CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
昨天都被Meta的SAM模型刷屏了吧!但在其发布24h不到!
北京智源人工智能研究院联合浙大、北大发布SegGPT: Segmenting Everything In Context。让我们来一探究竟。
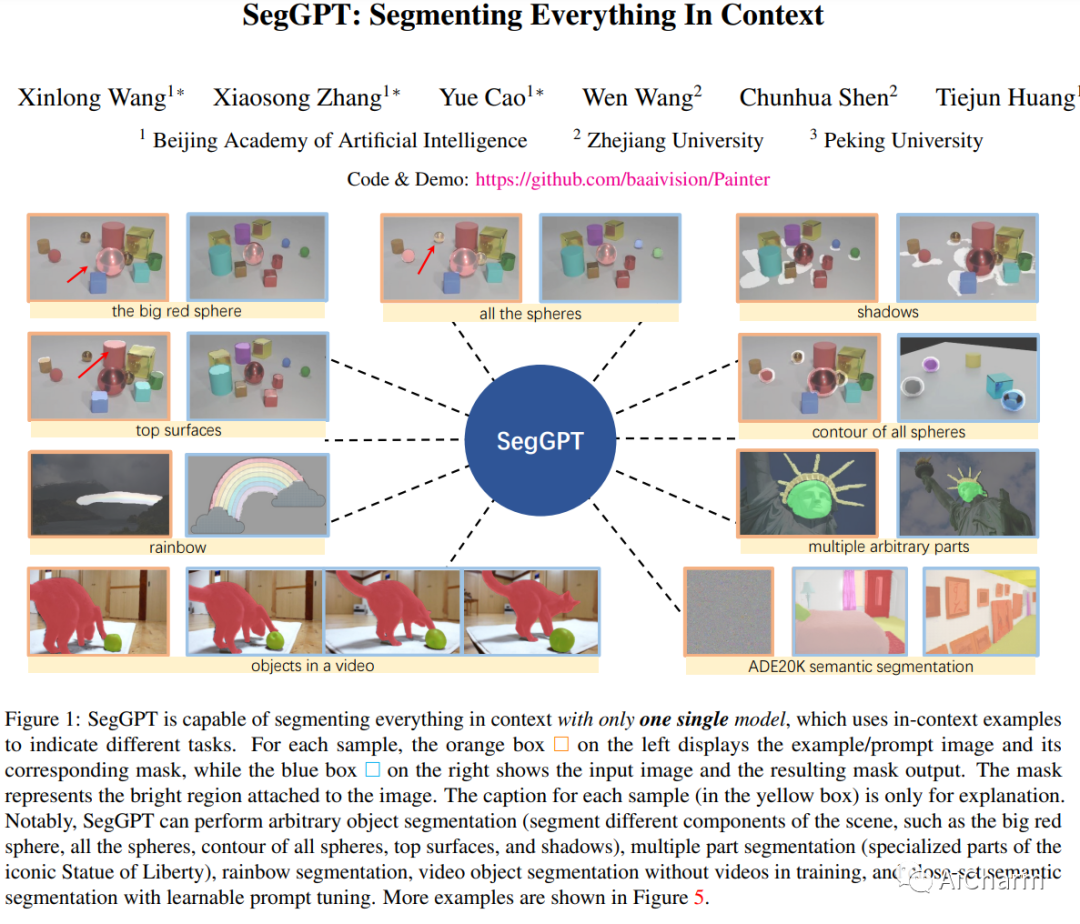
我们提出了SegGPT,这是一个通用模型,可以在上下文中分段任何东西。我们将各种分割任务统一到一个通用的上下文学习框架中,通过将它们转换为图像的相同格式来适应不同种类的分割数据。SegGPT的训练被公式化为一个具有随机颜色映射的上下文着色问题,目标是根据上下文完成不同的任务,而不是依赖于特定的颜色。训练后,SegGPT可以通过上下文推理在图像或视频中执行任意的分割任务,例如对象实例、杂项、零件、轮廓和文本。SegGPT在广泛的任务中进行评估,包括少量语义分割、视频对象分割、语义分割和全景分割。我们的结果表明,在领域内和领域外目标的分割方面,无论是质量还是数量,都具有强大的能力。
项目代码:https://github.com/baaivision/Painter
1.研究背景与动机:
传统的基于规则和基于图像特征的方法需要手动设计特征或规则,而深度学习方法通常需要大量标注数据来训练模型。此外,现有方法通常只能处理特定类型的分割任务,难以适应不同类型的数据。因此,本文旨在提出一种通用的图像分割模型,可以自动适应不同类型的数据,并且无需大量标注数据即可进行训练。同时,本文还希望通过使用自然语言处理技术来解决图像分割任务中存在的挑战,并提高模型性能。
2.贡献
本文的主要贡献如下:
提出了一种通用的图像分割模型SegGPT,它使用基于自然语言处理的生成式预训练模型GPT-3,并将其应用于图像分割任务中。SegGPT模型采用上下文学习框架来统一各种分割任务,并使用随机颜色映射来训练模型。
引入了上下文集成策略和In-Context Tuning方法来提高模型性能。上下文集成策略利用多个上下文信息来增强模型的表征能力,而In-Context Tuning方法则通过微调预训练模型来适应特定任务。
对SegGPT进行了广泛评估,使用多个数据集进行实验,包括ADE20K、COCO-Stuff、PASCAL VOC 2012、Cityscapes等。实验结果表明,SegGPT在各种分割任务上都取得了优秀的性能,并且在少样本学习和视频对象分割等任务上表现出色。
3.方法
3.1 In-Context Coloring
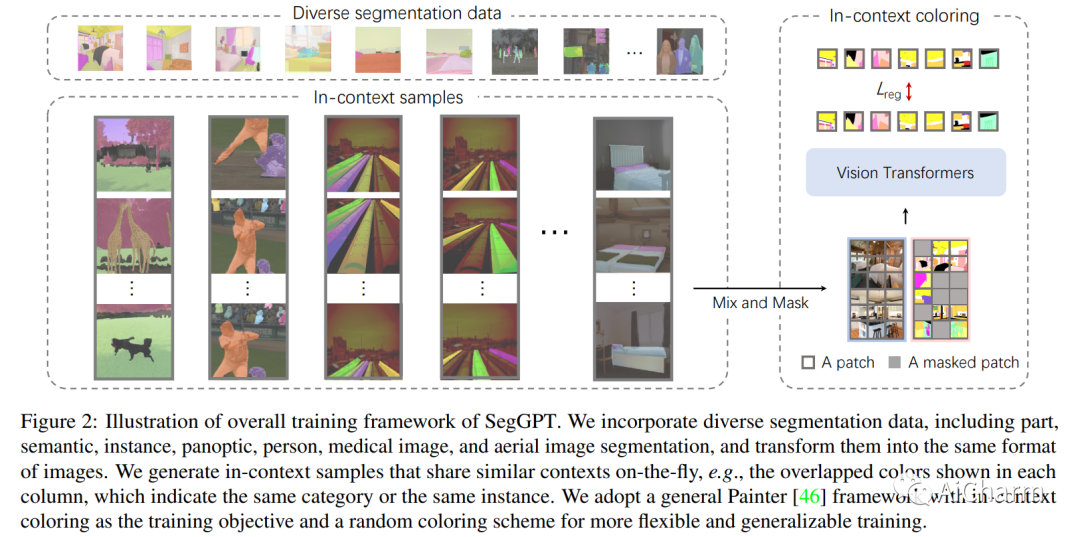
In-Context Coloring是SegGPT模型中的一种方法,用于训练模型以执行多种分割任务。传统的Painter框架中,每个任务的颜色空间都是预定义的,这导致解决方案崩溃成为多任务学习。例如,在语义分割中,一组颜色被预定义,并且每个语义类别被分配一个固定的颜色。同样,在实例分割中,实例对象的颜色根据其位置类别进行分配,即颜色数量等于空间位置数量,从而导致模型崩溃。为了解决这个问题,SegGPT使用In-Context Coloring方法来训练模型。该方法使用随机颜色映射来完成不同的任务,并强制模型参考上下文信息来完成指定任务,而不是依赖特定的颜色。
3.3 Context Ensemble
Context Ensemble是本文提出的一种上下文集成策略,旨在利用多个上下文信息来增强模型的表征能力。具体而言,Context Ensemble包括两个部分:空间集成和特征集成。空间集成通过将不同尺度的特征图进行融合来捕捉不同尺度的上下文信息。特征集成则通过将不同层次的特征进行融合来捕捉不同层次的上下文信息。这两种集成方法可以相互结合,以进一步提高模型性能。在实验中,本文使用了ADE20K数据集进行评估,并比较了使用Context Ensemble和不使用Context Ensemble两种方法的性能差异。实验结果表明,使用Context Ensemble可以显著提高模型性能,在各种分割任务上都取得了优秀的结果。因此,Context Ensemble是一种有效的上下文集成策略,可以帮助模型更好地利用上下文信息,并提高图像分割任务的性能。
3.3 In-Context Tuning
In-Context Tuning是SegGPT模型中的一种方法,用于调整模型以适应特定的任务或数据集。该方法使用可学习的提示来指示不同的任务,并且可以方便地作为专家模型,在不更新模型参数的情况下通过调整特定提示来适应特定用例。具体而言,该方法将任务提示定义为可学习张量,冻结整个模型,然后使用相同的训练损失来优化任务提示。本文在挑战性的ADE20K语义分割和COCO全景分割数据集上进行了In-Context Tuning实验,并证明了该方法对于提高SegGPT模型性能的重要性。

4.Experiment
在Experiment部分,本文介绍了对SegGPT模型的广泛评估。具体而言,本文使用了多个数据集进行实验,包括ADE20K、COCO-Stuff、PASCAL VOC 2012、Cityscapes等。实验结果表明,SegGPT在各种分割任务上都取得了优秀的性能,并且在少样本学习和视频对象分割等任务上表现出色。此外,本文还比较了SegGPT和其他先进方法的性能,并证明了SegGPT的优越性。
4.1 One-Shot Training Details
本文使用了一种名为Vision Transformer (ViT-L) encoder的编码器,并使用了一个预训练模型作为初始权重。然后,将多个数据集混合在一起进行训练,以使模型能够适应不同类型的数据。在测试时,只需要对模型进行微调即可适应特定任务。 本文还提到了一些具体的实现细节,如使用随机颜色映射来训练模型、使用多尺度输入图像来增强模型的鲁棒性等。实验结果表明,One-Shot Training Details方法可以有效地提高模型性能,在各种分割任务上都取得了优秀的结果。因此,One-Shot Training Details是一种有效的训练方法,可以帮助模型更好地适应不同类型的数据,并提高图像分割任务的性能。
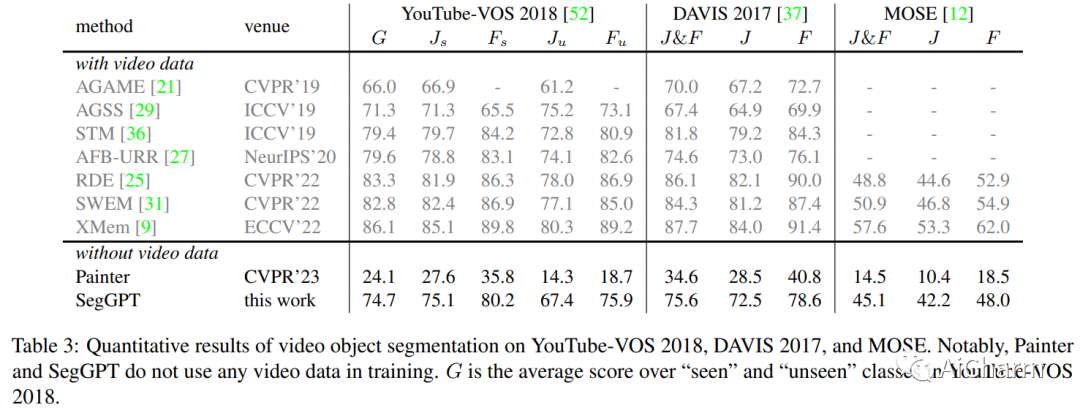
4.1 Qualitative Results
本文使用了一些特定的任务提示来对选定的图像进行分割,并将结果可视化展示出来。这些任务提示包括任意部分/对象分割、文本分割、视频对象分割等。此外,本文还使用了YouTube-VOS 2018数据集进行视频对象分割实验,并将结果可视化展示出来。通过这些可视化结果,可以看出SegGPT模型在各种分割任务上都取得了优秀的性能,并且具有很高的灵活性和适应性。因此,Qualitative Results是一种有效的实验结果展示方式,可以帮助读者更好地理解SegGPT模型在图像分割任务中的表现。
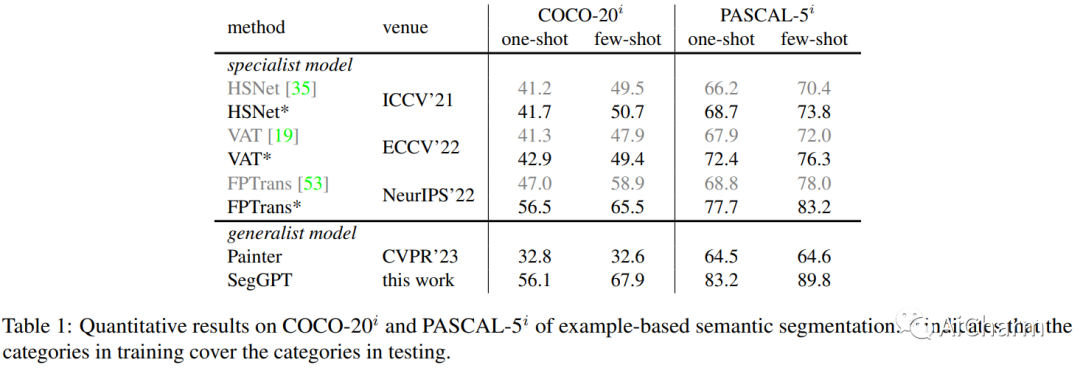
4.3 Comparison with Specialist Methods
本文使用了两个few-shot semantic segmentation数据集进行评估,并将SegGPT模型与一些专业方法进行了比较。实验结果表明,SegGPT模型在这两个数据集上都取得了优秀的性能,并且在某些任务上甚至超越了一些专业方法。为了更好地比较不同方法之间的性能差异,本文还使用了一些评价指标,如mIoU、F1-score等。实验结果表明,在大多数情况下,SegGPT模型都可以达到或超过其他专业方法的性能水平。此外,本文还对不同方法之间的计算复杂度进行了比较,并发现SegGPT模型具有更低的计算复杂度和更高的效率。
4.4 Ablation Study
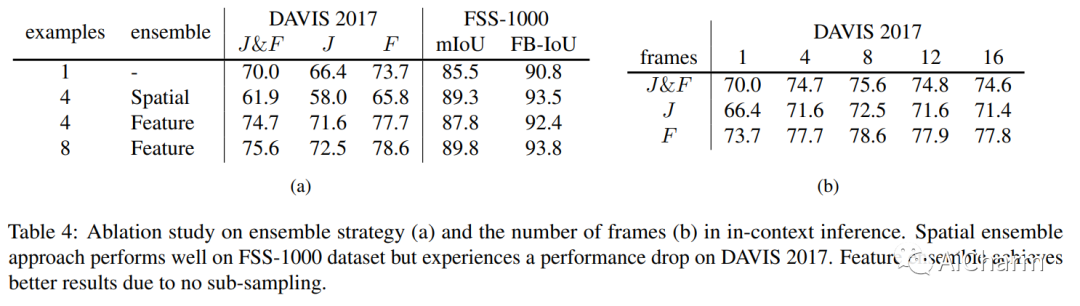
本文分别消融了空间集成和特征集成两种策略,并对实验结果进行了比较。实验结果表明,这两种上下文集成策略都对模型的性能有着重要的影响。在空间集成方面,本文发现将不同位置的特征进行平均池化可以有效地提高模型的性能。在特征集成方面,本文发现将不同层次的特征进行拼接可以有效地提高模型的性能。此外,本文还对不同消融组合进行了比较,并发现将这两种策略同时应用可以取得最好的效果。
5.Conclusion
在这项工作中,我们提出了一种通用的分割模型,展示了如何设计适当的训练策略,充分利用上下文视觉学习的灵活性。我们的模型表现出了处理领域内外分割任务的强大能力,包括对象实例、物体、部分、轮廓、文本分割等。然而,我们的工作也存在缺点。虽然我们的工作引入了一种新的随机着色机制,以提高上下文训练的泛化能力,但也使得训练任务本质上更加困难,这可能是在具有丰富训练数据的领域内任务中表现较差的原因,例如ADE20K上的语义分割和COCO上的全景分割。展望未来,我们认为我们的方法有潜力成为在图像/视频分割中实现更多样化应用的强大工具,通过利用任务定义中的灵活性进行上下文推断。扩大模型规模是我们计划追求的一条途径,以进一步提高性能。更大的模型可以捕捉到数据中更复杂的模式,这可能会导致更好的分割结果。但这也带来了寻找更多数据的挑战。一个潜在的解决方案是探索自监督学习技术。我们希望我们的研究能够激发社区继续探索上下文学习在计算机视觉中的潜力。我们仍然乐观地认为,视觉领域最好的GPT-3时刻还在未来。