深度学习(猫狗二分类)
题目要求数据获取与预处理网络模型模型原理Resnet背景Resnet原理 代码实现模型构建训练过程批验证过程单一验证APP 运行结果训练结果批验证结果APP运行结果Tensorboard可视化 模型对比可视化结果分析 附录resnet网络架构resnet34网络架构
题目要求
题目: 猫狗二分类。要求: 利用Pytorch深度学习框架实现对猫狗图片进行分类。说明:1.学会读取训练集中的图片
2.自行搭建模型,利用训练集进行训练并在验证集上进行测试
3.尝试不同模型,比较实验结果
数据获取与预处理
训练集中有12500张猫的图片和12500张狗的图片,共计25000张;
测试集由人工分拣,在所给测试集中人工选择1000张猫的图片和1000张狗的图片,共计2000张,分别放入各类文件夹中;
在划分训练集与测试集时,可以使用如下代码快速实现:
# 划分训练集和测试集 n_val = int(len(dataset) * val_percent) n_train = len(dataset) - n_val dataset_train, dataset_val = Data.dataset.random_split(dataset, [n_train, n_val]) # 训练数据集与测试数据集长度 train_data_length = len(dataset_train) test_data_length = len(dataset_val) print(f"using {train_data_length} images for training, {test_data_length} images for validation.")数据集文件夹结构如图所示: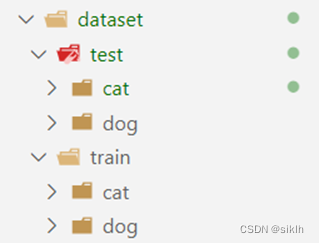
文件夹如此构造是因为可以使用torchvision.datasets.ImageFolder()方法很容易的导入数据集。
通过对图片粗略地预览,我们可以发现,数据集中的图片格式参差不齐,有大有小,如果直接放入网络会报错,因此,在图片放入网络前需要使用torchvision.transforms.Resize()方法将所有图片改造成大小相同;
图片的像素一般都是0-255,再加之是彩色图片,也就是三通道图片,如果直接输入到网络,将会使网络很难收敛,因此,需要使用torchvision.transforms.Normalize()方法将图片标准化。
至此,图片在输入到网络前的基本工作就结束了。
网络模型
在刚刚接触该题目时,尝试搭建简单的多层卷积网络,效果并不是很理想。因此,在多方权衡后,我尝试了Resnet网络,发现效果较好,因此,我学习并尝试手动搭建该网络进行该问题的解决,最终实现结果较好。
模型原理
Resnet背景
在深度学习中,随着网络的加深,能获取的信息越多,而且特征也越丰富。但是事实上随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了。这是由于网络的加深会造成梯度爆炸和梯度消失的问题。
针对这种现象已有的解决方法是对输入数据和中间层的数据进行归一化操作,这种方法可以保证网络在反向传播中采用随机梯度下降(SGD),从而让网络达到收敛。但是,这个方法仅对几十层的网络有用,当网络再加深时,这种方法就效果不是很好了。而Resnet网络的出现可以让更深的网络也可以得到更好的训练效果。
Resnet原理
在这个框架中,就我的理解,其中主要的创新点在于残差的引入和跳跃连接的思想。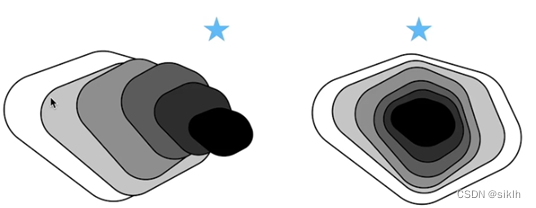
如上图,在不断加深网络的过程中,对于一般的卷积网络,他会像左边的图一样,在训练过程中,它的性能在提升(即覆盖面积更大),但是复杂模型往往可能会学偏,产生模型偏差,导致模型的效果反而更差了。
而Resnet网络简单来说就是可以使每次新的更复杂的模型都会包含上一个模型,这样就可以保证模型不会更差,简单来说,就像是“套娃”,距离最优解会越来越近。
它的具体实现比较简单,是引入了残差块的概念,实际上这个网络就是残差块的堆叠,就像是搭积木一样。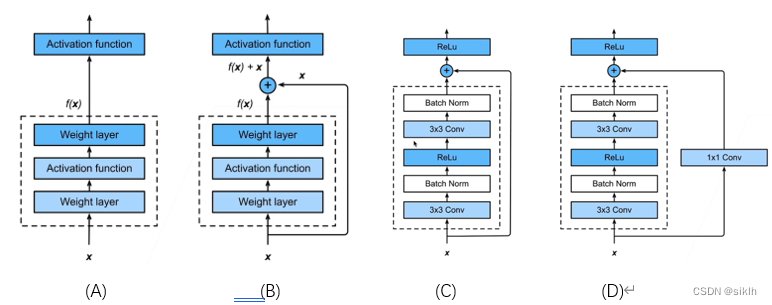
在串联模块的过程中,我们希望大模型可以在继承小模型的基础上再学到一些新的东西。所以在这里采用的方法就是在原有的基础上加上一个快速通道(如上图B所示),得到一种类似f(x)=x+g(x)的结构。
事实上,在实现过程中,往往要在快速通道上添加一个1x1的卷积层(如上图D所示),其目的是为了保证维度的相同,便于模型的可加。
残差块的实现往往是不同的,写法是多种多样的,但其中的核心思想是不变的。
其实Resnet的网络架构类似于VGG和GoogleNet,只是替换了残差块而已。
代码实现
在了解了Resnet的基本原理和构造后,下面就是代码的实现,详细的实现过程请参照代码中的注释。
模型构建
使用import导入必要的包。
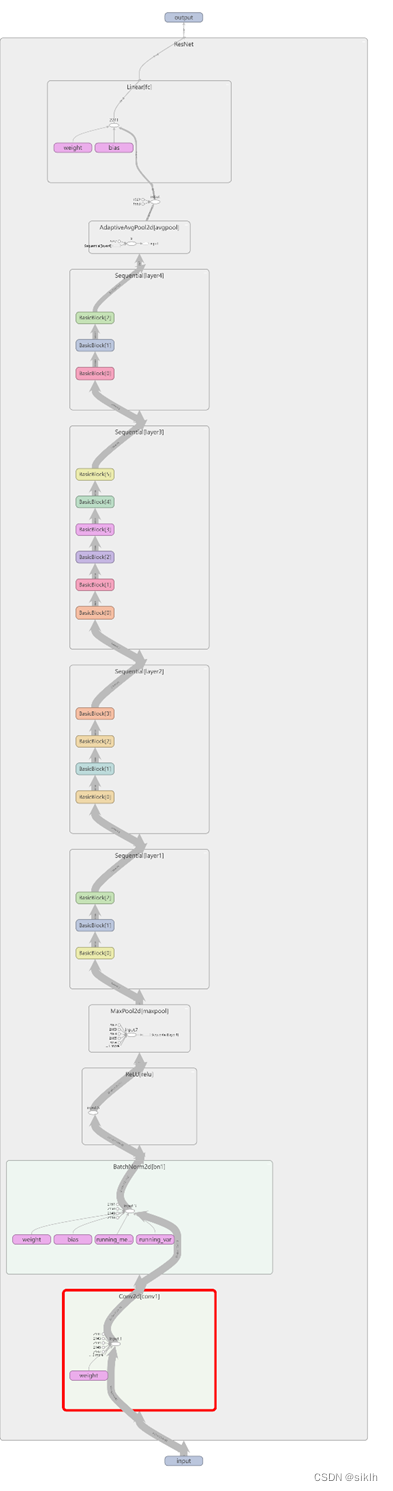
import torch.nn as nnimport torchclass BasicBlock(nn.Module): expansion = 1 def __init__(self, in_channel, out_channel, stride=1, downsample=None, **kwargs): super(BasicBlock, self).__init__() self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel, kernel_size=3, stride=stride, padding=1, bias=False) # 加速收敛,防止梯度消失和梯度爆炸 self.bn1 = nn.BatchNorm2d(out_channel) self.relu = nn.ReLU() self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel, kernel_size=3, stride=1, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(out_channel) self.downsample = downsample def forward(self, x): identity = x #这是为了保证原始输入与卷积后的输出层叠加时维度相同 if self.downsample is not None: identity = self.downsample(x) out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out += identity out = self.relu(out) return outclass ResNet(nn.Module): def __init__(self, block, blocks_num, num_classes=1000, include_top=True, groups=1, width_per_group=64): super(ResNet, self).__init__() self.include_top = include_top self.in_channel = 64 self.groups = groups self.width_per_group = width_per_group self.conv1 = nn.Conv2d(3, self.in_channel, kernel_size=7, stride=2, padding=3, bias=False) self.bn1 = nn.BatchNorm2d(self.in_channel) self.relu = nn.ReLU(inplace=True) self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.layer1 = self._make_layer(block, 64, blocks_num[0]) self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2) self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2) self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2) if self.include_top: self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # output size = (1, 1) self.fc = nn.Linear(512 * block.expansion, num_classes) for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') def _make_layer(self, block, channel, block_num, stride=1): downsample = None if stride != 1 or self.in_channel != channel * block.expansion: downsample = nn.Sequential( nn.Conv2d(self.in_channel, channel * block.expansion, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(channel * block.expansion)) layers = [] layers.append(block(self.in_channel, channel, downsample=downsample, stride=stride, groups=self.groups, width_per_group=self.width_per_group)) self.in_channel = channel * block.expansion for _ in range(1, block_num): layers.append(block(self.in_channel, channel, groups=self.groups, width_per_group=self.width_per_group)) return nn.Sequential(*layers) def forward(self, x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) if self.include_top: x = self.avgpool(x) x = torch.flatten(x, 1) x = self.fc(x) return x# resnet18网络def resnet18(num_classes=1000, include_top=True): return ResNet(BasicBlock, [2,2,2,2], num_classes=num_classes, include_top=include_top)# resnet34网络def resnet34(num_classes=1000, include_top=True): return ResNet(BasicBlock, [3, 4, 6, 3], num_classes=num_classes, include_top=include_top)在代码中,残差块见BasicBlock类,它实现了如下图所示的结构。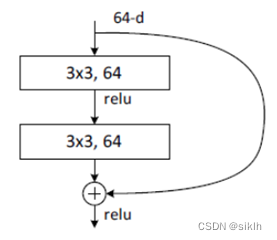
最后的ResNet类可以根据列表大小来构建不同深度的resnet网络架构。resnet一共有5个阶段,第一阶段是一个7x7的卷积,stride=2,然后再经过池化层,得到的特征图大小变为原图的1/4。_make_layer()函数用来产生4个layer,可以根据输入的layers列表来创建网络。
卷积层之后总会添加BatchNorm2d进行数据的归一化处理,这使得数据在进行Relu之前不会因为数据过大而导致网络性能的不稳定
该代码实现的模型框架为:
ResNet( (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU(inplace=True) (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False) (layer1): Sequential( (0): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU() (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) (1): BasicBlock( (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU() (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer2): Sequential( (0): BasicBlock( (conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU() (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU() (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer3): Sequential( (0): BasicBlock( (conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU() (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU() (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (layer4): Sequential( (0): BasicBlock( (conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU() (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (downsample): Sequential( (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False) (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (1): BasicBlock( (conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (relu): ReLU() (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) ) ) (avgpool): AdaptiveAvgPool2d(output_size=(1, 1)) (fc): Linear(in_features=512, out_features=2, bias=True))训练过程
# 导入必要的模块import sysimport torchvisionfrom tqdm import tqdmimport torchvision.transforms as transimport torch.utils.data as Dataimport torchvision.datasets as dsetsimport torch.optim as optimfrom torch.utils.tensorboard import SummaryWriterfrom resnet import *from datetime import datetime# 定于时间戳,便于分别保存训练过程在tensorboard中TIMESTAMP = "{0:%Y-%m-%dT%H-%M-%S/}".format(datetime.now())# 定义输入图片预处理的操作transform = trans.Compose( [trans.Resize((224, 224)), trans.ToTensor(), trans.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])# 读取训练数据与验证数据train_dataset = dsets.ImageFolder('dataset/testset', transform=transform) # 做transformtest_dataset = dsets.ImageFolder('dataset/test', transform=transform) # 做transform# 打印训练数据集与测试数据集长度train_data_length = len(train_dataset)test_data_length = len(test_dataset)print(f"using {train_data_length} images for training, {test_data_length} images for validation.")# 导入数据# Data.DataLoader()函数中shuffle用于打乱数据集,drop_last用于舍弃最后剩余的图片,防止报错batch_size = 32 # 设置每次进行训练的图片数量train_loader = Data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, drop_last=True)val_loader = Data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True, drop_last=True)# 查看GPU是否可用,如果可以就使用GPU进行训练并打印出训练设备device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("using {} device.".format(device))# 导入网络模型net = resnet34() # 使用resnet34网络进行训练# net = resnet18() # 使用resnet18网络进行训练# 改变网络最后的输出的维数,由于只有cat与dog两类,故重构为2in_channel = net.fc.in_featuresnet.fc = nn.Linear(in_channel, 2)net.to(device) # 将网络迁移到GPU进行计算# 定义损失函数,使用CrossEntropyLoss,即交叉熵损失函数loss_function = nn.CrossEntropyLoss()# 构造一个优化器params = [p for p in net.parameters() if p.requires_grad] # 将网络中所有需要更新梯度的参数放入paramsoptimizer = optim.Adam(params, lr=0.0001) # 构建优化器,传入两个参数,前者为要优化的参数,后者为学习率epochs = 10 # 训练批次best_acc = 0.0 # 用于存放准确率save_path = './finidhresNet34kk.pth' # 模型保存路径train_steps = len(train_loader) # 训练步长train_log_dir = 'logs/resnet34/train/' + TIMESTAMP # tensorboard记录保存训练信息路径test_log_dir = 'logs/resnet34/test/' + TIMESTAMP # tensorboard记录保存测试信息路径writer_train = SummaryWriter(log_dir=train_log_dir) # 构造tensorboard的SummaryWriter初始化(训练)writer_test = SummaryWriter(log_dir=test_log_dir) # 构造tensorboard的SummaryWriter初始化(测试)# 开始训练与测试的迭代for epoch in range(epochs): # 训练部分 net.train() running_loss = 0.0 # 用于记录训练损失函数 train_bar = tqdm(train_loader, file=sys.stdout) # 用这个包来显示训练进度 for step, data in enumerate(train_bar): images, labels = data optimizer.zero_grad() # 把梯度置零,也就是把loss关于weight的导数变成0 logits = net(images.to(device)) # 将图片张量送入网络前向传播,images.to(device) 是让其在GPU上计算 loss = loss_function(logits, labels.to(device)) # 计算损失 loss.backward() # 反向传播,根据loss计算梯度 optimizer.step() # 更新梯度 # 打印统计 running_loss += loss.item() train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1, epochs, loss) # 将图片写入tensorboard grid = torchvision.utils.make_grid(images) writer_train.add_image('images', grid) # 将训练网络写入tensorboard writer_train.add_graph(net, images.to(device)) # 将训练指标数据写入tensorboard writer_train.add_scalar("train_loss", loss.item(), step) # 测试部分 net.eval() acc = 0.0 # 累计正确率 / 批次 with torch.no_grad(): # with 下的所有代码都不更新梯度 val_bar = tqdm(val_loader, file=sys.stdout) for val_data in val_bar: val_images, val_labels = val_data outputs = net(val_images.to(device)) # loss = loss_function(outputs, test_labels) predict_y = torch.max(outputs, dim=1)[1] acc += torch.eq(predict_y, val_labels.to(device)).sum().item() val_bar.desc = "valid epoch[{}/{}]".format(epoch + 1, epochs) val_accurate = acc / test_data_length print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' % (epoch + 1, running_loss / train_steps, val_accurate)) # 将测试误差写入tensorboard writer_test.add_scalar("test_loss", running_loss / train_steps, epoch + 1) # 将测试正确率写入tensorboard writer_test.add_scalar("test_accuary", val_accurate, epoch + 1) # 当当前训练模型的准确率高于之前时,就将模型保存 if val_accurate > best_acc: best_acc = val_accurate torch.save(net.state_dict(), save_path)print('Finished Training')批验证过程
import sysimport torchvisionfrom tqdm import tqdmimport torchvision.transforms as transimport torch.utils.data as Dataimport torchvision.datasets as dsetsimport torch.optim as optimfrom resnet import *# 定义输入图片预处理的操作transform = trans.Compose( [trans.Resize((224, 224)), trans.ToTensor(), trans.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])# 读取数据test_dataset = dsets.ImageFolder('dataset/test', transform=transform) # 做transform# 测试数据集长度test_data_length = len(test_dataset)print(f" {test_data_length} images for test.")# 导入数据batch_size = 32test_loader = Data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True, drop_last=True)device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("using {} device.".format(device))net = resnet18()# 改变网络最后的输出的维数,由于只有cat与dog两类,故重构为2in_channel = net.fc.in_featuresnet.fc = nn.Linear(in_channel, 2)net.to(device)# 定义损失函数,使用CrossEntropyLoss,即交叉熵损失函数loss_function = nn.CrossEntropyLoss()# 构造一个优化器params = [p for p in net.parameters() if p.requires_grad]optimizer = optim.Adam(params, lr=0.0001)net.load_state_dict(torch.load('module/finidhresNet18kk.pth'))net.eval()acc = 0.0 with torch.no_grad(): val_bar = tqdm(test_loader, file=sys.stdout) for val_data in val_bar: val_images, val_labels = val_data outputs = net(val_images.to(device)) predict_y = torch.max(outputs, dim=1)[1] acc += torch.eq(predict_y, val_labels.to(device)).sum().item()val_accurate = acc / test_data_lengthprint(' val_accuracy: %.3f' %( val_accurate))print('Finished Testing')单一验证APP
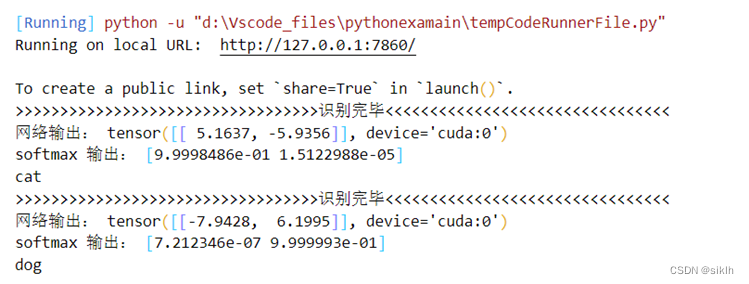
import gradio as grimport torchimport torch.nn as nnimport torchvision.transforms as transfrom PIL import Imagefrom resnet import *# 定义事件函数def dogvscat(image): # 定义标签 labels = ['cat', 'dog'] # 定义图片预处理方法 transform = trans.Compose([trans.Resize((224, 224)), # 把给定的图片resize到given size trans.ToTensor(), trans.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 用均值和标准差归一化张量图像,把0-1变换到(-1,1). ]) # 将输入图片转化为narry的格式,便于送入网络 image = Image.fromarray(image) # 将图片进行预处理 image = transform(image) # 扩充图片维度:3D==》4D(本质上在最前面加上一个图片个数的维度) image = image.unsqueeze(0) # 调用网络 model = resnet18(num_classes=2) # model = resnet34(num_classes=2) # 将模型与图片放入GPU device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model.to(device) image = image.to(device) # 调用已经修炼好的网络参数 model.load_state_dict(torch.load('module/finidhresNet18kk.pth')) # model.load_state_dict(torch.load('module/finidhresNet34kk.pth')) # 利用模型进行识别 model.eval() with torch.no_grad(): output = model(image) m = nn.Softmax(dim=1) outputsoft = m(output) outputsoft = outputsoft.cpu().numpy()[0] print('>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>识别完毕<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<') print("网络输出:", output) print('softmax 输出:', outputsoft) if output[0][0] > 0: print('cat') if output[0][1] > 0: print('dog') return {labels[i]: float(outputsoft[i]) for i in range(2)}# 规定APP的输出outputs = gr.outputs.Label(num_top_classes=2)# 对APP布局进行必要的设计interface = gr.Interface(fn=dogvscat, inputs="image", outputs=outputs, examples=['flagged/11.jpg', 'flagged/57.jpg'], title='猫狗识别')# 加载激活interface.launch()运行结果
训练结果
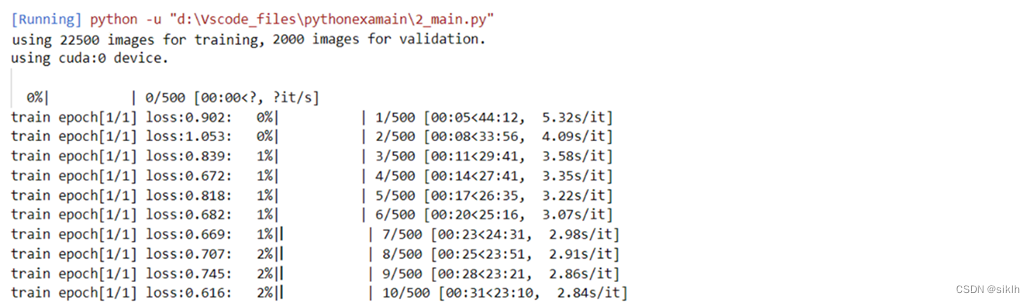
···
(用时太长,略)
批验证结果

···
该模型在测试集上可以获得98.7%的准确率,相当不错。
APP运行结果
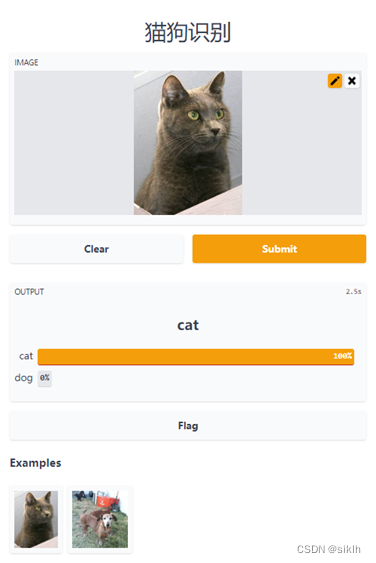
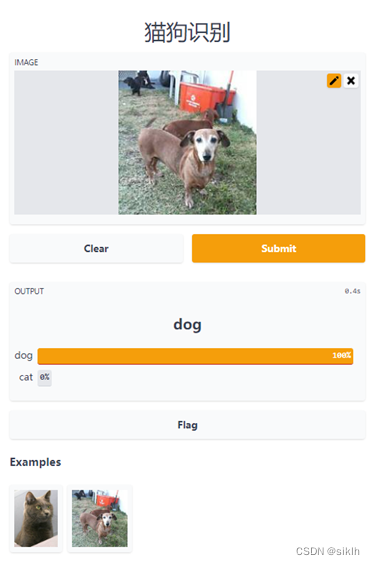
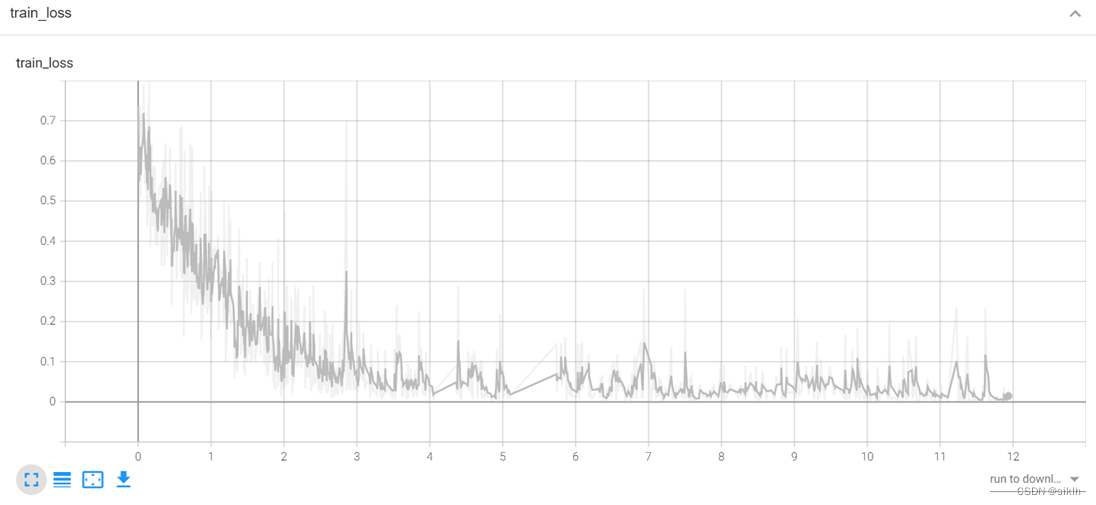
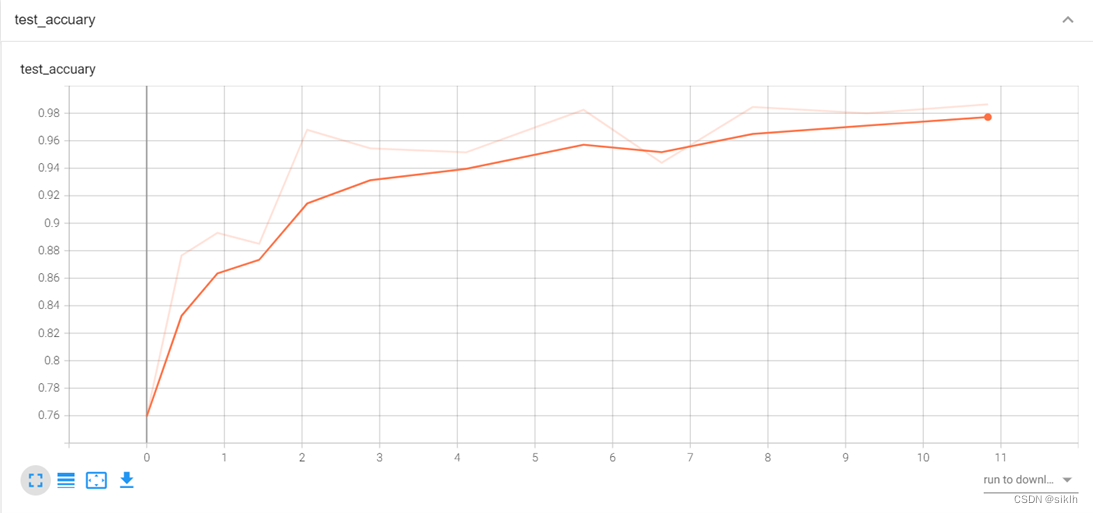
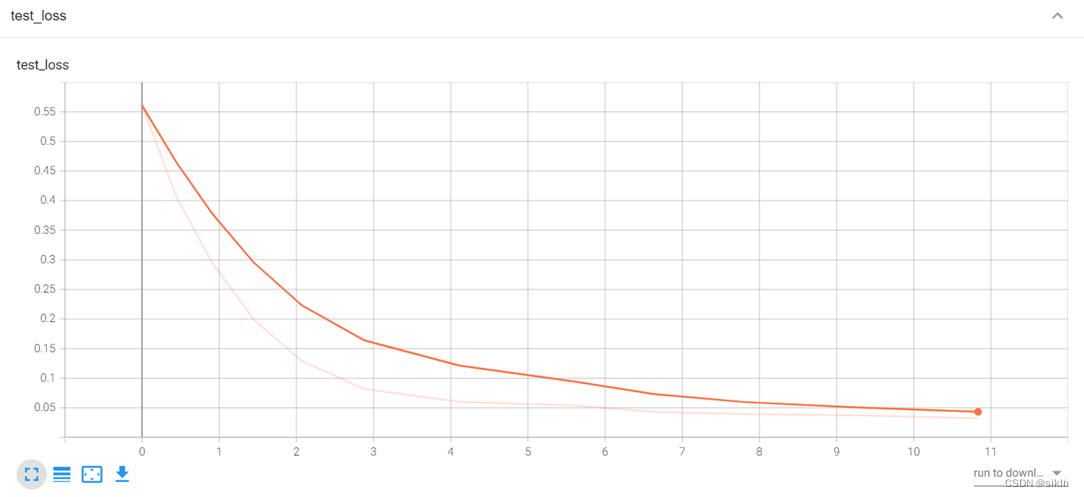
Tensorboard可视化


模型对比
我也使用了resnet34来进行训练,期望得到对照来进行深入探究。
可视化结果
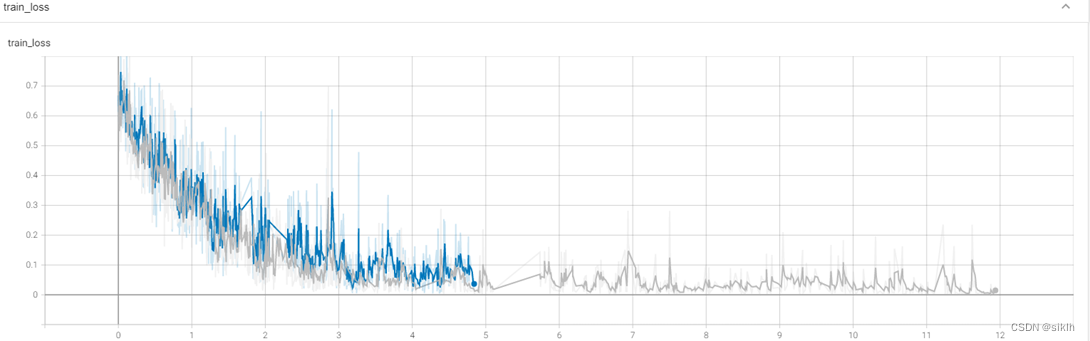

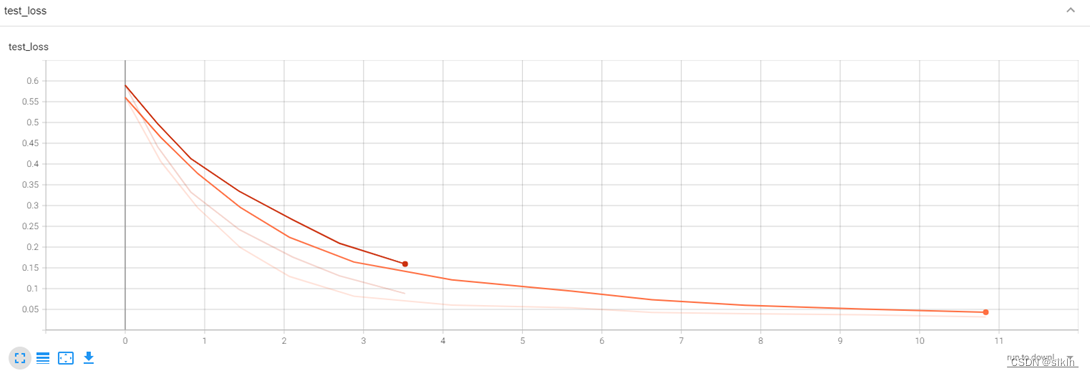

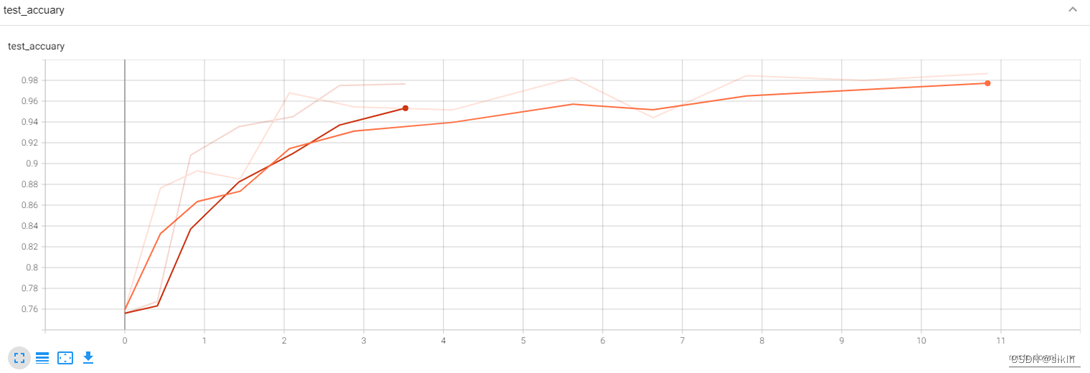

分析
由于电脑硬件的缘故,在复杂网络下训练时,内存与cpu占用极高,造成长时间的卡顿,因此,resnet34下并没有能够训练足够多的epoch,但是事实上,我们可以就现在的结果中获取不少信息。
resnet34相较于我的模型,在前几个批次的训练中,可以更快地获取较高准确率,但是损失函数下降的更慢,因此,我们可以大胆预测,如果继续训练下去,resnet34一定可以更快达到我的模型的水平,并且有极大的可能性在测试集上获得更好地准确率。
事实上,这与现有资料中显示的信息相符,即更深的resnet网络效果更好。
附录
resnet网络架构
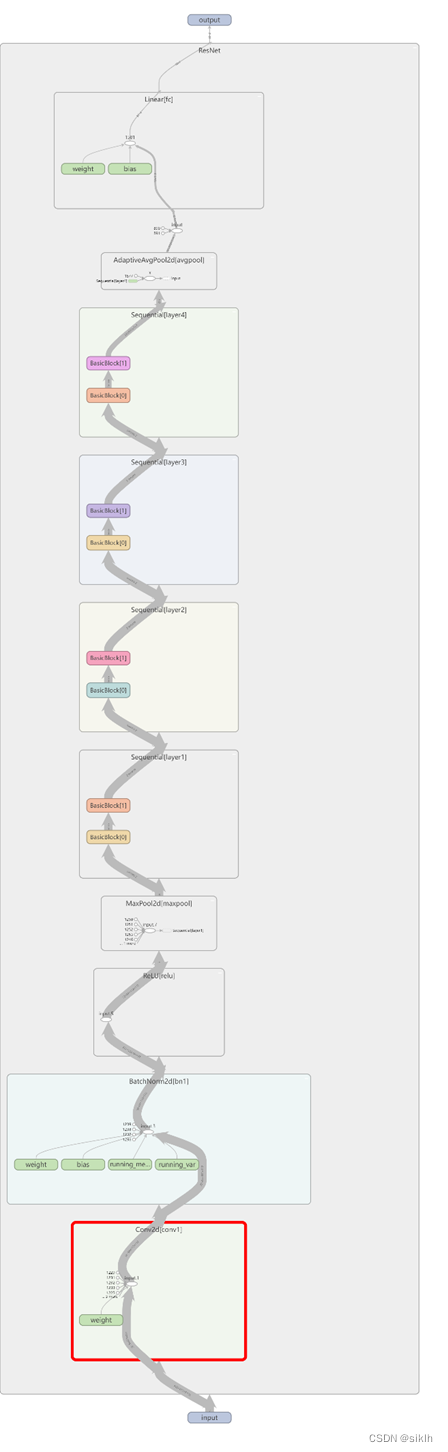
resnet34网络架构