爬虫简介
请结合这期视频进行学习:
前端爬虫+可视化项目实战,从0到1快速开发一个爬虫程序,分析程序员求职行情
可以把互联网比做成一张 “大网”,爬虫就是在这张大网上不断爬取信息的程序。
爬虫是请求网站并提取数据的自动化程序。
省流:Demo实现前置知识:
JS 基础Node 基础(1)爬虫基本工作流程:
向指定的URL发送 http 请求获取响应(HTML、XML、JSON、二进制等数据)处理数据(解析DOM、解析JSON等)将处理好的数据进行存储 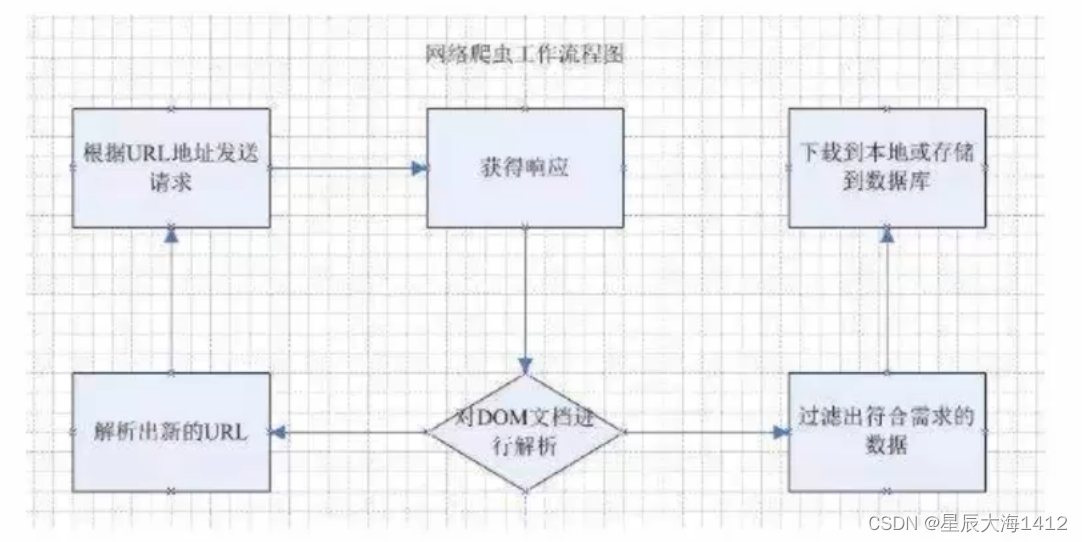
相关岗位:
数据分析大数据应用运营人工智能(2)爬虫作用
搜索引擎自动化程序 自动获取数据自动签到自动薅羊毛自动下载 抢票软件爬虫就是一个探测程序,它的基本功能就是模拟人的行为去各个网站转悠,点点按钮,找找数据,或者把看到的信息背回来。就像一只虫子在一幢楼里不知疲倦地爬来爬去 。
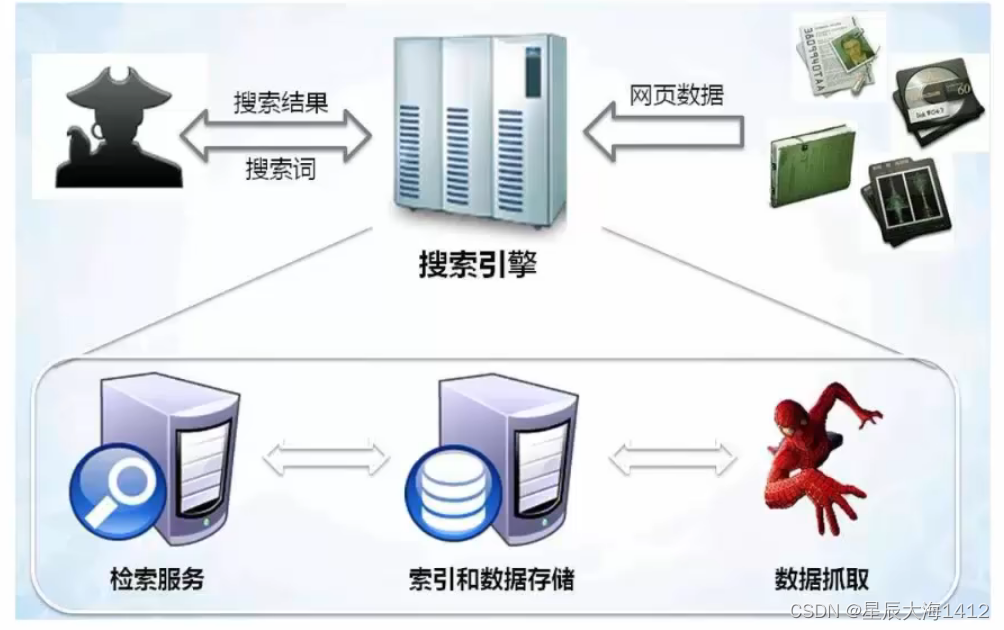
使用的百度和Google,其实就是利用了这种爬虫技术: 每天放出无数爬虫到各个网站,把他们的信来,存到数据库中等用户来检索。
抢票软件,自动帮你不断刷新 12306 网站的火车余票。一旦发现有票,就马上下单,然后你自己来付款。
在现实中几乎所有行业的网站都会被爬虫所“骚扰”,而这些骚扰都是为了方便用户。
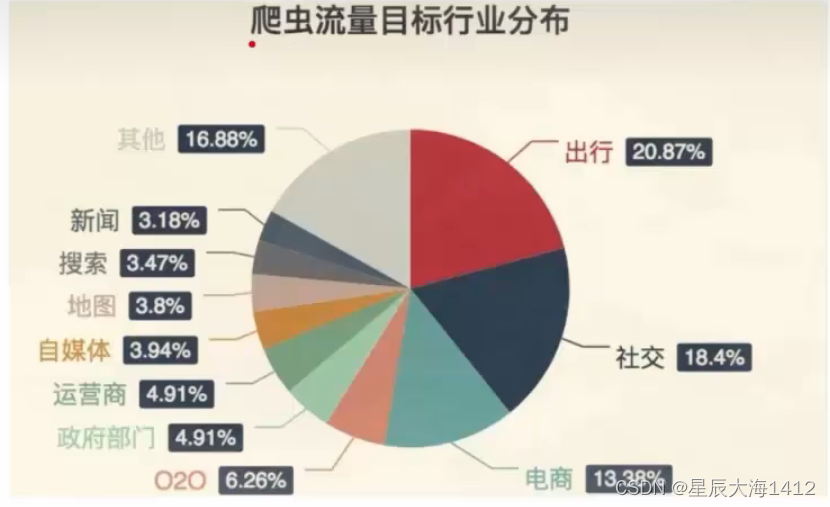
爬虫批量下载图片
目标:以https://www.itheima.com/teacher.html#aweb 网站目标为例,下载图片
①获取网页内容
使用 axios 或 node 原生 API发起请求,得到的结果就是整个HTML网页内容
(1) 使用axios
// 步骤//使用ES6 语法记得将package.json中的修改为"type":"module"//1.发起 HTTP 请求,获取到当前网页(借助 axios)import axios from 'axios'//function getData(){ //axios.get('https://www.itheima.com/teacher.html#aweb').then() //.then 后拿到promise对象//}async function getData(){ const res = await axios.get('https://www.itheima.com/teacher.html#aweb') console.log(res.data)}getData()
(2)使用node方法(使用 http.request()方法即可发送 http 请求)如下:
//引入https模块const http =require('https')//创建请求对象let reg = http.request('https://www.itheima.com/teacher.html#aweb', res =>{ //准备chunks let chunks = [] res.on('data',chunk =>{//监听到数据就存储 chunks.push(chunk)})res.on('end',()=>{ //结束数据监听时讲所有内容拼接 console.log(Buffer.concat(chunks).toString('utf-8')) })})//发送请求req.end()
②解析 HTML 并下载图片
使用 cheerio 加载 HTML回顾 jQueryAPI·加载所有的 img标签的 src 属性使用 download 库批量下载图片
cheerio库 官方地址:The industry standard for working with HTML in JavaScript | cheerioThe fast, flexible & elegant library for parsing and manipulating HTML and XML. https://cheerio.js.org/
https://cheerio.js.org/
在服务器上用这个库来解析 HTML 代码,并且可以直接使用和 jQuery 一样的 API
官方 demo 如下:
const cheerio = require('cheerio')const $ = cheerio.load('<h2 class="title">Hello world</h2>')$('h2.title').text('Hello there!')$('h2').addClass('welcome')$.html()//=> <html><head></head><body><h2 class="title welcome">Hello there!</h2></body></html>同样也可以通过 jQuery 的 API 来获取DOM元素中的属性和内容
(1)使用 cheerio库解析 HTML
1.分析网页中所有 img 标签所在结构
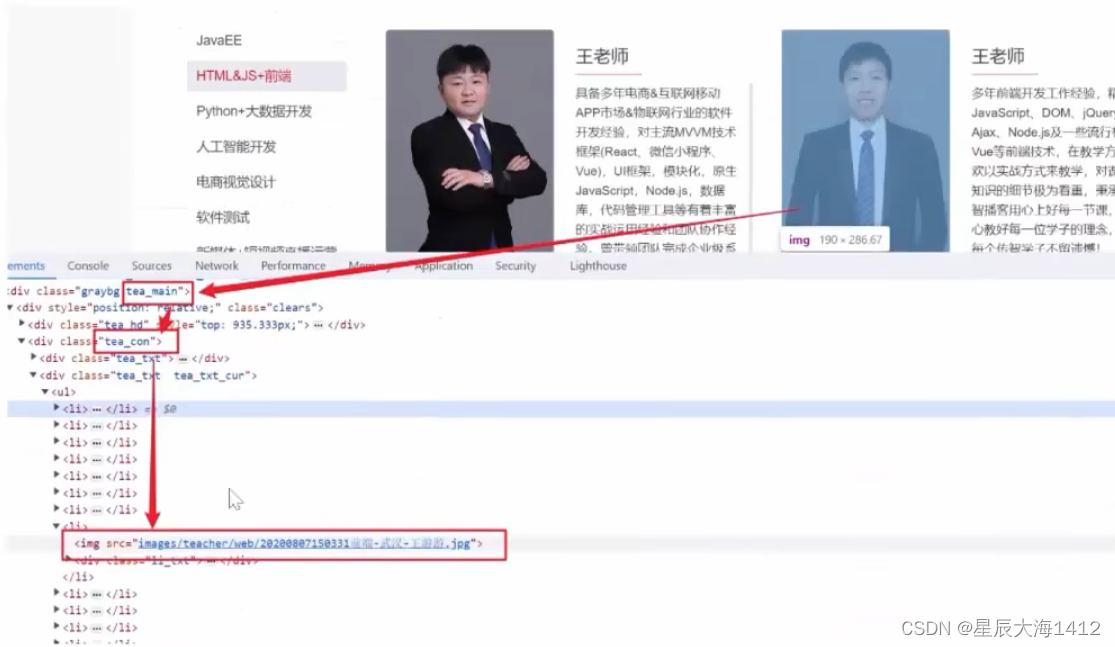
import axios from 'axios'import cheerio from 'cheerio'import download from'download'const fs = require('fs');async function getData(){ const res = await axios.get('https://www.itheima.com/teacher.html#aweb') const $ = cheerio.load(res.data) //使用 cheerio 解析网页源码 const imgReg =/\.jpgljpeglpnglbmplgif$/ const imgs = Array.from($('.tea main .tea con img')).map(img => 'https://www.itheima.com/'+$(img).attr('src')) //用map遍历之后jQuery的attr //使用选择器解析所有的 img 的src 属性 console.log(imgs) encodeURI($(img).attr('src'))).filter(img =>imgReg.test(img)) //imgs.forEach(img=>console.log(img)) imgs.forEach(async img =>{ if(!fs.existssync('dist')) fs.mkdirsync('dist') fs.writeFilesync('dist/'+ decodeURI(img).split('/').pop(),await download(img))}getData()
Selenium 的基本使用
简介
Selenium是一个Web应用的自动化测试框架,可以创建回归测试来检验软件功能和用户需求,通过框架可以编写代码来启动浏览器进行自动化测试,换言之,用于做爬虫就可以使用代码启动浏览器,让真正的浏览器去打开网页然后去网页中获取想要的信息!从而实现真正意义上无惧反爬虫手段!
步骤
根据平台下载需要的 webdriver项目中安装 selenium-webdriver 包根据官方文档写一个小 demo根据平台选择 webdriver
| 浏览器 | webdriver |
| Chrome | chromedriver(.exe) |
| Internet Explorer | lEDriverServer.exe |
| Edge | MicrosoftWebDriver.msi |
| Firefox | geckodriver(.exe) |
| Safari | safaridriver |
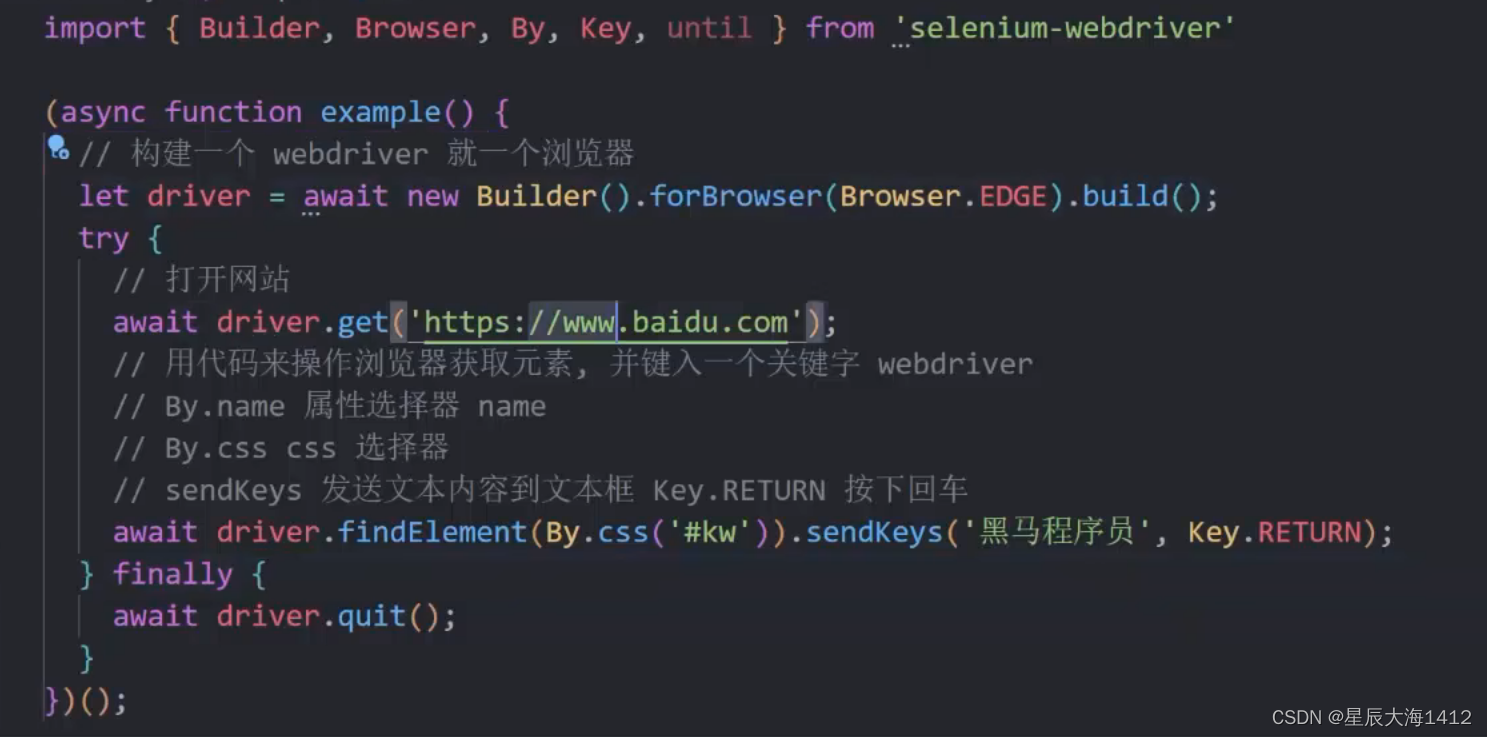
通过 Selenium 可以操作浏览器,打开某个网址,接下来只需要学习其AP!,就能获取网页中需要的内容了! 反爬虫技术只是针对爬虫的,例如检查请求头是否像爬虫,检查!P地址的请求频率(如果过高则封杀)等手段而Selenium打开的就是一个自动化测试的浏览器,和用户正常使用的浏览器并无差别,所以再厉害的反爬虫技术也无法直接把它干掉,除非这个网站连普通用户都想放弃掉(12306曾经迫于无奈这样做过)
Selenium官网:
SeleniumSelenium automates browsers. That's it! https://www.selenium.dev/ 核心对象:
https://www.selenium.dev/ 核心对象:
辅助对象:
ByKey
(1)Builder
用于构建 WebDriver 对象的构造器
const driver = new Builder().forBrowser('chrome').build()(2)WebDriver
通过构造器创建好Webpriver后就可以使用API查找网页元素和获取信息了。
findElement() 查找元素,返回一个 WebElement 对象
传入 By.css()可以通过选择器获取元素(3)WebElement
getText() 获取文本内容sendKeys() 发送一些按键指令click() 点击该元素
(1)案例:
自动打开拉勾网搜索"前端"
1.使用 driver 打开拉勾网主页
2.找到全国站并点击一下
3.输入“前端”并回车

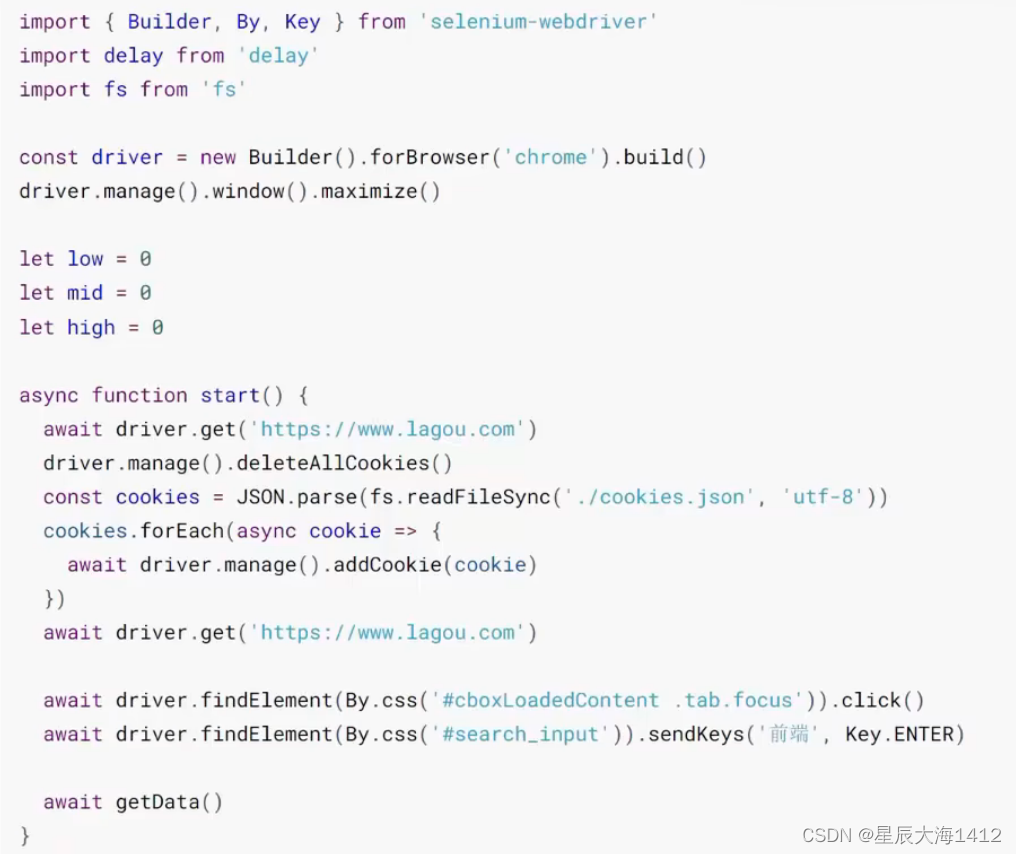
(2)模拟登录
默认是未登录状态,翻页次数过多会被要求登录(电商搜索功能也有此类限制,主要就是为了反爬虫)
原理
运行 selenium 打开目标网站快速完成登录操作登录后会将身份标识存储在 Cookie 中延时 20秒,使用 selenium 导出所有 Cookie这就需要在打开浏览器之后的 20 秒内快速完成登录操作(考验手速的时候到了,可自行设置更长的时间) 导出后注释掉以上代码加上注入 Cookie 的代码
导出后注释掉以上代码加上注入 Cookie 的代码 
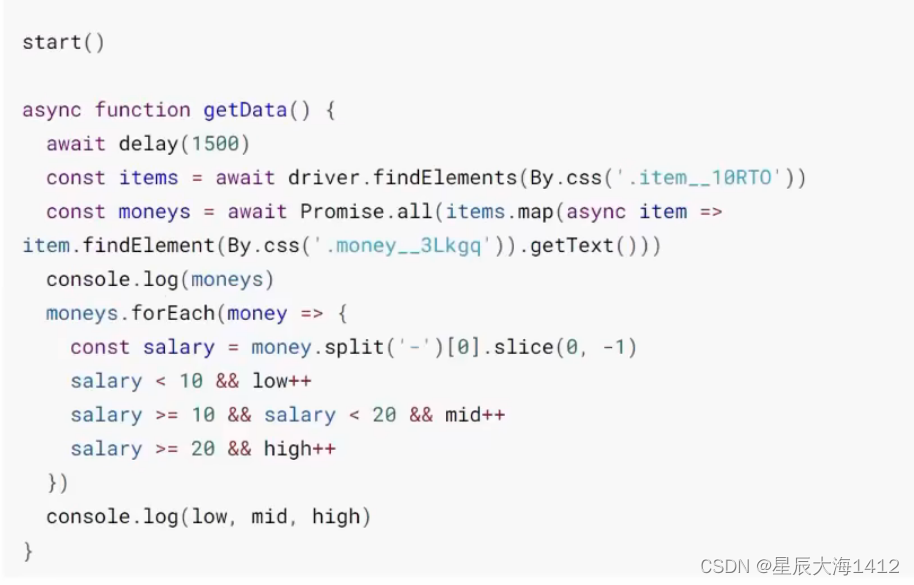
(3)获取招聘信息中的薪资
步骤
搜索前端并获取当前页面所有公司的最低薪资
使用driver.findElement()找到所有条目项,根据需求分析页面元素,获取其文本内容即可:
(4) 自动点击不同城市
步骤
定义城市数组和初始索引搜索前端后先点击初始城市后续配合自动翻页再完善功能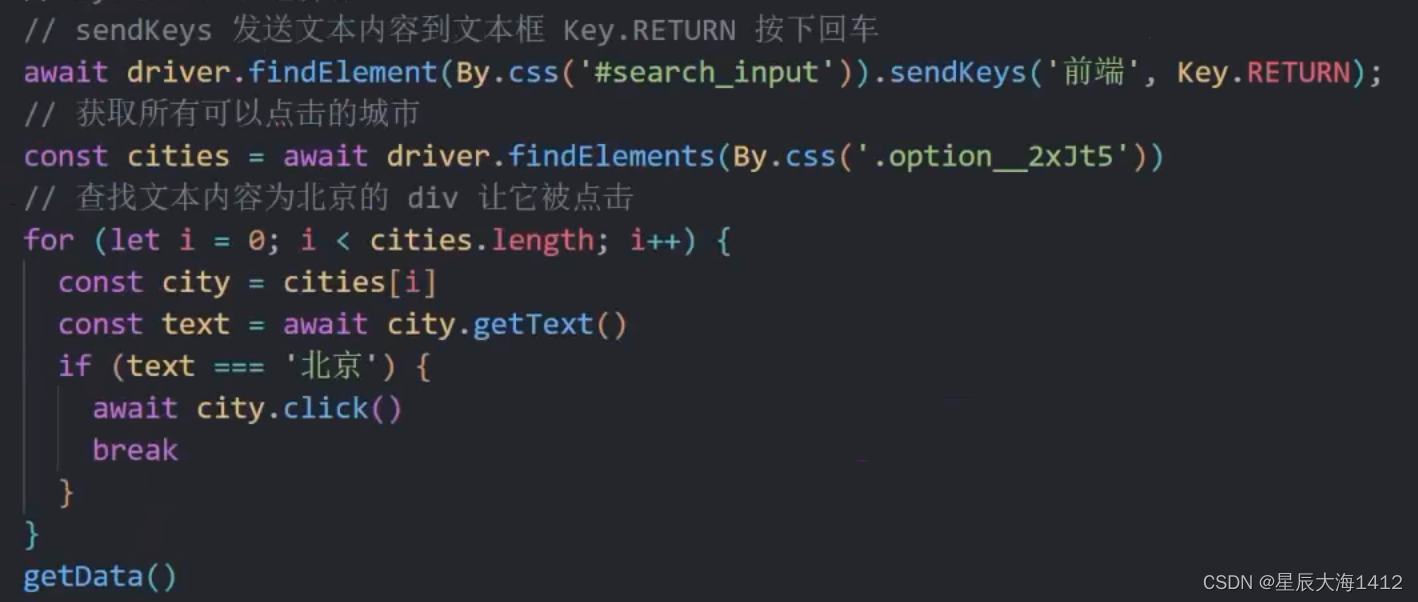
(5) 自动翻页
定义初始页码和最大页码 (拉勾最多 30)开始获取数据时打印当前正在获取的城市及页码数获取完一页数据后,当前页码自增,然后判断是否达到最大页码查找下一页按钮并调用点击 api,进行自动翻页翻页后递归调用获取数据的函数当前城市页码翻完后 记录当前城市信息城市索引自增重置记录数据和页码继续递归调用
(6)搭建服务器并实现数据可视化
用 express 快速构建服务器使用 echarts 渲染图表