结果就不对了。
如何使用其他模型进行 Embedding 呢?
只要启动了任何一个模型,我们通过修改上面的 withModel("gemma") 中的参数即可使用其他模型,如果本地下载过 llama2 模型,就可以直接改这里的参数,不需要重新执行 ollama run llama2 命令,这个命令影响 chat 功能的使用,不影响 embedding。如果指定的模型不存在,会提示如下信息:
[404] Not Found - {"error":"model 'llama2' not found, try pulling it first"}可以通过 ollama pull llama2 进行下载。
我们还可以搜专门的 embedding 模型,搜索时注意下图搜索的位置:
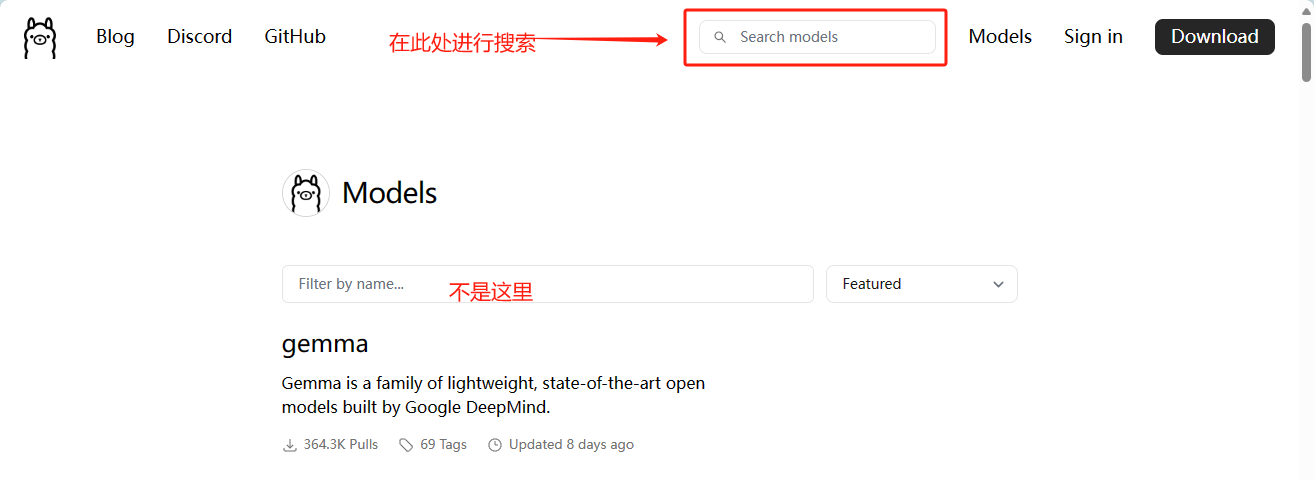
顶部可以搜索全局的模型,不限于官方 library 下面的模型,搜索 embedding 结果如下:
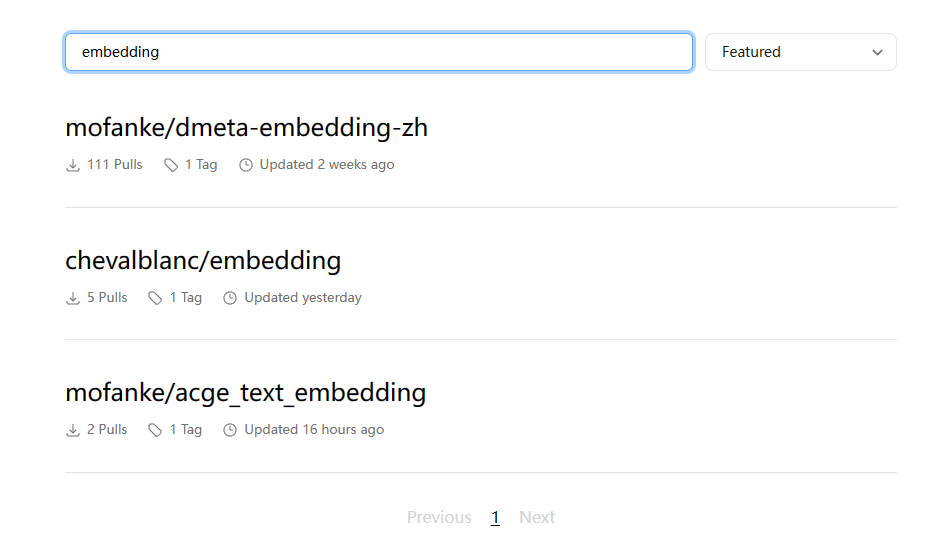
我们可以试试 mofanke/dmeta-embedding-zh 这个模型,还有一个 mofanke/acge_text_embedding 是我联系作者后,作者新提供的模型,后面文章也会以这个为例介绍如何将 huggingface 上的模型转换为 ollama 的模型来使用。
使用命令 ollama pull mofanke/dmeta-embedding-zh 下载模型,这个模型不能通过 ollama run xxx 启动,需要通过其他模型启动后来引用,还使用前面的 ollama run gemma,下载完模型后修改 withModel("mofanke/dmeta-embedding-zh"),然后进行测试即可。
Ollama 的存在使得 Java 调用各种开源大模型变得更统一更简单,就好比大部分商业大模型都参考 OpenAI 的 API,方便我们调用一样。通过 Ollama 的扩展方式,还可以方便我们导入官方仓库不存在的其他模型,后续文章会以 acge_text_embedding 为例介绍如何自定义基于 PyTorch 的模型。