导 读
生成对抗网络(GAN)因其生成图像的能力而变得非常受欢迎,而语言模型(例如 ChatGPT)在各个领域的使用也越来越多。这些 GAN 模型可以说是人工智能/机器学习目前主流的原因;
因为它向每个人(尤其是该领域之外的人)展示了机器学习所具有的巨大潜力。网上已经有很多关于 GAN 模型的资源,但其中大多数都集中在图像生成上。这些图像生成和语言模型需要复杂的空间或时间复杂性,这增加了额外的复杂性,使读者更难理解 GAN 的真正本质。
为了解决这个问题并使 GAN 更容易被更广泛的受众所接受,在本文的 GAN 模型示例中,我们将采取一种不同的、更实用的方法,重点关注生成数学函数的合成数据。
除了出于学习目的的简化之外,合成数据生成本身也变得越来越重要。数据不仅在业务决策中发挥着核心作用,而且数据驱动方法的用途也越来越多,比第一原理模型更受欢迎。
比如天气预报,第一个原理模型包括通过数值求解的纳维-斯托克斯方程的简化版本。然而,深度学习研究中进行天气预报的尝试在捕捉天气模式方面非常成功,并且一旦经过训练,运行起来会更容易、更快。
有需要的朋友关注公众号【小Z的科研日常】,获取更多内容。
01、生成模型与判别模型
在机器学习中,理解判别模型和生成模型之间的区别非常重要,因为它们是 GAN 的关键组成部分:
判别模型:
判别模型侧重于将数据分类为预定义的类别,例如将狗和猫的图像分类为各自的类别。这些模型不是捕获整个分布,而是辨别不同类别的边界。它们输出 P(y|x)(类别概率,给定输入数据的 y,x),即它们回答给定数据点属于哪个类别的问题。
生成模型:
生成模型旨在理解数据的底层结构。与区分类别的判别模型不同,生成模型学习数据的整个分布。这些模型输出 p(x|y),即它们回答了给定指定类生成该特定数据点的可能性有多大的问题。
这两个模型之间的相互作用构成了 GAN 的基础。
02、GAN—结构和组件
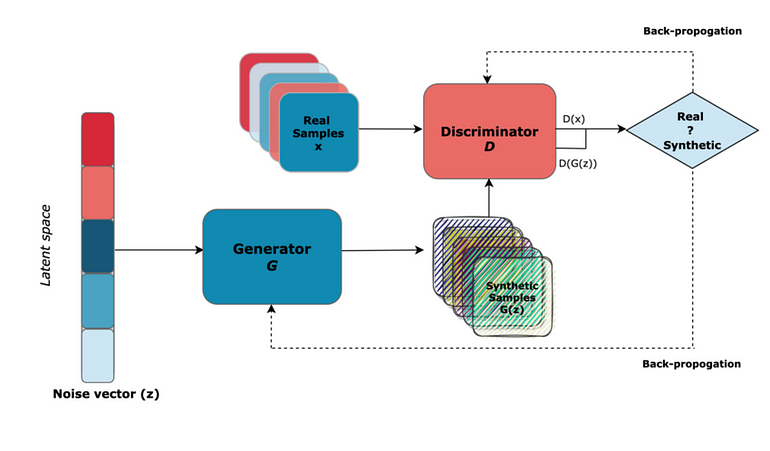
GAN 的关键组件包括噪声向量、生成器和鉴别器。
生成器:生成真实数据
为了生成合成数据,生成器使用随机噪声向量作为输入。为了欺骗鉴别器,生成器的目的是学习真实数据的分布并生成无法与真实数据区分开的合成数据。这里的一个问题是,对于相同的输入,它总是会产生相同的输出(想象一个图像生成器产生真实的图像,但总是相同的图像,这不是很有用)。随机噪声向量将随机性注入到过程中,从而提供生成的输出的多样性。
鉴别器:辨别真假
鉴别器就像一位受过训练来区分真实数据和虚假数据的艺术评论家。它的作用是仔细检查收到的数据并为工作真实性分配概率分数。如果合成数据看起来与真实数据相似,则鉴别器分配高概率,否则分配低概率分数。
对抗性训练:动态决斗
生成器努力学习生成鉴别器无法与真实数据区分开的合成数据。同时,鉴别器还学习并提高区分真实与合成的能力。这种动态的训练过程促使两个模型提高技能。这两个模型总是相互竞争(因此被称为对抗性),并且通过这种竞争,两个模型都在各自的角色中变得非常出色。
03、Pytorch实现GAN
在此示例中,我们在 pytorch 中实现了一个可以生成合成数据的模型。对于训练,我们有一个具有以下形状的 6 参数数据集(所有参数都绘制为参数 1 的函数)。每个参数都经过精心选择,具有显着不同的分布和形状,以增加数据集的复杂性并模仿真实世界的数据。

定义 GAN 模型组件(生成器和判别器)
import torchfrom torch import nnfrom tqdm.auto import tqdmfrom torch.utils.data import DataLoaderimport matplotlib.pyplot as pltimport torch.nn.init as initimport pandas as pdimport numpy as npfrom torch.utils.data import Dataset# 定义单块功能def FC_Layer_blockGen(input_dim, output_dim): single_block = nn.Sequential( nn.Linear(input_dim, output_dim), nn.ReLU() ) return single_block # 定义 GENERATORclass Generator(nn.Module): def __init__(self, latent_dim, output_dim): super(Generator, self).__init__() self.model = nn.Sequential( nn.Linear(latent_dim, 256), nn.ReLU(), nn.Linear(256, 512), nn.ReLU(), nn.Linear(512, 512), nn.ReLU(), nn.Linear(512, output_dim), nn.Tanh() ) def forward(self, x): return self.model(x) #定义单个判别块def FC_Layer_BlockDisc(input_dim, output_dim): return nn.Sequential( nn.Linear(input_dim, output_dim), nn.ReLU(), nn.Dropout(0.4) ) # 定义判别器class Discriminator(nn.Module): def __init__(self, input_dim): super(Discriminator, self).__init__() self.model = nn.Sequential( nn.Linear(input_dim, 512), nn.ReLU(), nn.Dropout(0.4), nn.Linear(512, 512), nn.ReLU(), nn.Dropout(0.4), nn.Linear(512, 256), nn.ReLU(), nn.Dropout(0.4), nn.Linear(256, 1), nn.Sigmoid() ) def forward(self, x): return self.model(x) #定义训练参数batch_size = 128num_epochs = 500lr = 0.0002num_features = 6latent_dim = 20# 模型初始化generator = Generator(noise_dim, num_features)discriminator = Discriminator(num_features)# 损失函数和优化器criterion = nn.BCELoss()gen_optimizer = torch.optim.Adam(generator.parameters(), lr=lr)disc_optimizer = torch.optim.Adam(discriminator.parameters(), lr=lr)模型初始化和数据处理
file_path = 'SamplingData7.xlsx'data = pd.read_excel(file_path)X = data.valuesX_normalized = torch.FloatTensor((X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0)) * 2 - 1)real_data = X_normalizedclass MyDataset(Dataset): def __init__(self, dataframe): self.data = dataframe.values.astype(float) self.labels = dataframe.values.astype(float) def __len__(self): return len(self.data) def __getitem__(self, idx): sample = { 'input': torch.tensor(self.data[idx]), 'label': torch.tensor(self.labels[idx]) } return sample# 创建数据集实例dataset = MyDataset(data)# 创建数据加载器dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, drop_last=True)def weights_init(m): if isinstance(m, nn.Linear): init.xavier_uniform_(m.weight) if m.bias is not None: init.constant_(m.bias, 0)pretrained = Falseif pretrained: pre_dict = torch.load('pretrained_model.pth') generator.load_state_dict(pre_dict['generator']) discriminator.load_state_dict(pre_dict['discriminator'])else: # 应用权重初始化 generator = generator.apply(weights_init) discriminator = discriminator.apply(weights_init)模型训练
model_save_freq = 100latent_dim =20for epoch in range(num_epochs): for batch in dataloader: real_data_batch = batch['input'] real_labels = torch.FloatTensor(np.random.uniform(0.9, 1.0, (batch_size, 1))) disc_optimizer.zero_grad() output_real = discriminator(real_data_batch) loss_real = criterion(output_real, real_labels) loss_real.backward() fake_labels = torch.FloatTensor(np.random.uniform(0, 0.1, (batch_size, 1))) noise = torch.FloatTensor(np.random.normal(0, 1, (batch_size, latent_dim))) generated_data = generator(noise) output_fake = discriminator(generated_data.detach()) loss_fake = criterion(output_fake, fake_labels) loss_fake.backward() disc_optimizer.step() valid_labels = torch.FloatTensor(np.random.uniform(0.9, 1.0, (batch_size, 1))) gen_optimizer.zero_grad() output_g = discriminator(generated_data) loss_g = criterion(output_g, valid_labels) loss_g.backward() gen_optimizer.step() print(f"Epoch {epoch}, D Loss Real: {loss_real.item()}, D Loss Fake: {loss_fake.item()}, G Loss: {loss_g.item()}")模型评估和可视化结果
import seaborn as snssynthetic_data = generator(torch.FloatTensor(np.random.normal(0, 1, (real_data.shape[0], noise_dim))))# 绘制结果fig, axs = plt.subplots(2, 3, figsize=(12, 8))fig.suptitle('Real and Synthetic Data Distributions', fontsize=16)for i in range(2): for j in range(3): sns.histplot(synthetic_data[:, i * 3 + j].detach().numpy(), bins=50, alpha=0.5, label='Synthetic Data', ax=axs[i, j], color='blue') sns.histplot(real_data[:, i * 3 + j].numpy(), bins=50, alpha=0.5, label='Real Data', ax=axs[i, j], color='orange') axs[i, j].set_title(f'Parameter {i * 3 + j + 1}', fontsize=12) axs[i, j].set_xlabel('Value') axs[i, j].set_ylabel('Frequency') axs[i, j].legend()plt.tight_layout(rect=[0, 0.03, 1, 0.95])plt.show()#创建 2x3 网格的子绘图fig, axs = plt.subplots(2, 3, figsize=(15, 10))fig.suptitle('Comparison of Real and Synthetic Data', fontsize=16)# Define parameter namesparam_names = ['Parameter 1', 'Parameter 2', 'Parameter 3', 'Parameter 4', 'Parameter 5', 'Parameter 6']# 各参数的散点图for i in range(2): for j in range(3): param_index = i * 3 + j sns.scatterplot(real_data[:, 0].numpy(), real_data[:, param_index].numpy(), label='Real Data', alpha=0.5, ax=axs[i, j]) sns.scatterplot(synthetic_data[:, 0].detach().numpy(), synthetic_data[:, param_index].detach().numpy(), label='Generated Data', alpha=0.5, ax=axs[i, j]) axs[i, j].set_title(param_names[param_index], fontsize=12) axs[i, j].set_xlabel(f'Real Data - {param_names[param_index]}') axs[i, j].set_ylabel(f'Real Data - {param_names[param_index]}') axs[i, j].legend()plt.tight_layout(rect=[0, 0.03, 1, 0.95])plt.show()

