【人工智能课程】计算机科学博士作业一
1 任务要求
模型拟合:用深度神经网络拟合一个回归模型。从各种角度对其改进,评价指标为MSE。掌握技巧: 熟悉并掌握深度学习模型训练的基本技巧。提高PyTorch的使用熟练度。掌握改进深度学习的方法。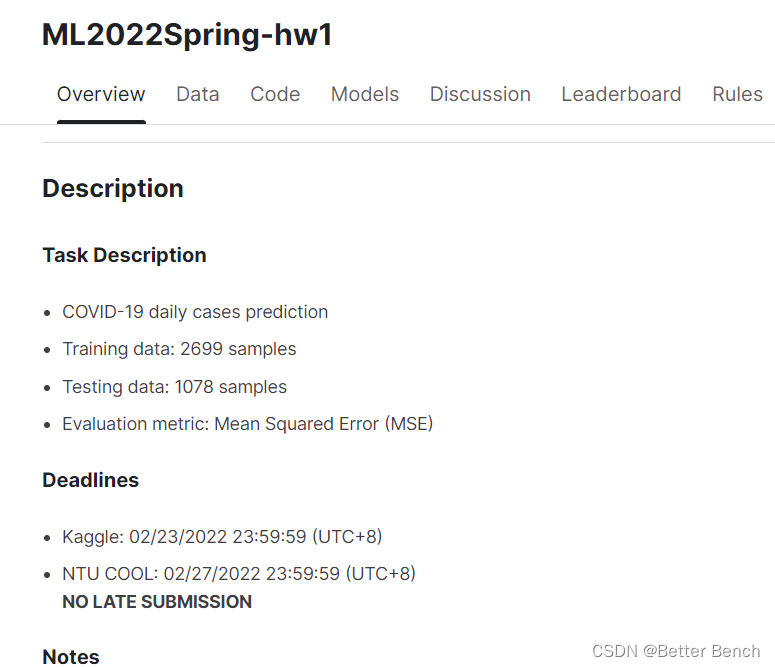
数据集下载:
Kaggle下载数据:https://www.kaggle.com/competitions/ml2022spring-hw1 百度云下载数据: https://pan.baidu.com/s/1ahGxV7dO2JQMRCYbmDQyVg (提取码:ml22)
这是一个非时间序列的回归任务,预测公共场所获取的人群数据,预测会发生COVID-19阳性的人数。改进角度,参考博客:http://t.csdnimg.cn/fUAzT

2 baseline 代码
我将老师给的代码重构了结构,便于组员之间协作编程,无需修改的代码都放到了utils.py中。只需要修改特征选择、神经网络、模型训练部分的代码就可以。
2.1 导入包
# 数值、矩阵操作import math# 数据读取与写入make_dotimport pandas as pdimport osimport csv# 学习曲线绘制from torch.utils.tensorboard import SummaryWriterfrom utils import *2.2 数据读取
# 设置随机种子便于复现same_seed(config['seed'])# 训练集大小(train_data size) : 2699 x 118 (id + 37 states + 16 features x 5 days) # 测试集大小(test_data size): 1078 x 117 (没有label (last day's positive rate))pd.set_option('display.max_column', 200) # 设置显示数据的列数train_df, test_df = pd.read_csv('./covid.train.csv'), pd.read_csv('./covid.test.csv')display(train_df.head(3)) # 显示前三行的样本train_data, test_data = train_df.values, test_df.valuesdel train_df, test_df # 删除数据减少内存占用train_data, valid_data = train_valid_split(train_data, config['valid_ratio'], config['seed'])# 打印数据的大小print(f"""train_data size: {train_data.shape} valid_data size: {valid_data.shape} test_data size: {test_data.shape}""")2.3 特征选择
def select_feat(train_data, valid_data, test_data, select_all=True): ''' 特征选择 选择较好的特征用来拟合回归模型 ''' y_train, y_valid = train_data[:,-1], valid_data[:,-1] raw_x_train, raw_x_valid, raw_x_test = train_data[:,:-1], valid_data[:,:-1], test_data if select_all: feat_idx = list(range(raw_x_train.shape[1])) else: feat_idx = [0,1,2,3,4] # TODO: 选择需要的特征 ,这部分可以自己调研一些特征选择的方法并完善. return raw_x_train[:,feat_idx], raw_x_valid[:,feat_idx], raw_x_test[:,feat_idx], y_train, y_valid# 特征选择x_train, x_valid, x_test, y_train, y_valid = select_feat(train_data, valid_data, test_data, config['select_all'])# 打印出特征数量.print(f'number of features: {x_train.shape[1]}')train_dataset, valid_dataset, test_dataset = COVID19Dataset(x_train, y_train), \ COVID19Dataset(x_valid, y_valid), \ COVID19Dataset(x_test)# 使用Pytorch中Dataloader类按照Batch将数据集加载train_loader = DataLoader(train_dataset, batch_size=config['batch_size'], shuffle=True, pin_memory=True)valid_loader = DataLoader(valid_dataset, batch_size=config['batch_size'], shuffle=True, pin_memory=True)test_loader = DataLoader(test_dataset, batch_size=config['batch_size'], shuffle=False, pin_memory=True)2.4 神经网络
class My_Model(nn.Module): def __init__(self, input_dim): super(My_Model, self).__init__() # TODO: 修改模型结构, 注意矩阵的维度(dimensions) self.layers = nn.Sequential( nn.Linear(input_dim, 16), nn.ReLU(), nn.Linear(16, 8), nn.ReLU(), nn.Linear(8, 1) ) def forward(self, x): x = self.layers(x) x = x.squeeze(1) # (B, 1) -> (B) return x2.5 模型训练
def trainer(train_loader, valid_loader, model, config, device): criterion = nn.MSELoss(reduction='mean') # 损失函数的定义 # 定义优化器 # TODO: 可以查看学习更多的优化器 https://pytorch.org/docs/stable/optim.html # TODO: L2 正则( 可以使用optimizer(weight decay...) )或者 自己实现L2正则. optimizer = torch.optim.SGD(model.parameters(), lr=config['learning_rate'], momentum=0.9) # tensorboard 的记录器 # 将 train loss 保存到 "tensorboard/train" 文件夹 train_writer = SummaryWriter(log_dir=os.path.join('tensorboard', 'train')) # 将 valid loss 保存到 "tensorboard/valid" 文件夹 valid_writer = SummaryWriter(log_dir=os.path.join('tensorboard', 'valid')) if not os.path.isdir('./models'): # 创建文件夹-用于存储模型 os.mkdir('./models') n_epochs, best_loss, step, early_stop_count = config['n_epochs'], math.inf, 0, 0 for epoch in range(n_epochs): model.train() # 训练模式 loss_record = [] # tqdm可以帮助我们显示训练的进度 train_pbar = tqdm(train_loader, position=0, leave=True) # 设置进度条的左边 : 显示第几个Epoch了 train_pbar.set_description(f'Epoch [{epoch+1}/{n_epochs}]') for x, y in train_pbar: optimizer.zero_grad() # 将梯度置0. x, y = x.to(device), y.to(device) # 将数据一到相应的存储位置(CPU/GPU) pred = model(x) loss = criterion(pred, y) loss.backward() # 反向传播 计算梯度. optimizer.step() # 更新网络参数 step += 1 loss_record.append(loss.detach().item()) # 训练完一个batch的数据,将loss 显示在进度条的右边 train_pbar.set_postfix({'loss': loss.detach().item()}) mean_train_loss = sum(loss_record)/len(loss_record) model.eval() # 将模型设置成 evaluation 模式. loss_record = [] for x, y in valid_loader: x, y = x.to(device), y.to(device) with torch.no_grad(): pred = model(x) loss = criterion(pred, y) loss_record.append(loss.item()) mean_valid_loss = sum(loss_record)/len(loss_record) print(f'Epoch [{epoch+1}/{n_epochs}]: Train loss: {mean_train_loss:.4f}, Valid loss: {mean_valid_loss:.4f}') # 每个epoch,在tensorboard 中记录验证的损失(后面可以展示出来) # 将训练损失和验证损失写入TensorBoard train_writer.add_scalar('Train-Valid Loss', mean_train_loss, step) valid_writer.add_scalar('Train-Valid Loss', mean_valid_loss, step) if mean_valid_loss < best_loss: best_loss = mean_valid_loss torch.save(model.state_dict(), config['save_path']) # 模型保存 print('Saving model with loss {:.3f}...'.format(best_loss)) early_stop_count = 0 else: early_stop_count += 1 if early_stop_count >= config['early_stop']: print('\nModel is not improving, so we halt the training session.') return device = 'cuda' if torch.cuda.is_available() else 'cpu'model = My_Model(input_dim=x_train.shape[1]).to(device) # 将模型和训练数据放在相同的存储位置(CPU/GPU)trainer(train_loader, valid_loader, model, config, device)2.6 模型可视化
%reload_ext tensorboard%tensorboard --logdir=tensorboard#执行完后这两行代码,在浏览器打开:http://localhost:6006/打开后,将smoothing调为0,就不会有四条曲线了。如果不改为0,就会自动加入一条平滑后的曲线在图中,影响观察。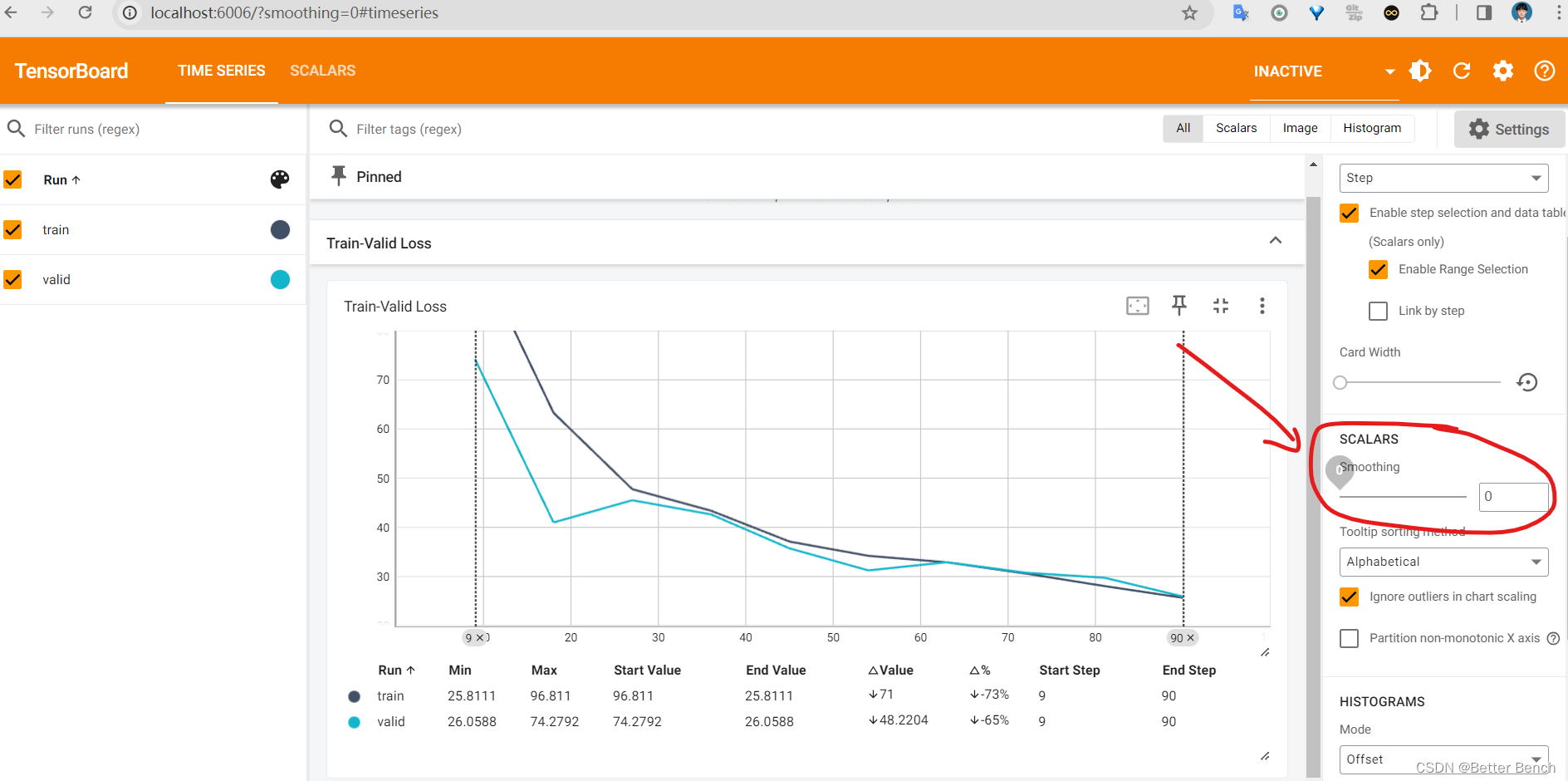
2.7 模型评价
model = My_Model(input_dim=x_train.shape[1]).to(device)model.load_state_dict(torch.load(config['save_path']))MSE = predict_MSE(valid_loader, model, device) print("MSE:",MSE) 只跑了10epoch的MSE
MSE: 30.798155
2.8 新建一个utils.py文件
把以下代码放进去utils.py文件中,放到和以上代码文件同一级的目录
import torchimport torch.nn as nnfrom torch.utils.data import Dataset, DataLoader, random_splitimport numpy as npfrom tqdm import tqdmconfig = { 'seed': 5201314, # 随机种子,可以自己填写. :) 'select_all': True, # 是否选择全部的特征 'valid_ratio': 0.2, # 验证集大小(validation_size) = 训练集大小(train_size) * 验证数据占比(valid_ratio) 'n_epochs': 10, # 数据遍历训练次数 'batch_size': 256, 'learning_rate': 1e-5, 'early_stop': 400, # 如果early_stop轮损失没有下降就停止训练. 'save_path': './models/model.ckpt' # 模型存储的位置}def same_seed(seed): ''' 设置随机种子(便于复现) ''' torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False np.random.seed(seed) torch.manual_seed(seed) if torch.cuda.is_available(): torch.cuda.manual_seed_all(seed) print(f'Set Seed = {seed}')def train_valid_split(data_set, valid_ratio, seed): ''' 数据集拆分成训练集(training set)和 验证集(validation set) ''' valid_set_size = int(valid_ratio * len(data_set)) train_set_size = len(data_set) - valid_set_size train_set, valid_set = random_split(data_set, [train_set_size, valid_set_size], generator=torch.Generator().manual_seed(seed)) return np.array(train_set), np.array(valid_set)def predict(test_loader, model, device): model.eval() # 设置成eval模式. preds = [] for x in tqdm(test_loader): x = x.to(device) with torch.no_grad(): pred = model(x) preds.append(pred.detach().cpu()) preds = torch.cat(preds, dim=0).numpy() return predsdef predict_MSE(valid_loader, model, device): model.eval() # 设置成eval模式. preds = [] labels = [] for x,y in tqdm(valid_loader): x = x.to(device) with torch.no_grad(): pred = model(x) preds.append(pred.detach().cpu()) labels.append(y) preds = torch.cat(preds, dim=0).numpy() labels = torch.cat(labels, dim=0).numpy() # 计算MSE mse = np.mean((preds - labels) ** 2) return mseclass COVID19Dataset(Dataset): ''' x: np.ndarray 特征矩阵. y: np.ndarray 目标标签, 如果为None,则是预测的数据集 ''' def __init__(self, x, y=None): if y is None: self.y = y else: self.y = torch.FloatTensor(y) self.x = torch.FloatTensor(x) def __getitem__(self, idx): if self.y is None: return self.x[idx] return self.x[idx], self.y[idx] def __len__(self): return len(self.x)3 改进程序
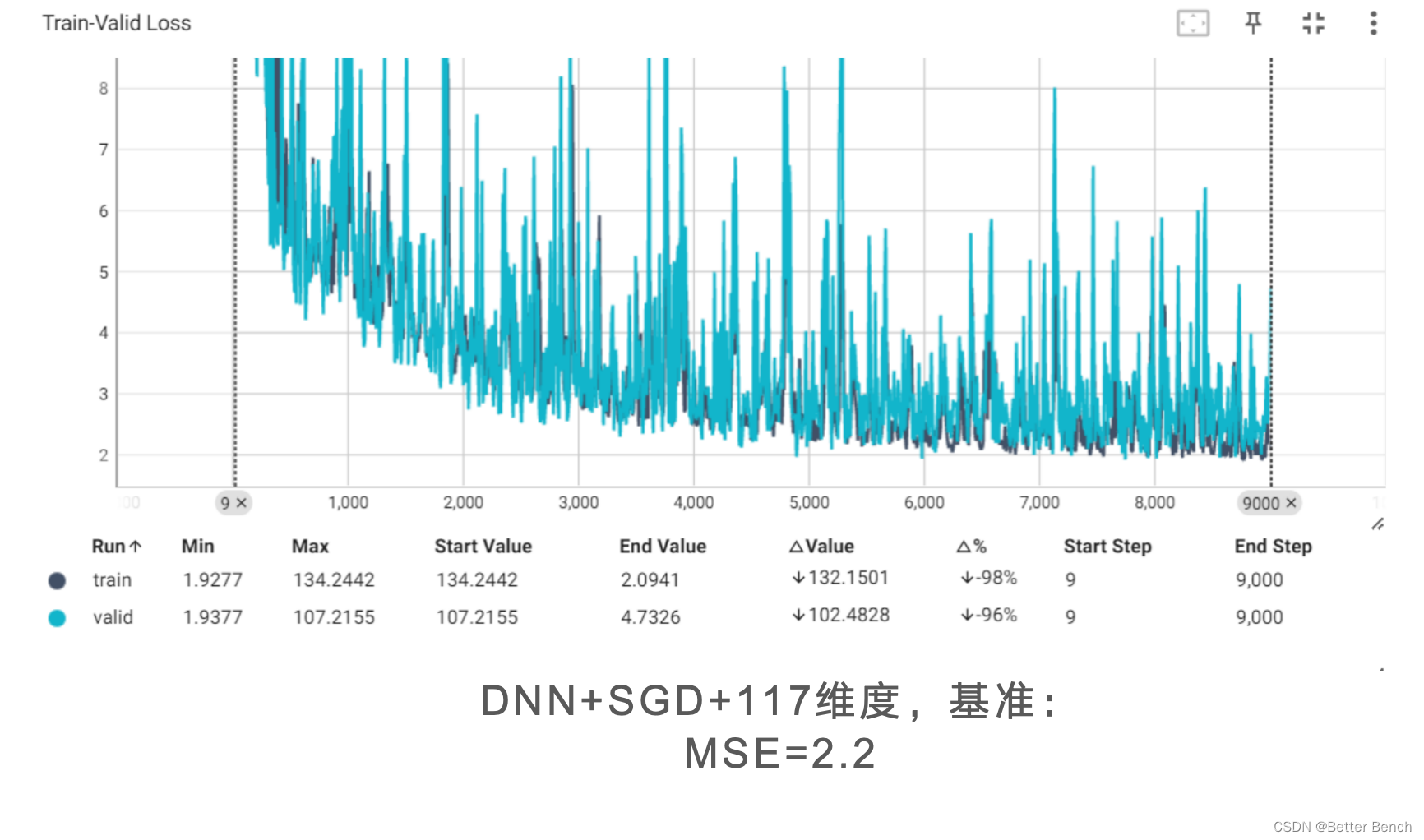
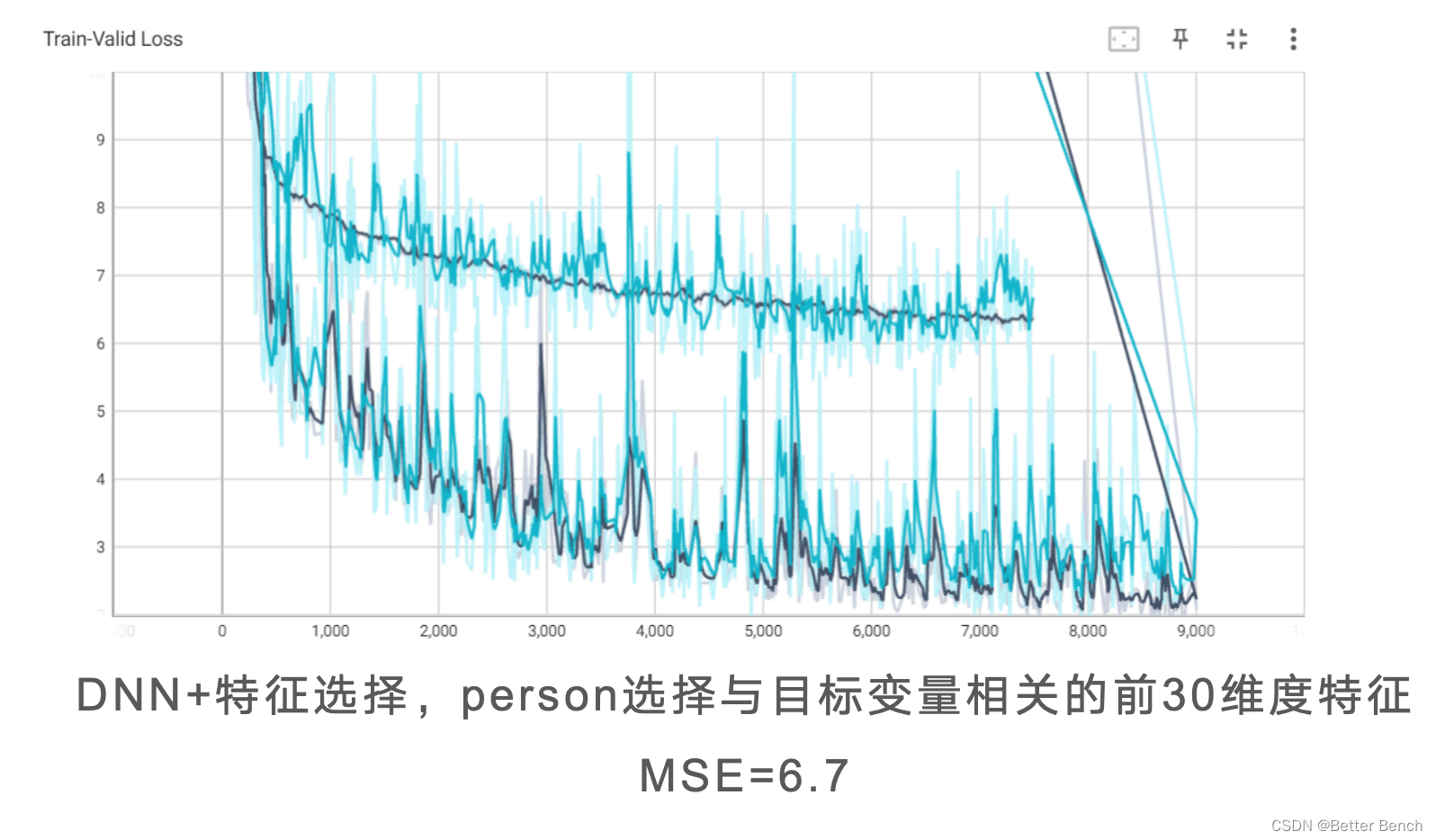
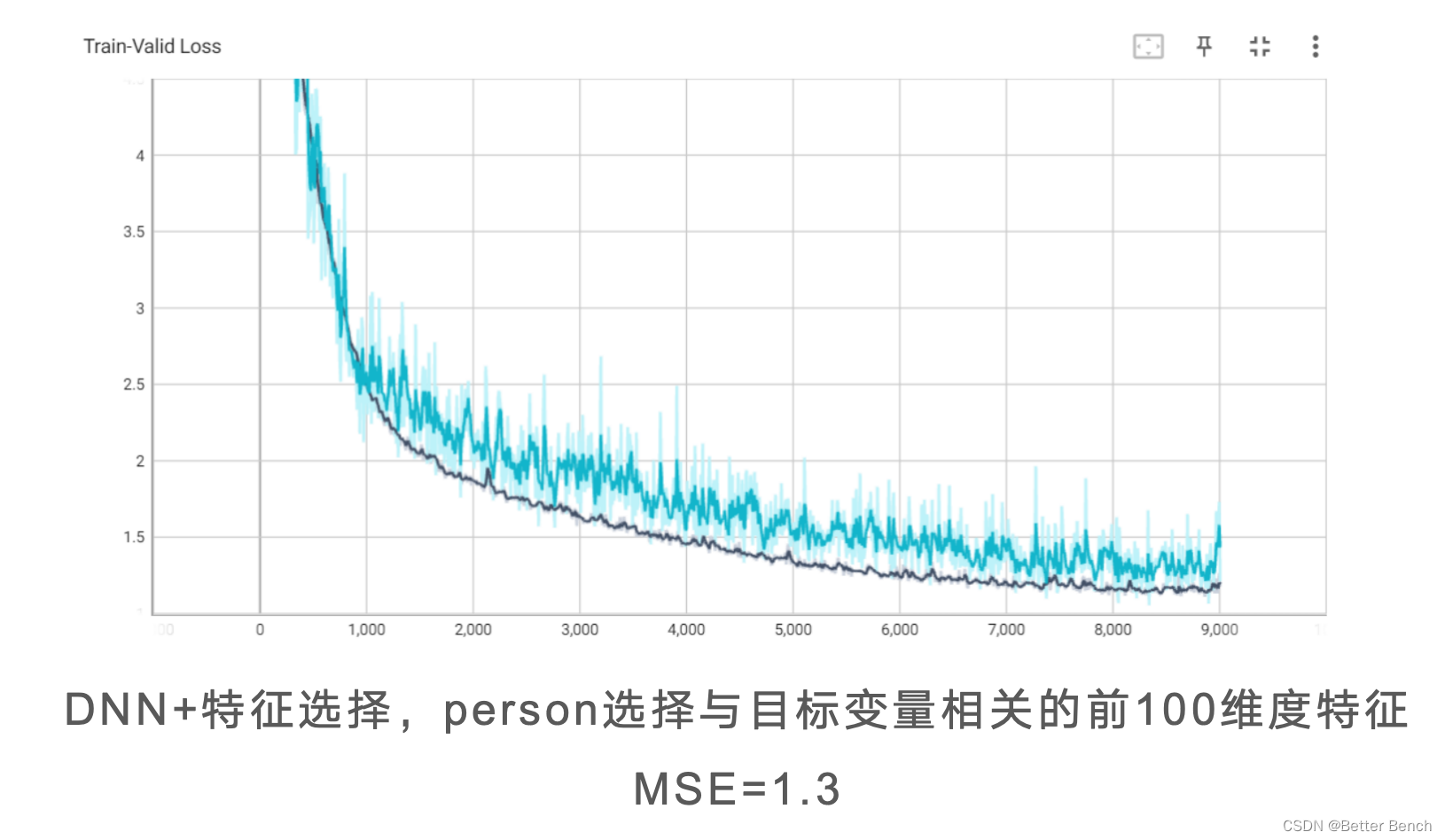
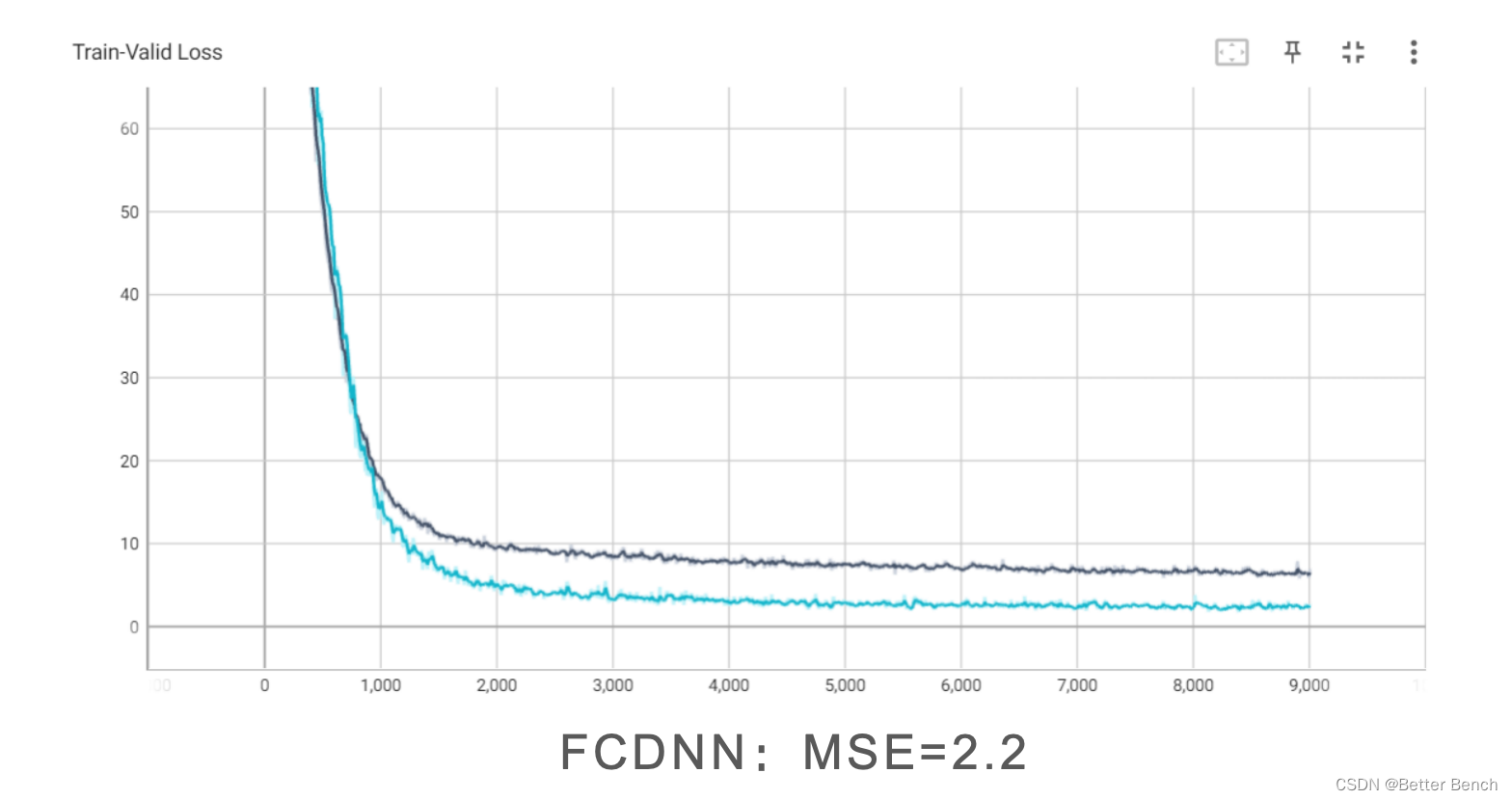
以下统一设定1000epoch,改进角度包括
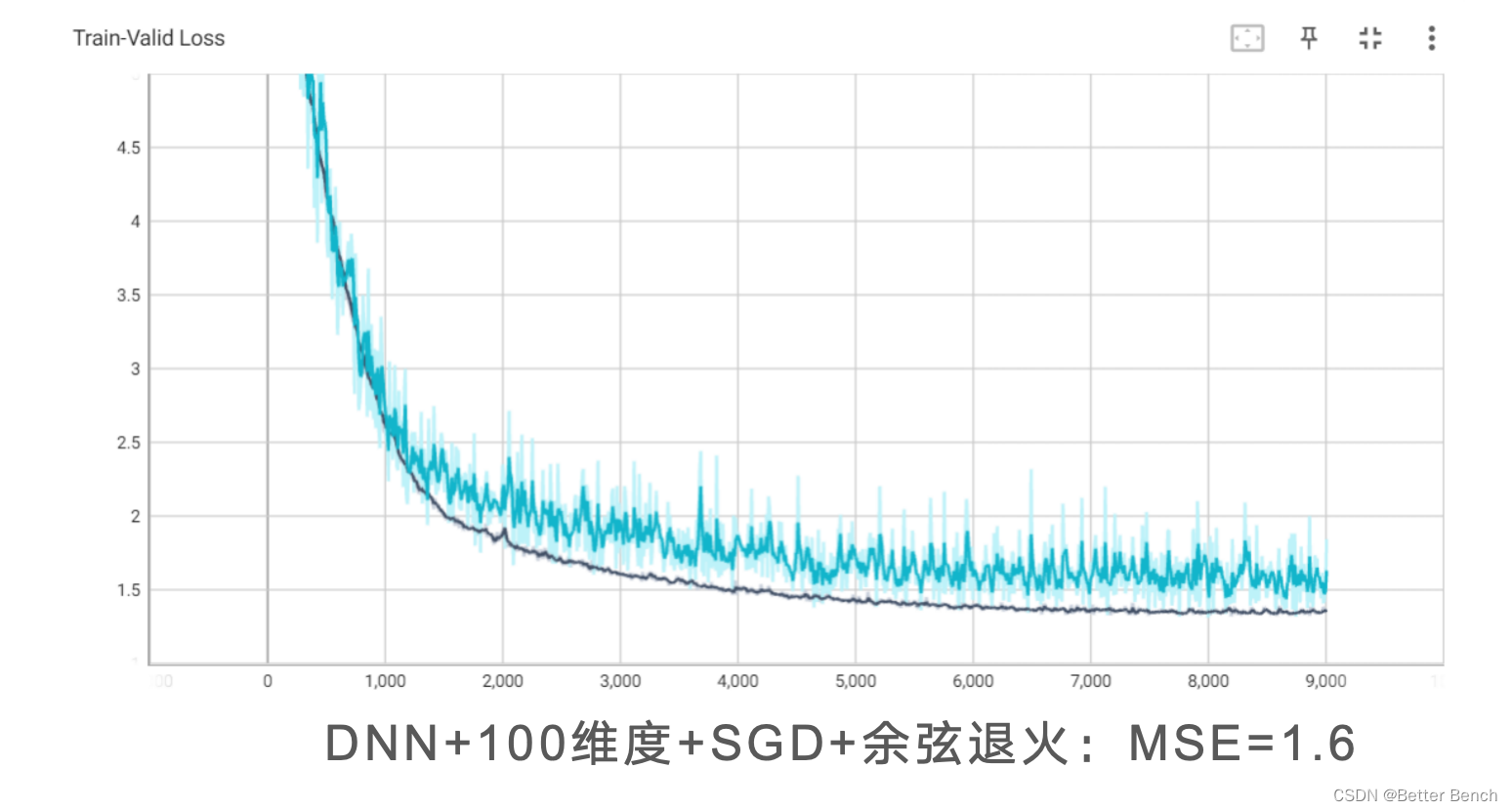
(1)特征选择
(2)模型改进
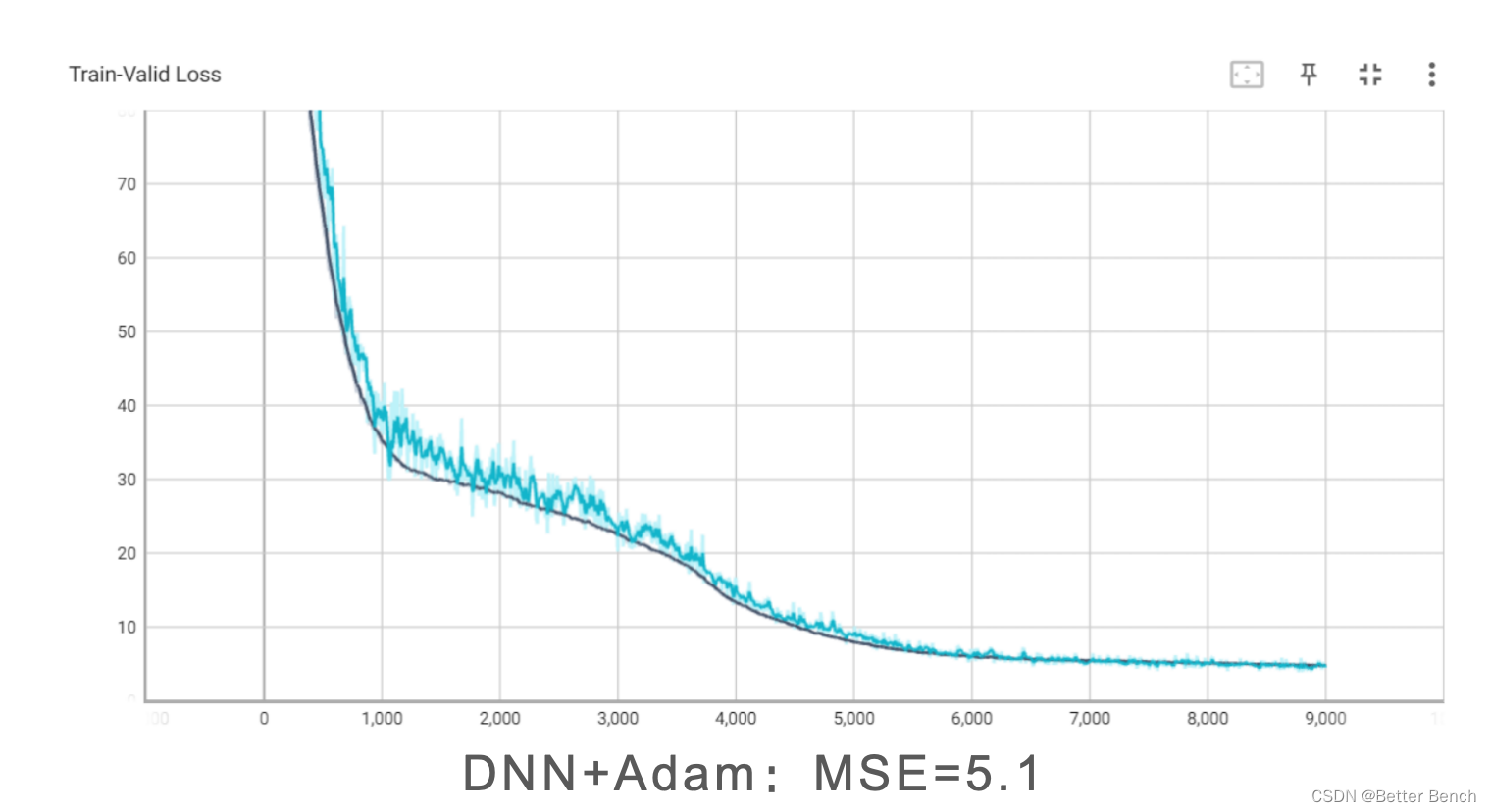
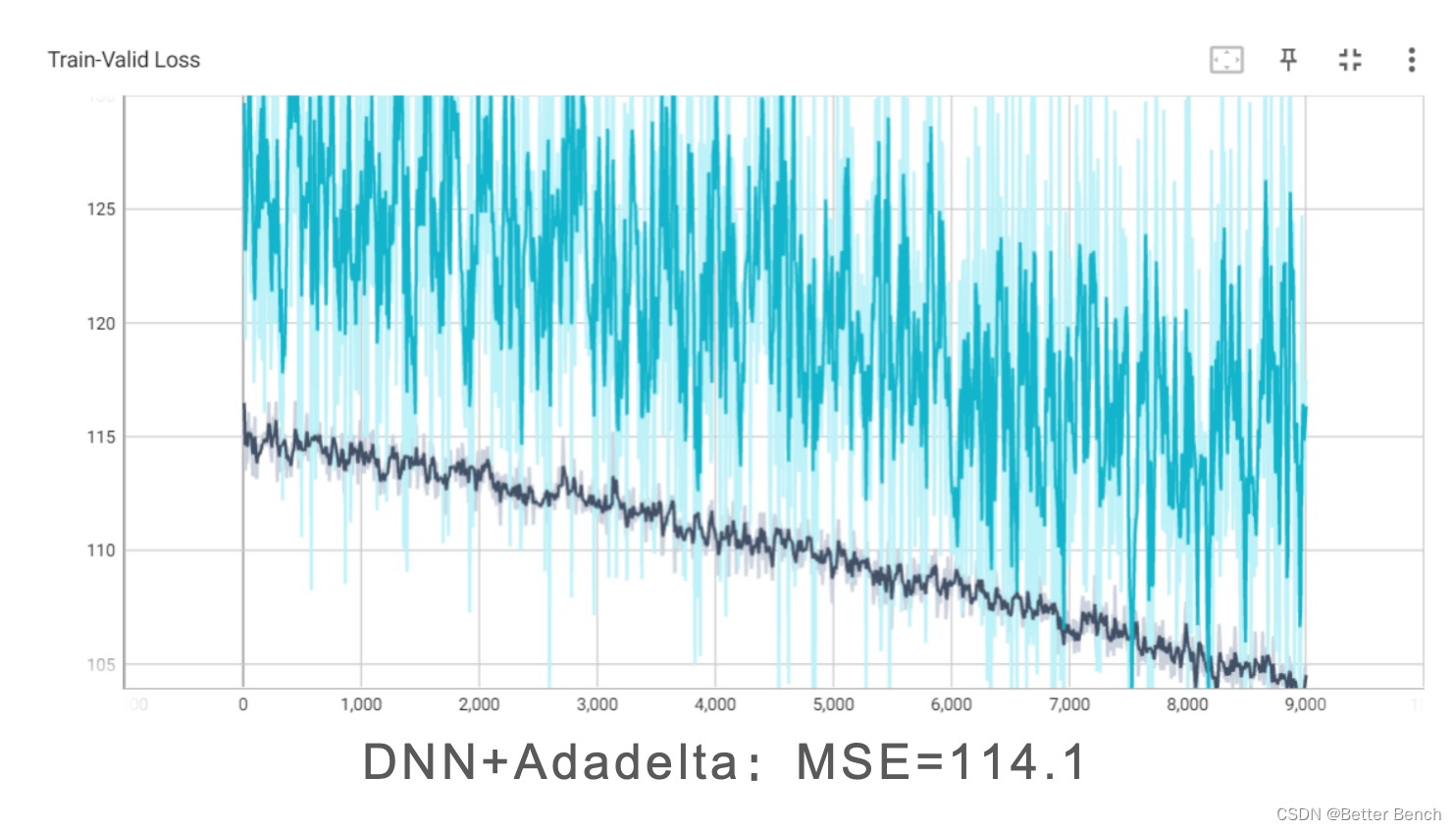
DNNFCDNNDenseNetResNet(3)优化器
SGDAadmAdadelta(4)余弦学习率
# 数值、矩阵操作import math# 数据读取与写入make_dotimport pandas as pdimport osimport csv# 学习曲线绘制from torch.utils.tensorboard import SummaryWriterfrom utils import *# 设置随机种子便于复现same_seed(config['seed'])# 训练集大小(train_data size) : 2699 x 118 (id + 37 states + 16 features x 5 days) # 测试集大小(test_data size): 1078 x 117 (没有label (last day's positive rate))pd.set_option('display.max_column', 200) # 设置显示数据的列数train_df, test_df = pd.read_csv('./covid.train.csv'), pd.read_csv('./covid.test.csv')display(train_df.head(3)) # 显示前三行的样本train_data, test_data = train_df.values, test_df.valuesdel train_df, test_df # 删除数据减少内存占用train_data, valid_data = train_valid_split(train_data, config['valid_ratio'], config['seed'])# 打印数据的大小print(f"""train_data size: {train_data.shape} valid_data size: {valid_data.shape} test_data size: {test_data.shape}""")def select_feat(train_data, valid_data, test_data, select_all=True): ''' 特征选择 选择较好的特征用来拟合回归模型 ''' y_train, y_valid = train_data[:,-1], valid_data[:,-1] raw_x_train, raw_x_valid, raw_x_test = train_data[:,:-1], valid_data[:,:-1], test_data if select_all: feat_idx = list(range(raw_x_train.shape[1])) else: # feat_idx = [0,1,2,3,4] # TODO: 选择需要的特征 ,这部分可以自己调研一些特征选择的方法并完善. # feat_idx = range(0,117) correlation_matrix = np.corrcoef(raw_x_train, rowvar=False) corr_with_target = np.abs(correlation_matrix[-1, :-1]) feat_idx = list(np.argsort(corr_with_target)[::-1][:100]) # 选择与目标变量相关性最高的五个特征索引 return raw_x_train[:,feat_idx], raw_x_valid[:,feat_idx], raw_x_test[:,feat_idx], y_train, y_valid# 特征选择x_train, x_valid, x_test, y_train, y_valid = select_feat(train_data, valid_data, test_data, config['select_all'])# 打印出特征数量.print(f'number of features: {x_train.shape[1]}')train_dataset, valid_dataset, test_dataset = COVID19Dataset(x_train, y_train), \ COVID19Dataset(x_valid, y_valid), \ COVID19Dataset(x_test)# 使用Pytorch中Dataloader类按照Batch将数据集加载train_loader = DataLoader(train_dataset, batch_size=config['batch_size'], shuffle=True, pin_memory=True)valid_loader = DataLoader(valid_dataset, batch_size=config['batch_size'], shuffle=True, pin_memory=True)test_loader = DataLoader(test_dataset, batch_size=config['batch_size'], shuffle=False, pin_memory=True)class Raw_Model(nn.Module): def __init__(self, input_dim): super(Raw_Model, self).__init__() # TODO: 修改模型结构, 注意矩阵的维度(dimensions) self.layers = nn.Sequential( nn.Linear(input_dim, 16), nn.ReLU(), nn.Linear(16, 8), nn.ReLU(), nn.Linear(8, 1) ) def forward(self, x): x = self.layers(x) x = x.squeeze(1) # (B, 1) -> (B) return ximport torchimport torch.nn as nnimport torch.nn.functional as Fclass FCNN_Model(nn.Module): def __init__(self, input_dim): super(FCNN_Model, self).__init__() # 修改模型结构 self.layers = nn.Sequential( nn.Linear(input_dim, 64), nn.BatchNorm1d(64), nn.LeakyReLU(0.01), # 使用LeakyReLU nn.Dropout(0.3), nn.Linear(64, 32), nn.BatchNorm1d(32), nn.LeakyReLU(0.01), # 使用LeakyReLU nn.Dropout(0.3), nn.Linear(32, 16), nn.BatchNorm1d(16), nn.LeakyReLU(0.01), # 使用LeakyReLU nn.Dropout(0.3), nn.Linear(16, 1) ) def forward(self, x): x = self.layers(x) x = x.squeeze(1) # (B, 1) -> (B) return ximport torchimport torch.nn as nnimport torch.nn.functional as F# 定义基础的残差块class ResidualBlock(nn.Module): def __init__(self, input_dim): super(ResidualBlock, self).__init__() self.fc1 = nn.Linear(input_dim, input_dim) self.relu = nn.ReLU(inplace=True) self.fc2 = nn.Linear(input_dim, input_dim) def forward(self, x): residual = x out = self.fc1(x) out = self.relu(out) out = self.fc2(out) out += residual # 这里添加了跳越连接 out = self.relu(out) return out# 将模型定义为一个等于ResNet的回归模型class RegressionResNet(nn.Module): def __init__(self, input_dim, num_blocks=2): super(RegressionResNet, self).__init__() # 输入层 self.input_fc = nn.Linear(input_dim, input_dim) # 创建残差块堆叠 self.res_blocks = nn.Sequential( *[ResidualBlock(input_dim) for _ in range(num_blocks)] ) # 输出层 self.output_fc = nn.Linear(input_dim, 1) def forward(self, x): x = F.relu(self.input_fc(x)) x = self.res_blocks(x) x = self.output_fc(x) x = x.squeeze(1) # (B, 1) -> (B) return ximport torchimport torch.nn as nnimport torch.nn.functional as Fclass DenseLayer(nn.Module): def __init__(self, in_channels, growth_rate): super(DenseLayer, self).__init__() # A single Dense Layer within a Dense Block self.dense_layer = nn.Sequential( nn.BatchNorm1d(in_channels), nn.ReLU(inplace=True), nn.Linear(in_channels, growth_rate), nn.Dropout(0.2) # Dropout for regularization ) def forward(self, x): new_features = self.dense_layer(x) # Concatenating the input features with the new features return torch.cat([x, new_features], 1)class DenseBlock(nn.Module): def __init__(self, num_layers, in_channels, growth_rate): super(DenseBlock, self).__init__() self.block = nn.Sequential() for i in range(num_layers): layer = DenseLayer(in_channels + i * growth_rate, growth_rate) self.block.add_module(f"dense_layer_{i + 1}", layer) def forward(self, x): return self.block(x)class TransitionLayer(nn.Module): def __init__(self, in_channels, out_channels): super(TransitionLayer, self).__init__() # This layer reduces the number of features (compression) self.transition = nn.Sequential( nn.BatchNorm1d(in_channels), nn.ReLU(inplace=True), nn.Linear(in_channels, out_channels), nn.Dropout(0.2) # Dropout for regularization ) def forward(self, x): return self.transition(x)class My_DenseNet_Model(nn.Module): def __init__(self, input_dim, num_classes=1, growth_rate=12, block_config=(6, 12, 24), compression=0.5): super(My_DenseNet_Model, self).__init__() # Initial convolution layer self.init_features = nn.Sequential( nn.Linear(input_dim, growth_rate * 2), nn.ReLU(inplace=True) ) # DenseBlocks and TransitionLayers num_features = growth_rate * 2 # Initial number of features self.features = nn.Sequential() for i, num_layers in enumerate(block_config): block = DenseBlock(num_layers=num_layers, in_channels=num_features, growth_rate=growth_rate) self.features.add_module(f"denseblock_{i + 1}", block) num_features += num_layers * growth_rate if i != len(block_config) - 1: # Do not add Transition Layer after the last block trans = TransitionLayer(in_channels=num_features, out_channels=int(num_features * compression)) self.features.add_module(f"transition_{i + 1}", trans) num_features = int(num_features * compression) # Final batch normalization self.features.add_module('norm5', nn.BatchNorm1d(num_features)) # Linear layer for regression self.classifier = nn.Linear(num_features, num_classes) def forward(self, x): x = self.init_features(x) x = self.features(x) x = F.relu(x, inplace=True) x = F.avg_pool1d(x, kernel_size=1).view(x.size(0), -1) x = self.classifier(x) return xfrom torch.optim.lr_scheduler import CosineAnnealingLRdef trainer(train_loader, valid_loader, model, config, device): criterion = nn.MSELoss(reduction='mean') # 损失函数的定义 # 定义优化器 optimizer = torch.optim.SGD(model.parameters(), lr=config['learning_rate'], momentum=0.9) # optimizer = torch.optim.Adam(model.parameters(), lr=config['learning_rate']) # optimizer = torch.optim.Adadelta(model.parameters(), lr=config['learning_rate'], rho=0.9, eps=1e-06, weight_decay=0) # tensorboard 的记录器 # 将 train loss 保存到 "tensorboard/train" 文件夹 train_writer = SummaryWriter(log_dir=os.path.join('tensorboard', 'train')) # 将 valid loss 保存到 "tensorboard/valid" 文件夹 valid_writer = SummaryWriter(log_dir=os.path.join('tensorboard', 'valid')) # 添加余弦退火调度器 scheduler = CosineAnnealingLR(optimizer, T_max=config['n_epochs'], eta_min=0) if not os.path.isdir('./models'): # 创建文件夹-用于存储模型 os.mkdir('./models') n_epochs, best_loss, step, early_stop_count = config['n_epochs'], math.inf, 0, 0 for epoch in range(n_epochs): model.train() # 训练模式 loss_record = [] # tqdm可以帮助我们显示训练的进度 train_pbar = tqdm(train_loader, position=0, leave=True) # 设置进度条的左边 : 显示第几个Epoch了 train_pbar.set_description(f'Epoch [{epoch+1}/{n_epochs}]') for x, y in train_pbar: optimizer.zero_grad() # 将梯度置0. x, y = x.to(device), y.to(device) # 将数据一到相应的存储位置(CPU/GPU) pred = model(x) loss = criterion(pred, y) loss.backward() # 反向传播 计算梯度. optimizer.step() # 更新网络参数 step += 1 loss_record.append(loss.detach().item()) # 训练完一个batch的数据,将loss 显示在进度条的右边 train_pbar.set_postfix({'loss': loss.detach().item()}) mean_train_loss = sum(loss_record)/len(loss_record) model.eval() # 将模型设置成 evaluation 模式. loss_record = [] for x, y in valid_loader: x, y = x.to(device), y.to(device) with torch.no_grad(): pred = model(x) loss = criterion(pred, y) loss_record.append(loss.item()) mean_valid_loss = sum(loss_record)/len(loss_record) print(f'Epoch [{epoch+1}/{n_epochs}]: Train loss: {mean_train_loss:.4f}, Valid loss: {mean_valid_loss:.4f}') # 每个epoch,在tensorboard 中记录验证的损失(后面可以展示出来) # 将训练损失和验证损失写入TensorBoard train_writer.add_scalar('Train-Valid Loss', mean_train_loss, step) valid_writer.add_scalar('Train-Valid Loss', mean_valid_loss, step) if mean_valid_loss < best_loss: best_loss = mean_valid_loss torch.save(model.state_dict(), config['save_path']) # 模型保存 print('Saving model with loss {:.3f}...'.format(best_loss)) early_stop_count = 0 else: early_stop_count += 1 if early_stop_count >= config['early_stop']: print('\nModel is not improving, so we halt the training session.') return # 更新学习率 scheduler.step()device = 'cuda' if torch.cuda.is_available() else 'cpu'model = Raw_Model(input_dim=x_train.shape[1]).to(device) # model = RegressionResNet(input_dim=x_train.shape[1],num_blocks=10).to(device) # model = My_DenseNet_Model(input_dim=x_train.shape[1]).to(device)# model = FCNN_Model(input_dim=x_train.shape[1]).to(device)trainer(train_loader, valid_loader, model, config, device)# model = RegressionResNet(input_dim=x_train.shape[1],num_blocks=10).to(device)# model = My_DenseNet_Model(input_dim=x_train.shape[1]).to(device)model = Raw_Model(input_dim=x_train.shape[1]).to(device)# model = FCNN_Model(input_dim=x_train.shape[1]).to(device)model.load_state_dict(torch.load(config['save_path']))MSE = predict_MSE(valid_loader, model, device) print("MSE:",MSE)