❤写在前面:有一说一哈夫曼有点厉害!
❤博客主页:努力的小鳴人
❤系列专栏:算法
❤欢迎小伙伴们,点赞?关注?收藏?一起学习!
❤如有错误的地方,还请小伙伴们指正!?
上期热榜好文:?昨天上课学到的 贪心法
目录
?哈夫曼编码1.问题描述2.构造思想3.算法设计4.构造实例5.算法描述及分析
?哈夫曼编码
小科普:
1951年,哈夫曼在麻省理工学院(MIT)攻读博士学位,他和修读信息论课程的同学得选择是完成学期报告还是期末考试。导师罗伯特·法诺(Robert Fano)出的学期报告题目是:查找最有效的二进制编码。由于无法证明哪个已有编码是最有效的,哈夫曼放弃对已有编码的研究,转向新的探索,最终发现了基于有序频率二叉树编码的想法,并很快证明了这个方法是最有效的。哈夫曼使用自底向上的方法构建二叉树,避免了次优算法香农-范诺编码(Shannon–Fano coding)的最大弊端──自顶向下构建树
1952年,于论文《一种构建极小多余编码的方法》(A Method for the Construction of Minimum-Redundancy Codes)中发表了这个编码方法
1.问题描述
不等长编码方法出现的问题:任何一个字符的编码都不能是其它字符编码的前缀,否则译码时将产生二义性。那么如何来设计前缀编码呢?利用二叉树来进行设计,具体做法是:约定在二叉树中用叶子结点表示字符,从根结点到叶子结点的路径中,左分支表示“0”,右分支表示“1”。那么从根结点到叶子结点的路径分支所组成的字符串做为该叶子结点字符的编码,可以证明这样的编码一定是前缀编码,这棵二叉树即为编码树
哈夫曼树又称为最优树
然后剩下的问题就是怎样保证这样的编码树所得到的编码总长度最小?哈夫曼提出了解决该问题的方法,由此产生的编码方案称为 哈夫曼算法
2.构造思想
以字符的使用频率做权构建一棵哈夫曼树,然后利用哈夫曼树对字符进行编码,这就是哈夫曼编码。具体来讲,是将所要编码的字符作为叶子结点,该字符在文件中的使用频率作为叶子结点的权值,以自底向上的方式、通过执行n-1次的“合并”运算后构造出最终所要求的树,即哈夫曼树,它的核心思想是让权值大的叶子离根最近,这里需要用到贪心策略,我们采用的贪心策略是每次从树的集合中取出双亲为0且权值最小的两棵树作为左、右子树,构造一棵新树,新树根结点的权值为其左右孩子结点权之和,将新树插入到树的集合中
这里个人感觉有点抽象,不太好懂,相信看到算法设计和构造实例问题就迎刃而解了
?补充:
哈夫曼静态编码:它对需要编码的数据进行两遍扫描:第一遍统计原数据中各字符出现的频率,利用得到的频率值创建哈夫曼树,并必须把树的信息保存起来,即把字符0-255(2^8=256)的频率值以24BYTES的长度顺序存储起来,(用4Bytes的长度存储频率值,频率值的表示范围为0–2^32-1,这已足够表示大文件中字符出现的频率了)以便解压时创建同样的哈夫曼树进行解压;第二遍则根据第一遍扫描得到的哈夫曼树进行编码,并把编码后得到的码字存储起来
哈夫曼动态编码:动态哈夫曼编码使用一棵动态变化的哈夫曼树,对第t+1个字符的编码是根据原始数据中前t个字符得到的哈夫曼树来进行的,编码和解码使用相同的初始哈夫曼树,每处理完一个字符,编码和解码使用相同的方法修改哈夫曼树,所以没有必要为解码而保存哈夫曼树的信息。编码和解码一个字符所需的时间与该字符的编码长度成正比,所以动态哈夫曼编码可实时进行
3.算法设计
步骤:
步骤1:确定合适的数据结构步骤2:初始化。构造n棵结点为n个字符的单结点树集合F={T1,T2,…, Tn},每棵树中只有一个带权的根结点,权值为该字符的使用频率;步骤3:如果F中只剩下一棵树,则哈夫曼树构造成功,转步骤6;否则,从集合F中取出双亲为0且权值最小的两棵树Ti和Tj,将它们合并成一棵新树Zk,新树以Ti为左儿子,Tj为右儿子(反之也可以)。新树Zk的根结点的权值为Ti与Tj的权值之和步骤4:从集合F中删去Ti、Tj,加入Zk;步骤5:重复步骤 3和 4;步骤6:从叶子结点到根结点逆向求出每个字符的哈夫曼编码(约定左分支表示字符“0”,右分支表示字符“1”)。则从根结点到叶子结点路径上的分支字符组成的字符串即为叶子字符的哈夫曼编码算法结束4.构造实例
已知某系统在通信联络中只可能出现8种字符,分别为a,b,c,d,e,f,g,h,其使用频率分别为0.05,0.29,0.07,0.08,0.14,0.23,0.03,0.11,试设计出哈夫曼编码
设权w=(5,29,7,8,14,23,3,11),n=8,按哈夫曼算法的设计步骤构造一棵哈夫曼编码树
(这里就是把字符出现的频率作为叶子结点的权值)
?补充:
1、路径和路径长度
在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径。通路中分支的数目称为路径长度。若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1
2、结点的权及带权路径长度
若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积
3、树的带权路径长度
树的带权路径长度规定为所有叶子结点的带权路径长度之和,记为WPL
具体过程如下:
对着上图把权值从小到大形成树再“合并”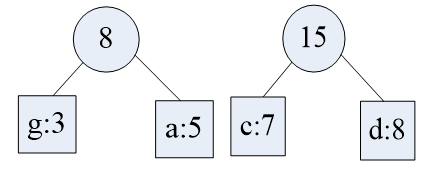
“合并”后如下: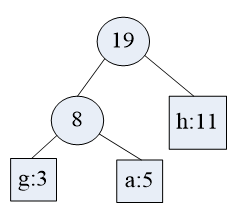
掌握好了形成树很简单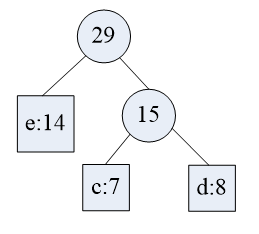
继续合并: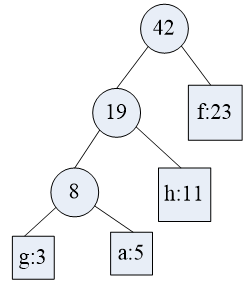
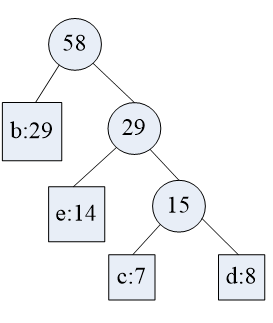
把这两大枝再合并: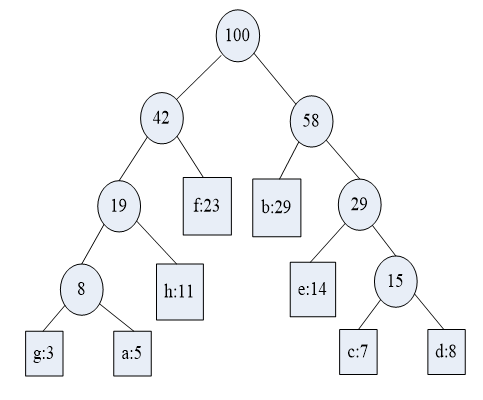
结果就出来了:
路径上左边改为0,右面改为1
哈夫曼编码是从叶子找到根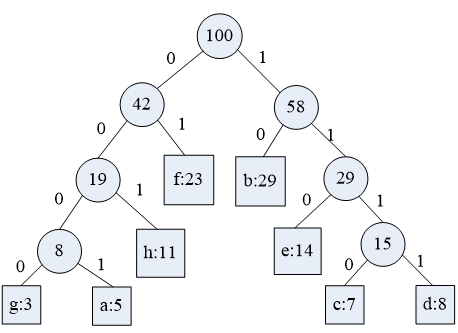
哈夫曼树的代码实现:需要考虑到权值进行排序,这边建议用冒泡排序,真的很香,不管是从大到小还是从小到大都很实用
代码实现:我用的是C++和VS2017
han.cpp:
#include<iostream>#include<string>using namespace std;typedef struct{int w;int parent;int lchild, rchild;}HTNode, *HuffmanTree;void shaixuan(HuffmanTree H, int i, int &s1, int &s2){int n = 1;int j = 1;int z;while (j <= 2){n = 1;while (H[n].parent != 0){n++;}z = n;while (n < i){n = n + 1;if (H[n].parent == 0){if (H[z].w > H[n].w){z = n;}}}if (j == 1){s1 = z;H[s1].parent = 1;j++;}else{s2 = z;j++;}}}void createmanTree(HuffmanTree &H, int n){if (n <= 1)return;int m = 2 * n - 1; //结点数H = new HTNode[m + 1];int i;for (i = 1; i <= m; i++){H[i].parent = 0;H[i].lchild = 0;H[i].rchild = 0;}i = 1;while (i <= n){cin >> H[i].w;i++;}int j = n;int s1, s2;for (i = n + 1; i <= m; ++i){shaixuan(H, i - 1, s1, s2);H[s1].parent = i;H[s2].parent = i;H[i].lchild = s1;H[i].rchild = s2;H[i].w = H[s1].w + H[s2].w;}}void bianma(HuffmanTree H, int n){char c[n][n + 1];char ch[n];int i = 1;int j, f, k = 0;int z, m;for (i = 1; i <= n; ++i){j = i;f = H[i].parent;k = 0;while (f != 0){if (H[f].lchild == j){ch[k] = '0';k++;}else{ch[k] = '1';k++;}j = f;f = H[f].parent;}ch[k] = '\0';z = strlen(ch);int u = 0;for (m = z - 1; m >= 0; m--){c[i - 1][u] = ch[m];u++;}c[i - 1][u] = '\0';}i = 0;while (i <= 7){j = 0;cout << "第" << i + 1 << "个字符的哈夫曼编码是 :";while (c[i][j] != '\0'){cout << c[i][j];j++;}i++;cout << endl;}}Status.cpp:
#define TRUE 1#define FALSE 0#define OK 1#define ERROR 0#define INFEASIBLE -1#define OVERFLOW -2#define MAXSIZE 100typedef int Status;源.cpp:
#include <iostream>#include "han.cpp"#include "Status.cpp"using namespace std;int main(){HuffmanTree H;int n;n = 8;createmanTree(H, n);bianma(H, n);return 0;}输出结果为:
5 29 7 8 14 23 3 11
第1个字符的哈夫曼编码是 :0001
第2个字符的哈夫曼编码是 :10
第3个字符的哈夫曼编码是 :1110
第4个字符的哈夫曼编码是 :1111
第5个字符的哈夫曼编码是 :110
第6个字符的哈夫曼编码是 :01
第7个字符的哈夫曼编码是 :0000
第8个字符的哈夫曼编码是 :001
5.算法描述及分析
采用线性结构实现的算法,其复杂性为O(n2)
算法的改进:采用极小堆实现,其复杂性为O(nlogn)
?总结:我想问一下你们从哈夫曼编码中学到了什么?请畅所欲言哦
? 作者算是一名Java初学者,文章如有错误,欢迎评论私信指正,一起学习~~
?如果文章对小伙伴们来说有用的话,点赞?关注?收藏?就是我的最大动力!
?不积跬步,无以至千里,书接下回,欢迎再见?