文章目录
15万条数据从Excel导入优化普通导入(22.1s)快速开始接口测试 批量保存优化(12.7s)查看 `saveBatch` 源码选装件InsertBatchSomeColumn接口测试 读取Excel优化(5.9s)快速开始接口测试 多线程批量插入(3.3s)加入线程池接口测试
15万条数据从Excel导入优化
最近,刚好有了一个excel,数据是150031条。数据列不多,只有5列。
文件有5.47MB,因为考虑到数据量比较大,就想着导入到MySQL看一看需要多长时间。
进而,就开始了本文之旅。
环境:SpringBoot、Mybatis-PLUS、MySQL
普通导入(22.1s)
SpringBoot实现Excel文件导入的方法有很多,如POI等等。我这里用的是EasyPoi,它对Poi做了一些封装处理,比Poi要快一点,这里我就直接使用EasyPoi来进行导入了。
以前也做了一个使用EasyPoi快速实现Excel导入导出的demo,可以参考下方链接:
使用EasyPoi快速实现excel导入导出功能
本文也是参考Demo来进行的延伸。
快速开始
定义导入VO
@Datapublic class DataImportVO { @Excel(name = "搜索词", orderNum = "0") private String name; @Excel(name = "搜索频率排名", orderNum = "1") private Integer ranking; @Excel(name = "年", orderNum = "2") private Integer year; @Excel(name = "月", orderNum = "3") private Integer month; @Excel(name = "日", orderNum = "4") private Integer day;}定义数据库实体DO
@Datapublic class TData extends BaseDO implements Serializable { /** * 搜索词 */ private String name; /** * 排名 */ private Integer ranking; /** * 年 */ private Integer year; /** * 月 */ private Integer month; /** * 日 */ private Integer day; private static final long serialVersionUID = 1L;}导入控制层
@RequestMapping("export") public ApiResponse<Boolean> export(@RequestPart MultipartFile file) { long start = System.currentTimeMillis() / 1000; ImportParams importParams = new ImportParams(); importParams.setHeadRows(1); importParams.setTitleRows(0); try { List<DataImportVO> voList = ExcelImportUtil.importExcel(file.getInputStream(), DataImportVO.class, importParams); List<TData> dataList = BeanUtils.copyList(voList, TData.class); long read = System.currentTimeMillis() / 1000; log.info("读取excel数量为:{},耗时:{}s", dataList.size(), System.currentTimeMillis() / 1000 - start); ApiResponse<Boolean> apiResponse = dataService.saveBatchData(dataList); log.info("保存到数据库,耗时:{}s", System.currentTimeMillis() / 1000 - read); return apiResponse; } catch (Exception e) { e.printStackTrace(); } return ApiResponse.failed("系统异常"); }服务实现层
@Override @Transactional(rollbackFor = Exception.class) public ApiResponse<Boolean> saveBatchData(List<TData> dataList) { return ApiResponse.ok(saveBatch(dataList)); }接口测试
这里我使用自动化测试,我只调用10次,统计下平均耗时。

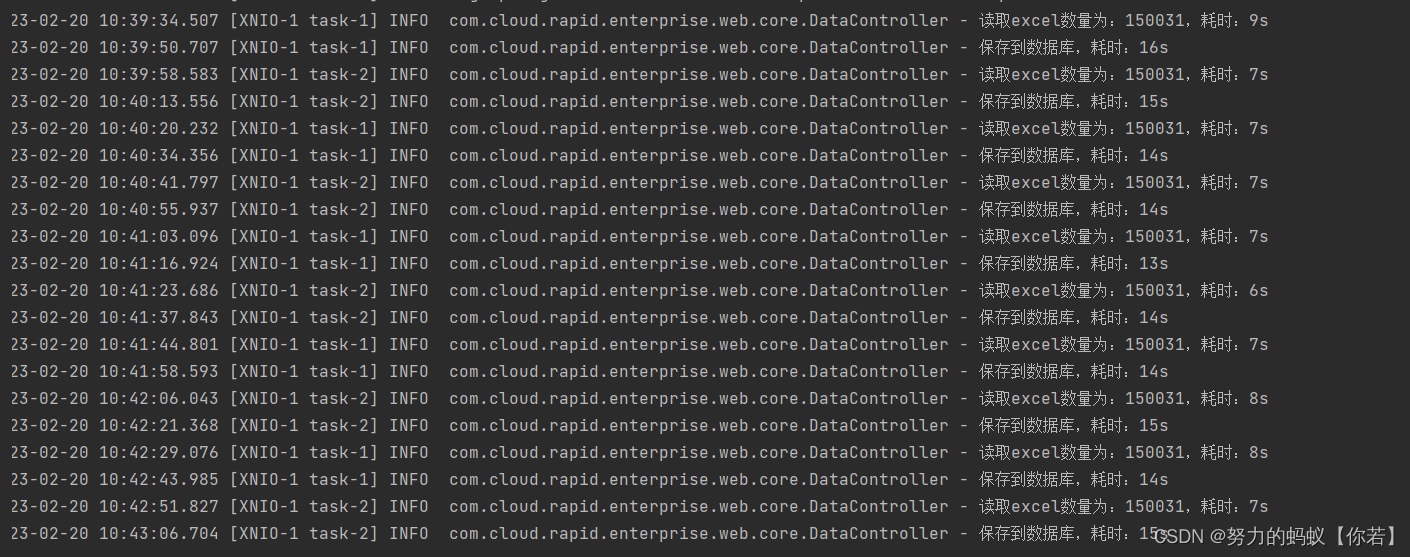
结论:通过结果图可以看出来总耗时在22s左右;
通过日志可以看出来,读取excel数据耗时7s左右;
保存数据库在15s左右。
查看数据库
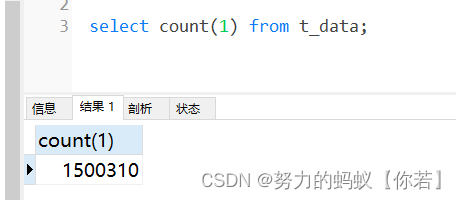
既然两个操作都比较耗时,我就开始分别来进行优化一下。
先对批量保存操作进行优化
批量保存优化(12.7s)
查看 saveBatch 源码
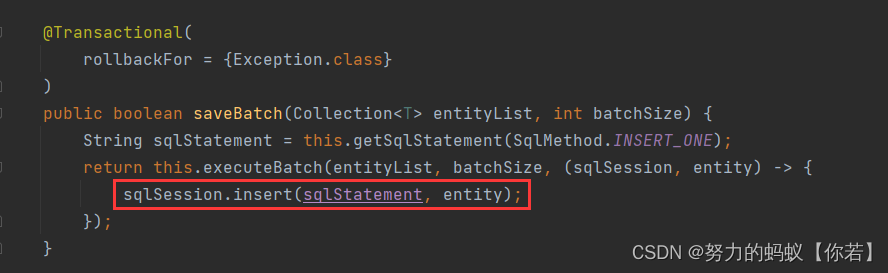
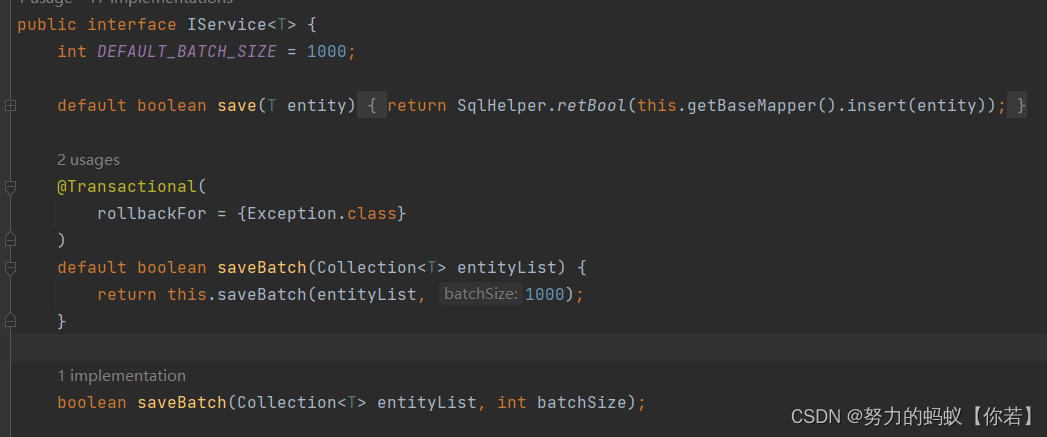
通过源码可以发现,mybatis-plus的saveBatch方法其实还是单条添加,只是For循环进行了多次调用。
这里我拿部分数据来验证一下。

结论:确实还是单条执行sql,就是说有多少数据,sql就执行多少次。
insert其实分为两种,一种就是像上面一条单条执行,如果有10条数据,那就是10条sql语句分别执行;
还有一种就是多条数据一条sql执行。如
INSERT INTO `t_data`(`name`, `ranking`, `year`, `month`, `day`) VALUES ('surgical mask', 1, 2020, 1, 29),('surgical mask', 1, 2020, 1, 29),('surgical mask', 1, 2020, 1, 29);这里举一个形象的例子,如需要搬10块转到2楼,我可以选择一次搬1块,也可以选择一次搬5块。
前者10次可以完成,后者2次就可以了。
这两者的耗时差别到底有多大,接下来可以看一下。
选装件InsertBatchSomeColumn
MyBatis-Plus提供了mapper层 选装件insertBatchSomeColumn,来支持批量新增
编写sql注入器
public class MySqlInjector extends DefaultSqlInjector { @Override public List<AbstractMethod> getMethodList(Class<?> mapperClass, TableInfo tableInfo) { List<AbstractMethod> methodList = super.getMethodList(mapperClass, tableInfo); //注意:此SQL注入器继承了DefaultSqlInjector(默认注入器),调用了DefaultSqlInjector的getMethodList方法,保留了mybatis-plus的自带方法 //例: 不要指定了 update 填充的字段 methodList.add(new InsertBatchSomeColumn(i -> i.getFieldFill() != FieldFill.UPDATE)); return methodList; }}注入插件
@Configuration//开启注解事务管理@EnableTransactionManagementpublic class IMybatisPlusConfig { @Bean public MybatisPlusInterceptor mybatisPlusInterceptor() { MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor(); //添加分页插件 interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL)); //添加乐观锁插件 interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor()); return interceptor; } /** * 注入插件 * @return */ @Bean public MySqlInjector mySqlInjector() { return new MySqlInjector(); }}定义自己的mapper
/** * @author SunChangSheng * @apiNote 定义自己的mapper,继承BaseMapper * @since 2023/2/17 10:59 */public interface BaseScsMapper<T> extends BaseMapper<T> { /** * 批量插入 仅适用于mysql * @param list 实体列表 * @return 影响行数 */ Integer insertBatchSomeColumn(@Param("list") Collection<T> list); /** * 分批插入。每次插入 * @param entityList 原实体对象 * @param size 分批大小 * @return 总插入记录 */ @Transactional(rollbackFor = Exception.class) default int insertBatchSomeColumn(List<T> entityList, int size) { if (CollUtil.isEmpty(entityList)) { return 0; } List<List<T>> split = CollUtil.split(entityList, size); return split.stream().mapToInt(this::insertBatchSomeColumn).sum(); }}注意:要扫描该mapper
mapper层
这里就继承自己刚定义的mapper,供支持批量插入。
public interface TDataMapper extends BaseScsMapper<TData> {}服务实现层
@Override@Transactional(rollbackFor = Exception.class)public ApiResponse<Boolean> saveBatchData(List<TData> dataList) { return ApiResponse.ok(baseMapper.insertBatchSomeColumn(dataList, 10000) > 0);}接口测试

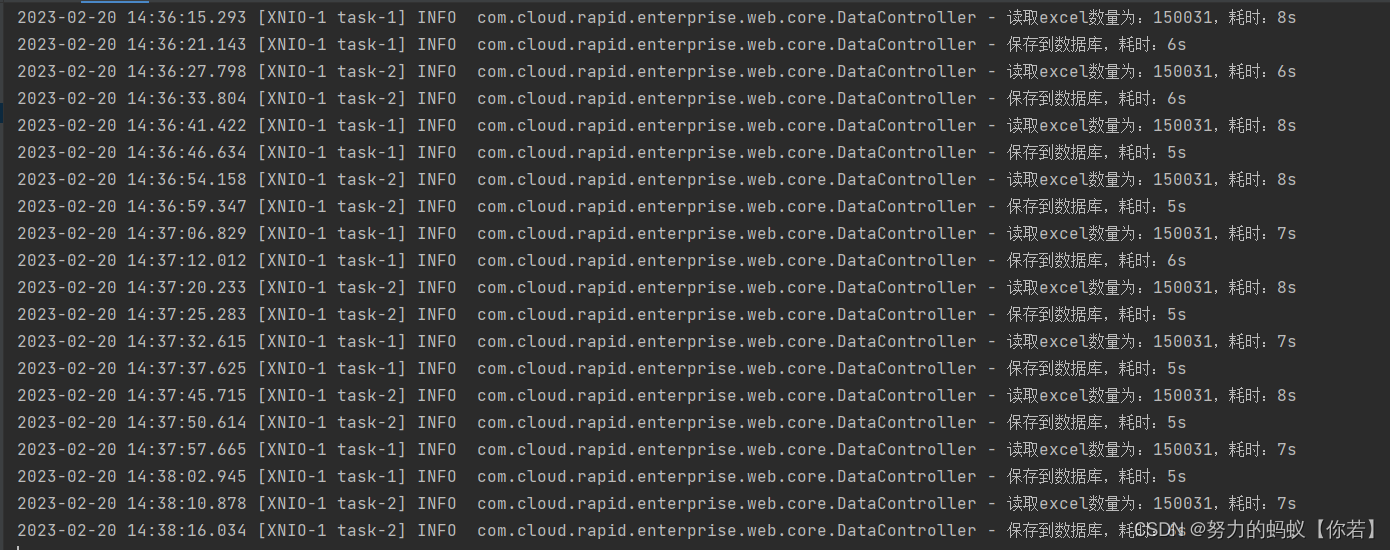
结论:可以发现改为批量保存后,插入15w条数据,大概平均在6s左右,平均单个接口耗时12.7S。和单条插入比较效率提高一半,不错!
读取Excel优化(5.9s)
通过上面的日志,可以看出读取15w条数据的Excel大概需要7-8秒的时间。我们可以在读取Excel上进行优化一下,减少读取时间。
上面讲到,读取Excel文件我使用的是EasyPoi,这里我推荐另一个神器EasyExcel。
可以看一下官网是如何介绍的。

百闻不如一试,到底有没有EasyPoi好用我们试一下就知道了。
快速开始
依赖
<!--easyexcel--> <dependency> <groupId>com.alibaba</groupId> <artifactId>easyexcel</artifactId> <version>3.2.1</version> </dependency>控制层
@RequestMapping("export") public ApiResponse<Boolean> export(@RequestPart MultipartFile file) { long start = System.currentTimeMillis() / 1000; try { List<TData> dataList = new ArrayList<>(); EasyExcel.read(file.getInputStream(), DataImportVO.class, new PageReadListener<DataImportVO>(list -> { List<TData> tDataList = BeanUtils.copyList(list, TData.class); dataList.addAll(tDataList); })).sheet().doRead(); long read = System.currentTimeMillis() / 1000; log.info("读取excel数量为:{},耗时:{}s", dataList.size(), read - start); ApiResponse<Boolean> apiResponse = dataService.saveBatchData(dataList); log.info("保存到数据库,耗时:{}s", System.currentTimeMillis() / 1000 - read); return apiResponse; } catch (Exception e) { e.printStackTrace(); } return ApiResponse.failed("系统异常"); }服务实现层
@Override @Transactional(rollbackFor = Exception.class) public ApiResponse<Boolean> saveBatchData(List<TData> dataList) { return ApiResponse.ok(baseMapper.insertBatchSomeColumn(dataList, 5000) > 0); }接口测试
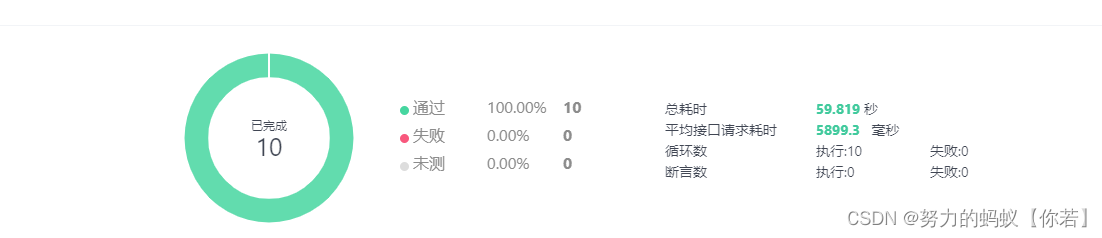
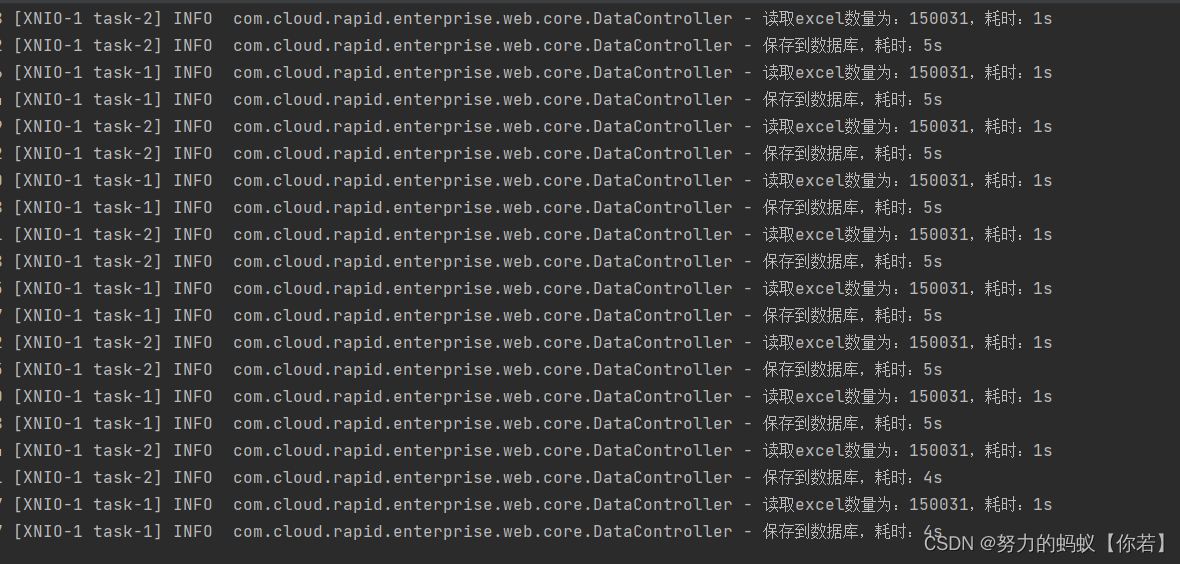
结论:读取Excel的速度都在1秒左右,可以看出EasyExcel确实很强,这时接口总耗时为5.9秒左右。
多线程批量插入(3.3s)
在上面的批量插入,我们确实提升了效率。我们进行每5000条进行插入一次,按顺序进行。
这时我们也可以使用多线程,当15w的数据量任务过来以后,我分为10个线程来同时执行,也就是每一个线程只要执行3次就可以了。
需要注意的是:使用多线程因为是异步的,所以任务还没执行完成接口就会返回了,而任务会在后台执行直接任务结束。这样的话,其实测试这个接口的响应时间其实意义不大。所以我在该实例中使用阻塞式编程,当线程池的任务都结束以后再进行返回,来计算响应时间。
关于线程池,之前也写过一篇文章,可以参考:
深入理解线程池ThreadPoolExecutor并实践使用
加入线程池
线程池配置
@Componentpublic class DataThreadConfig { private static final Logger log = LoggerFactory.getLogger(DataThreadConfig.class); @Bean("dataExecutor") public ThreadPoolTaskExecutor start() { ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor(); //核心线程数:线程池创建时候初始化的线程数 executor.setCorePoolSize(10); //最大线程数:线程池最大的线程数,只有在缓冲队列满了之后才会申请超过核心线程数的线程 executor.setMaxPoolSize(30); //缓冲队列:用来缓冲执行任务的队列 executor.setQueueCapacity(30); //允许线程的空闲时间60秒:当超过了核心线程出之外的线程在空闲时间到达之后会被销毁 executor.setKeepAliveSeconds(60); //线程池名的前缀:设置好了之后可以方便我们定位处理任务所在的线程池 executor.setThreadNamePrefix("data-thread-"); //线程池对拒绝任务的处理策略:这里采用了CallerRunsPolicy策略,当线程池没有处理能力的时候,该策略会直接在 execute 方法的调用线程中运行被拒绝的任务; //如果执行程序已关闭,则会丢弃该任务 executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); log.info("data-thread-线程池初始化"); executor.initialize(); return executor; }}启动类开启异步
@EnableAsync控制层
@RequestMapping("export") public ApiResponse<Boolean> export(@RequestPart MultipartFile file) { long start = System.currentTimeMillis() / 1000; try { List<TData> dataList = new ArrayList<>(); EasyExcel.read(file.getInputStream(), DataImportVO.class, new PageReadListener<DataImportVO>(list -> { List<TData> tDataList = BeanUtils.copyList(list, TData.class); dataList.addAll(tDataList); })).sheet().doRead(); long read = System.currentTimeMillis() / 1000; log.info("读取excel数量为:{},耗时:{}s", dataList.size(), read - start); //ApiResponse<Boolean> apiResponse = dataService.saveBatchData(dataList); ApiResponse apiResponse = testService.saveData(dataList); log.info("保存到数据库,耗时:{}s", System.currentTimeMillis() / 1000 - read); return apiResponse; } catch (Exception e) { e.printStackTrace(); } return ApiResponse.failed("系统异常"); }服务层
这里我新建了一个TestService服务层
ApiResponse saveData(@RequestBody List<TData> dataList);服务实现层
@Transactional public ApiResponse saveData(List<TData> dataList) { List<List<TData>> list = ListUtils.splistList(dataList, 5000); List<Future<Boolean>> futureList = new ArrayList<>(); for (List<TData> data : list) { Future<Boolean> future = dataService.save123(data); futureList.add(future); } //当所有的任务都执行完成后返回 for (Future<Boolean> future : futureList) { try { future.get(); } catch (Exception e) { e.printStackTrace(); } } return ApiResponse.ok(true); }接口
Future<Boolean> save123(@RequestBody List<TData> dataList);服务实现层
加入异步编程线程池
@Override@Transactional(rollbackFor = Exception.class)@Async("dataExecutor")public Future<Boolean> save123(List<TData> dataList) { boolean b = baseMapper.insertBatchSomeColumn(dataList, 5000) > 0; log.info("执行完成:{}", dataList.size()); return new AsyncResult<>(b);}接口测试
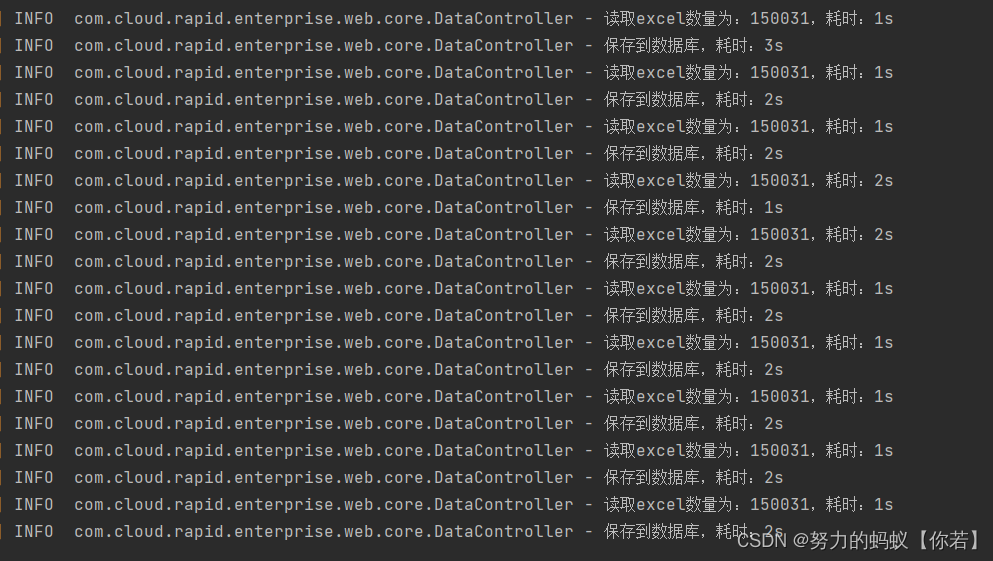
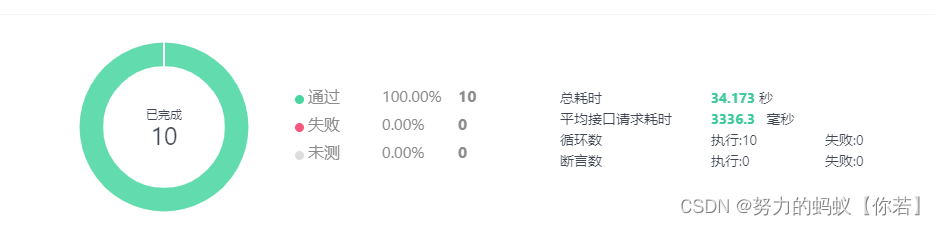
结论:读取excel为1s,保存数据为2s,平均耗时3秒左右。
从最初的22秒到现在的3秒,效率确实得到很大的提升了。