目录
一、辅助编程
(一)代码生成
二、其他功能
(一)工具手册
(二)源码学习
(三)技术讨论
一、AI辅助编程
作为主要以 JAVA 语言为核心的后端开发者,其实,早些时间我也用过比如 Codota、Tabnine、Github 的 Copilot、阿里的 AI Coding Assistant 等 IDEA 插件,但是我并没有觉得很惊奇,感觉就是生成一些代码片段罢了,直到我接触了 ChatGPT......
(一)代码生成
去年9月份的时候,我接到一个项目,是老项目重构,具体要求就是给你提供入参和出参的结构文档,然后你来写具体的代码,将入参对象 XxxxDTO 解析后调用另外一个服务,然后他再将处理后的结果返回给你,你再解析成 java 对象返回。大概有一百多个接口要实现,其中不乏有入参中有几十个字段的类,写service层真的很累很累。入参结构和对应的类如下图:
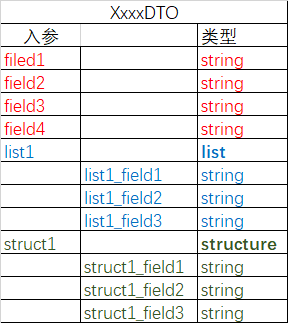
@DatapublicclassXxxxDTO {privateStringfiled1;privateStringfiled2;privateStringfiled3;privateStringfiled4;privateList<XxxxItemDTO> list1;privateStruct1 struct1;}@DataclassXxxxItemDTO {privateStringlist1_filed1;privateStringlist1_filed2;privateStringlist1_filed3;}@DataclassStruct1 {privateStringstruct1_filed1;privateStringstruct1_filed2;privateStringstruct1_filed3;}最开始,我分析了需求,使用了模板方法模式来实现这个service层的功能,然后每个接口就只需要实现模板类的抽象方法即可,即实现远程调用接口的函数名,入参对象的拼装,出参对象的拼装三个方法的实现。
后来发现,每个人的代码都或多或少的会出现问题,比如代码风格,单词打错,漏写或者错写等问题,而且代码特别多,不好定位问题。于是我就用 java 写了一个工具类,用来生成代码,这样,我们就只用关心入参和出参是否写对就行了,其他的代码就按模板来生成。
其实生成代码的方法有很多,比如通过模板文件生成代码,但是我为了不引入多余的依赖,我直接使用了最笨且最有效的方式,即反射解析类的详情,然后在控制台打印出具体代码。
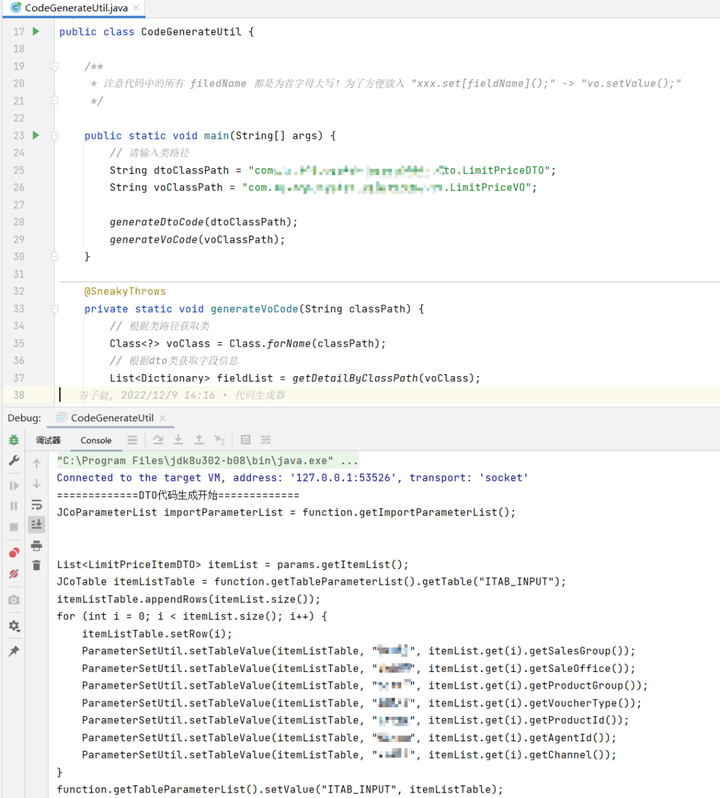
然后我们就顺利的减少了90%的代码编写,只需要将入参出参的类创建好即可。至于定位问题,只要能保证代码生成器没有问题,那我们就可以只通过判断类的创建是否正确就可以了。
之所以要说这个案例,就是为了来引出我是怎么使用 ChatGPT 的。在这个项目快结束的时候,AI火了,我试着使用 ChatGPT 来实现这个代码的生成,结局让我大吃一惊。
我的思路有两个,一个是通过给他模板和出入参对象的方式,让他直接给我生成代码,还有一种就是通过我的调教,让他给我写一个代码生成器出来。
于是我先测试了方案一,那就是把我已经写好的几个接口告诉给他,让他模仿着来给我写出类似的代码,如果哪里有问题,我就会告诉他确实是有问题的,让他进行调整,在经过半个小时的微调后,他已经能够很好地通过我给的类来生成具体的代码了。只要我这个会话还在,那么我就可以随时的回来,让他生成类似的代码。而坏处就是,只能我自己用,别人想用的话,就得自己去训练了。
所以才有了方案二,那就是让他帮我生成一个类似于我前面写的那个工具类,放到项目里,这样,所有开发者就能直接使用工具类来生成代码了。然后我便开始了实践,虽然说,他一开始回复我的代码生成器问题很多,但是我们能通过对话很好的让他进行微调,最后,我也是成功的让他帮我实现了代码生成器的功能,这比我自己手写快了一倍。
其实,我们还能使用 PDF 的 AI工具,直接读取文档,然后连出入参对象也生成出来呢~那可能是99%的代码都已经能自动生成了。(不过这个可能会出错,没有代码生成器稳定)
接下来,我直接演示一个案例,让大家感受下ChatGPT代码生成的威力:
总所周知,mybatis plus 等 ORM 框架是自带代码生成的,一般就是通过定义好数据库的表,然后通过解析这个表来实现代码的生成。但是,大多数人的习惯一般是先定义实体类,然后才去数据库创建对象,而且如果编码人员水平不高的话,很有可能会创建出一些很拉胯的数据表定义,从而导致问题。因此,我通过和 ChatGPT 对话,让他帮我生成了一个代码生成器,来实现通过反射实体类的方式生成建表SQL。(下面案例只展示最简单的实现,关于继承子类,涉及comment等高级操作这里就不演示了,感兴趣的话可以后台联系作者了解演示详情)

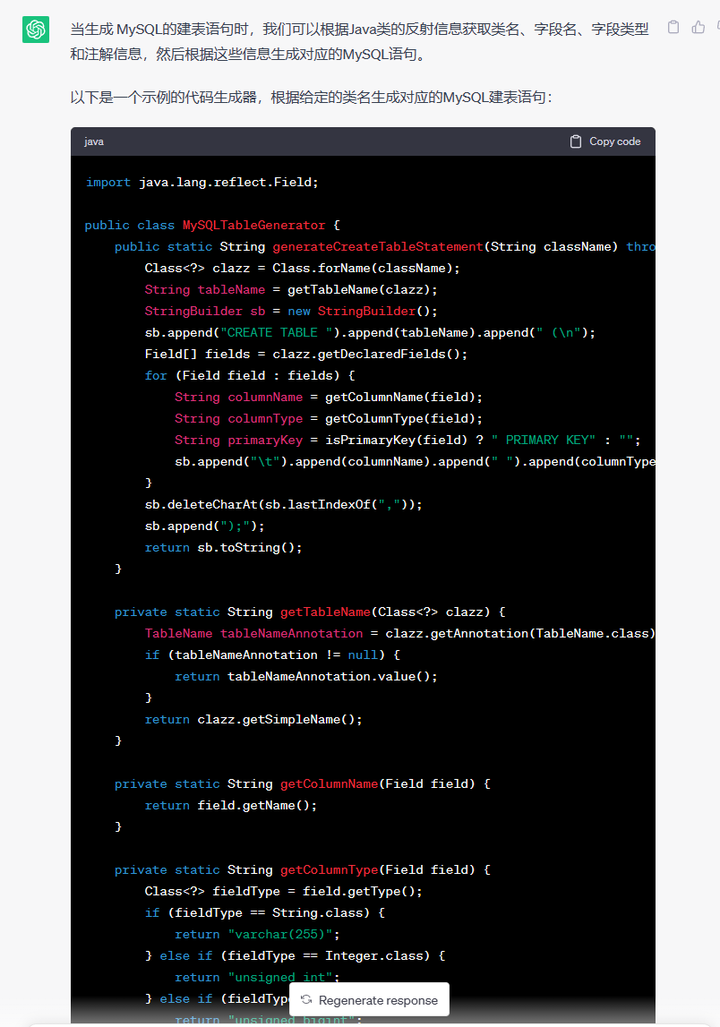
接下来我们去idea实测一下
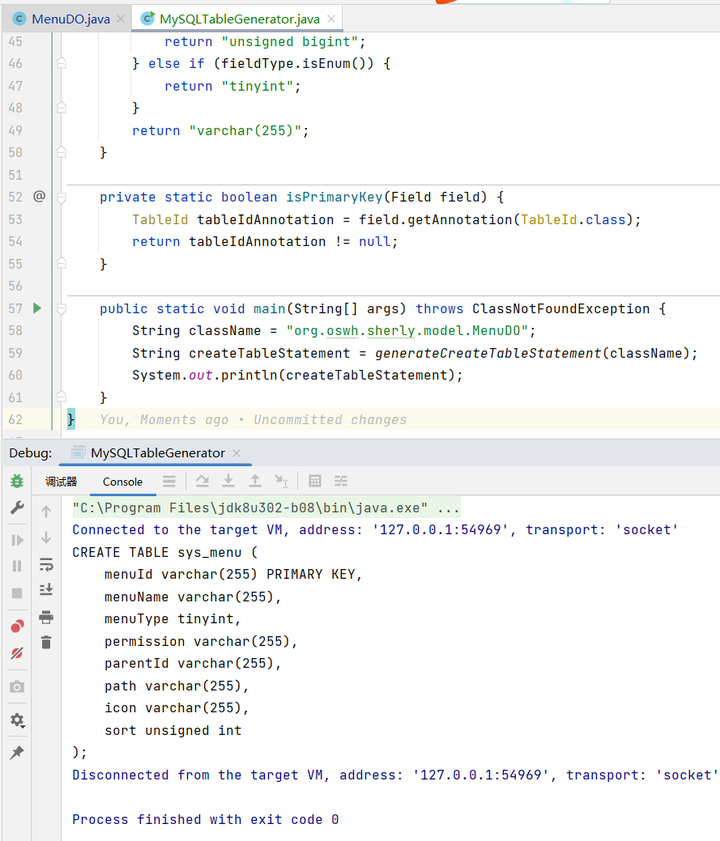
可以发现,他生成的SQL不是下划线形式,且没有设置非空,我们可以让他修改。
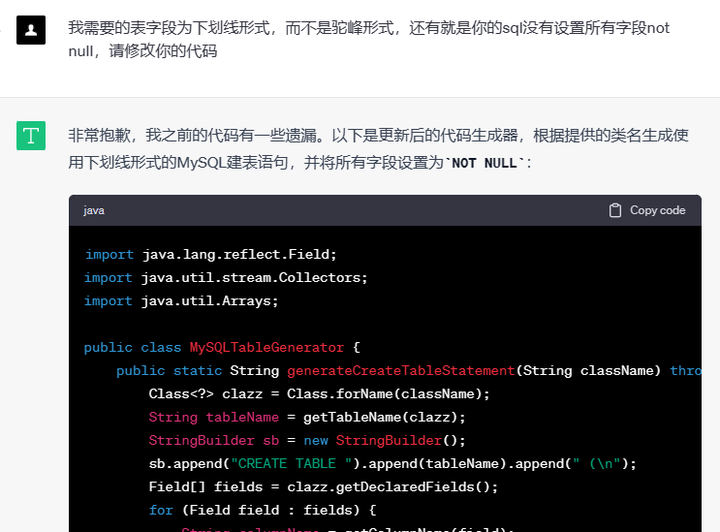
再去idea测试下
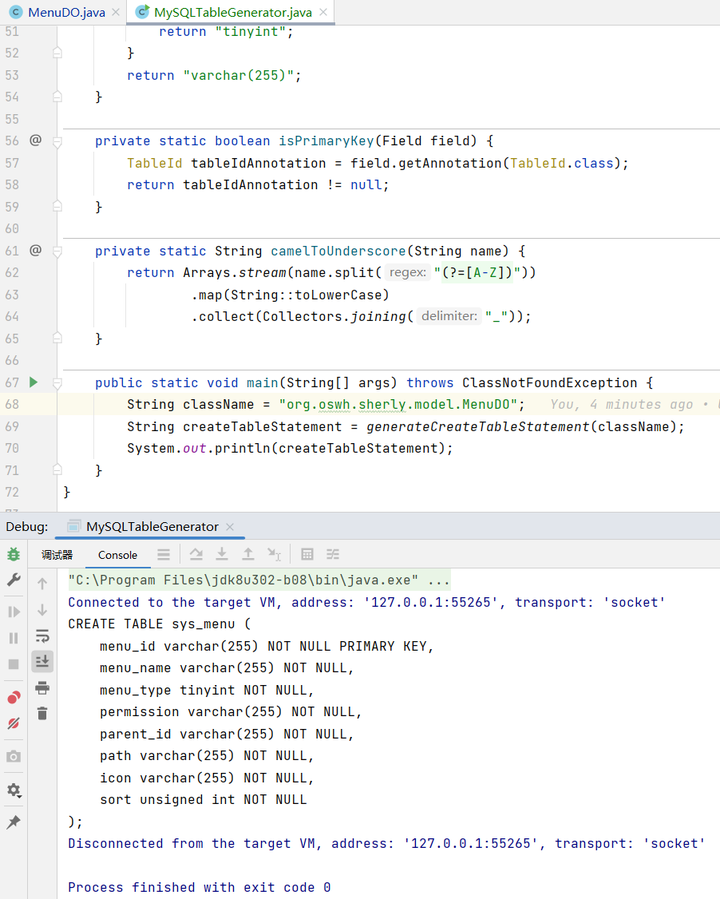
可以看到,基本上已经没有问题了,再自己微调一下代码,后面使用的时候,我们就只需要再根据实际情况,修改一下表字段的范围即可,这样就能省去一个一个复制粘贴的时间了,简直爽歪歪。(如前面提到的,目前这个sql生成器还是有很大问题的,大家可以自己试着完善一下,让他能实现在sql中也生成 comment,继承子类的 ORM 的对象的sql生成,固定字符集,设置默认值,设置数据类型的范围等等,当然我已经调教好我自己的sql生成器了)
像这种经常用的,当然是搞出代码生成器最好了,还有一些简单的,不常用的生成,我们就可以直接让他生成代码,而不是搞出代码生成器了。这里再举最后一个例子:
像有些老数据库,他们没有使用mybatis plus,需要写各种各样的SQL,很麻烦。那么我们就可以解析他的插入方法,生成 ORM 对象,然后通过mybatis plus来快捷使用。

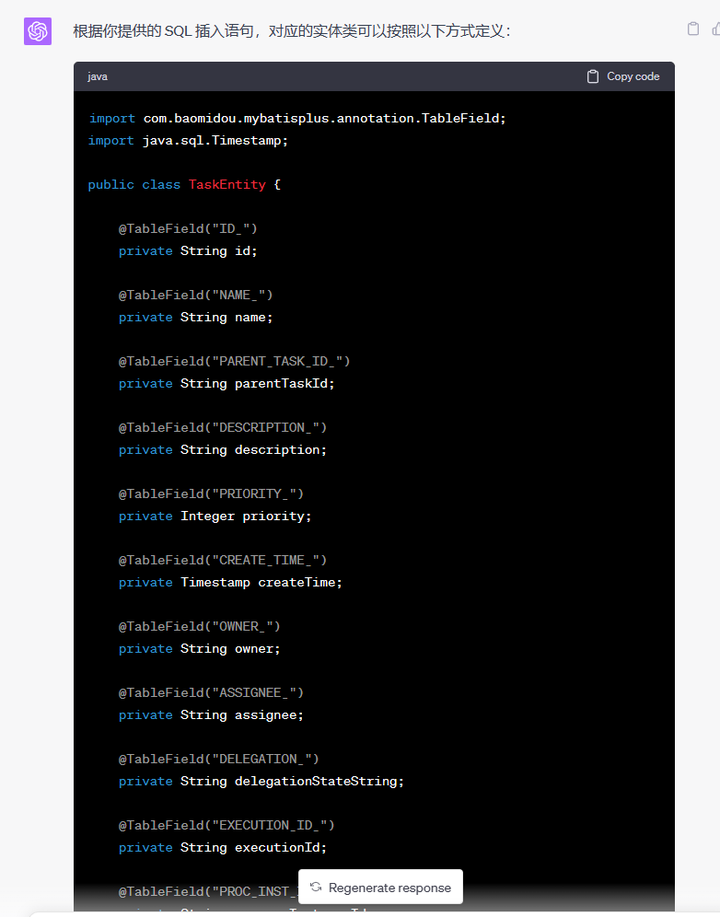
不会吧?不会吧?不会还有人在 AI 时代下,还一个个复制粘贴吧。不会吧,不会吧......(
狗头保命)
二、其他功能
(一)工具手册
关于工具手册这点没有太多可说的,我们可以把 ChatGPT 当成工具书,直接向他提问,很多时候,先问 ChatGPT,可能比百度,Google更快。他不仅能够给出你答案,你还可以让他给你演示示例,以下为我自己体验过的一些方向:
根据你的描述快速生成正则表达式,而不是自己慢慢调试。快速生成一些代码示例,比如问他如何合并两个list,如何使用stream流来实现groupBy,如何在springboot框架中动态增强源码。生成Ant风格的路径通配符,UEL风格的表达式等,其实这个基本上和①是一个意思(我自己容易记混,用ChatGPT生成确实比每次查资料再写快一些)。
(二)源码学习
最近的时间,我也是一直在研究flowable的源码,但是源码确实有很多地方没有注释,所以,我会拿出那个代码片段去问他,让他作为 flowable 专家来告诉我每一步是干什么的,他也能很聪明的识别出那段代码的作用,甚至知道代码是写在什么位置。
我也会将实体类都发给他,他会帮我把每一个字段的含义和用法告诉我,确实比百度要来的更快,有些东西搜索引擎和官方文档都查不到,但是他能够通过他的智能,判断出字段的作用,这极大地协助了我进行我们项目流程中心服务的代码优化。
而且,你可以在不知道是哪段代码的情况下,直接问他 flowable 这块是怎么实现的,他也能自己分析出来,然后告诉你答案。
(三)技术讨论
技术讨论这一部分,其实可以包括代码review,代码优化等子部分,也可以和他讨论当下一些技术的实现方案,每当我有好的想法时,我也会和他沟通,看看他的意见,下面我做一下展示:
代码分析的简单举例

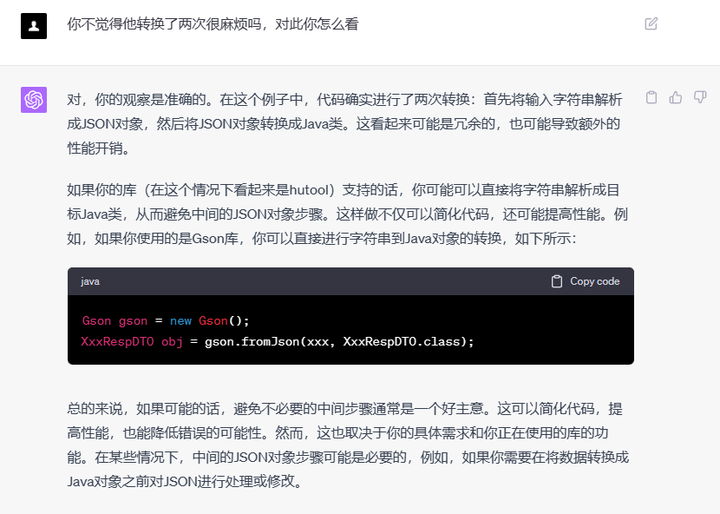
其他举例
很多时候,我们规定了工具类库,但是,有些人不知道有某些工具类,他们就会这种工具类用一下,那种工具类用一下,就显得很不协调,因此,我们可以直接问他,XXX工具类库有无这样的方法。使用该思路,可以让团队的代码更加让人心旷神怡,在一些代码规范要求比较高的地方很好用。
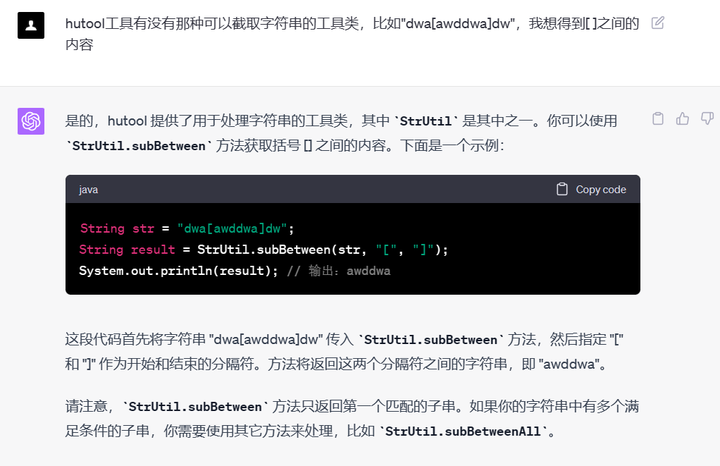
由于篇幅要求,我还是尽量精简了一些,主要还是想说明一些我自己的思路,希望对大家有用。
版权声明:本文由神州数码云基地团队整理撰写,若转载请注明出处。
公众号搜索神州数码云基地,了解更多AI相关技术干货。