
摘 要
随着人们对于贷款的需求量不断增加以及我国债券市场和信贷市场违约事件频发,商业银行不良资产率与用户个人贷款违约风险成为了政府和银行业关心的核心问题,而对信用贷款违约风险进行有效评估和测度也成为了商业银行提高其经营管理水平的核心要务。
本小组以金融风控中的个人信贷为背景,根据贷款申请人的数据信息预测其是否有违约的可能,我们致力建立多种机器学习模型,基于贷款违约信息的数据,进行模型训练,用来预测贷款人是否存在违约的可能。
本次实验使用了Decision tree、AdaBoost、Bagging、RandomForest、Xgboost、Lightgbm和Catboost 7种机器学习模型,使用五折交叉验证的方法,对贷款违约数据进行训练,使用AUC指标作为评估这7个模型的评估指标,得到效果最好的模型是catboost模型,它最高的AUC为74.88%,并且生成数据可视化分析报告。
关键词:数据分析;数据不平衡;机器学习;交叉验证;集成学习
基于机器学习的贷款违约预测
1. 问题描述
1.1 问题背景
近年来,我国用于买房、购车以及其他消费的贷款规模快速增长,人们对于贷款的需求不断增加,随之而来的,是我国债券市场和信贷市场违约事件频发。商业银行不良资产率与用户个人贷款违约风险成为了政府和银行业关心的核心问题,而对信用贷款违约风险进行有效评估和测度也成为了商业银行提高其经营管理水平的核心要务。
本文通过处理用户贷款数据以及贷款人的各项特征数据,分析各项特征与违约情况之间的相关性,建立个人贷款违约预测模型,帮助银行的业务人员明确客户的更多有意义的指标变量,在应对日益增多的贷款审核业务中对用户贷款风险进行预测,及早发现贷款的潜在损失,减少人工审核成本,提高预测准确率,更好地为用户提供贷款服务与业务。
本项目数据集来源于阿里天池大数据平台,以金融风控中的个人信贷为背景,根据贷款申请人的数据信息预测其是否有违约的可能,建立模型预测是否通过此项贷款。
1.2 所需关键技术
(1)matplotlib数据可视化:Matplotlib是Python中最基本的可视化工具,是一个非常简单而又完善的开源绘图库,能够以跨平台的交互式环境生成图形,用来绘制各种静态,动态,交互式的图表。
(2)seaborn数据可视化:Seaborn是基于matplotlib的图形可视化python包。它提供了一种高度交互式界面,便于用户能够做出各种有吸引力的统计图表。Seaborn是在matplotlib的基础上进行了更高级的API封装,从而使得作图更加容易,可以将Seaborn视为matplotlib的补充。
(3)pandas数据统计分析:pandas是一个以Numpy为基础的强大的分析结构化数据的工具集,为Python数据分析提供了高性能,且易于使用的数据结构。pandas提供了两种数据结构,分别是Series(一维数组结构)与DataFrame(二维数组结构),这两种数据结构极大地增强的了Pandas的数据分析能力。
(4)Scikit-learn机器学习:Scikit-learn是一个基于NumPy,SciPy,Matplotlib的开源机器学习工具包,主要涵盖分类、回归和聚类算法,例如逻辑回归、朴素贝叶斯、随机森林、SVM、k-means等算法,旨在与Python数值科学库NumPy和SciPy联合使用。
(5)PCA数据降维:PCA主成分分析是一种无监督的数据降维方法,将一个高维数据集转换为一个低维数据集。PCA降维的思想旨在减少数据集的维数,同时还保持数据集的对方差贡献最大的特征,最终使数据直观呈现在二维坐标系。
(6)集成学习:集成学习是一种通过构建并结合多个学习器来完成学习任务机器学习方法,主要是将有限的模型相互组合。集成学习就是组合多个弱监督模型以期得到一个更好更全面的强监督模型,集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。集成学习主要有Bagging、Boosting以及Stacking。
(7)网格搜索法:网格搜索法是指定参数值的一种穷举搜索方法,通过将估计函数的参数通过交叉验证的方法进行优化来得到最优的学习算法。网格搜索用于选取模型的最优超参数,算法在拟合函数尝试了所有的参数组合后,返回一个合适的分类器,自动调整至最佳参数组合。
2. 数据分析
2.1 数据获取
本文数据下载于阿里天池大数据平台,是Datawhale与天池联合发起金融风控之贷款违约预测挑战赛训练数据集。贷款违约预测数据集中包含了部分匿名特征,该数据来自某信贷平台的贷款记录,总数据量超过120w,包含47列变量信息,其中15列为匿名变量。在本次实验中,从中抽取80万条作为训练集,20万条作为测试集A。
数据集特征概况介绍如表2-1所示:
表2-1 数据集特征概况介绍
| 特征名称 | 特征含义 |
| id | 为贷款清单分配的唯一信用证标识 |
| loanAmnt | 贷款金额 |
| term | 贷款期限(year) |
| interestRate | 贷款利率 |
| installment | 分期付款金额 |
| grade | 贷款等级 |
| subGrade | 贷款等级之子级 |
| employmentTitle | 就业职称 |
| employmentLength | 就业年限(年) |
| homeOwnership | 借款人在登记时提供的房屋所有权状况 |
| annualIncome | 年收入 |
| verificationStatus | 验证状态 |
| issueDate | 贷款发放的月份 |
| purpose | 借款人在贷款申请时的贷款用途类别 |
| postCode | 借款人在贷款申请中提供的邮政编码的前3位数字 |
| regionCode | 地区编码 |
| dti | 债务收入比 |
| delinquency_2years | 借款人过去2年信用档案中逾期30天以上的违约事件数 |
| ficoRangeLow | 借款人在贷款发放时的fico所属的下限范围 |
| ficoRangeHigh | 借款人在贷款发放时的fico所属的上限范围 |
| openAcc | 借款人信用档案中未结信用额度的数量 |
| pubRec | 贬损公共记录的数量 |
| pubRecBankruptcies | 公开记录清除的数量 |
| revolBal | 信贷周转余额合计 |
| revolUtil | 循环额度利用率,或借款人使用的相对于所有可用循环信贷的信贷金额 |
| totalAcc | 借款人信用档案中当前的信用额度总数 |
| initialListStatus | 贷款的初始列表状态 |
| applicationType | 表明贷款是个人申请还是与两个共同借款人的联合申请 |
| earliesCreditLine | 借款人最早报告的信用额度开立的月份 |
| title | 借款人提供的贷款名称 |
| policyCode | 公开可用的策略_代码=1新产品不公开可用的策略_代码=2 |
| n系列匿名特征 | 匿名特征n0-n14,为一些贷款人行为计数特征的处理 |
2.2 数据统计分析
在预处理之前,进行简单的数据统计分析可以帮助我们初步了解数据的维度与规模、类型与其他描述性信息。

图2-1 查看数据维度
如图2-1,通过查看数据集的数据维度,可以得出该数据集中,训练集的维度是800000*47;而测试集A的维度是200000*46。
通过函数data_train.info()可以查看数据基本信息,了解数据的基本类型,数据基本类型如表2-2:
表2-2 数据的基本类型
| 序号 | 特征名称 | 类型 | 序号 | 特征名称 | 类型 |
| 0 | id | int64 | 24 | revolBal | float64 |
| 1 | loanAmnt | float64 | 25 | revolUtil | float64 |
| 2 | term | int64 | 26 | totalAcc | float64 |
| 3 | interestRate | float64 | 27 | initialListStatus | int64 |
| 4 | installment | float64 | 28 | applicationType | int64 |
| 5 | grade | object | 29 | earliesCreditLine | object |
| 6 | subGrade | object | 30 | title | float64 |
| 7 | employmentTitle | float64 | 31 | policyCode | float64 |
| 8 | employmentLength | object | 32 | n0 | float64 |
| 9 | homeOwnership | int64 | 33 | n1 | float64 |
| 10 | annualIncome | float64 | 34 | n2 | float64 |
| 11 | verificationStatus | int64 | 35 | n3 | float64 |
| 12 | issueDate | object | 36 | n4 | float64 |
| 13 | isDefault | int64 | 37 | n5 | float64 |
| 14 | purpose | int64 | 38 | n6 | float64 |
| 15 | postCode | float64 | 39 | n7 | float64 |
| 16 | regionCode | int64 | 40 | n8 | float64 |
| 17 | dti | float64 | 41 | n9 | float64 |
| 18 | delinquency_2years | float64 | 42 | n10 | float64 |
| 19 | ficoRangeLow | float64 | 43 | n11 | float64 |
| 20 | ficoRangeHigh | float64 | 44 | n12 | float64 |
| 21 | openAcc | float64 | 45 | n13 | float64 |
| 22 | pubRec | float64 | 46 | n14 | float64 |
| 23 | pubRecBankruptcies | float64 |
|
|
|
利用函数data_train.isnull().any()可以简单查看数据缺失值情况,data_train.isnull().sum() / len(data_train)则可以得到数据缺失比例,数据缺失比例如下图所示:

图2-2 数据缺失比例图
2.3 数据可视化
数据可视化是将数据用图形化的方式来表示,可视化的信息可以帮助人们快速、轻松地获取数据和理解其隐含的意义,因此数据可视化是将数据分析结果呈现的最有效的方式。数据可视化可以使得数据呈现更加直观,观察变量的变化趋势,易于理解,因此数据可视化在数据分析中占据着重要的作用。
我们可以查看该数据的类别标签的对比情况,可见如下图。我们可以发现数据类别标签是不平衡的,所以对于后续模型选择的模型评估指标也是一种考验。

图2-3 数据类别标签占比情况
在本实验中的数据可视化首先查看某一个数值型变量的分布,查看变量是否符合正态分布,一般情况下正态化的数据可以让模型更快的收敛,如果不符合正太分布的变量可以对数化。各个变量的分布可视化图像如下:
|
|
|
|
|
|
|
|
|






图2-4 各个变量分布可视化图
绘制交易金额值分布如图2-5,其中右图是log后的分布。



图2-5 交易金额值分布
我们可以查看数据中某些年份的分布情况,可见如下图

图2-6 某些年份的分布情况
查看类别标签0和1在数据总量中的占比(左)和在贷款总金额中的占比情况(右)

图2-7 类别标签0和1在数据总量中的占比(左)和在贷款总金额中的占比情况(右)
查看训练集数据与测试集数据中的贷款时间分布情况,我们可以发现两者之间是有许多的重叠的部分的。

图2-8 训练集数据与测试集数据中的贷款时间分布情况图
查看各个特征之间的相关性,可见如下热力图。颜色越深表示两两特征之间的相关性越强。

图2-9 各个特征之间的相关性热力图
3. 数据预处理
3.1 缺失值填充
首先使用函数data_train.isnull().sum()查看数据的缺失值情况,有数据缺失值的特征情况如表3-1所示:
表3-1 数据缺失值的特征情况
| 含缺失值特征 | 缺失值数量 | 含缺失值特征 | 缺失值数量 |
| employmentTitle | 1 | n4 | 33239 |
| employmentLength | 46799 | n5 | 40270 |
| postCode | 1 | n6 | 40270 |
| dti | 239 | n7 | 40270 |
| pubRecBankruptcies | 405 | n8 | 40271 |
| revolUtil | 531 | n9 | 40270 |
| title | 1 | n10 | 33239 |
| n0 | 40270 | n11 | 69752 |
| n1 | 40270 | n12 | 40270 |
| n2 | 40270 | n13 | 40270 |
| n3 | 40270 | n14 | 40270 |
可以看到匿名变量的数据缺失值情况比较严重,而非匿名变量中,特征employmentLength、dti、pubRecBankruptcies、revolUtil缺失值较多。
数据填充的方法有很多,常用的比如默认值填充、均值填充、众数填充、KNN填充等,根据具体数据缺失值的类型采用不同的填充方法。在本实验中,连续类型数据使用中数填充,而离散数据使用众数填充。本次实验操作可见如下图。

图3-1 对于数据缺失值的填充操作
3.2 数据格式转换
在做数据分析的时候,原始数据往往会因为各种各样的原因产生各种数据格式的问题,而数据格式错误往往会造成严重的后果。许多异常值也是经过数据格式转换之后才会被发现,因此数据格式转换对于规整数据、清洗数据有者重要的作用。
在本实验中,将特征issueDate从字符串格式转换为日期格式,最常用的是datetime模块,转换成时间格式代码实现如下图所示:

图3-2 时间格式转换操作代码图
数据类型转换是将数据从一种格式或结构转换为另一种格式或结构的过程,在数据预处理中数据转换对于后续的数据分析等处理有着非常重要的作用。本次实验操作可见如下图。

图3-3 数据类型转换操作代码图
3.3 特征编码
特征编码对特征向量进行编码的工作过程,对后续的模型训练有着非常重要的作用。本次实验操作可见如下图。


图3-4 数据特征编码操作代码图
3.4 数据标准化
由于本数据集中存在大量不同的相关指标,每个指标的性质、量纲、数量级、可用性等特征均可能存在差异,导致我们无法直接用其分析研究对象的特征和规律。当各指标间的水平相差很大时,如果直接用指标原始值进行分析,数值较高的指标在综合分析中的作用就会被放大,相对地,会削弱数值水平较低的指标的作用。
因此在模型训练之前,我们要对数据进行标准化。数据标准化是指将数据按比例缩放,使之落入一个小的特定区间。去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。常见的数据标准化方法有min-max标准化、log函数转换、z-score标准化模糊量化法等。本次实验使用的是z-score标准化,可见如下图

图3-5 z-score标准化操作代码图
3.5特征删除
本部分主要是删除掉与标签数据没有任何关系的特征,例如用户id,和该特征只有唯一值得特征,本次实验可见如下图


图3-6 数据特征删除操作代码图
4. 模型介绍
4.1 决策树
决策树学习的算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得各个子数据集有一个最好的分类的过程。这一过程对应着对特征空间的划分,也对应着决策树的构建。决策树构造步骤如下:
①开始时构建根节点,将所有训练数据都放在根节点,选择一个最优特征,按着这一特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。
②如果这些子集已经能够被基本正确分类,那么构建叶节点,并将这些子集分到所对应的叶节点去。
③如果还有子集不能够被正确的分类,那么就对这些子集选择新的最优特征,继续对其进行分割,构建相应的节点,如果递归进行,直至所有训练数据子集被基本正确的分类,或者没有合适的特征为止。
④每个子集都被分到叶节点上,即都有了明确的类,这样就生成了一颗决策树。
决策树划分准则主要有信息增益、信息增益率以及基尼指数三种。著名的ID3决策树学习算法就是以信息增益为准则来选择划分属性。把得到最大的信息增益的作为最优划分属性,这就是ID3算法选择划分属性的准则。
信息增益准则对可取值数目较多的属性有所偏好,为了减少这种偏好可能带来的不利影响,C4.5决策树算法不直接使用信息增益,而是使用增益率来选择最优划分属性。需要注意的是,增益率准则对可取值数目较少对属性有所偏好。所以,C4.5算法并不是直接选择增益率最大对候选划分属性,而是用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
CART决策树算法使用基尼指数来选择划分属性,这个准则不再用熵和增益来衡量数据集的纯度,而是用基尼值来度量。直观来说基尼指数反映了从数据集中随机抽取两个样本,其类别标记不一致的概率。因此基尼值越小,则数据集的纯度越高。
剪枝是决策树算法对付“过拟合”的主要手段,通过主动去掉一些分支来降低过拟合的风险。根据泛化性能是否提升来判断和评估要不要留下这个分支。常常使用“留出法”判断决策树的泛化性能是否提升,即预留一部分数据用作“验证集”来进行性能评估。
4.2 Bagging
Bagging又称为“装袋法”,它是所有集成学习方法当中最为著名,也最为有效的操作之一。Bagging是一种通过组合多个模型来减少泛化误差的技术,是常用的一种集成学习框架。集成学习是本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务,一般结构是:先产生一组“个体学习器”,再用某种策略将它们结合起来。
Bagging模型的主要思想是:降低模型的方差,并提高准确率,从样本总体中抽取很多个训练集,对每个训练集分别拟合模型,将每个模型的结果求平均。
在Bagging集成当中,并行建立多个弱评估器(通常是决策树,也可以是其他非线性算法),并综合多个弱评估器的结果进行输出。当集成算法目标是回归任务时,集成算法的输出结果是弱评估器输出的结果的平均值,当集成算法的目标是分类任务时,集成算法的输出结果是弱评估器输出的结果少数服从多数(每个类别所对应的弱评估器的数量)。
4.3 随机森林
随机森林算法是最常用也是最强大的监督学习算法之一,它兼顾了解决回归问题和分类问题的能力。随机森林是通过集成学习的思想,将多棵决策树进行集成的算法。对于分类问题,其输出的类别是由个别树输出的众数所决定的。在回归问题中,把每一棵决策树的输出进行平均得到最终的回归结果。在随机森林中,决策树的数量越大,随机森林算法的鲁棒性越强,精确度越高。
构造随机森林的步骤如下:
①假如有N个样本,则有放回的随机选择N个样本(每次随机选择一个样本,然后返回继续选择)。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
②当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m<<M。然后从这m个属性中采用某种策略(比如信息增益)来选择1个属性作为该节点的分裂属性。
③决策树形成过程中每个节点都要按照步骤②来分裂,一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
④按照步骤①~③建立大量的决策树,这样就构成了随机森林了。
4.4 AdaBoost
AdaBoost是一种重要的集成学习技术,其核心思想是针对同一个训练集训练不同的弱分类器,然后把这些弱分类器集合起来,构成一个更强的最终分类器。
Adaboost算法基本原理就是将多个弱分类器(弱分类器一般选用单层决策树)进行合理的结合,使其成为一个强分类器。Adaboost采用迭代的思想,每次迭代只训练一个弱分类器,训练好的弱分类器将参与下一次迭代的使用。也就是说,在第N次迭代中,一共就有N个弱分类器,其中N-1个是以前训练好的,其各种参数都不再改变,本次训练第N个分类器。其中弱分类器的关系是第N个弱分类器更可能分对前N-1个弱分类器没分对的数据,最终分类输出要看这N个分类器的综合效果。
AdaBoost算法采取的优化方法是:提高上一轮被错误分类的样本的权值,降低被正确分类的样本的权值;线性加权求和,误差率小的基学习器拥有较大的权值,误差率大的基学习器拥有较小的权值。
4.5 XGBoost
XGBoost是基于预排序方法的决策树算法。这种构建决策树的算法基本思想是:首先,对所有特征都按照特征的数值进行预排序。其次,在遍历分割点的时候用O(#data)的代价找到一个特征上的最好分割点。最后,在找到一个特征的最好分割点后,将数据分裂成左右子节点。
这样的预排序算法的优点是能精确地找到分割点。但是缺点也很明显:首先,空间消耗大。这样的算法需要保存数据的特征值,还保存了特征排序的结果(例如,为了后续快速的计算分割点,保存了排序后的索引),这就需要消耗训练数据两倍的内存。其次,时间上也有较大的开销,在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。最后,对cache优化不友好。在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
4. 6LightGBM
GBDT是机器学习中一个长盛不衰的模型,其主要思想是利用决策树迭代训练以得到最优模型,该模型具有训练效果好、不易过拟合等优点。GBDT通常被用于多分类和数据挖掘等任务中。而LightGBM是一个实现GBDT算法的框架,支持高效率的并行训练,并且具有更快的训练速度、更低的内存消耗、更好的准确率、支持分布式可以快速处理海量数据等优点。
LightGBM原理和XGBoost类似,通过损失函数的泰勒展开式近似表达残差(包含了一阶和二阶导数信息),另外利用正则化项控制模型的复杂度。为了避免XGBoost的缺陷,并且能够在不损害准确率的条件下加快GBDT模型的训练速度,lightGBM在传统的GBDT算法上进行优化。
LightGBM最大的特点是,通过使用leaf-wise分裂策略代替XGBoost的level-wise分裂策略,通过只选择分裂增益最大的结点进行分裂,避免了某些结点增益较小带来的开销。另外LightGBM通过使用基于直方图的决策树算法,只保存特征离散化之后的值,代替XGBoost使用exact算法中使用的预排序算法(预排序算法既要保存原始特征的值,也要保存这个值所处的顺序索引),减少了内存的使用,并加速的模型的训练速度。
4.7 CatBoost
CatBoost是Boosting族算法的一种,也是在GBDT算法框架下的一种改进实现。CatBoost是一种基于对称决策树为基学习器实现的参数较少、支持类别型变量和高准确性的GBDT框架,主要解决的痛点是高效合理地处理类别型特征,CatBoost还解决了梯度偏差(Gradient Bias)以及预测偏移(Prediction shift)的问题,从而减少过拟合的发生,进而提高算法的准确性和泛化能力。
与XGBoost、LightGBM相比,CatBoost嵌入了自动将类别型特征处理为数值型特征的创新算法:首先对categorical features做一些统计,计算某个类别特征(category)出现的频率,之后加上超参数,生成新的数值型特征。Catboost还使用了组合类别特征,可以利用到特征之间的联系,这极大的丰富了特征维度。
CatBoost采用排序提升的方法对抗训练集中的噪声点,从而避免梯度估计的偏差,进而解决预测偏移的问题。CatBoost 还计算每个数据点的残差,并使用其他数据训练的模型进行计算。这样,每个数据点就得到了不同的残差数据。这些数据被评估为目标,并且通用模型的训练次数与迭代次数一样多,但CatBoost通过有序提升在更短的时间内完成。
5.模型实现
5.1运行环境
模型的训练环境可见如表5-1所示
表5-1 模型训练环境
| 环境 | 版本号、其他信息 |
| 笔记本 | 华硕飞行堡垒7 |
| 操作系统 | Windows 10专业版本 |
| 编程语言 | Python3.7 |
| 编程软件 | Jupyter notebook |
| 模型API | Sklearn、xgboost、lightgbm、catboost |
| 其他依赖库 | Numpy、pandas、matplotlib、seaborn |
5.2实验介绍
模型所使用的数据已经全部经过前续的数据预处理,每一个模型使用的数据都是一致的,且数据划分的大小都一致。模型所采用的交叉验证法都是采用五折交叉验证法。数据集的划分均为80%的训练集和20%的验证集。可见如下图

图5-1 数据集划分操作代码
我们将采用decision tree、AdaBoost、Bagging、RandomForest、xgboost、lightgbm和catboost 7种模型对同一数据进行训练,并且使用AUC指标评估每一个训练得到的模型,每个模型的参数选择方法都将采用网格搜索法对最优参数进行选择。
5.3 decision tree
在机器学习中,decision tree是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系,我们使用sklearn的API调用tree的方法,实现decision tree,并且使用网格搜索法选着最优参数,网格搜索法可见如下图,可以对模型的最优参数进行选择,缺点是非常考验电脑性能,运行时间会非常的久。

图5-2 决策树实现操作代码
对decision tree的运行结果可见如下图,我们可以查看模型的训练报告,我们可以发现模型的准确率为80.14%,已经达到较好的效果。

图5-3 决策树运行结果混淆矩阵
由于本数据集的标签是不平衡的,所以需要使用到AUC指标,对模型进行评估,具体可见如下图,基础decision tree的模型训练效果的AUC为70.66%。

图5-4 决策树模型训练效果AUC
我们可以查看decision tree模型中,特征重要性排序在前十的特征,可见如下图,它们分别是subGrade 、grade、issueDateDT 、term、homeOwnership、dti、annualIncome、installment、ficoRangeLow、interestRate

图5-5 决策树模型中特征重要性排序在前十的特征
前十个特征的贡献度排序可见如下表

图5-6 前十个特征的贡献度排序
我们还可以查看该模型的部分结构树,可见如下图

图5-7 决策树模型的部分结构树
5.4 Bagging
Bagging是通过结合几个模型降低泛化误差的技术。主要想法是分别训练几个不同的模型,然后让所有模型表决测试样例的输出。这是机器学习中常规策略的一个例子,被称为模型平均(modelaveraging)。采用这种策略的技术被称为集成方法。
我们采用上述的decision tree作为底层树,使用网格搜索法搜索得到最佳的Bagging袋装法的最佳模型参数,其模型报告可见如下图,我们可以发现基于bagging的decision tree模型,准确率是要比基础decision tree模型的准确率要高的,为80.239%。

图5-8 Bagging运行结果混淆矩阵
查看该模型的AUC指标,我们可以发现该模型的AUC指标也要比基础的decision tree模型的AUC要高,为71.46%。

图5-9 Bagging模型训练效果AUC
5.5 RandomForest
随机森林是利用多个decision tree对样本进行训练、分类并预测的一种算法,在对数据进行分类的同时,还可以给出各个变量的重要性评分,评估各个变量在分类中所起的作用。随机森林是一种比较有名的集成学习方法,属于集成学习算法中弱学习器之间不存在依赖的一部分。
本次实验使用sklearn的API,调用方法实现decision tree,使用网格搜索法对搜索最佳的模型参数,具体模型训练结果可见如下图,我们可以发现上述的Bagging方法和该集成方法,他们的效果在本数据集上是差不多的。本次随机森林的模型准确率为80.295%。

图5-10 随机森林运行结果混淆矩阵
查看该随机森林的AUC,为70.91%。我们可以发现随机森林的模型准确率要比Bagging方法的准确率要高,但是模型的AUC指标却比Bagging方法的AUC要低,这也是为什么有时候对模型评估不只能看模型准确率的原因,要结合数据的实际情况选着模型评估指标。

图5-11 随机森林模型训练效果AUC
我们可以查看该模型输出的重要特征排序,选择前10个重要性特征,可见如下图。它们分贝为dti、interestRate、revolBal、employmentTitle、revolUtil 、postCode、annualIncome、installment、issueDateDT、subGrade,我们可以发现该模型的前10个重要特征指标,与decision tree的前10个重要特征指标有部分是一样的。

图5-12 随机森林模型输出的前十个重要特征排序
该模型前10个重要特征指标的重要性可见如下图

图5-13 模型前10个重要特征指标的重要性
5.6 Adaboost
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器,然后把这些弱分类器集合起来,构成一个更强的最终分类器,Boosting,也称为增强学习或提升法,是一种重要的集成学习技术,能够将预测精度仅比随机猜度略高的弱学习器增强为预测精度高的强学习器。Adaboost与RandomForest都是集成方法其中的一种。
本次实验调用sklearn的API方法实现Adaboost模型,选择网格搜索法选择模型最佳参数,对模型进行训练,模型训练报告可见如下图,我们可以发现该模型的准确率为80.31%。与上述模型的准确率相差不大。

图5-14 Adaboost运行结果混淆矩阵
查看该模型的AUC指标,AUC为71.59%,具体可见如下图。我们可以发现,该模型的准确率和AUC指标都要比RandomForest模型的都要高。

图5-15 Adaboost模型训练效果AUC
输出该模型的前10个重要特征,可见如下图,它们分别是subGrade 、issueDateDT、grade、employmentTitle、loanAmnt 、interestRate 、n14、homeOwnership、annualIncome、totalAcc。我们可以发现该模型的前10个重要性指标都与前面模型的重要性指标有部分的重合。

图5-16 Adaboost模型输出的前十个重要特征排序
我们可以查看该模型的前10个模型的特征的重要性,具体可见如下图。

图5-17 Adaboost模型前10个重要特征指标的重要性
5.7 xgboost
xgboost是大规模并行boosted tree的工具,据说它是目前最快最好的开源boosted tree工具包,比常见的工具包快10倍以上。xgboost的全称是eXtreme Gradient Boosting,它是经过优化的分布式梯度提升库,旨在高效、灵活且可移植。
本次实验直接调用xgboost工具包,构造实现该模型的函数。Xgboost模型的参数是非常多的,所以使用网格搜索法寻求最优参数的时候,会非常非常的慢。Xgboost模型的具体参数可见如下图

图5-18 xgboost实现代码操作
使用该模型对同一数据进行训练,输出模型的训练效果,具体可见如下图,该图为其中一折的模型训练过程中AUC的变化过程。

图5-19 xgboost模型训练过程中AUC的变化过程
我们可以查看某一折的模型训练结果的AUC,为73.41%。我们可以发现该模型得到的AUC,要比前面几个模型的都要好。

图5-20 xgboost模型训练效果AUC
5.8 lightgbm
LightGBM(Light Gradient Boosting Machine)是一个实现GBDT算法的框架,支持高效率的并行训练,并且具有更快的训练速度、更低的内存消耗、更好的准确率、支持分布式可以快速处理海量数据等优点。
该模型实现的方法是直接调用lightgbm工具包的API,使用该方法实现。该模型的参数也是非常的多,具体可见如下图

图5-21 lightgbm实现代码操作
该模型五折交叉验证训练部分过程图具体可见如下

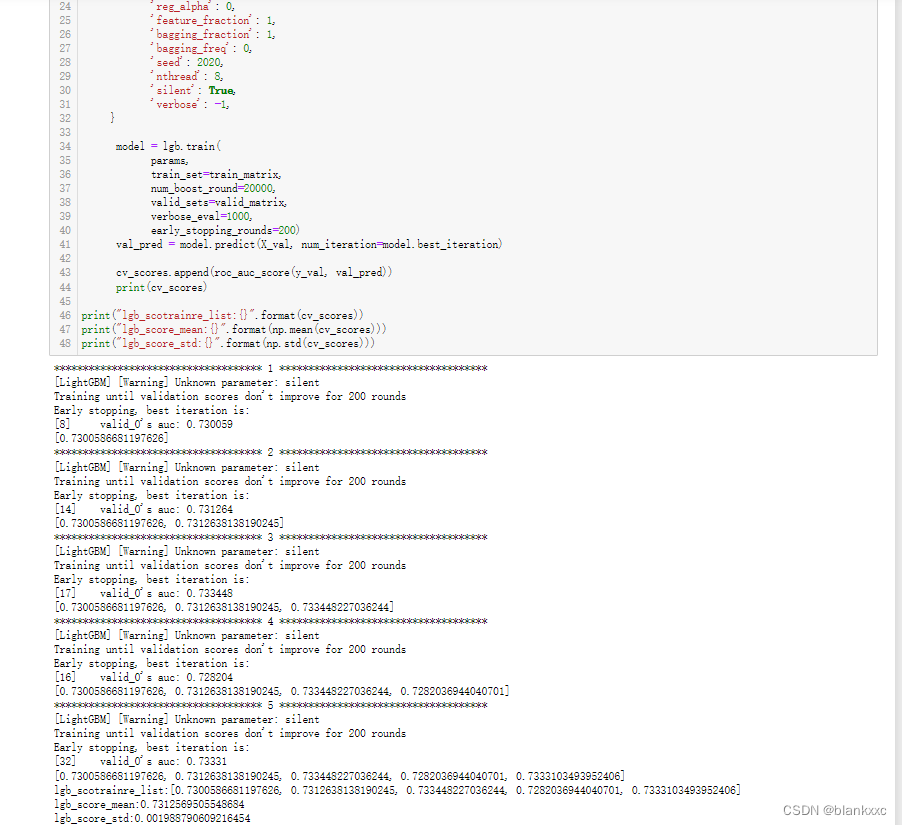
图5-22 lightgbm模型训练过程中AUC的变化过程
Lgb模型训练得到的AUC为73.33%,效果要比lgb模型略差一些,有一部分可能是因为参数没有调到最优。但是都要比前面的decision tree等模型要好。

图5-23 lightgbm模型训练效果AUC
我们可以查看该模型的结构树,可见如下图

图5-24 lightgbm模型的结构树
5.9 catboost
CatBoost是俄罗斯的搜索巨头Yandex在2017年开源的机器学习库,是Boosting族算法的一种。CatBoost和XGBoost、LightGBM并称为GBDT的三大主流神器,都是在GBDT算法框架下的一种改进实现。CatBoost是一种基于对称决策树(oblivious trees)为基学习器实现的参数较少、支持类别型变量和高准确性的GBDT框架。
本次实验是使用catboost工具包的API实现的catboost模型,该模型的参数相对来说是比较少的,可见如下图所示

图5-25 catboost实现操作代码
该模型的五折交叉验证训练过程可见如下图

图5-26 catboost模型训练过程中AUC的变化过程
catboost五折交叉验证训练过程的全部AUC分别是74.70%、74.77%、74.88、74.68%、74.68%。我们可以发现该模型的最大AUC为74.88%,是目前已经实验的7个模型之中最高AUC的模型,该模型的平均AUC为74.76%,都比前面模型的AUC要高。





图5-27 catboost模型训练效果AUC
6. 总结
基于本次数据分析大作业,我们使用7种模型decision tree、AdaBoost、Bagging、RandomForest、xgboost、lightgbm和catboost,分别对阿里天池的贷款违约预测数据进行训练,得到每个模型最好的效果可见如下图。我们得到最好的效果是使用Catboost模型,最高AUC达到了74.88%。

图6-1 各个模型评估效果图
做了本次的数据分析课程大作业,我觉得难度还是有的,但是也是对自己本身的一种锻炼,让我们熟悉掌握数据分析的方法和工具,例如本次实验我们小组就使用到了许多的依赖库,还有一些库还是从未触碰过的,例如Xgboost和Catboost等。我们还可以使用其他的工具,例如graphviz第三方工具,可以进行决策树模型结构进行绘画,画出模型的结构树模型图,在对于理解和学习该模型是非常有帮助的,我们还使用pandas_profiling工具生成数据分析可视化报告。
本次实验使用到的模型,绝大多数都是使用在机器学习的有监督学习中,也就是分类。由于本次课程设计选择的数据量很大,仅训练数据就有800000多条,普通笔记本电脑是较难实现对数据的读取和模型的训练,并且时间非常长,本小组成员曾多次因为跑模型导致电脑死机或者是故障。所以本次课程设计我们小组还是用到了Google的一个服务器Cloab和百度开源的深度学习平台AI studio,利用提供的GPU对数据进行一个读取和模型的训练。我们发现利用GPU对于数据的读取和模型的训练速度是非常快,若没有GPU,对于大量数据的训练会非常的耗时。据了解,训练深度网络时,GPU比CPU快40倍左右。CPU适合复杂的逻辑运算,GPU适合矩阵运算,深度学习大部分的模型训练的算法运算都采用了矩阵运算,而且CPU的核心数要比GPU少,模型训练需要很多并行的矩阵运算,GPU在深度学习模型的训练上显得非常的出色。
我们小组认为,在数据分析的过程中,最重要的一步还是对于数据的预处理部分,该部分还可以实现特征工程。同一场比赛,同一个数据集,有时候还会同一个模型,但是每个人的结果都可能不太一样,很大可能是因为数据的处理方式不一样。再好的模型,用在普通的数据上,得到的结果都会比较普通的,所以我们小组认为数据分析的最重要一部分是数据的预处理部分和特征工程。
经过本学期的数据分析课程的学习,和本次课程的期末大作业,我们组成员学到了如何利用各种模型来训练数据,并且会借用其他的工具,例如AI Studio开源平台来实现对大规模数据的训练,使得我们对数据分析的认识更进一步。
7 参考文献
[1]杨宁,赵联文,郭耀煌. 随机决策树[J]. 西南交通大学学报,2000(2). DOI:10.3969/j.issn.0258-2724.2000.02.025.
[2] 李苍柏,肖克炎,李楠,等. 支持向量机、随机森林和人工神经网络机器学习算法在地球化学异常信息提取中的对比研究[J]. 地球学报,2020(2). DOI:10.3975/cagsb.2020.022501.
[3]方匡南,吴见彬. 个人住房贷款违约预测与利率政策模拟[J]. 统计研究,2013(10). DOI:10.3969/j.issn.1002-4565.2013.10.008.
[4]张佳倩,李伟,阮素梅. 基于机器学习的贷款违约风险预测[J]. 长春理工大学学报(社会科学版),2021(4). DOI:10.3969/j.issn.1009-1068.2021.04.018.
[5] 周丽峰. 基于非平衡数据分类的贷款违约预测研究[D]. 2013. DOI:10.7666/d.Y2426281.
[6] 隋孟琪. 基于混合特征提取和集成学习的个人贷款违约预测研究[D]. 2020.
[7] 刘斌,陈凯. 基于SMOTE和XGBoost的贷款风险预测方法[J]. 计算机与现代化,2020(2). DOI:10.3969/j.issn.1006-2475.2020.02.006.
[8] 李赵飞. 基于代价敏感AdaBoost的贷款违约风险预测研究[D]. 2021.
[9] 朱喆泓. 基于LightGBM算法的住房按揭贷款提前偿付风险预测模型[D]. 2021.
附录
1:使用jupyter notebook运行文件即可,每个代码文件前面都有依赖库的安装和导入。
2:代码文件有三个:cat.ipynb,lgb and xgb.ipynb, 数据分析期末大作业.ipynb三个代码文件。
3:数据文件有2个:train.csv和testA.csv两个文件。
4:可以先运行数据分析期末大作业.ipynb这个总体的代码,再去独自运行另外两个小代码文件