本文借鉴了数学建模清风老师的课件与思路,可以点击查看链接查看清风老师视频讲解:清风数学建模:https://www.bilibili.com/video/BV1DW411s7wi
一、前言

二、回归分析简介



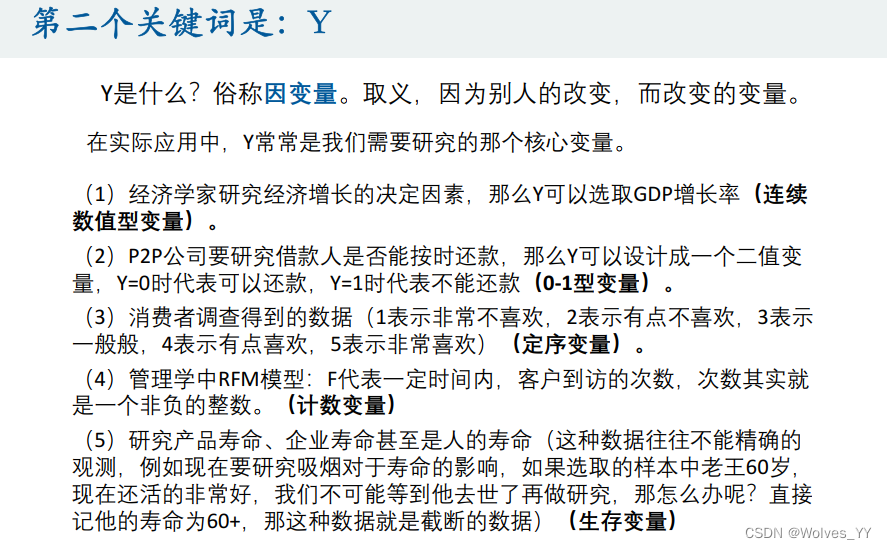
 该问题可通过后文提到的标准化回归解决。
该问题可通过后文提到的标准化回归解决。

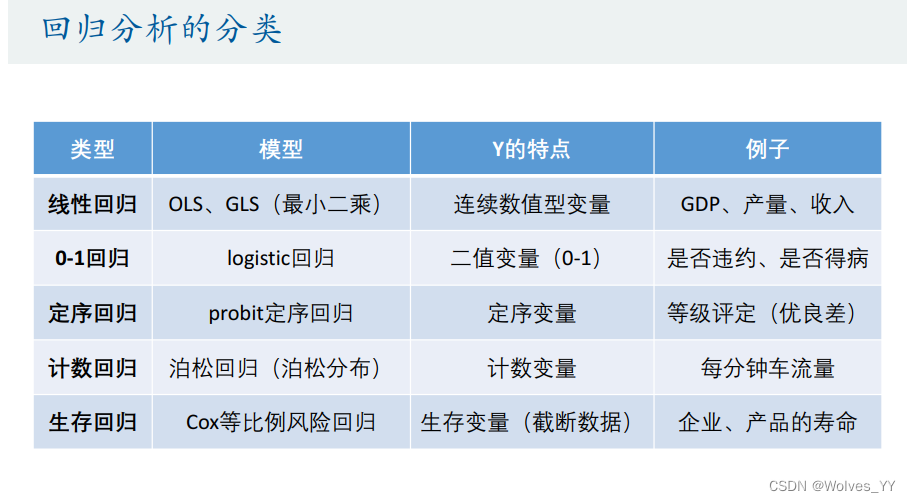
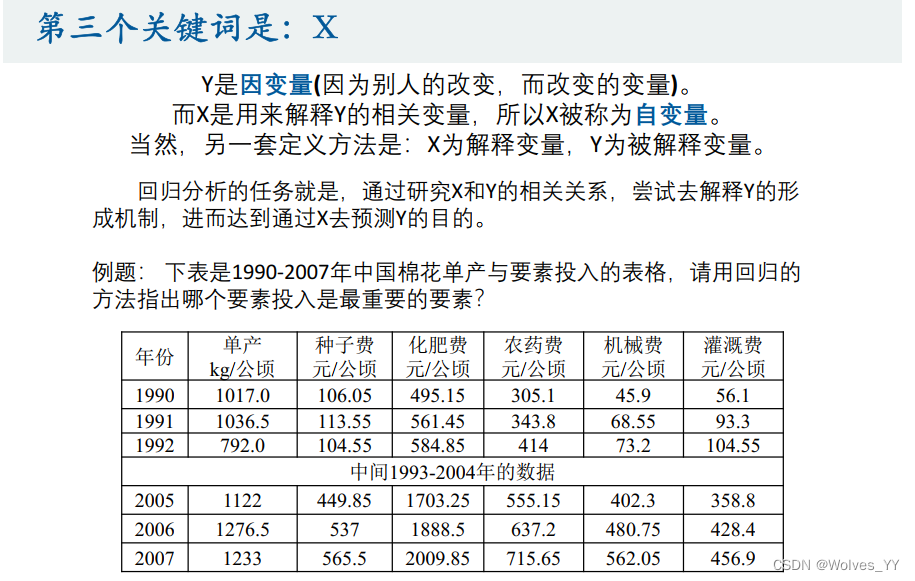
三、数据的简介
3.1 数据的分类



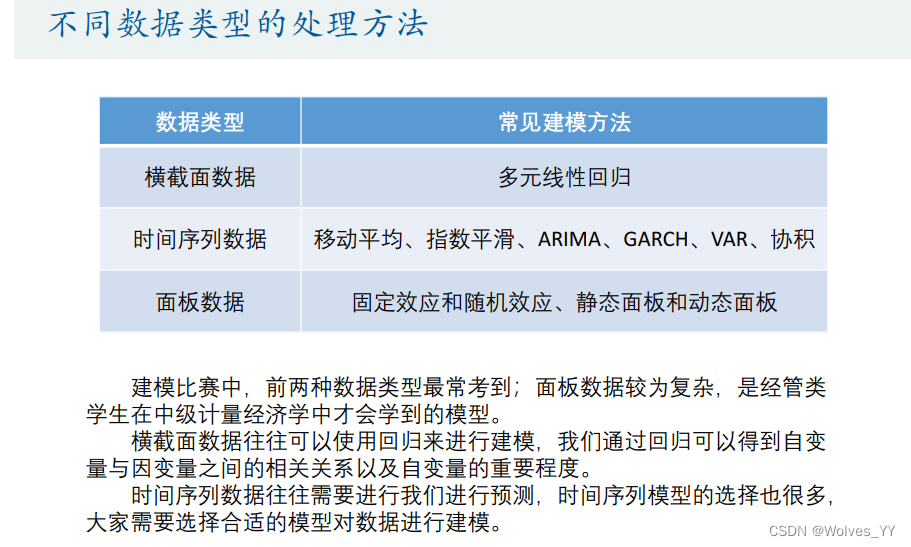
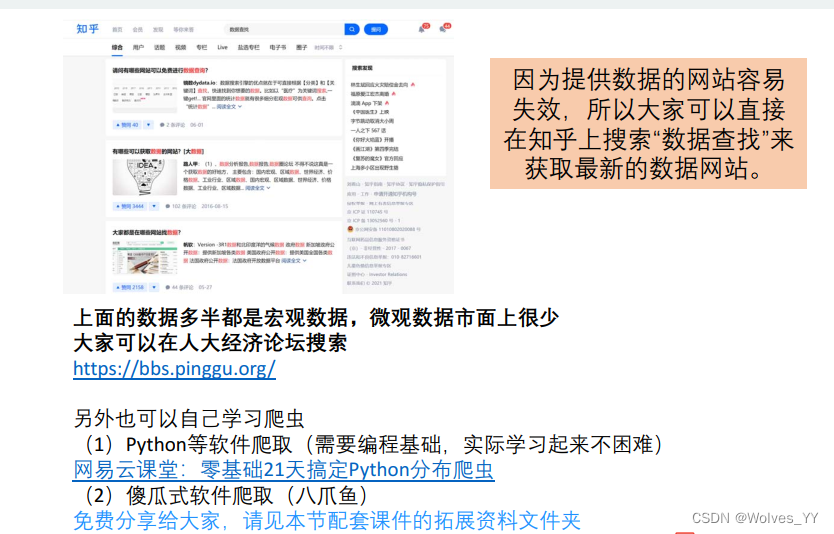
3.2 数据的收集
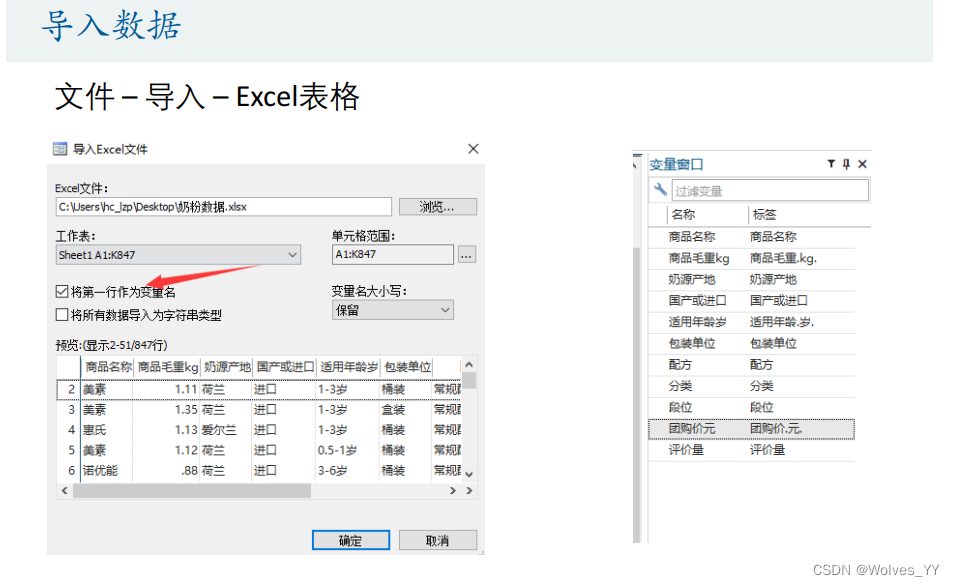
四、对数据的处理


详见《Excel对数据进行预处理》文件。
五、内生性的探究(实际操作时不是很重要)


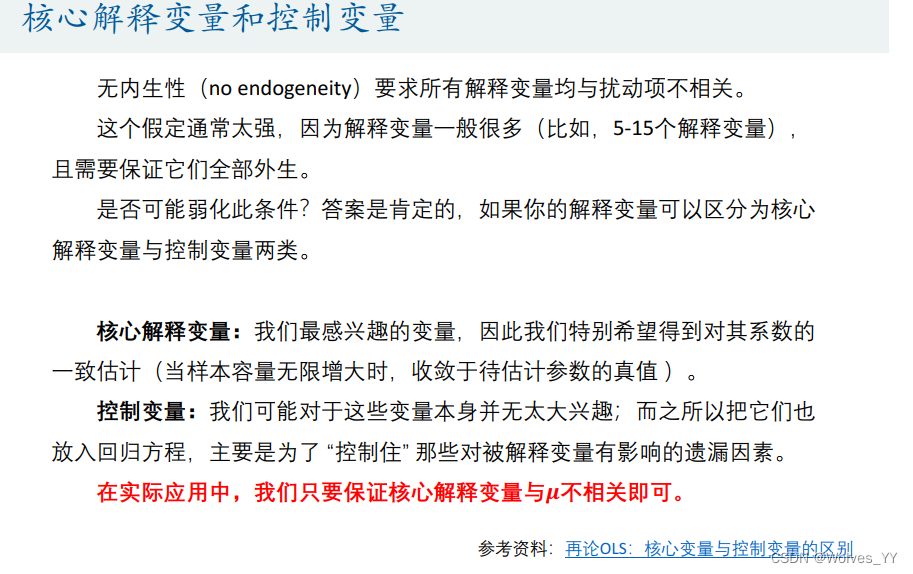
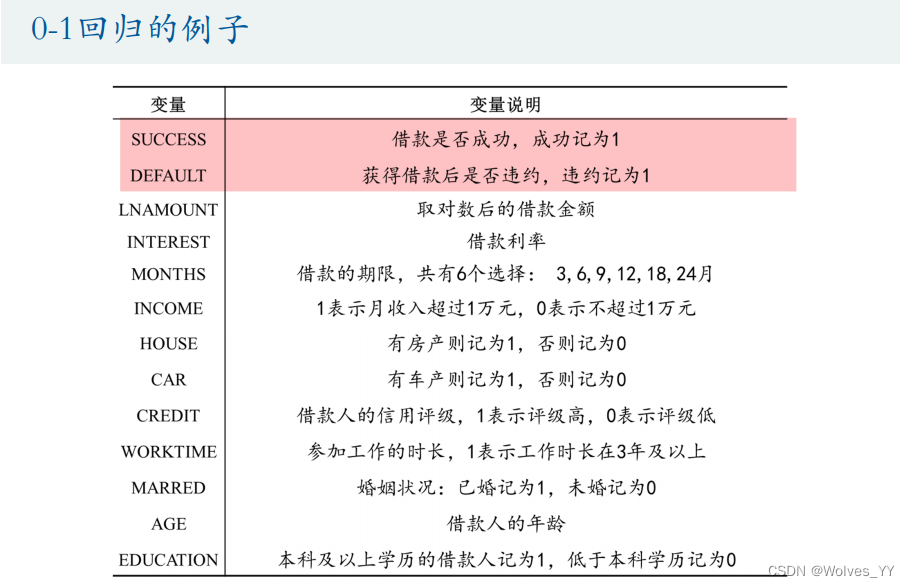
六、分类变量的设置

在Stata里操作时,会自动设置对照组,从而避免多重共线性的影响。

七、案例背景
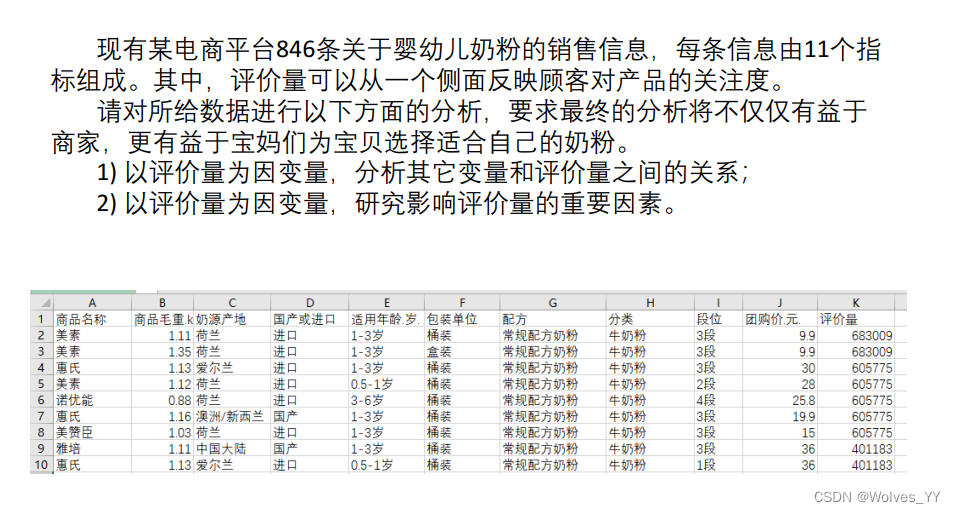
八、Stata实现多元线性回归
8.1 Stata基础
 8.2 Stata里进行描述性统计分析
8.2 Stata里进行描述性统计分析
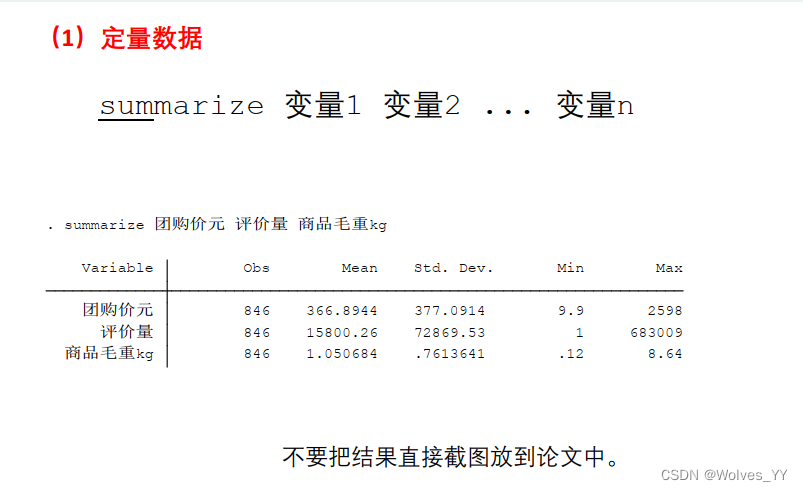
这里的数据为连续性数据,得到的结果在Excel里优化一下再放入论文中。
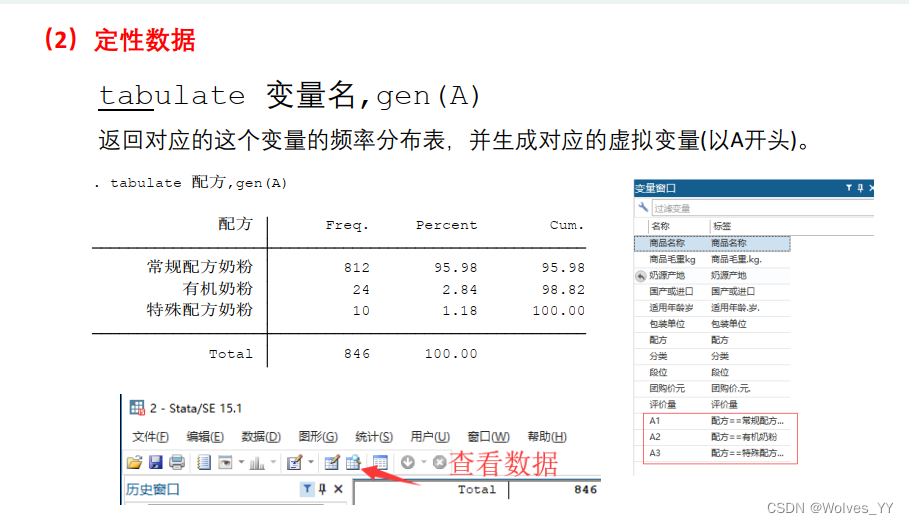
这里的数据为分类数据,tab命令可以得到分类数据的频数分布表,gen命令可以对该分类变量生成虚拟变量。
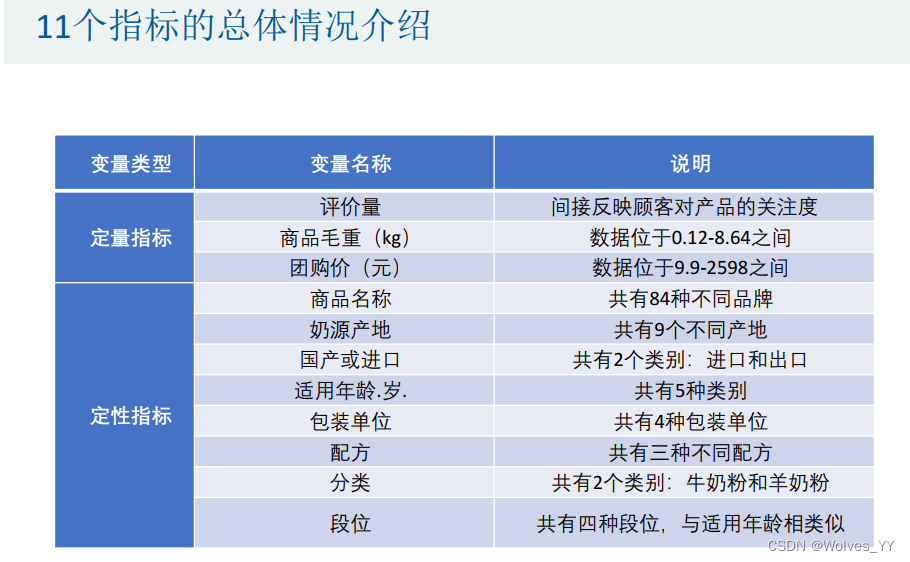
可将该指标总体情况放入论文中。
8.3 案例第1问求解
8.3.1 不加入分类变量时的回归
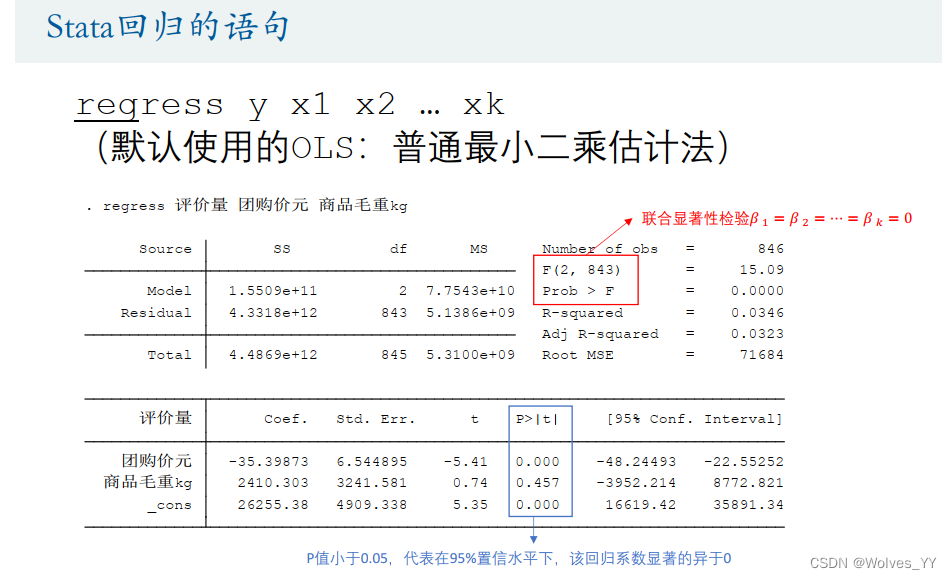
这里只用了两个自变量进行演示。
其中,第一个表里,联合显著性检验=0<0.05代表在95%的置信水平下(这里看你自己定为95%还是90%),拒绝原假设,模型通过了联合显著性检验,所以该线性模型才是有意义的。调整后的R^2为0.0346,这里因为是对其进行分析而不是预测,所以可不用关注R^2,在预测的时候再重点关注即可。
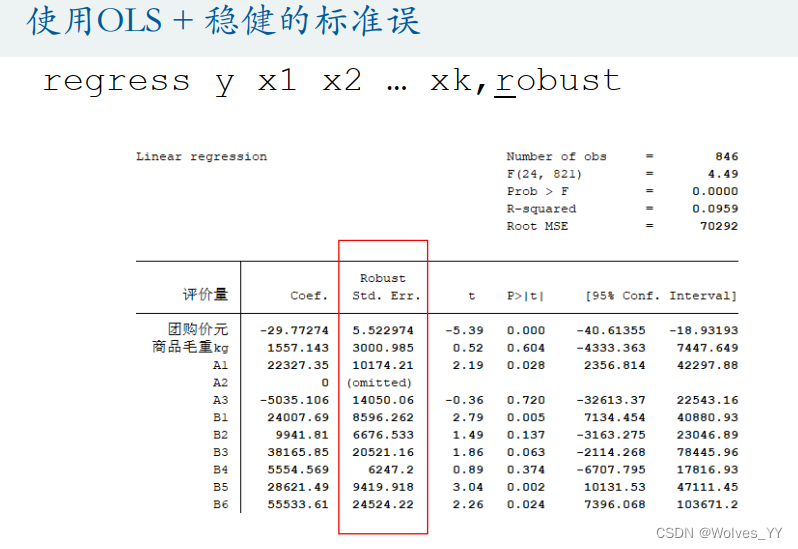
第二个表里,Coef一列为两个指标的回归系数。团购价的P值是在t检验下得到的,表示在95%的置信水平下,有一个自变量(团购价)是显著的,-35.39873代表在其他自变量不变的情况下,当团购价平均每增加1元,就会导致评价量平均减少35.39873,商品毛重该变量不显著,故不对其进行分析;_cons为常数项,也是显著的。
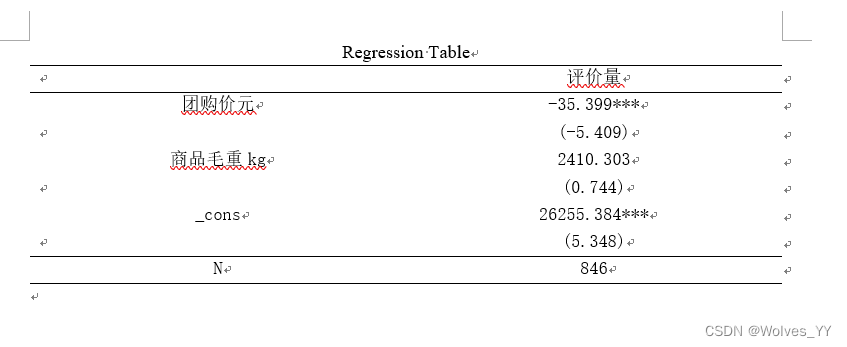
在回归之后,可以通过下面的命令将回归的结果保存到一个word里(详见stata里操作),其中,*** p<0.01 ** p<0.05 * p<0.1分别为在99%,95%,90%的置信水平下显著。
regress 评价量 团购价元 商品毛重kg// 下面的语句可帮助我们把回归结果保存在Word文档中// 在使用之前需要运行下面这个代码来安装下这个功能包(运行一次之后就可以注释掉了)// ssc install reg2docx, all replace// 如果安装出现connection timed out的错误,可以尝试换成手机热点联网,如果手机热点也不能下载,就不用这个命令吧,可以自己做一个回归结果表,如果觉得麻烦就直接把回归结果截图。est store m1reg2docx m1 using m1.docx, replace// *** p<0.01 ** p<0.05 * p<0.1word里的结果如下:
8.3.2 加入分类变量时的回归
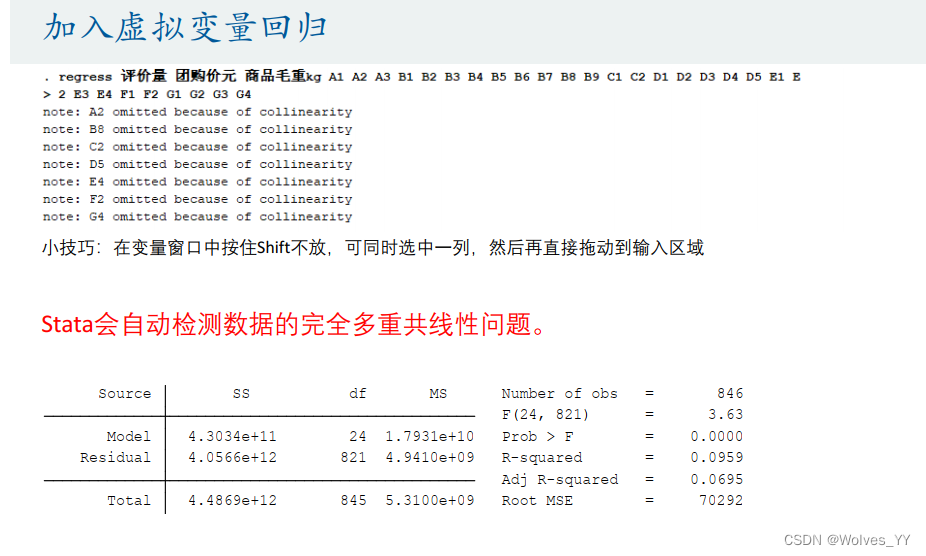
这里Stata自动对多重共线性问题进行解决,即在分类变量里随机设置 一组对照组。
完整图见Stata里操作。和上面的没加入分类变量时的操作步骤类似,分析是一样的,说明联合显著性检验、调整后的R^2、回归系数和P值即可。
最终的结果为:
第一个表里,联合显著性检验=0<0.05代表在95%的置信水平下(,拒绝原假设,模型通过了联合显著性检验,所以该线性模型是有意义的。
第二个表里,Coef一列为两个指标的回归系数(这里可以参考Excel作图这篇文章里的对回归系数显不显著作可视化处理放入论文中)。团购价的P值是在t检验下得到的,表示在95%的置信水平下,自变量团购价和F1(分类=牛奶粉)是显著的,-29.77274代表在其他自变量不变的情况下,当团购价平均每增加1元,就会导致评价量平均减少29.77274, 14894.55代表在其他自变量不变的情况下,分类为牛奶粉的评价量比羊奶粉(因为羊奶粉为对照组)的评价量平均高出29.77274。
8.3.3 关于调整后R^2值太小怎么办

在论文中放入调整后R^2时,可以将调整后R^2的介绍放进去。
8.4 案例第2问求解
所谓的标准化回归就是在对数据标准化后再使用回归。
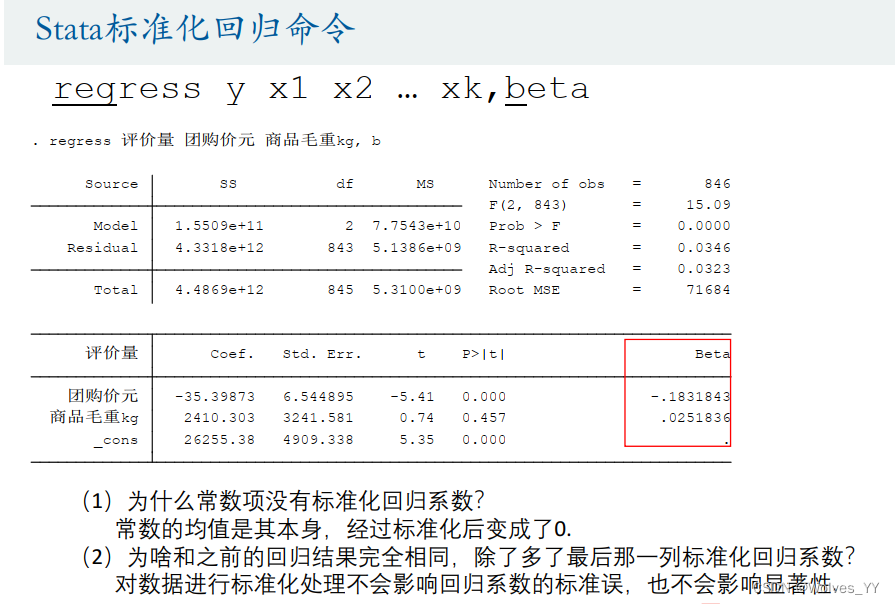
关于回归结果的可视化见 柱状图可视化回归结果
九、论文点评
9.1 一篇错误很多的论文《基于多元回归模型的大学生期末数学成绩影响因素探究》点评
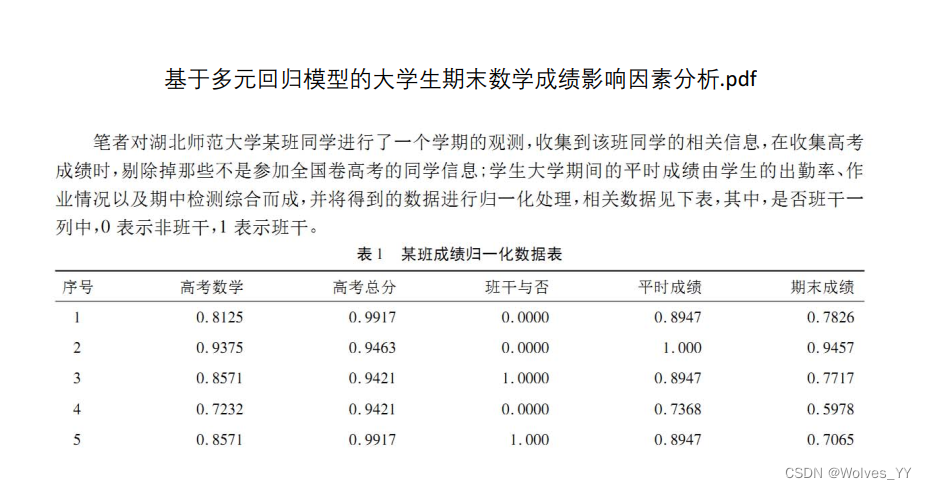
其中,期末成绩为y,其他四个变量为x。

这里并没有对回归系数说明各自为多少,R^2也不是相关系数,是拟合优度,显著性也没告诉。在数据归一化后,在对回归系数解释那里就不好说了。
也不用加入平方项,只是对数据进行分析,不用这么复杂,如果是预测的话还行,加入平方项之后也不好解释。
数据也不用进行归一化。
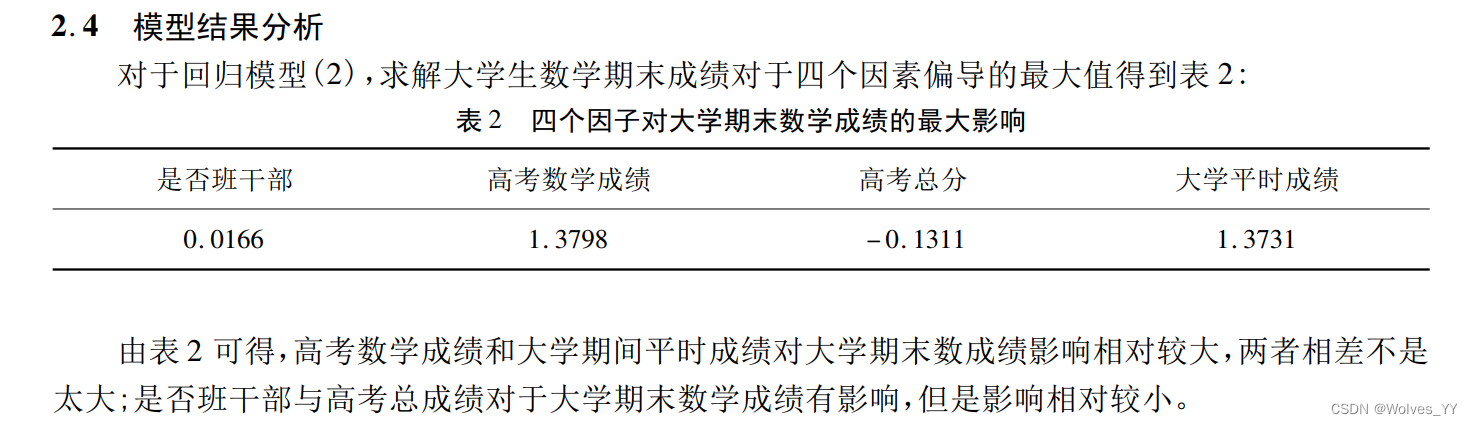
这里就和上面案例第二问一样,求哪个x对影响最大,这里可以直接用标准化回归系数。
9.2 清风的毕业论文点评

详见清风的论文和答辩PPT。一定要去看!!!
十、异方差(回归之前检验数据是否存在异方差)
10.1 异方差介绍

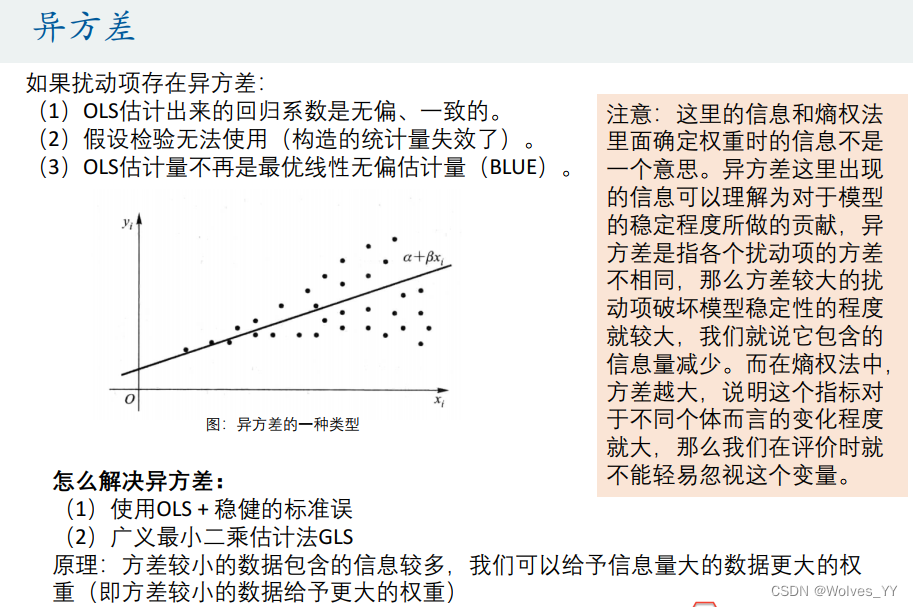
10.2 检验异方差
10.2.1 图形检验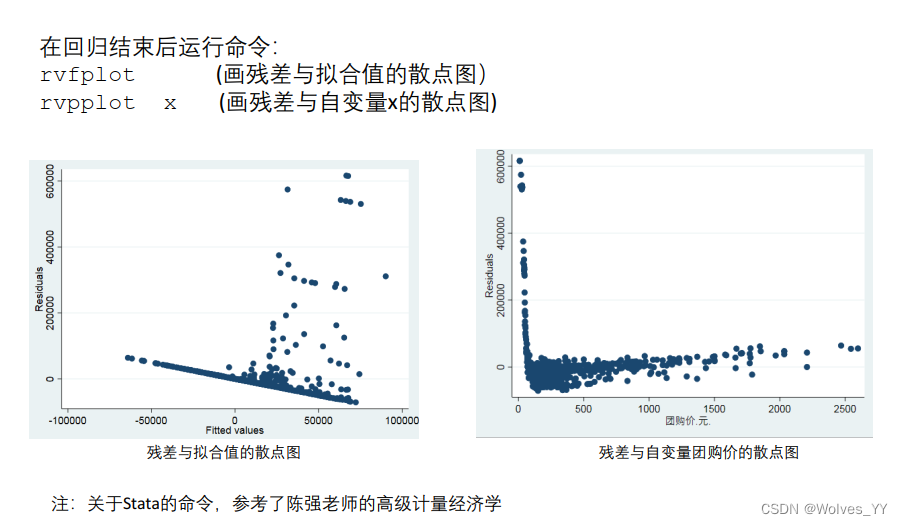
这里是通过绘制残差图来看,但并不严谨。图1为残差与拟合值的散点图,在拟合值较小时数据几乎没有波动,变大时波动就很明显,故数据存在异方差;图2为残差与自变量x(这里x可以随机给)的散点图,在团购价较小时,波动很大,而当团购价变大时,波动较小,故数据存在异方差。
stata保存图片的命令见 regress_stata

10.2.2 假设检验
(1)BP检验

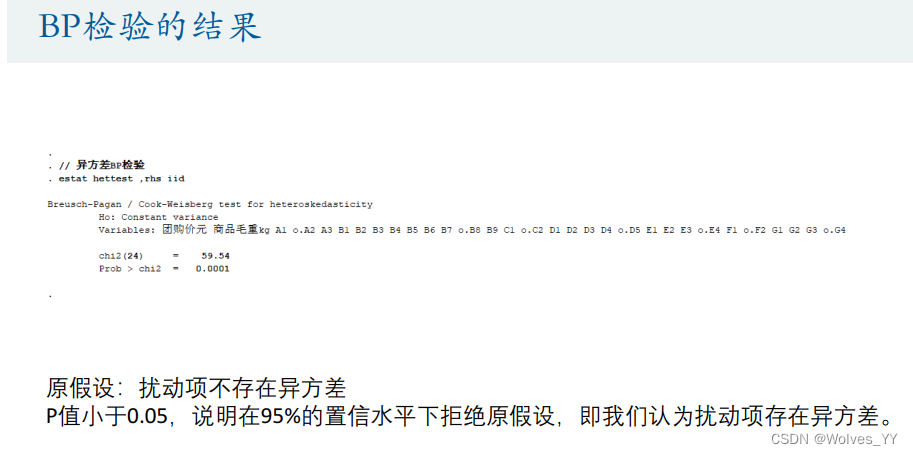
(2)怀特检验(推荐使用这个检验)
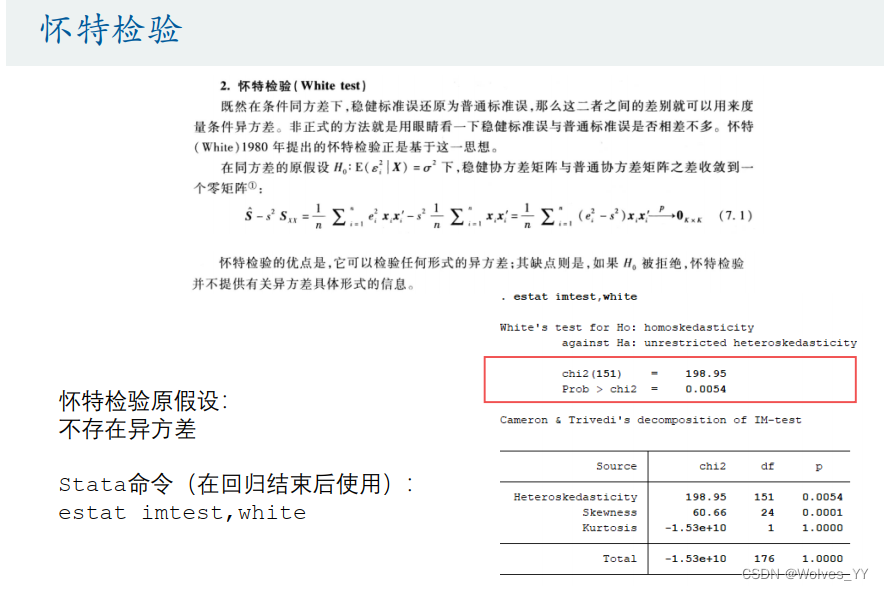
10.3 异方差的处理方法

可以将蓝色字体写入论文中,然后使用第一种方法。
十一、多重共线性(回归结束后用)
11.1 多重共线性介绍
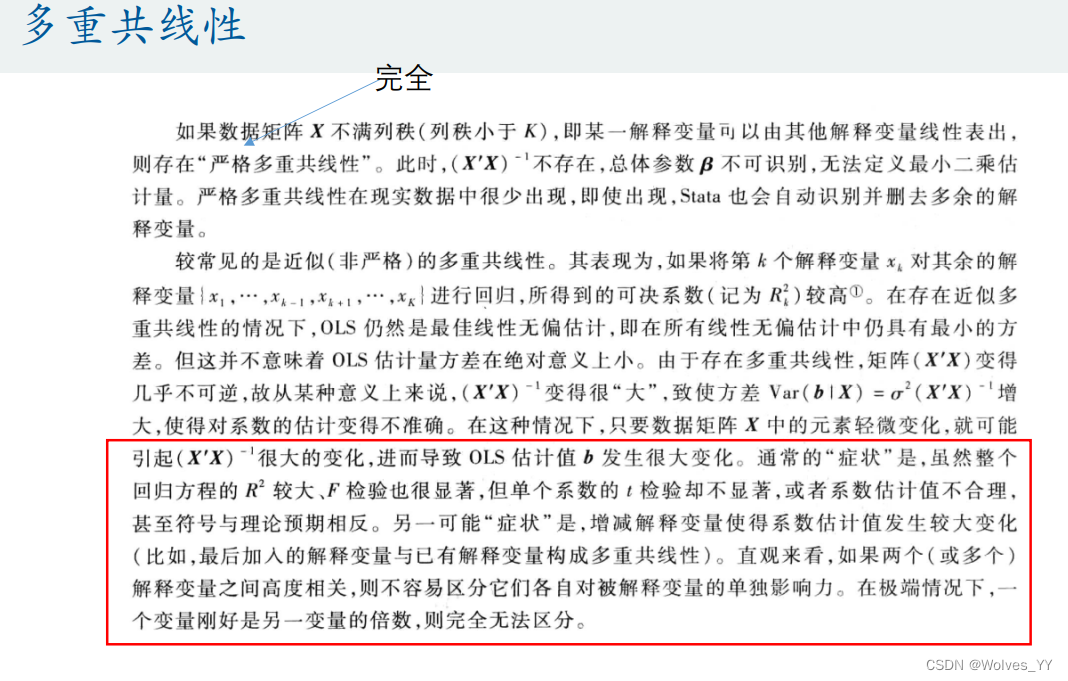
前文提到的完全多重共线性Stata会自动帮我们解决。红色框起来的为多重共线性带来的问题。
11.2 多重共线性检验
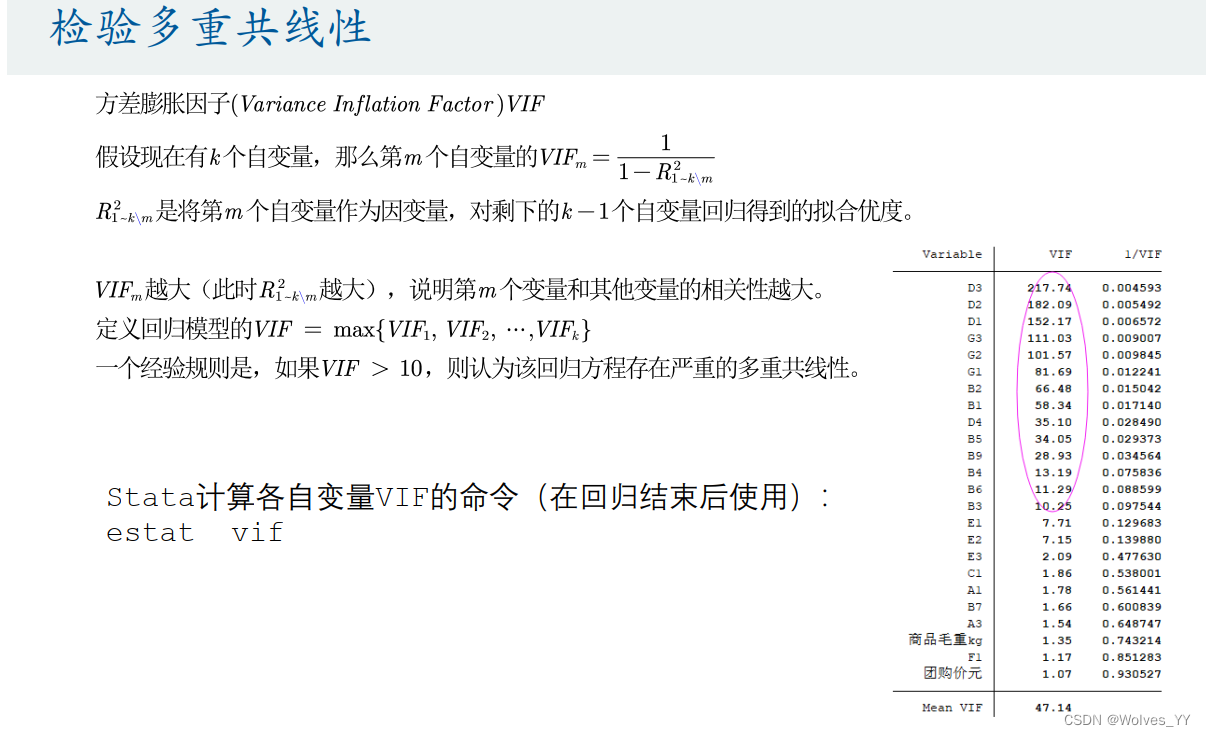 11.3 多重共线性的处理方法
11.3 多重共线性的处理方法

(1):如果回归是用来预测的话,可以不管多重共线性,只管R^2即可。
(2):如果只关心回归系数也不用管。
(3):关心变量即核心解释变量,可以尝试删除这些变量。
十二、逐步回归
12.1 逐步回归简介

使用向后逐步回归就行。
12.2 Stata实现逐步回归


因为逐步回归不能有完全多重共线性,所以运行该数据时报错了,解决方法为:前面运行的回归Stata检测出了哪些变量为完全多重共线性的,此时只需剔除这些变量再重新运行即可。
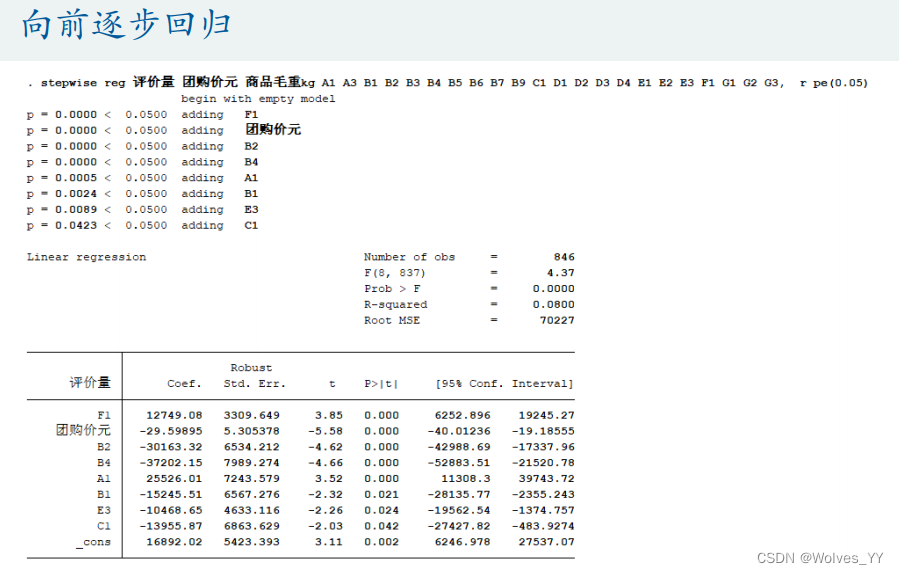
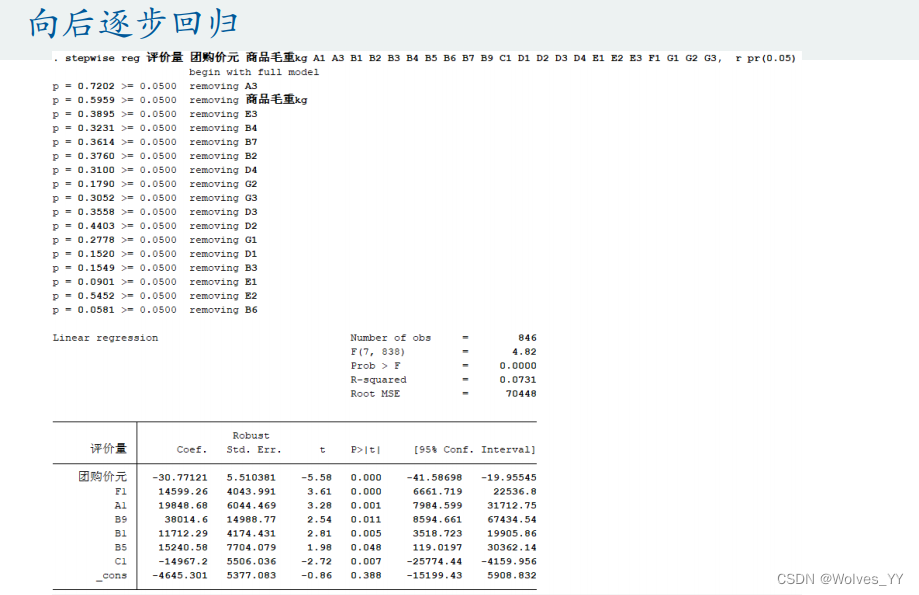
上面两图为Stata里向前、向后逐步回归的演示。
12.3 逐步回归说明

(2)可以忽略,使用的时候就用向后逐步回归就行,然后分析显著的变量。