目录
前言背景专业多层数据对象强大计算能力优化体系结构SPL资料
前言
WebService/Restful广泛应用于程序间通讯,如微服务、数据交换、公共或私有的数据服务等。之所以如此流行,主要是因为WebService/Restful采用了XML/Json这类多层结构化数据进行信息传递。XML/Json不仅是文本格式,而且支持多层结构,可承载足够通用和足够丰富的信息。但多层结构要比传统的二维表复杂,取数后再处理的难度也大。
背景
早期,没有专业的json/XML的后处理技术,Java开发者通常要采取硬写代码或入库再用SQL的方式。硬写代码工作量巨大,计算能力几乎为零,开发效率极低。SQL虽然可以提供部分计算能力,但存在明显的架构缺陷,不仅会因为引入SQL而制造额外的耦合性,而且会因为入库过程导致额外的系统延迟。此外,数据库只适合计算二维表,多层结构化数据的计算能力并不强。
后来,XPath/JsonPath、Python Pandas、Scala这类专业的json/XML的后处理技术出现了,才终于在保证较好架构性的同时,提供了一定的计算能力。但这些技术也存在各自的问题,XPath/JsonPath只支持条件查询和简单聚合,不支持一般的日常计算,比如排序、去重、分组汇总、关联、交集等,而且没有自己的多层数据对象,计算能力较差。
Python Pandas支持一般的日常计算,其数据对象dataFrame能描述二维表,但计算处理多层数据并不方便,而且和Java应用的集成性很不好。Scala的数据对象dataFrame也类似,可以描述多层结构,但计算处理也不方便。此外,Scala和Pandas对XML支持得都不好,要手工进行类型转换,或引入第三方类库,开发效率不高。
所以,SPL是个更好的选择。
专业多层数据对象
SPL是JVM下开源的结构化数据/多层数据处理语言,内置专业的多层数据对象和方便的层次访问方法,可以表达复杂的层次关系,为上层计算能力提供有力的支持。
SPL提供了专业的多层数据对象序表,可以直观地表现XML\Json的层级结构。
比如,从文件读取多层XML串,解析为序表:
| A | |
|---|---|
| 1 | =file(“d:\xml\emp_orders.xml”).read() |
| 2 | =xml(A1,“xml/row”) |
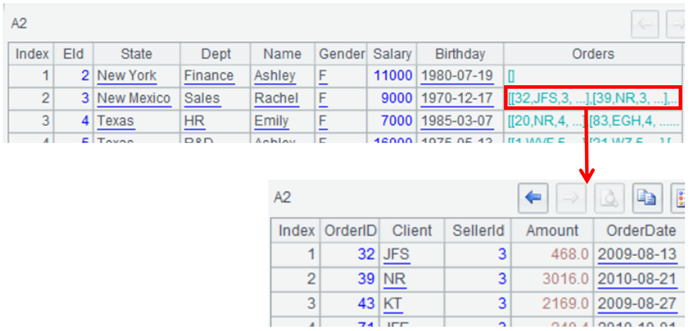
点击A2格可以看到多层序表的结构,其中,EId、State等字段存储简单数据类型,Orders字段存储记录集合(二维表)。点击Orders中的某一行,可以展开观察数据:
序表也可以表达来自文件的多层Json(与上面的XML同构):
| A | |
|---|---|
| 1 | =file(“d:\xml\emp_orders.json”).read() |
| 2 | =json(A1) |
点击A2格可以看到,来自Json的序表与来自XML的序表一样。事实上,SPL序表可以统一地表达不同来源的多层数据,无论XML还是Json,无论WebService还是Restful,这是其他技术难以做到的。
SPL提供了方便的多层数据访问方法,可以通过点号访问不同的层级,通过下标访问不同的位置。
第1层的单个字段的集合:A2.(Client)
第1层的多个字段的集合:A2.([Client,Name])
第2层所有记录的集合:A2.conj(Orders)
第1层第10条记录:A2(10)
第1层第10条记录的Orders字段(即所有下层记录):A2(10).Orders
第1层第10条件记录Orders字段的单个字段的集合:(A2(10).Orders).(Amount)
第1层第10条件记录Orders字段的第5条记录:(A2(10).Orders)(5)
第1层的第10-20条记录:A2(to(10,20))
第1层的最后三条记录:A2.m([-1,-2,-3])
SPL序表专业性强,可以表达复杂的层次关系。比如,针对多含多个子文档的多层Json:
[ { "race": { "raceId":"1.33.1141109.2", "meetingId":"1.33.1141109" }, ... "numberOfRunners": 2, "runners": [ { "horseId":"1.00387464", "trainer": { "trainerId":"1.00034060" }, "ownerColours":"Maroon,pink,dark blue." }, { "horseId":"1.00373620", "trainer": { "trainerId":"1.00010997" }, "ownerColours":"Black,Maroon,green,pink." } ] },...]进行不同层级的分组汇总(对trainerId分组,统计每组中 ownerColours的成员个数),一般的技术难以写出代码,SPL就简单多了:
| A | |
|---|---|
| 1 | … |
| 2 | =A1(1).runners |
| 3 | =A2.groups(trainer.trainerId; ownerColours.array().count():times) |
强大计算能力
以序表为基础,SPL内置丰富的计算函数、日期函数、字符串函数,提供了强大的计算能力。依靠函数选项、层次参数等高级语法,SPL提供了超越SQL的计算能力。
SPL内置丰富的计算函数,基础计算一句完成。比如,对多层数据进行条件查询:
| A | |
|---|---|
| 2 | …//省略取数解析 |
| 3 | =A2.conj(Orders) |
| 4 | =A3.select(Amount>1000 && Amount<=2000 && like@c(Client,“business”)) |
可以看到,SPL对条件查询的支持很完整,包括关系运算符、逻辑运算符、正则表达式和字符串函数,如模糊匹配like。此外,SPL还支持在条件查询中使用数学运算符(函数)、位置函数、日期函数。
更多例子:
| A | B | |
|---|---|---|
| 2 | … | |
| 3 | = A3.sum(Salary) | 聚合 |
| 4 | =A2.groups(State,Gender;avg(Salary),count(1)) | 第1层分组汇总 |
| 5 | =A2.conj(Orders).groups(Client;sum(Amount)) | 第2层分组汇总 |
| 6 | =A1.new(Name,Gender,Dept,Orders.OrderID,Orders.Client,Orders.Client,Orders.SellerId,Orders.Amount,Orders.OrderDate) | 关联 |
| 7 | =A1.sort(Salary) | 排序 |
| 8 | =A1.id(State) | 去重 |
| 9 | =A2.top(-3;Amount) | topN |
| 10 | =A2.groups(Client;top(3,Amount)) | 组内TopN(窗口函数) |
SPL内置大量日期函数和字符串函数,在数量和功能上远远超过其他技术甚至SQL,同样的运算代码量更短。比如:
时间类函数,日期增减:elapse("2020-02-27",5) //返回2020-03-03
星期几:day@w("2020-02-27") //返回5,即星期6
N个工作日之后的日期:workday(date("2022-01-01"),25) //返回2022-02-04
字符串类函数,判断是否全为数字:isdigit("12345") //返回true
取子串前面的字符串:substr@l("abCDcdef","cd") //返回abCD
按竖线拆成字符串数组:"aa|bb|cc".split("|") //返回[“aa”,“bb”,“cc”]
SPL还支持年份增减、求年中第几天、求季度、按正则表达式拆分字符串、拆出SQL的where或select部分、拆出单词、按标记拆HTML等功能。
SPL提供了函数选项、层次参数等方便的函数语法,可以提供更强的计算能力。功能相似的函数可以共用一个函数名,只用函数选项区分差别。比如select函数的基本功能是过滤,如果只过滤出符合条件的第1条记录,可使用选项@1:
Orders.select@1(Amount>1000)
数据量较大时,用并行计算提高性能,可使用选项@m:
Orders.select@m(Amount>1000)
对排序过的数据,用二分法进行快速过滤,可用@b:
Orders.select@b(Amount>1000)
函数选项还可以组合搭配,比如:
Orders.select@1b(Amount>1000)
结构化运算函数的参数常常很复杂,比如SQL就需要用各种关键字把一条语句的参数分隔成多个组,但这会动用很多关键字,也使语句结构不统一。SPL支持层次参数,通过分号、逗号、冒号自高而低将参数分为三层,用通用的方式简化复杂参数的表达:
join(Orders:o,SellerId ; Employees:e,EId)
优化体系结构
SPL内置易于集成的JDBC接口,可有效降低系统耦合性,并支持代码热切换。SPL支持多种多层数据源,可用一致的代码进行计算,使代码易于移植。
SPL提供了通用的JDBC接口,可以被JAVA代码方便地集成。 比如,将前面的SPL代码存为脚本文件,在JAVA中以存储过程的形式调用文件名:
Class.forName("com.esproc.jdbc.InternalDriver");Connection connection =DriverManager.getConnection("jdbc:esproc:local://");Statement statement = connection.createStatement();ResultSet result = statement.executeQuery("call groupBy()");SPL脚本文件外置于JAVA,使计算代码和应用程序分离,可有效降低系统耦合性。SPL是解释型语言,修改后不必重启JAVA应用就可以直接执行,从而实现代码热切换,可保障系统稳定,降低维护难度。
SPL支持来自WebSerivce和Restful的多层数据。比如,从WebService读取多层XML,进行条件查询:
| A | |
|---|---|
| 1 | =ws_client(“http://127.0.0.1:6868/ws/RQWebService.asmx?wsdl”) |
| 2 | =ws_call(A1,“RQWebService”:“RQWebServiceSoap”:“getEmp_orders”) |
| 3 | =A2.conj(Orders) |
| 4 | =A3.select(Amount>1000 && Amount<=2000 && like@c(Client,“business”)) |
类似地,从Restful取多层Json,进行同样的条件查询:
| A | |
|---|---|
| 1 | =httpfile(“http://127.0.0.1:6868/restful/emp_orders”).read() |
| 2 | =json(A1) |
| 3 | =A2.conj(Orders) |
| 4 | =A3.select(Amount>1000 && Amount<=2000 && like@c(Client,“business”)) |
SPL支持MongoDB、ElasticSearch、SalesForce等特殊数据源中的多层数据,可直接从这些数据源取数并计算。
比如,从MongoDB取多层Json,进行条件查询:
| A | |
|---|---|
| 1 | =mongo_open(“mongodb://127.0.0.1:27017/mongo”) |
| 2 | =mongo_shell@x(A1,“data.find()”) |
| 3 | =A2.conj(Orders) |
| 4 | =A3.select(Amount>1000 && Amount<=2000 && like@c(Client,“business”)) |
除了多层数据,SPL也支持数据库,txt\csv\xls等文件, Hadoop、redis、Kafka、Cassandra等NoSQL。虽然数据源不同,但在SPL中的数据类型都是序表,因此可以用一致的方法计算多层数据,这样的计算代码也更容易移植。
XPath/JsonPath、Python Pandas、Scala等技术存在各自的缺陷,开发效率不高。SPL内置专业的多层数据对象和方便的层次访问方法,擅长计算结构复杂的多层数据。SPL内置丰富的库函数,提供了超过SQL的计算能力。SPL支持易用的JDBC接口、代码外置能力,支持来自多种文件和网络服务的多层数据源,可大幅提高WebService\Restful取数后的开发效率。
SPL资料
SPL官网SPL下载SPL源代码欢迎对SPL有兴趣的加小助手(VX号:SPL-helper),进SPL技术交流群