申明:本次只是说一下实现思路,官方的接口以及如何实现方式,本文没有提及,这次只是一个思路,若想代替人工完成质量还差的很远,请审核大大放行

今天再次优化了代码,修复了一些bug,考虑到不完善且文章质量不是很高的情况(连个图文都没有),打算将代码分离开来,一起使用可能会对后面维护开发产生不必要的麻烦,欢迎大佬的关注,我会自动回关!,等到真正实现自动化,会打包成exe分享
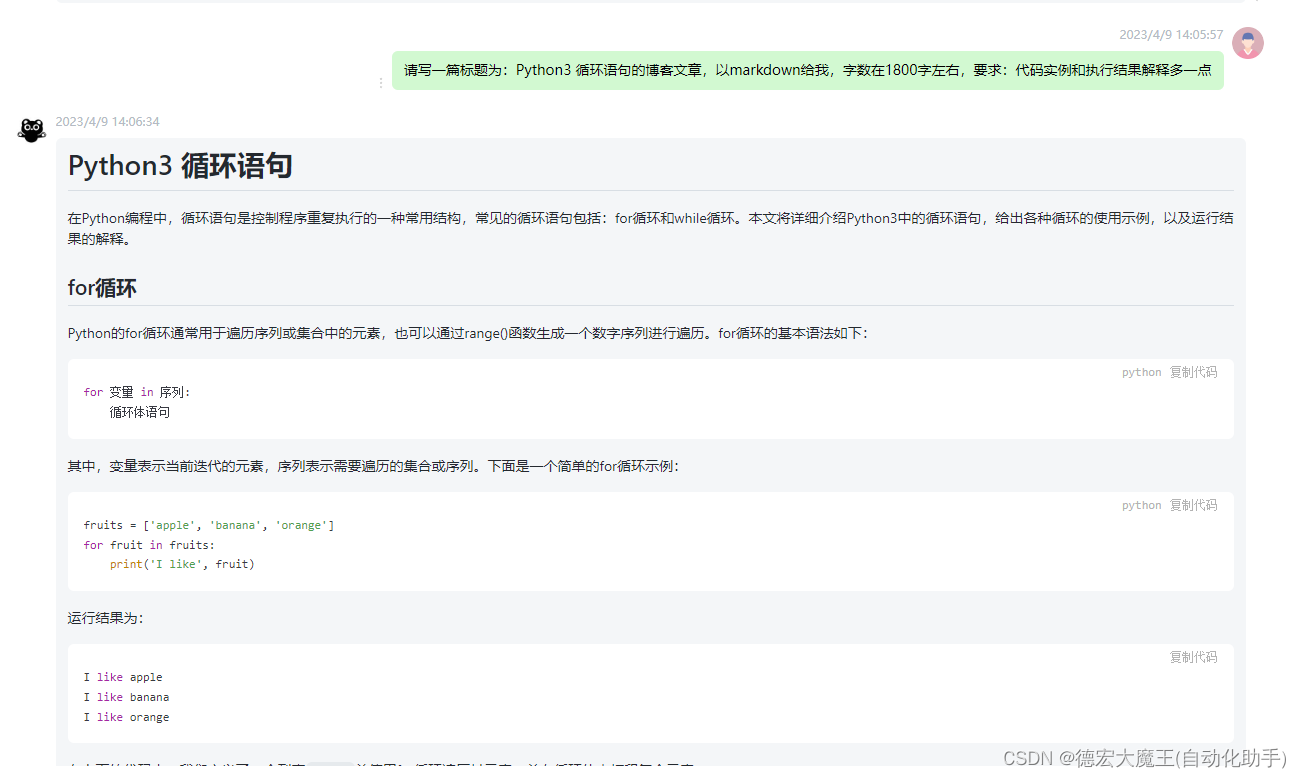
实现效果看我的博客:Python3 循环语句

缺点:
gpt3.5没有图文并茂"复制代码"转换过程中处理成了文字未知原因requests返回的数据和真实的数据有出入 已完成的工作
20230405
支持点赞、收藏回访(被动模式) 关注回访(需要发表过博客) 评论回访20230406优化
私信检测到群发消息自动三连/满足模板设定给予三连触发 优化检测模式,防止出现多触发情况 为了防止操作额度不够,只处理最新发表的博客(第一条),不在继续往下操作 暂未对动态blink进行调整,理论可以 评论多评检测(防止有人故意而为之)20230408
接入chatgpt,可对话、可自动评论实现流程
第三方chatgpt3.5api接口

这里接口有需要的伙伴,私聊领取哈,免费的
构造标题、关键字等
构造完成整理为发送gpt的模块中
title="Python3 循环语句" yaoqiu="要求:代码实例和执行结果解释多一点" text_val = "请写一篇标题为:"+title+"的博客文章,以markdown给我,字数在1800字左右"+yaoqiu content=chatgpt(title)分析C的markdown接口请求参数
文章保存参数:
| 参数名 | 值 | 说明 |
|---|---|---|
| title | Python3 循环语句 | 标题 |
| description | 摘要 | 摘要可为空 |
| content | 内容 | 需要使用markdown转换,不转换就是一行 |
| tags | 文章标签 | 例如:机器学习 |
| categories | 空 | 暂不清楚,猜测分类 |
| type | original | 暂不清楚 |
| status | 2 | 暂不清楚 |
| read_type | public | 是否公开 |
| reason | 暂不清楚 | |
| cover_images | imgurl | 头图支持多个 |
| is_new | 1 | 新文 |
| 等等… |
知道请求参数,关键在于标题、内容、标签、图片,于是接下来着手获取
内容
输入标题,完成构造对话发送等待返回文章,通过markdown处理请求
def convert_markdown_to_html(markdown_text): html = markdown.markdown(markdown_text) return html处理后获得title标题、content内容
获取标签、头图
C站标签和头图属于一个接口,通过请求
result=get_recommend_tags(title,content_mark)获取到标签和头图,这里由于比较忙我就不整理参数了
以下为接口返回数据(请求标题与numpy相关):
{"code": 200,"message": "success","traceId": "xxxxxx","data": {"common": ["bug", "php", "开发语言", "thinkphp5", "微信小程序"],"list": {"推荐": ["numpy", "python", "机器学习", "开发语言", "人工智能"],"Python": ["python", "django", "pygame", "virtualenv", "tornado", "flask", "scikit-learn", "plotly", "dash", "fastapi", "pyqt", "scrapy", "beautifulsoup", "numpy", "scipy", "pandas", "matplotlib", "httpx", "web3.py", "pytest", "pillow", "gunicorn", "pip", "conda", "ipython"],"images": ["https://xxxxxx/img_convert/7bc0b398d41f4dbc81d31b9dedc4e172.png", "https://xxxxxx/img_convert/77fcfea2a41749d7867f62f0e98b01ca.png", "https://xxxxxx/img_convert/fad536e972e14ce4b37803185dc3b00c.png", "https://xxxxxx/img_convert/5bbc102f2243430991aedee1be20b4f3.png", "https://xxxxxx/img_convert/cf52fbe57e404f30babcdda6f1ef2c08.png"]}}标签是[‘推荐’]字段,使用python转换
tags = result['data']['list']['推荐']tag_str = ', '.join(str(tag) for tag in tags)print(tag_str)打印结果为:numpy, python, 机器学习, 开发语言, 人工智能
以上已经获取到了标签和头图以及markdown格式的内容,接下来结合起来像C站文章保存接口请求一次
saveArticle(tag_str,imgurl,title,content_mark)部分请求成功构造:
json_data = { # 'article_id': 130040595, 'title': title, 'description': '', 'content': content, 'tags': tag_str, 'categories': '', 'type': 'original', 'status': 2, 'read_type': 'public', 'reason': '', 'resource_url': '', 'original_link': '', 'authorized_status': False, 'check_original': False, 'source': 'pc_postedit', 'not_auto_saved': 1, 'creator_activity_id': '', 'cover_images': [ imgurl, ], 'cover_type': 1, 'vote_id': 0, 'scheduled_time': 0, 'is_new': 1,} response = requests.post( 'xxxxx', cookies=cookies, headers=headers, json=json_data,) print(response.text)请求成功,刷新我的文章查看
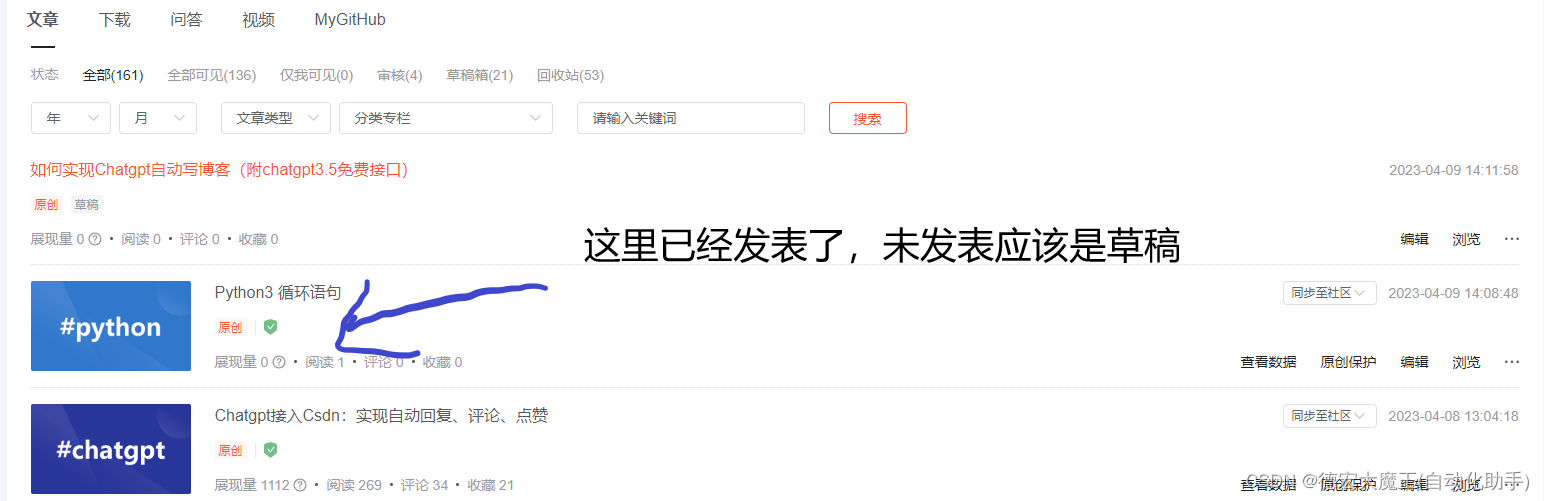
由于这里还在对文章内容排版优化,所以就不直接发表,需要核查一遍,等后面对接了文心一言考虑自动发表!