目录
前言
一、信息网站介绍
1、网站介绍
2、 地震历史信息
3、 历史信息接口分析
二、XxlCrawler组件
1、关于XxlCrawler
2、核心概念介绍
三、实际信息爬取
1、新建maven项目
2、新建model层对象
3、实际爬取
总结
前言
如今,只要谈起网络信息爬取也就是爬虫,相信绝大多数人的第一反应就是Python。确实Python在信息爬取方面资料很多,内容很丰富,同时案例也很丰富。爬虫技术是一门有一定门槛的技术。而在网络请求当中,不管是出于攻方或者是守方。有一句话是,你站在桥上看风景,看风景的人站在楼上看你。在获取信息和作为信息源头提供信息,如今都已经家常便饭,习以为常。你可以使用熟悉的语言和技术栈来实现爬虫,去爬取相应的知识,但是要用于正当目的。
在之前的博客当中,我们介绍了一些地震相关的博客,想把地震种类的地质灾害作为GIS的时空数据源来和人类活动轨迹和生活范围进行关联分析,为人类提供安全保障,为较少财产损失贡献自己的力量。为了对地震有更多的认识,我们需要将地震信息进行详细的搜集。通过长时序的地震信息搜集,为进一步的数据挖掘提供坚实的数据基础。由此,我们需要从中国地震台网挖掘。楼主采用熟悉的java技术栈,通过java语言去获取中国地震台网的信息。
本文将主要讲解使用Java语言结合XxlCrawler框架进行信息的抓取。首先讲解目标网站的相关信息,分析内容和需要抓取的链接地址,URL的构造,然后介绍XxlCrawler这个组件的相关使用情况,最后使用代码进行实际信息抓取的开发。方便大家对如何使用Java和XxlCrawler来实现信息爬取有一定的参考和指导。
一、信息网站介绍
本节对中国地震台网进行简要介绍。
1、网站介绍
CEIC.ac.cn是在中国地震台网中心资助科研项目的研究成果,它于2006年1月上线运行,之后陆续完善。根据中国 地震局监测预报司的要求(2008年第168号文件),网站从现在起用于地震信息及其相关数据产品的发布,根据要求,新 版网站于2009年5月起正式运行。中国地震台网中心于2004年10月18日成立,它是中国地震局直属事业单位,是我国防震减灾工作的重要业务枢纽、 核心技术平台和基础信息国际交流的重要窗口。中国地震台网中心承担着全国地震监测、地震中短期预测和地震速报;国 务院抗震救灾指挥部应急响应和指挥决策技术系统的建设和运行;全国各级地震台网的业务指导和管理;各类地震监测数 据的汇集、处理与服务。
2、 地震历史信息
在地震历史中可以查询到近10年的地震信息,可以在官方网站中打开历史查询tab页。默认不输入任何条件,查询近期的地震信息。界面如下所示:
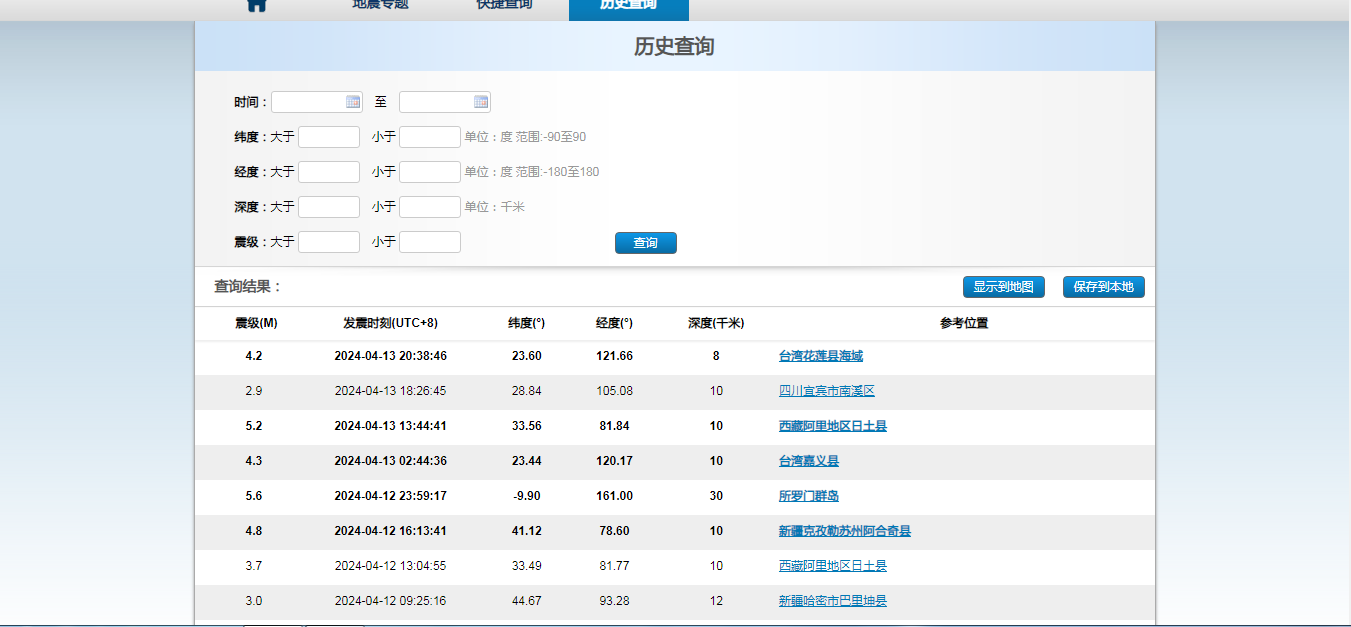
这就是地震信息,我们如果想要得到这信息,也就是根据接口把相应的历史信息取到即可。下面来看一下系统是怎么获取到这些信息的。
3、 历史信息接口分析
在上面的网页中,来看一下具体的信息获取接口。在谷歌浏览器中打开检查选项。
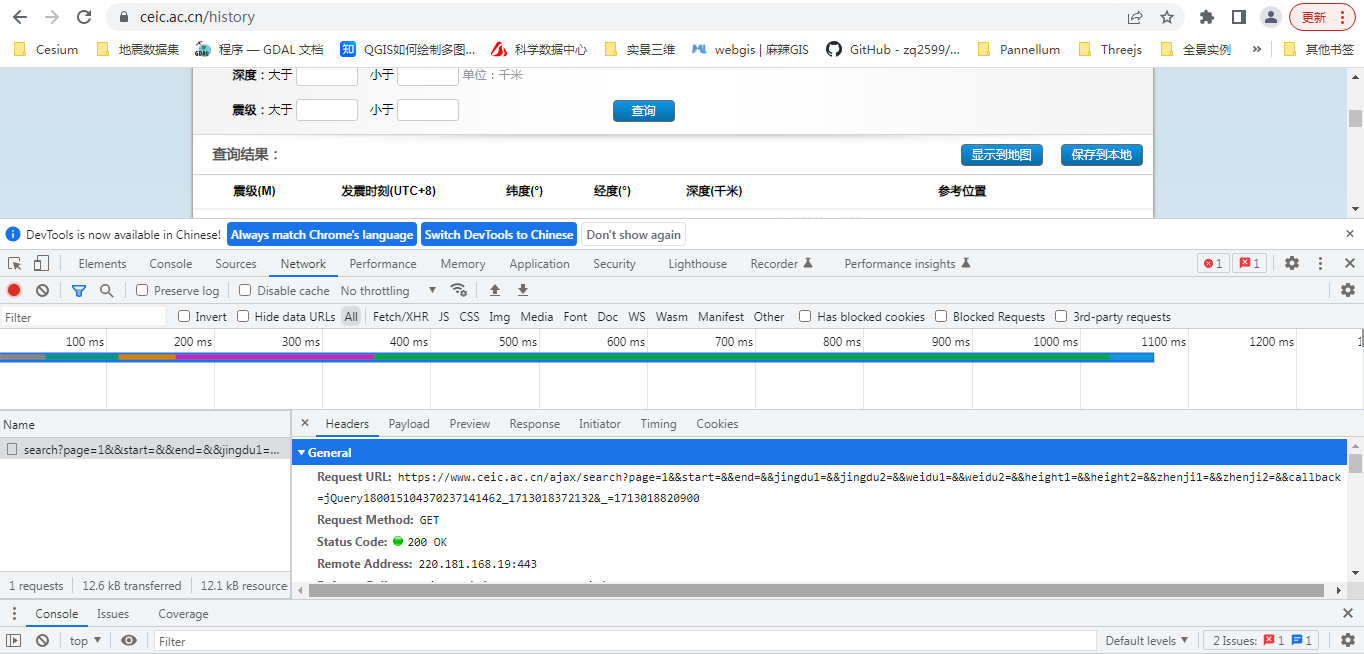
可以很清楚的看到,点击查询按钮之后。它的网络接口是:
https://www.ceic.ac.cn/ajax/search?page=1&&start=&&end=&&jingdu1=&&jingdu2=&&weidu1=&&weidu2=&&height1=&&height2=&&zhenji1=&&zhenji2=&&callback=jQuery180015104370237141462_1713018372132&_=1713018820900在这个接口中,有一个page的页数控制,通过这个参数来进行分页。因此我们只需要在请求中模拟页数的传递即可获取相应的数据。
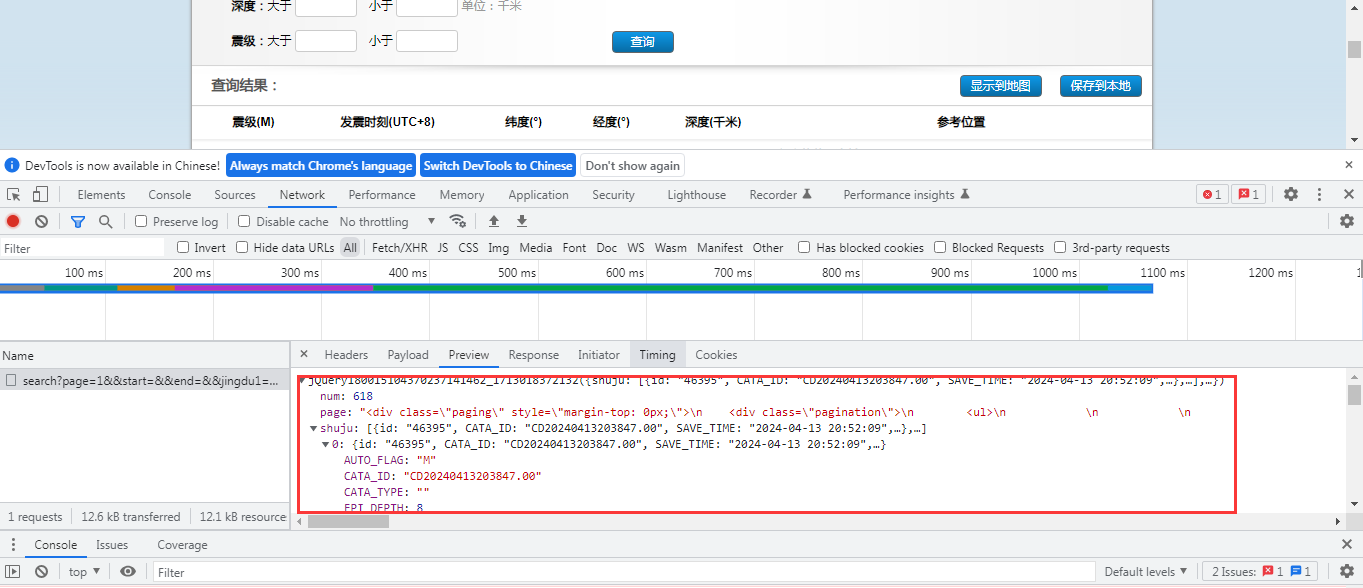
将上述的地址复制到浏览器中,可以看到以下的返回响应数据。
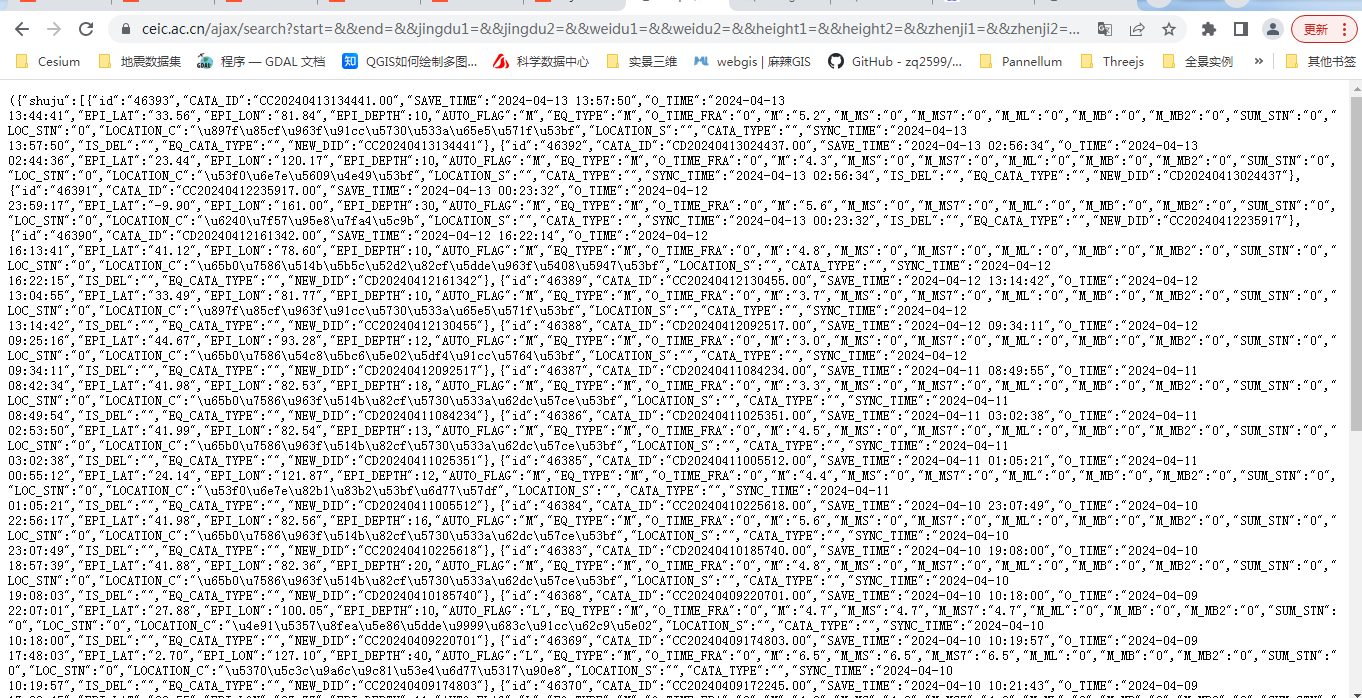
数据的主要信息包含以下:
AUTO_FLAG: "M"CATA_ID: "CD20240413222636.00"CATA_TYPE: ""EPI_DEPTH: 9EPI_LAT: "24.05"EPI_LON: "121.60"EQ_CATA_TYPE: ""EQ_TYPE: "M"IS_DEL: ""LOCATION_C: "台湾花莲县"LOCATION_S: ""LOC_STN: "0"M: "4.2"M_MB: "0"M_MB2: "0"M_ML: "0"M_MS: "0"M_MS7: "0"NEW_DID: "CD20240413222636"O_TIME: "2024-04-13 22:26:35"O_TIME_FRA: "0"SAVE_TIME: "2024-04-13 22:35:56"SUM_STN: "0"SYNC_TIME: "2024-04-13 22:35:56"id: "46396"其主要的信息包括num即数据总页数,是按照每页20条数据来展示的,还有page分页条,对于数据爬取,分页条信息不是最重要的,最重要是shuju,在接口中以shuju字段来返回。以上信息非常重要,在后续的信息爬取过程当中很重要。
二、XxlCrawler组件
本小节将重点介绍一个信息爬取框架XxlCrawler,通过这个框架来爬取相关信息。关于XxlCrawler,在其官网网站上有一定的介绍,这里不做很深入的介绍。
1、关于XxlCrawler
XXL-CRAWLER 是一个分布式爬虫框架。一行代码开发一个分布式爬虫,拥有”多线程、异步、IP动态代理、分布式、JS渲染”等特性;这是一位技术功底很深厚的专家贡献的开源框架。xxl-crawler。除了信息爬取框架,还有其它很有用的组件。下面是它的核心架构图:
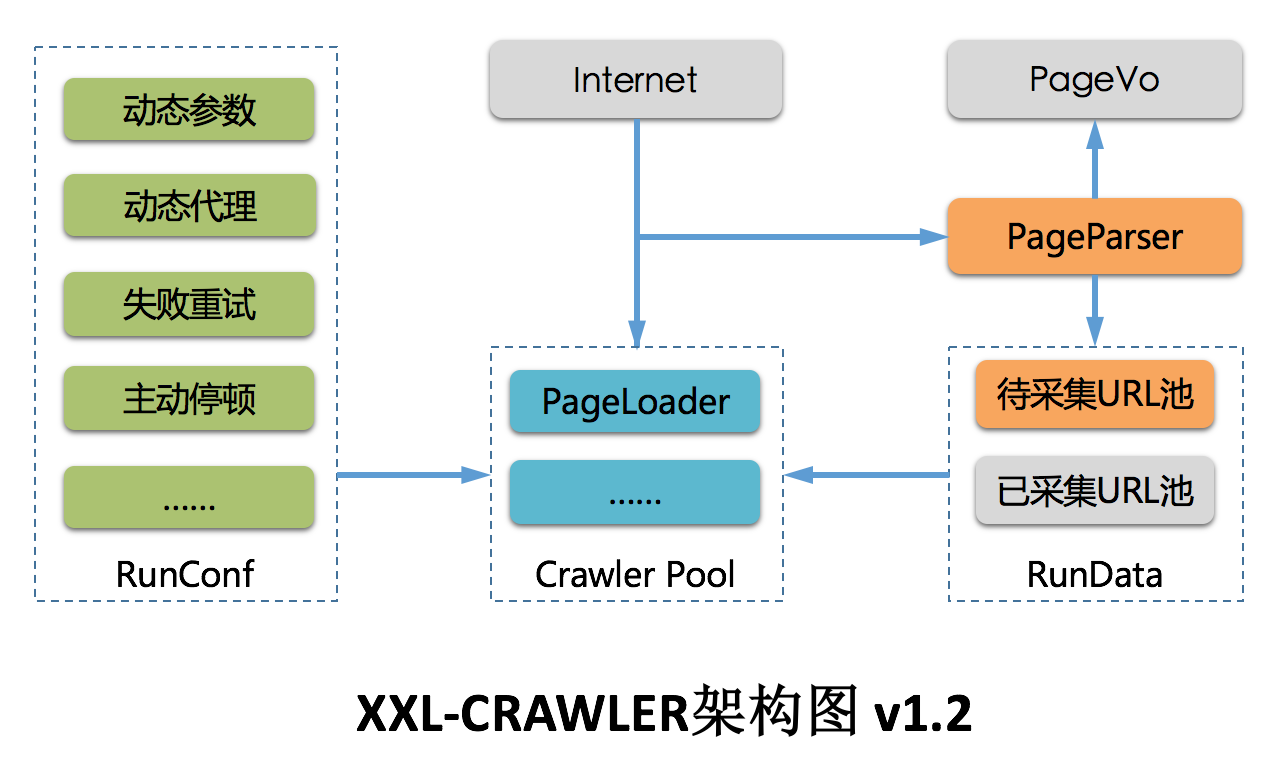
XXL-CRAWLER 是一个分布式Web爬虫框架。采用模块化设计,各个模块可灵活进行自定义和扩展。借助 XXL-CRAWLER,一行代码开发一个分布式爬虫。大家在使用过程当中,要自己进行合理的扩展,根据自己的业务来进行编码才能开发出符合要求的。
2、核心概念介绍
| 概念 | 说明 |
|---|---|
| XxlCrawler | 爬虫对象,维护爬虫信息 |
| PageVo | 页面数据对象,一张Web页面可抽取一个或多个PageVo |
| PageLoader | Wed页面加载器,负责加载页面数据,支持灵活的自定义和扩展 |
| PageParser | Wed页面解析器,绑定泛型PageVO后将会自动抽取页面数据对象,同时支持运行时调整请求参数信息; |
NonPageParser : 非Web页面解析器,如JSON接口等,直接输出响应数据。比如这里的地震信息查询接口返回的就是json的数据格式。
XxlCrawler的属性
| 方法 | 说明 |
|---|---|
| setUrls | 待爬的URL列表 |
| setAllowSpread | 允许扩散爬取,将会以现有URL为起点扩散爬取整站 |
| setWhiteUrlRegexs | URL白名单正则,非空时进行URL白名单过滤页面 |
| setIfPost | 请求方式:true=POST请求、false=GET请求 |
| setUserAgent | UserAgent |
| setParamMap | 请求参数 |
| setCookieMap | 请求Cookie |
| setTimeoutMillis | 超时时间,毫秒 |
| setPauseMillis | 停顿时间,爬虫线程处理完页面之后进行主动停顿,避免过于频繁被拦截; |
| setProxyMaker | 代理生成器,支持设置代理IP,同时支持调整代理池实现动态代理; |
| setThreadCount | 爬虫并发线程数 |
| setPageParser | 页面解析器 |
| setPageLoader | 页面加载器,默认提供 “JsoupPageParser” 和 “HtmlUnitPageLoader” 两种实现; |
| setRunData | 设置运行时数据模型,默认提供LocalRunData单机模型,支持扩展实现分布式模型; |
| start | 运行爬虫,可通过入参控制同步或异步方式运行 |
| stop | 终止爬虫 |
三、实际信息爬取
本节将重点讲述如何使用java语言基于XxlCrawler进行信息抓取的开发。首先讲解XxlCrawler来进行信息的获取,然后讲解如何将json数据转换成javaBean,不管以后用来存为Excel或者入库,比如保存到关系型数据库,都是需要采用JavaBean的。
1、新建maven项目
首先,新建一个maven项目,在pom.xml中引入相关的资源,首先便是XxlCrawler,然后是json处理工具,这里使用Gson,最后为了简化对象的get和set操作,使用lombok来进行对象简化。pom.xml的关键代码如下所示:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.yelang</groupId> <artifactId>xxl-crawler-demo</artifactId> <version>0.0.1-SNAPSHOT</version> <dependencies><dependency> <groupId>com.xuxueli</groupId> <artifactId>xxl-crawler</artifactId> <version>1.3.0</version></dependency><dependency> <groupId>com.google.code.gson</groupId> <artifactId>gson</artifactId> <version>2.10.1</version></dependency><dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.30</version> <scope>provided</scope></dependency> </dependencies></project>2、新建model层对象
model层对象对应是javaBean,主要包含两个对象,第一个是大的对象,包含num和shuju的定义。由于shuju是一个数组,因此再定义一个信息对象来接收数组的值。两个类的具体代码如下:
package com.yelang.entity;import java.io.Serializable;import java.math.BigDecimal;import lombok.Data;import lombok.ToString;@Data@ToStringpublic class Earthquake implements Serializable {private static final long serialVersionUID = -1212153879708670015L;private String AUTO_FLAG;private String CATA_ID;private String CATA_TYPE;private BigDecimal EPI_DEPTH = new BigDecimal("0");private String EPI_LAT;private String EPI_LON;private String EQ_CATA_TYPE;private String EQ_TYPE;private String IS_DEL;private String LOCATION_C;private String LOCATION_S;private String LOC_STN;private String M;private String M_MB;private String M_MB2;private String M_ML;private String M_MS;private String M_MS7;private String NEW_DID;private String O_TIME;private String O_TIME_FRA;private String SAVE_TIME;private String SUM_STN;private String SYNC_TIME;private String id;public Earthquake(String aUTO_FLAG, String cATA_ID, String cATA_TYPE, BigDecimal ePI_DEPTH, String ePI_LAT,String ePI_LON, String eQ_CATA_TYPE, String eQ_TYPE, String iS_DEL, String lOCATION_C, String lOCATION_S,String lOC_STN, String m, String m_MB, String m_MB2, String m_ML, String m_MS, String m_MS7, String nEW_DID,String o_TIME, String o_TIME_FRA, String sAVE_TIME, String sUM_STN, String sYNC_TIME, String id) {super();AUTO_FLAG = aUTO_FLAG;CATA_ID = cATA_ID;CATA_TYPE = cATA_TYPE;EPI_DEPTH = ePI_DEPTH;EPI_LAT = ePI_LAT;EPI_LON = ePI_LON;EQ_CATA_TYPE = eQ_CATA_TYPE;EQ_TYPE = eQ_TYPE;IS_DEL = iS_DEL;LOCATION_C = lOCATION_C;LOCATION_S = lOCATION_S;LOC_STN = lOC_STN;M = m;M_MB = m_MB;M_MB2 = m_MB2;M_ML = m_ML;M_MS = m_MS;M_MS7 = m_MS7;NEW_DID = nEW_DID;O_TIME = o_TIME;O_TIME_FRA = o_TIME_FRA;SAVE_TIME = sAVE_TIME;SUM_STN = sUM_STN;SYNC_TIME = sYNC_TIME;this.id = id;}public Earthquake() {super();}}package com.yelang.entity;import java.io.Serializable;import java.util.List;import lombok.Data;import lombok.ToString;@Data@ToStringpublic class EarthquakeCrawler implements Serializable {private static final long serialVersionUID = 2968933968732310138L;private Integer num;private List<Earthquake> shuju;public EarthquakeCrawler(Integer num, List<Earthquake> shuju) {super();this.num = num;this.shuju = shuju;}public EarthquakeCrawler() {super();}}3、实际爬取
package com.yelang.test;import java.util.Random;import org.jsoup.internal.StringUtil;import com.google.gson.Gson;import com.xuxueli.crawler.XxlCrawler;import com.xuxueli.crawler.parser.strategy.NonPageParser;import com.yelang.entity.Earthquake;import com.yelang.entity.EarthquakeCrawler;public class CeicCrawlerCase {public static void main(String[] args) {String commonUrl = "https://www.ceic.ac.cn/ajax/search?start=&&end=&&jingdu1=&&jingdu2=&&weidu1=&&weidu2=&&height1=&&height2=&&zhenji1=&&zhenji2=&_="+ System.currentTimeMillis();String[] urlList = new String[1];urlList[0] = commonUrl + "&&page=" + 1;// 构造爬虫XxlCrawler crawler = new XxlCrawler.Builder().setUrls(urlList).setThreadCount(3).setPauseMillis(3000).setUserAgent("Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36").setIfPost(false).setFailRetryCount(3)// 重试三次.setPageParser(new NonPageParser() {public void parse(String url, String pageSource) {if (!StringUtil.isBlank(pageSource)) {pageSource = pageSource.substring(1, pageSource.length() - 1);Gson gson = new Gson();EarthquakeCrawler crawler = gson.fromJson(pageSource, EarthquakeCrawler.class);System.out.println("总页数:"+crawler.getNum());for (Earthquake data : crawler.getShuju()) {System.out.println(data);}}}}).build();crawler.start(true);// 启动}}这里仅演示效果,请大家不要大量的请求台网,合理设置信息的获取频次。上面的代码运行之后,可以在控制台看到以下的信息,即表示成功的获取历史地震信息,同时将字符串转换成了JavaBean。至此,一个使用java开发的信息抓取程序开发完毕。
SLF4J: No SLF4J providers were found.SLF4J: Defaulting to no-operation (NOP) logger implementationSLF4J: See https://www.slf4j.org/codes.html#noProviders for further details618Earthquake(AUTO_FLAG=M, CATA_ID=CC20240324042204.00, CATA_TYPE=, EPI_DEPTH=30, EPI_LAT=-4.15, EPI_LON=143.10, EQ_CATA_TYPE=, EQ_TYPE=M, IS_DEL=, LOCATION_C=巴布亚新几内亚, LOCATION_S=, LOC_STN=0, M=6.9, M_MB=0, M_MB2=0, M_ML=0, M_MS=0, M_MS7=0, NEW_DID=CC20240324042204, O_TIME=2024-03-24 04:22:04, O_TIME_FRA=0, SAVE_TIME=2024-03-24 04:46:33, SUM_STN=0, SYNC_TIME=2024-03-24 04:46:33, id=46219)Earthquake(AUTO_FLAG=M, CATA_ID=CC20240323212028.00, CATA_TYPE=, EPI_DEPTH=60, EPI_LAT=-4.65, EPI_LON=102.70, EQ_CATA_TYPE=, EQ_TYPE=M, IS_DEL=, LOCATION_C=印尼苏门答腊岛南部海域, LOCATION_S=, LOC_STN=0, M=5.3, M_MB=0, M_MB2=0, M_ML=0, M_MS=0, M_MS7=0, NEW_DID=CC20240323212028, O_TIME=2024-03-23 21:20:28, O_TIME_FRA=0, SAVE_TIME=2024-03-23 21:46:17, SUM_STN=0, SYNC_TIME=2024-03-23 21:46:16, id=46218)总结
以上就是本文的主要内容,本文将主要讲解使用Java语言结合XxlCrawler框架进行信息的抓取。首先讲解目标网站的相关信息,分析内容和需要抓取的链接地址,URL的构造,然后介绍XxlCrawler这个组件的相关使用情况,最后使用代码进行实际信息抓取的开发。通过本文,相信大家对XxlCrawler有了更深入的了解。示例代码供参考,请朋友合理使用资源。行文仓促,定有不足之处,环境大家批评指正。