文章目录
前言一、为什么要使用RF1.优点:2.缺点: 二、使用步骤1.引入库2.读入数据3.缺失值数据处理4.哑变量数据的处理5.特征变量6.建模7.验证集结果输出对比8.决策树9.模型特征重要性 总结
前言
建立多个决策树并将他们融合起来得到一个更加准确和稳定的模型,是bagging 思想和随机选择特征的结合。随机森林构造了多个决策树,当需要对某个样本进行预测时,统计森林中的每棵树对该样本的预测结果,然后通过投票法从这些预测结果中选出最后的结果。
随机主要体现在以下两个方面:
1. 随机取特征
2. 随机取样本,让森林中的每棵树既有相似性又有差异性
一、为什么要使用RF
1.优点:
准确率高运行起来高效(树之间可以并行训练)
不用降维也可以处理高维特征
给出了度量特征重要性的方法
建树过程中内部使用无偏估计
有很好的处理缺失值的算法
对于类别不平衡数据能够平衡误差
能够度量样本之间的相似性,并基于这种相似性对于样本进行聚类和筛选异常值
提出了一种衡量特征交互性的经验方法(数据中存在冗余特征时能很好的处理)
可以被扩展到无监督学习
易于检测模型准确性(如ROC曲线)
以上优点基于总结和个人看法
2.缺点:
黑盒,不可解释性强,多个随机导致了非常好的效果在某些噪声较大的分类和回归问题上会过拟合模型会非常大,越准确意味着越多的数所生成的决策树量较多,分析较为麻烦二、使用步骤
1.引入库
代码如下(示例):
import numpy as npimport pandas as pdfrom matplotlib import pyplot as pltfrom sklearn.decomposition import PCAfrom sklearn.ensemble import RandomForestRegressorfrom sklearn.model_selection import train_test_splitimport seaborn as snsfrom six import StringIOfrom IPython.display import Imagefrom sklearn.pipeline import Pipelinefrom sklearn.preprocessing import StandardScalerfrom sklearn.tree import export_graphvizimport pydotplusimport os2.读入数据
代码如下(示例):
data_train = pd.read_excel("data_train.xlsx")# data_train.describe().to_excel('data_train_describe.xlsx')# 数据描述性分析print(data_train.describe())# 数据完整性、数据类型查看print(data_train.info())运用统计学方法对数据进行整理和描述性分析
3.缺失值数据处理
# 数据缺失值个数total = data_train.isnull().sum().sort_values(ascending=False)# 缺失值数据比例percent = (data_train.isnull().sum() / data_train.isnull().count()).sort_values(ascending=False)print(total)print(percent)上一幅代码是对缺失值数据的统计,下一幅代码是对缺失值数据的填充。
# 缺失值填充data_train['x1'] = data_train['x1'].fillna(0)print(data_train.isnull().sum().max())4.哑变量数据的处理
# 哑变量处理data_train.loc[data_train['x10'] == '类别1', 'x10'] = 1data_train.loc[data_train['x10'] == '类别2', 'x10'] = 2a = pd.get_dummies(data_train['x10'], prefix="x10")frames = [data_train, a]data_train = pd.concat(frames, axis=1)data_train = data_train.drop(columns=['x10'])data_train.to_excel('data_train_yucl.xlsx')5.特征变量
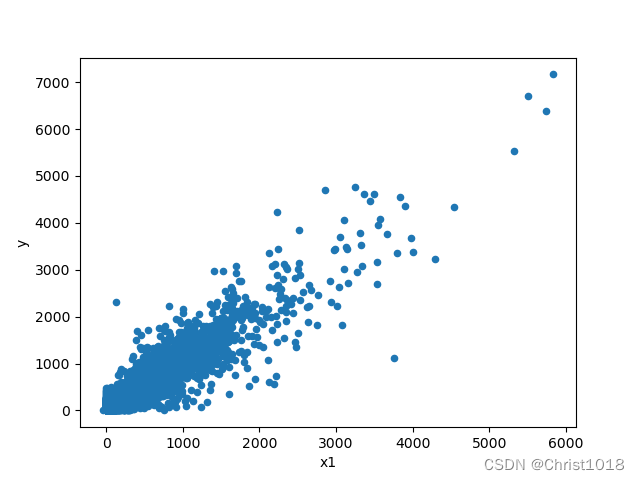
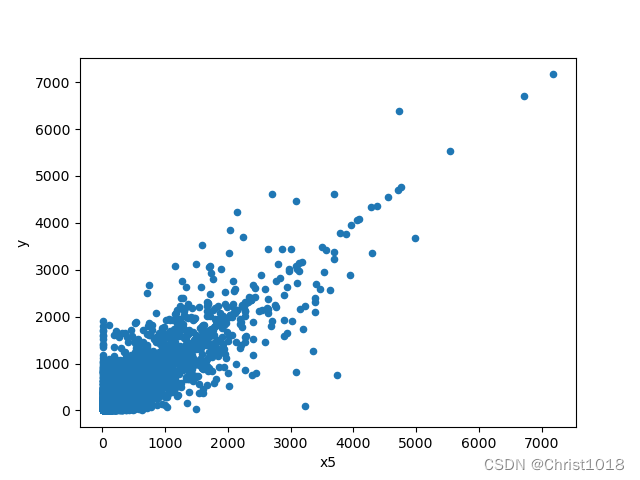
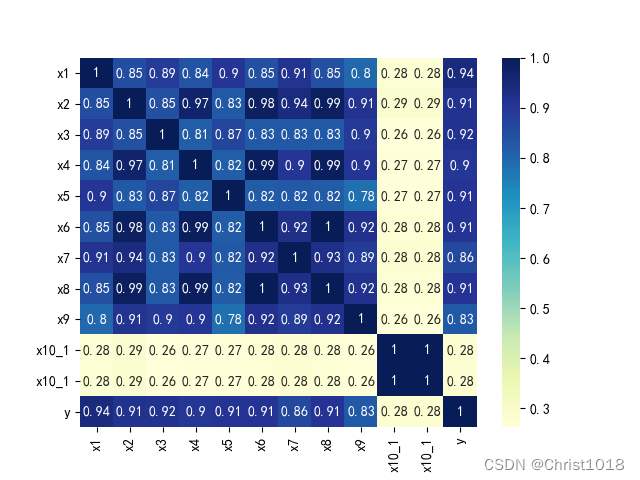
# 特征变量x1和标签变量y关系的散点图var = 'x1'data = pd.concat([data_train['y'], data_train[var]], axis=1)data.plot.scatter(x=var, y='y')plt.show()# 特征变量x5和标签变量y关系的散点图var0 = 'x5'data0 = pd.concat([data_train['y'], data_train[var0]], axis=1)data0.plot.scatter(x=var0, y='y')plt.show()# 特征数据和标签数据拆分X = data_train.drop(columns=['y'])y = data_train['y']特征数据的分析是为了更好的找出变量的重要程度。feature selection 的本质就是对一个给定特征子集的优良性通过一个特定的评价标准(evaluation criterion)进行衡量.通过特征选择,原始特征集合中的冗余(redundant)特征和不相关(irrelevant)特征被除去。而有用特征得以保留。这样模型相同,数据相同,而特征变量的选取不同,将会对结果带来巨大的影响,这也说明了在不同环境下,选取不同的特征变量进行分析的重要性。
6.建模
# 建模forest = RandomForestRegressor( n_estimators=100, random_state=1, n_jobs=-1)forest.fit(X_train, Y_train)score = forest.score(X_validation, Y_validation)print('随机森林模型得分: ', score)y_validation_pred = forest.predict(X_validation)通过调用RandomForestRegressor,我们可以进行建模,当然这也是最基础的建模。
7.验证集结果输出对比
# 验证集结果输出与比对plt.figure()plt.plot(np.arange(1000), Y_validation[:1000], "go-", label="True value")plt.plot(np.arange(1000), y_validation_pred[:1000], "ro-", label="Predict value")plt.title("True value And Predict value")plt.legend()plt.show()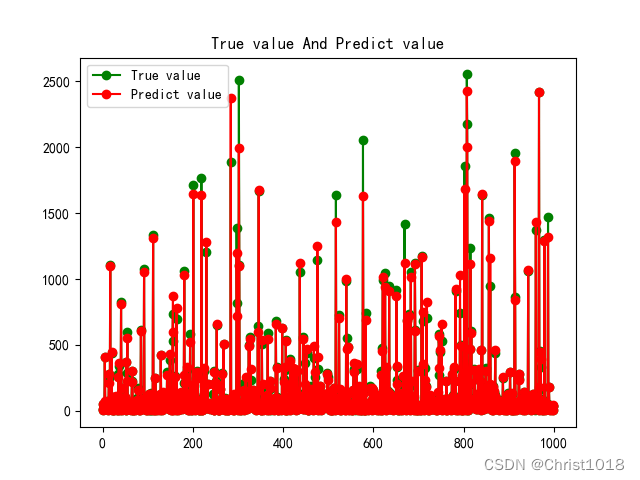
8.决策树
# 生成决策树# dot_data = StringIO()with open('./wine.dot','w',encoding='utf-8') as f: f=export_graphviz(pipe.named_steps['regressor'].estimators_[0], out_file=f)# graph = pydotplus.graph_from_dot_data(dot_data.getvalue())# graph.write_png('tree.png')# Image(graph.create_png())9.模型特征重要性
col = list(X_train.columns.values)importances = forest.feature_importances_x_columns = ['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8', 'x9', 'x10_类别1', 'x10_类别2']# print("重要性:", importances)# 返回数组从大到小的索引值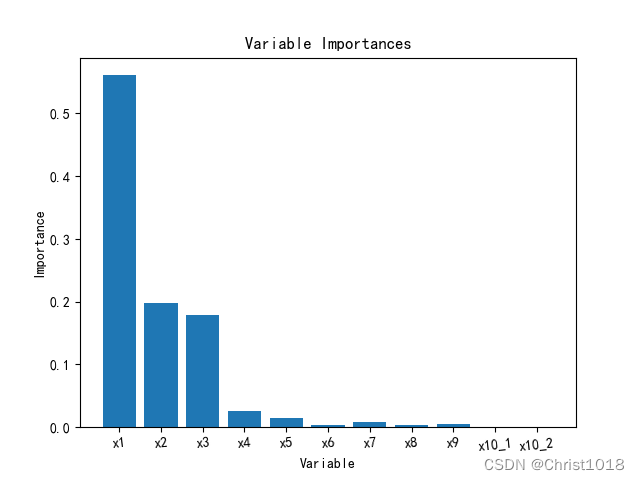
总结
通过随机森林模型的预测,可以发现所预测数据和真实的数据很接近,并且得分较高。